Dans les deux premiers articles, j'ai soulevé la question de l'automatisation et esquissé son cadre, dans le second j'ai fait une digression dans la virtualisation de réseau, comme première approche pour automatiser la configuration des services.
Et maintenant, il est temps de dessiner un schéma de réseau physique.
Si vous n'êtes pas sur un pied court avec l'appareil des réseaux de centres de données, alors je recommande fortement de commencer par un
article à leur sujet .
Tous les numéros:
Les pratiques décrites dans cette série devraient être applicables à un réseau de tout type, à toute échelle, avec toute variété de fournisseurs (non). Cependant, un exemple universel de l'application de ces approches ne peut être décrit. Par conséquent, je me concentrerai sur l'architecture moderne du réseau DC:
Klose Factory .
DCI fera l'affaire sur MPLS L3VPN.
Un réseau Overlay de l'hôte s'exécute au-dessus du réseau physique (il peut s'agir d'OpenStack VXLAN ou de Tungsten Fabric ou de tout autre élément qui ne nécessite qu'une connectivité IP de base du réseau).
Dans ce cas, nous obtenons un scénario d'automatisation relativement simple, car nous avons beaucoup d'équipements configurés de la même manière.
Nous choisirons un DC sphérique sous vide:
- Une version du design est partout.
- Deux vendeurs formant deux plans du réseau.
- Un DC est comme un autre comme deux gouttes d'eau.
Table des matières
- Topologie physique
- Acheminement
- Plan IP
- Laba
- Conclusion
- Liens utiles
Laissez notre fournisseur de services LAN_DC, par exemple, héberger des vidéos de formation sur la survie dans les ascenseurs bloqués.
Dans les mégapoles, c'est extrêmement populaire, il y a donc beaucoup de machines physiques.
Tout d'abord, je vais décrire le réseau à peu près comme je voudrais le voir. Et puis je vais le simplifier pour le laboratoire.
Topologie physique
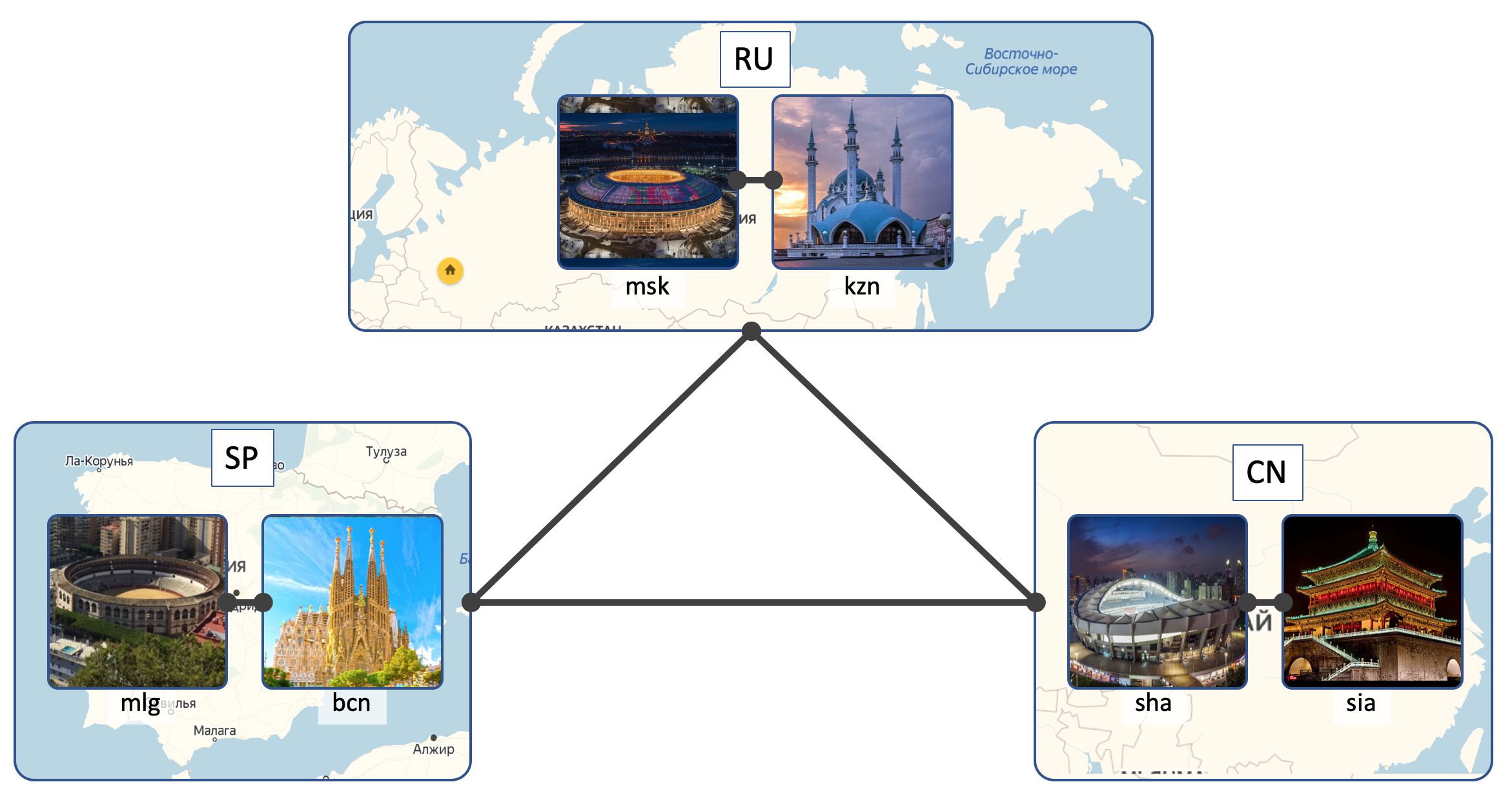
Emplacements
LAN_DC aura 6 DC:
- Russie ( RU ):
- Moscou ( msk )
- Kazan ( kzn )
- Espagne ( SP ):
- Barcelone ( bcn )
- Malaga ( mlg )
- Chine ( CN ):
- Shanghai ( sha )
- Xi'an ( sia )
Inside DC (Intra-DC)
Dans tous les DC, réseaux de connectivité interne identiques basés sur la topologie Clos.
Quels types de réseaux sont Klose et pourquoi sont-ils dans un
article séparé.
Dans chaque DC, il y a 10 racks avec des voitures, ils seront numérotés comme
A ,
B ,
C Et ainsi de suite.
Chaque rack a 30 voitures. Ils ne nous intéresseront pas.
De plus, dans chaque rack, il y a un commutateur auquel toutes les machines sont connectées - c'est
le commutateur Top of the Rack - ToR ou bien en termes d'usine Klose, nous l'appellerons
Leaf .
 Le schéma général de l'usine.
Le schéma général de l'usine.Nous les nommerons
XXX -feuille Y , où
XXX est l'abréviation à trois lettres DC et
Y est le numéro de série. Par exemple,
kzn-leaf11 .
Dans les articles, je me permets d'utiliser les termes Leaf et ToR de manière assez frivole, comme synonymes. Cependant, il faut se rappeler que ce n'est pas le cas.
ToR est un commutateur monté en rack auquel les machines se connectent.
Leaf est le rôle d'un périphérique dans un réseau physique ou d'un commutateur de premier niveau en termes de topologie de Clos.
Autrement dit, Leaf! = ToR.
Ainsi, Leaf peut être un commutateur EndofRaw, par exemple.
Cependant, dans le cadre de cet article, nous les désignerons néanmoins comme des synonymes.
Chaque commutateur ToR est à son tour connecté à quatre commutateurs d'agrégation en amont -
Spine . Sous Spine'y alloué un rack dans le DC. Nous l'appellerons de la même manière:
XXX- colonne vertébrale Y.Dans le même rack, il y aura un équipement réseau pour la connectivité entre les CC - 2 routeurs avec MPLS à bord. Mais dans l'ensemble, ce sont les mêmes TdR. Autrement dit, du point de vue des commutateurs Spine, peu importe qu'il existe un ToR habituel avec des machines connectées ou un routeur pour DCI - une putain de chose.
Ces ToR spéciaux sont appelés
Edge-leaf . Nous les appellerons
XXX bord Y.Cela ressemblera à ceci.

Dans le diagramme au-dessus du bord et de la feuille, je me suis vraiment placé au même niveau.
Les réseaux classiques à trois niveaux nous ont appris à considérer la liaison montante (le terme vient en fait d'ici), comme des liens. Et ici, il s'avère que la «liaison montante» de DCI redescend, ce qui rompt quelque peu la logique habituelle. Dans le cas des grands réseaux, lorsque les centres de données sont divisés en unités plus petites -
POD (Point Of Delivery), des
Edge-POD distincts sont alloués pour DCI et l'accès aux réseaux externes.
Pour plus de commodité, à l'avenir, je dessinerai toujours Edge on Spine, tout en gardant à l'esprit qu'il n'y a pas d'intelligence sur Spine et des différences lorsque vous travaillez avec une feuille ordinaire et une feuille de bord (bien qu'il puisse y avoir des nuances, mais en général il en est ainsi).
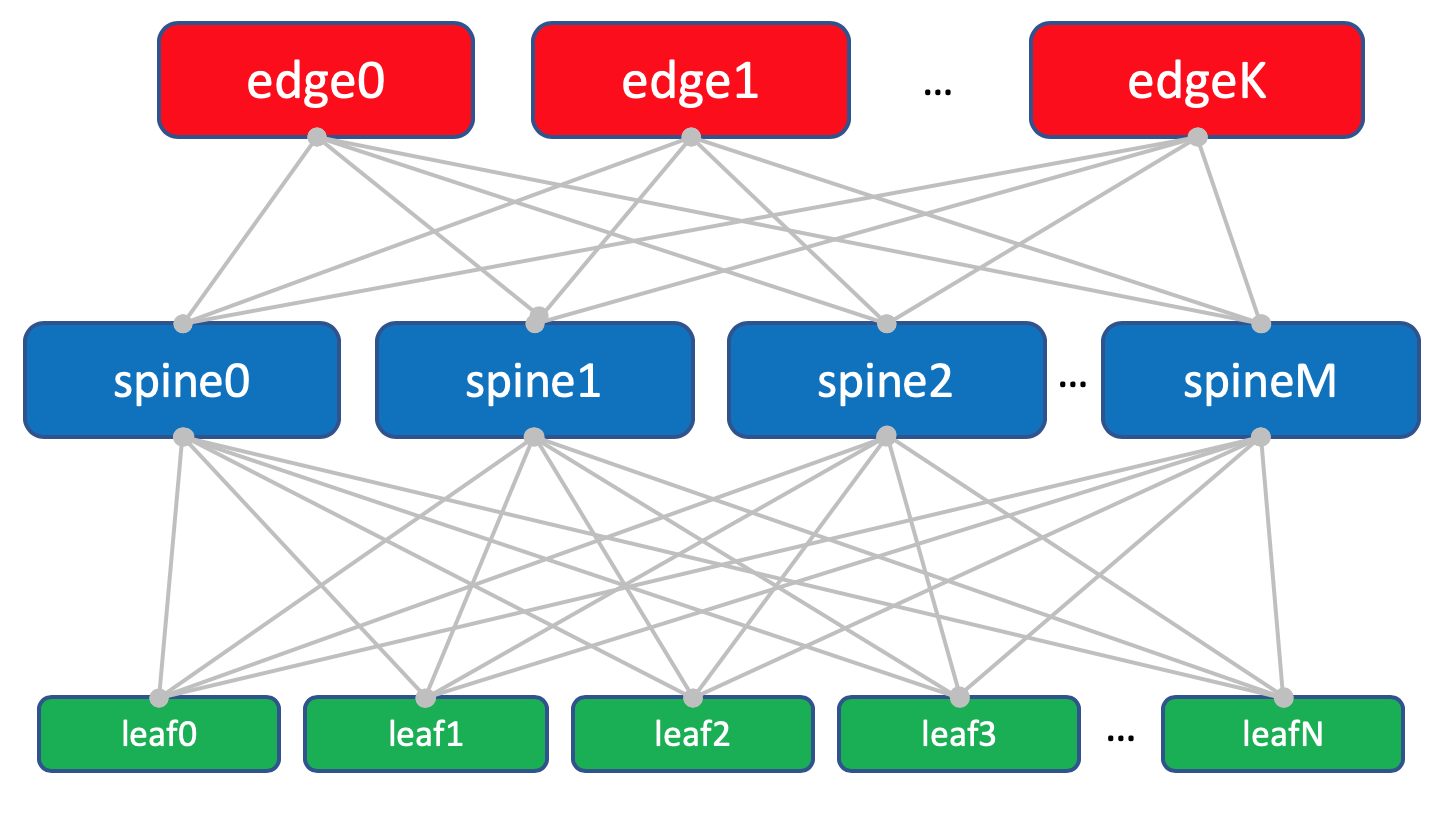 Disposition d'usine avec les feuilles Edge.
Disposition d'usine avec les feuilles Edge.Trinity Leaf, Spine et Edge forment un réseau ou une usine de sous-couches.
La tâche de l'usine de réseau (lire Underlay), comme nous l'avons déjà déterminé dans le
numéro précédent , est très, très simple - fournir une connectivité IP entre des machines à la fois dans le même DC et entre.
C'est pourquoi le réseau est appelé une usine, tout comme, par exemple, une usine de commutation à l'intérieur de boîtiers de réseau modulaires, que vous trouverez plus en détail dans
SDSM14 .
En général, une telle topologie est appelée usine, car le tissu en traduction est un tissu. Et c'est difficile de ne pas être d'accord:

Usine complètement L3. Pas de VLAN, pas de diffusion - ce sont d'excellents programmeurs à LAN_DC, ils peuvent écrire des applications qui vivent dans le paradigme L3, et les machines virtuelles ne nécessitent pas de migration en direct avec l'enregistrement de l'adresse IP.
Et encore: la réponse à la question de savoir pourquoi l'usine et pourquoi L3 - dans un
article séparé.
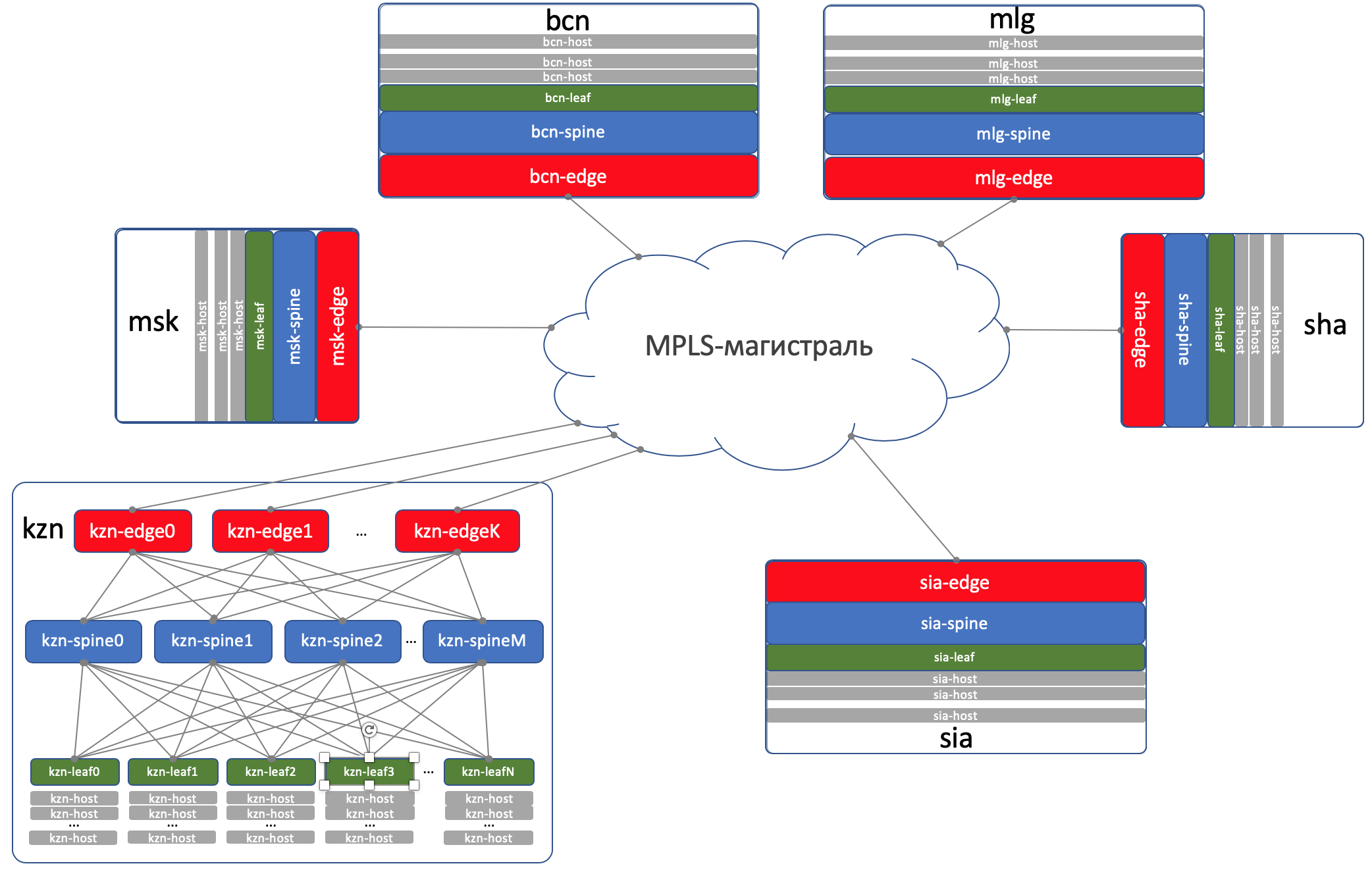
DCI - Data Center Interconnect (Inter-DC)
DCI sera organisé en utilisant Edge-Leaf, c'est-à-dire qu'ils sont notre point de sortie vers l'autoroute.
Pour simplifier, nous supposons que les contrôleurs de domaine sont connectés par des liaisons directes.
Nous excluons la connectivité externe de la considération.
Je suis conscient que chaque fois que je supprime un composant, je simplifie considérablement le réseau. Et avec l'automatisation de notre réseau abstrait, tout ira bien, mais des béquilles apparaîtront sur le vrai.
C'est vrai. Néanmoins, le but de cette série est de penser et de travailler sur des approches, et non de résoudre héroïquement des problèmes imaginaires.
Sur Edge-Leafs, la sous-couche est placée dans le VPN et transmise via le réseau principal MPLS (le même lien direct).
Voici un tel schéma de haut niveau.
Acheminement
Pour le routage à l'intérieur du DC, nous utiliserons BGP.
Sur le tronc OSPF + LDP MPLS
Pour DCI, c'est-à-dire que l'organisation de la connectivité en dessous est BGP L3VPN sur MPLS.
 Schéma de routage général
Schéma de routage généralIl n'y a pas d'OSPF et d'ISIS en usine (protocole de routage interdit dans la Fédération de Russie).
Et cela signifie qu'il n'y aura pas de détection automatique et de calculs de chemin le plus court - uniquement manuel (en fait automatique - nous sommes ici sur l'automatisation) pour configurer le protocole, le voisinage et les politiques.
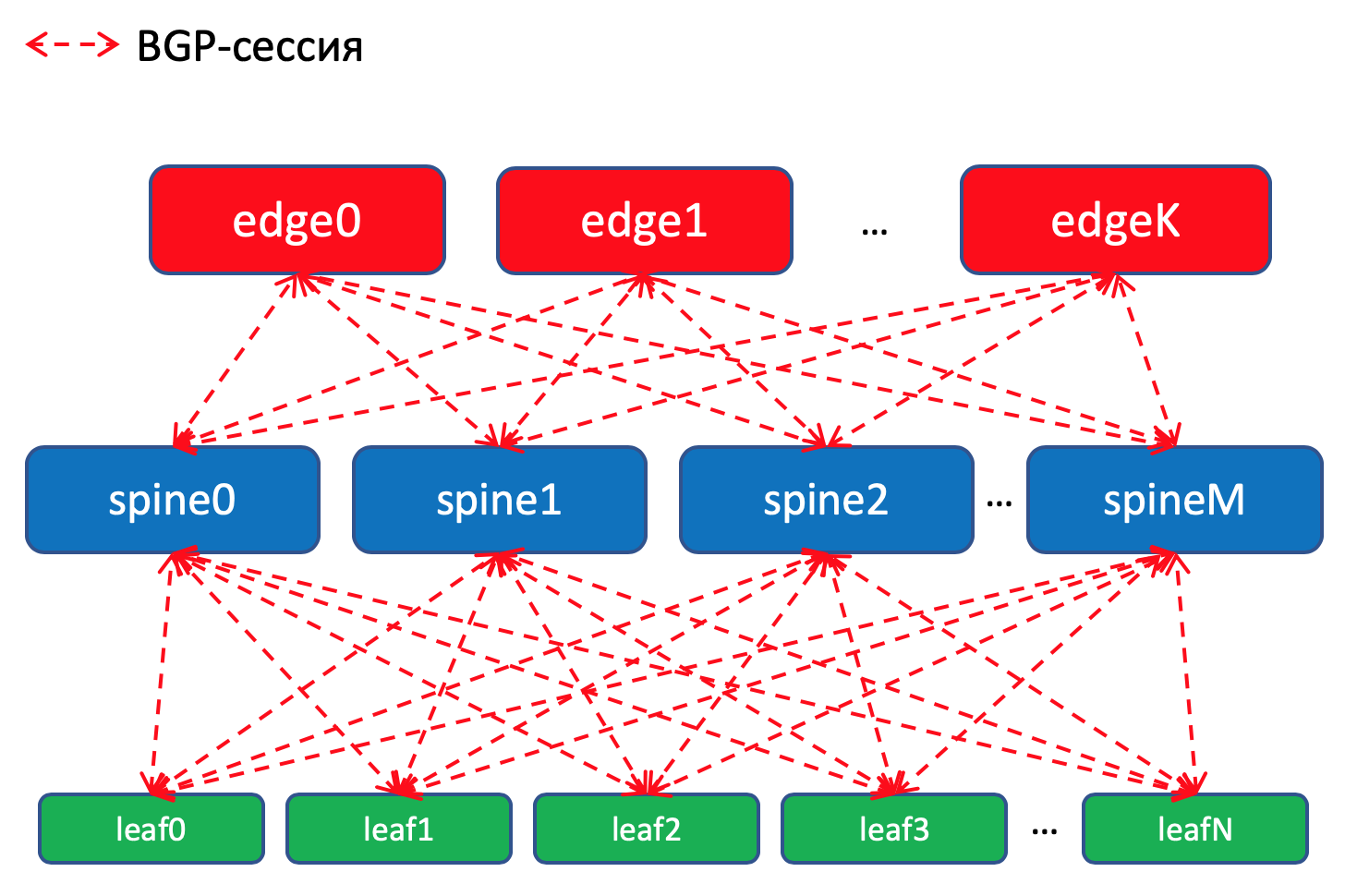 Schéma de routage BGP à l'intérieur du DCPourquoi BGP?
Schéma de routage BGP à l'intérieur du DCPourquoi BGP?Il existe
tout un RFC nommé Facebook et Arista à ce sujet, qui explique comment construire de
très grands réseaux de centres de données à l'aide de BGP. Il se lit presque comme un art, vivement recommandé pour une soirée langoureuse.
Et toute une section de mon article y est consacrée. Où je
t'envoie .
Mais, en bref, aucun IGP ne convient aux réseaux de grands centres de données, où comptent des milliers de périphériques réseau.
De plus, l'utilisation de BGP partout vous permet de ne pas pulvériser sur le support de plusieurs protocoles différents et la synchronisation entre eux.
La main sur le cœur, dans notre usine, qui avec un haut degré de probabilité ne se développera pas rapidement, l'OSPF suffirait aux yeux. Ce sont en fait les problèmes des mégascaleurs et des titans du cloud. Mais imaginons quelques problèmes dont nous avons besoin, et nous utiliserons BGP, comme l’a légué Peter Lapukhov.
Stratégies de routage
Sur les commutateurs Leaf, nous importons dans les préfixes BGP des interfaces Underlay avec les réseaux.
Nous aurons une session BGP entre
chaque paire Leaf-Spine dans laquelle ces préfixes Underlay seront annoncés sur un réseau de flaques d'eau.

Dans un centre de données, nous distribuerons les spécificités qui ont été importées dans ToRe. Sur Edge-Leafs, nous les agrégerons et les annoncerons dans les contrôleurs de domaine distants et les abaisserons en ToR. C'est-à-dire que chaque ToR saura exactement comment se rendre à un autre ToR dans le même DC et où est le point d'entrée pour accéder au ToR dans un autre DC.
Dans DCI, les itinéraires seront transmis en tant que VPNv4. Pour ce faire, sur l'Edge-Leaf, l'interface vers l'usine sera placée dans VRF, appelons-la UNDERLAY, et le quartier avec Spine sur l'Edge-Leaf augmentera à l'intérieur du VRF, et entre les Edge-Leafs de la famille VPNv4.
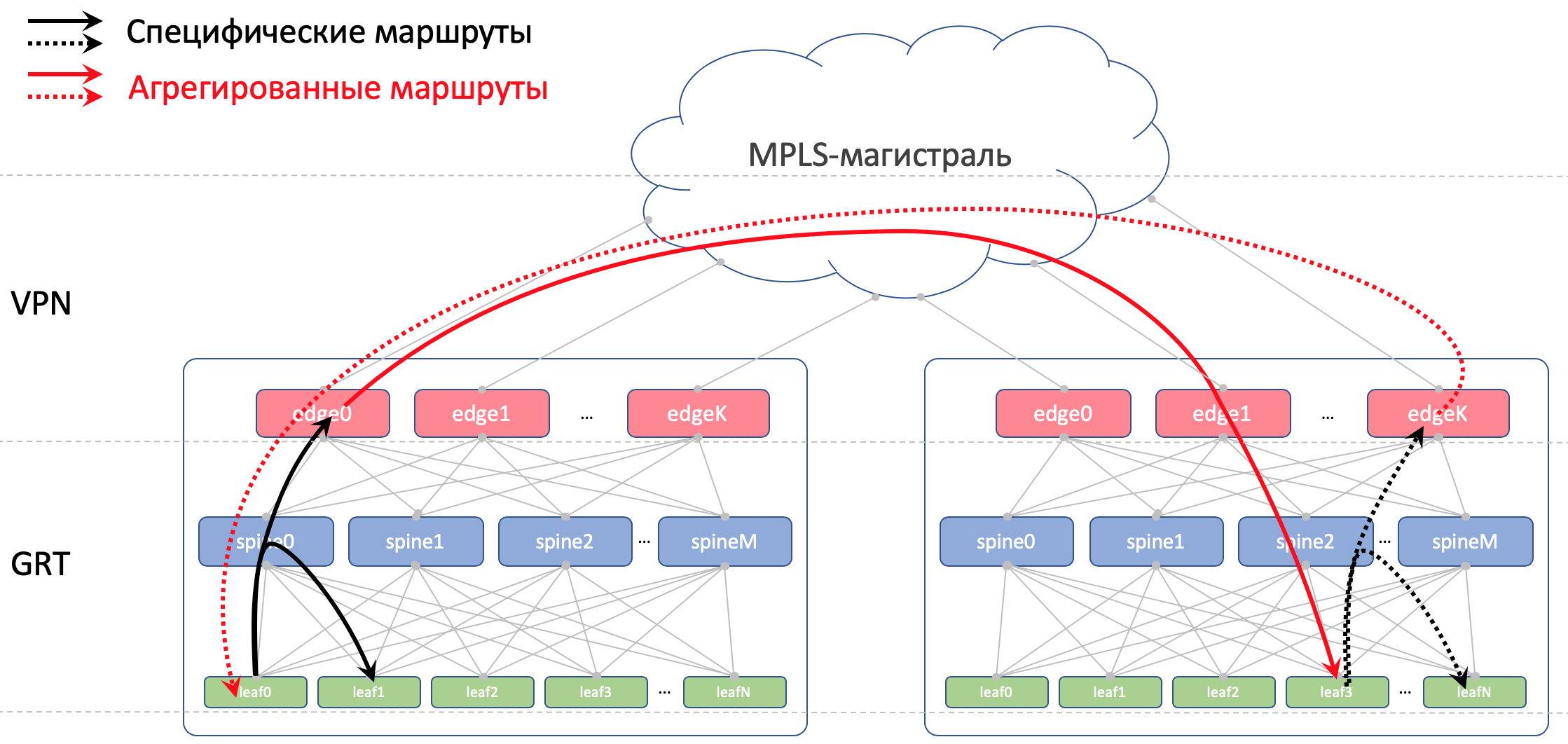
Et nous interdirons également de réannoncer les itinéraires reçus des épines, de retour vers eux.
Sur Leaf and Spine, nous n'importerons pas de boucles. Nous en avons besoin uniquement pour déterminer l'ID du routeur.
Mais sur Edge-Leafs, nous l'importons dans Global BGP. Entre les adresses de bouclage, Edge Leafs établira une session BGP dans la famille VPN IPv4 entre elles.
Entre les appareils EDGE, nous aurons une dorsale OSPF + LDP. Le tout dans une seule zone. Configuration extrêmement simple.
Voici une photo du routage.
BGP ASN
Edge-Leaf ASN
Sur les Edge-Leafs, il y aura un ASN dans tous les DC. Il est important qu'il y ait un iBGP entre les Edge-Leafs et que nous ne rencontrions pas les nuances de l'eBGP. Soit 65535. En réalité, ce pourrait être un numéro AS public.
Spine ASN
Chez Spine, nous aurons un ASN par DC. Commençons ici par le tout premier numéro de la gamme AS privée - 64512, 64513 Et ainsi de suite.
Pourquoi l'ASN est-il sur DC?
Nous décomposons cette question en deux:
- Pourquoi les mêmes ASN sur toutes les épines du même DC?
- Pourquoi sont-ils différents dans différents DC?
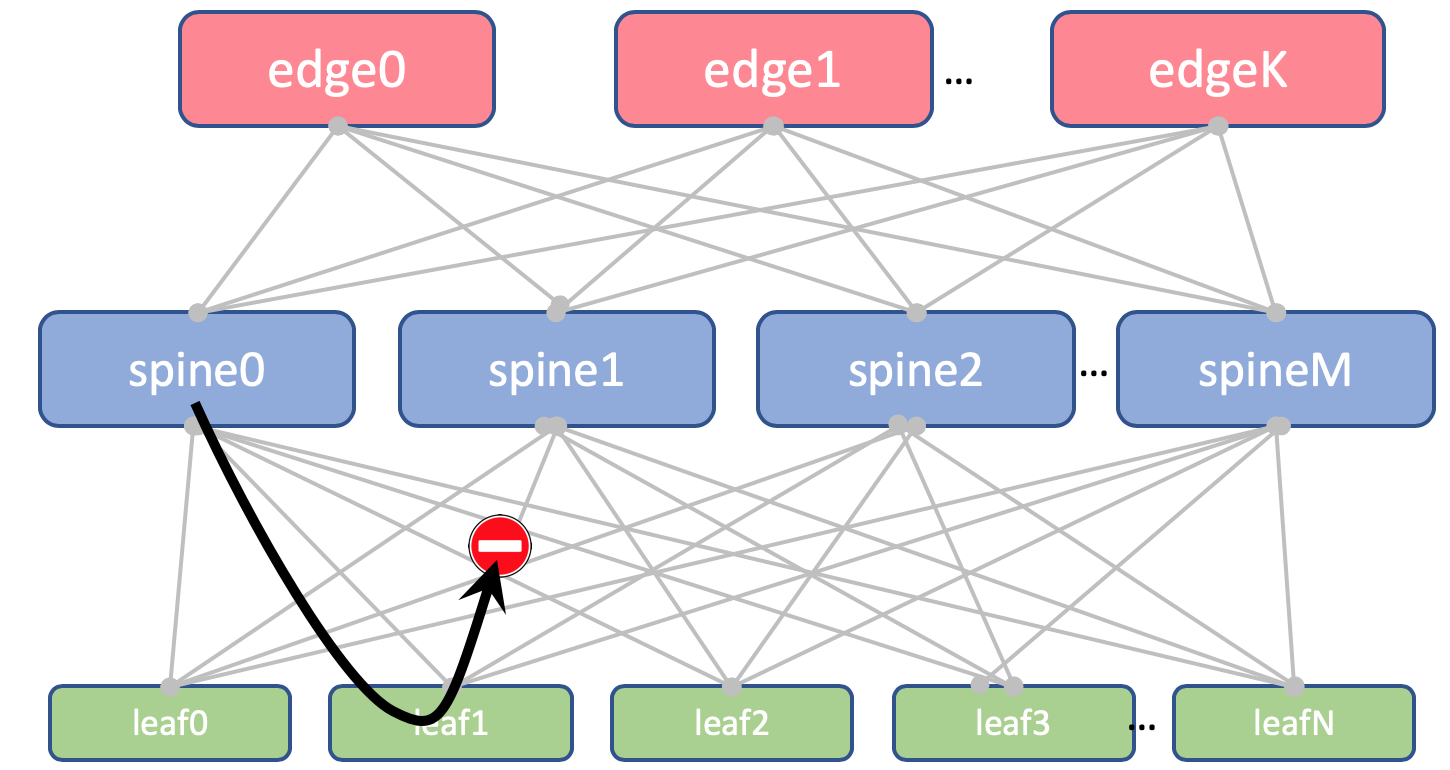
Pourquoi les mêmes ASN sur toutes les épines d'un DCVoici à quoi ressemblera l'itinéraire AS-Path Anderlay sur Edge-Leaf:
[leafX_ASN, spine_ASN , edge_ASN]Si vous essayez de l'annoncer à Spine, il le supprimera car son AS (Spine_AS) est déjà sur la liste.
Cependant, au sein du DC, nous sommes entièrement convaincus que les itinéraires Underlay qui ont grimpé jusqu'à Edge ne pourront pas descendre. Toutes les communications entre les hôtes au sein du contrôleur de domaine doivent se produire au niveau de la colonne vertébrale.
Dans le même temps, les routes agrégées d'autres DC en tout cas atteindront librement les ToR - dans leur AS-Path, il n'y aura que ASN 65535 - le nombre d'AS Edge-Leafs, car c'est sur eux qu'ils ont été créés.
Pourquoi sont différents dans différents DCThéoriquement, nous pourrions avoir besoin de faire glisser les boucles et certaines machines virtuelles de service entre les contrôleurs de domaine.
Par exemple, sur l'hôte, nous exécuterons un réflecteur de route ou
le même VNGW (passerelle de réseau virtuel), qui sera verrouillé avec ToR via BGP et annoncera son bouclage, qui devrait être disponible sur tous les contrôleurs de domaine.
Voici donc à quoi ressemblera son AS-Path:
[VNF_ASN, leafX_DC1_ASN, spine_DC1_ASN , edge_ASN, spine_DC2_ASN , leafY_DC2_ASN]Et ici, il ne devrait y avoir aucun ASN en double nulle part.
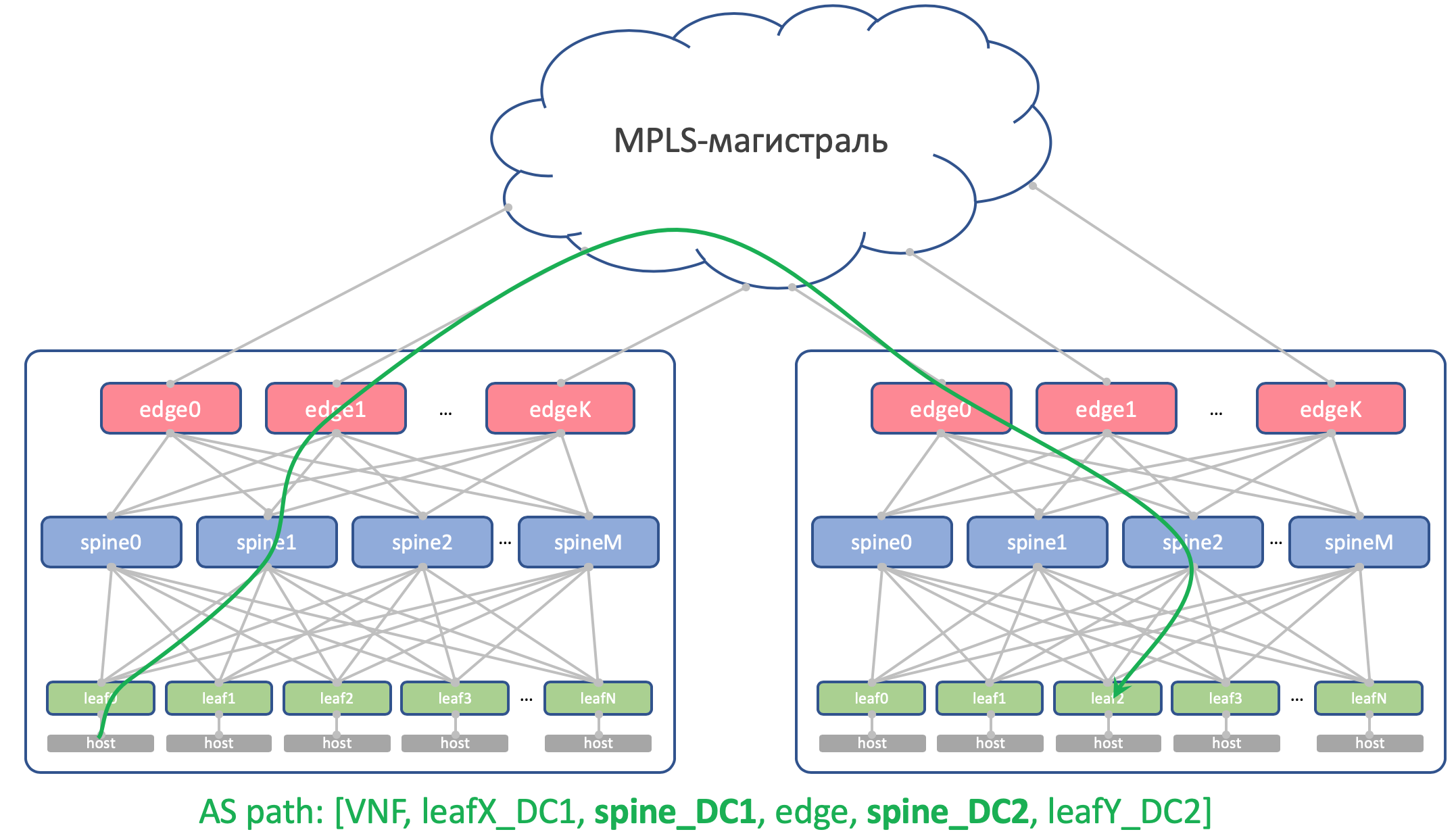
Autrement dit, Spine_DC1 et Spine_DC2 devraient être différents, tout comme leafX_DC1 et leafY_DC2, ce qui est exactement ce que nous approchons.
Comme vous le savez probablement, il existe des hacks qui vous permettent d'accepter des routes avec des ASN répétitifs contrairement au mécanisme de prévention de boucle (allowas-in sur Cisco). Et il a même des utilisations tout à fait légitimes. Mais il s'agit d'une violation potentielle de la résilience du réseau. Et je suis personnellement tombé dedans à quelques reprises.
Et si nous avons la possibilité de ne pas utiliser de choses dangereuses, nous l’utiliserons.
Leaf asn
Nous aurons un ASN individuel sur chaque commutateur Leaf du réseau.
Nous le faisons pour les raisons indiquées ci-dessus: AS-Path sans boucles, configuration BGP sans signets.
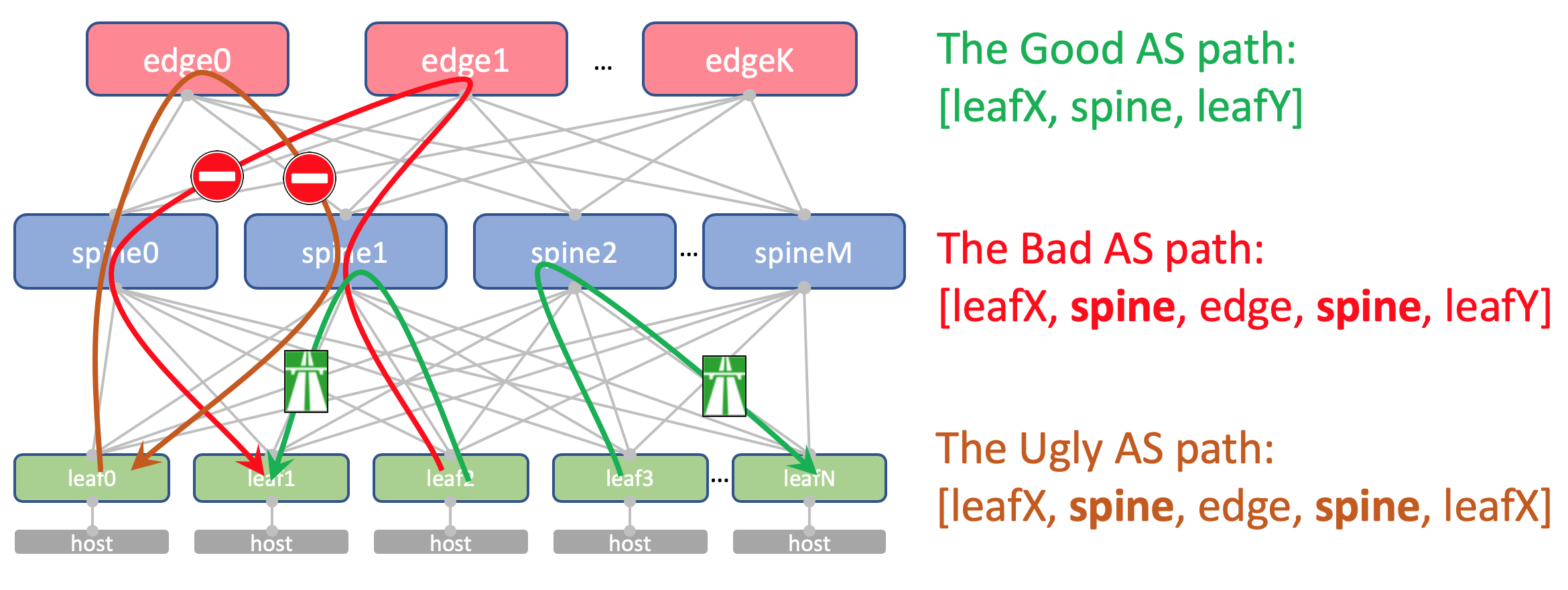
Pour que les routes entre Leafs passent sans entrave, AS-Path devrait ressembler à ceci:
[leafX_ASN, spine_ASN, leafY_ASN]où leafX_ASN et leafY_ASN serait bien d'être différent.
Ceci est également requis pour la situation avec l'annonce du bouclage VNF entre les contrôleurs de domaine:
[VNF_ASN, leafX_DC1_ASN , spine_DC1_ASN, edge_ASN, spine_DC2_ASN, leafY_DC2_ASN ]Nous allons utiliser un ASN à 4 octets et le générer en fonction de l'ASN de Spine et du numéro de commutateur de feuille, à savoir, comme ceci:
Spine_ASN.0000X .
Voici une photo avec l'ASN.
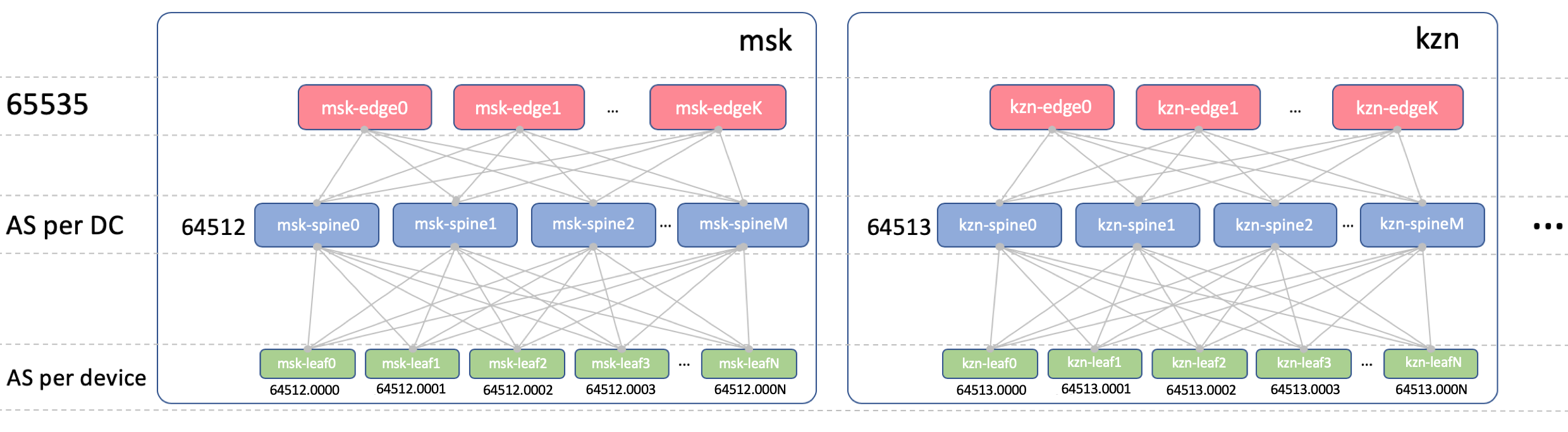
Plan IP
Fondamentalement, nous devons allouer des adresses pour les connexions suivantes:
- Les adresses réseau sous-jacentes entre ToR et la machine. Ils doivent être uniques sur tout le réseau afin que toute machine puisse communiquer avec une autre. Idéal pour 10/8 . Pour chaque rack / 26 avec une marge. Nous allouerons / 19 pour DC et / 17 pour la région.
- Liez les adresses entre Leaf / Tor et Spine.
Je voudrais les attribuer de manière algorithmique, c'est-à-dire calculer à partir des noms des appareils qui doivent être connectés.
Que ce soit ... 169.254.0.0/16.
A savoir, 169.254.00X.Y / 31 , où X est le numéro Spine, Y est le réseau P2P / 31.
Cela vous permettra d'exécuter jusqu'à 128 racks et jusqu'à 10 Spine dans le DC. Les adresses de liaison peuvent (et seront) répétées de DC à DC. - Nous organisons le joint Spine - Edge-Leaf sur les sous- réseaux 169.254.10X.Y / 31 , où de la même manière X est le numéro Spine, Y est le réseau P2P / 31.
- Liez les adresses de l'Edge-Leaf à la dorsale MPLS. Ici, la situation est quelque peu différente - le lieu de connexion de toutes les pièces en un seul, donc la réutilisation des mêmes adresses ne fonctionnera pas - vous devez sélectionner le prochain sous-réseau gratuit. Par conséquent, nous prendrons 192.168.0.0/16 comme base et nous en retirerons des extraits gratuits.
- Adresses de bouclage. Donnez-leur toute la gamme 172.16.0.0/12 .
- Feuille - à / 25 par DC - les mêmes 128 racks. Attribuer par / 23 à la région.
- Colonne vertébrale - par / 28 au DC - jusqu'à 16 vertèbres. Attribuer par / 26 à la région.
- Edge-Leaf - par / 29 sur DC - jusqu'à 8 boîtes. Attribuer par / 27 à la région.
Si dans le DC, nous n'avons pas assez de plages sélectionnées (mais elles ne seront pas là - nous prétendons être hyper-skeylerostvo), sélectionnez simplement le bloc suivant.
Voici une image avec l'adressage IP.

Bouclages:
| Préfixe | Rôle d'appareil | Région | DC |
| 172.16.0.0/23 | bord | | |
| 172.16.0.0/27 | ru | |
| 172.16.0.0/29 | msk |
| 172.16.0.8/29 | kzn |
| 172.16.0.32/27 | sp | |
| 172.16.0.32/29 | bcn |
| 172.16.0.40/29 | mlg |
| 172.16.0.64/27 | cn | |
| 172.16.0.64/29 | sha |
| 172.16.0.72/29 | sia |
| 172.16.2.0/23 | dos | | |
| 172.16.2.0/26 | ru | |
| 172.16.2.0/28 | msk |
| 172.16.2.16/28 | kzn |
| 172.16.2.64/26 | sp | |
| 172.16.2.64/28 | bcn |
| 172.16.2.80/28 | mlg |
| 172.16.2.128/26 | cn | |
| 172.16.2.128/28 | sha |
| 172.16.2.144/28 | sia |
| 172.16.8.0/21 | feuille | | |
| 172.16.8.0/23 | ru | |
| 172.16.8.0/25 | msk |
| 172.16.8.128/25 | kzn |
| 172.16.10.0/23 | sp | |
| 172.16.10.0/25 | bcn |
| 172.16.10.128/25 | mlg |
| 172.16.12.0/23 | cn | |
| 172.16.12.0/25 | sha |
| 172.16.12.128/25 | sia |
Sous-couche:
| Préfixe | Région | DC |
| 10.0.0.0/17 | ru | |
| 10.0.0.0/19 | msk |
| 10.0.32.0/19 | kzn |
| 10.0.128.0/17 | sp | |
| 10.0.128.0/19 | bcn |
| 10.0.160.0/19 | mlg |
| 10.1.0.0/17 | cn | |
| 10.1.0.0/19 | sha |
| 10.1.32.0/19 | sia |
Laba
Deux vendeurs. Un réseau. ADSM.
Juniper + Arista. Ubuntu Bonne vieille Eve.
La quantité de ressources sur notre virtuel à Miran est encore limitée, donc pour la pratique, nous utiliserons un tel réseau simplifié à la limite.
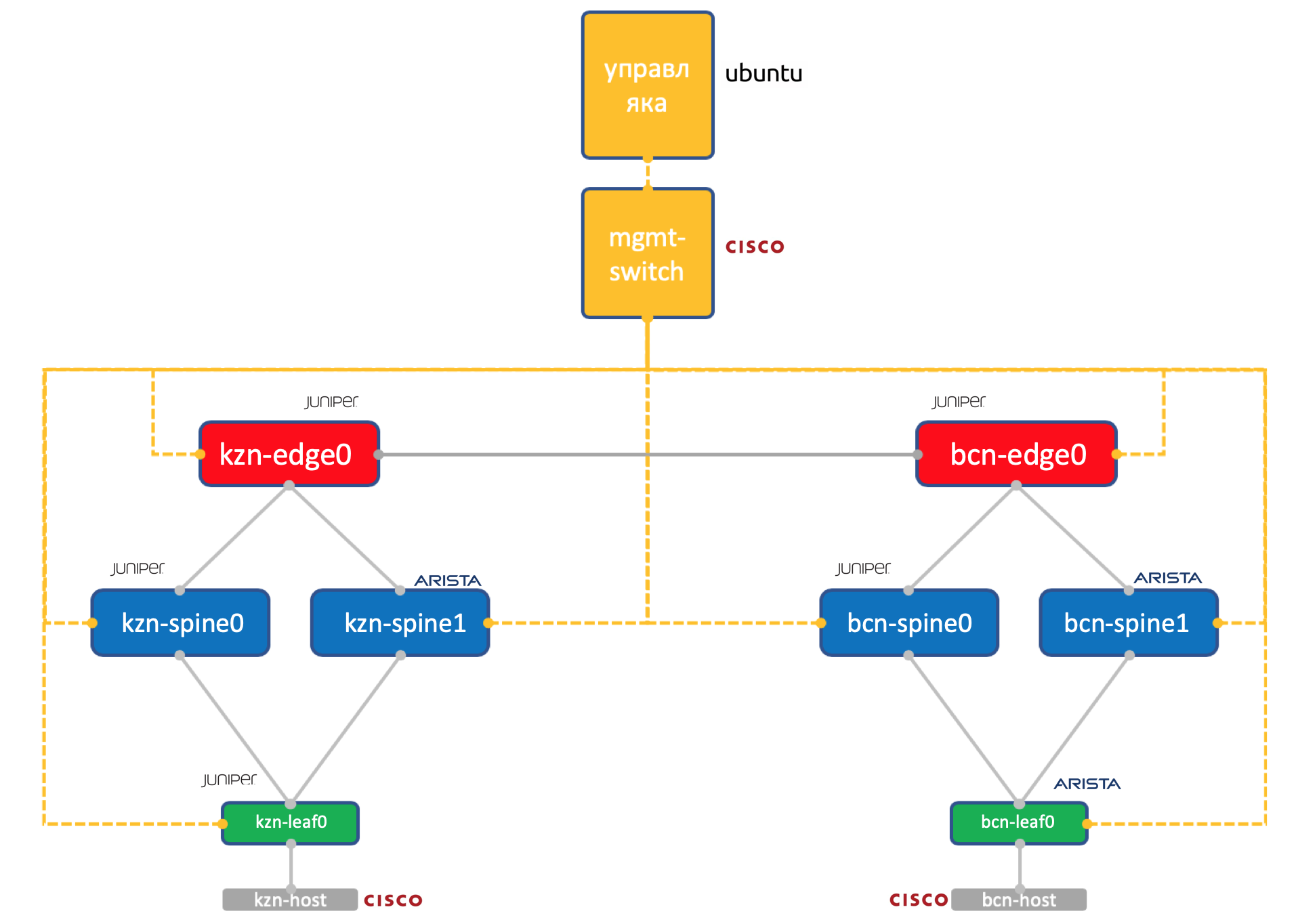
Deux centres de données: Kazan et Barcelone.
- Deux épines dans chacune: Juniper et Arista.
- Un tore (feuille) dans chacun - Juniper et Arista, avec un hôte connecté (prenons pour cela la légère IOL Cisco).
- Un nœud Edge-Leaf (jusqu'à présent Juniper uniquement).
- Un commutateur Cisco pour les gouverner tous.
- En plus des boîtiers réseau, une machine virtuelle de gestion a été lancée. Exécuter Ubuntu.
Il a accès à tous les appareils, aux systèmes IPAM / DCIM, à un tas de scripts Python, ansible et à tout ce dont nous pourrions avoir besoin.
La configuration complète de tous les périphériques réseau que nous allons essayer de reproduire en utilisant l'automatisation.
Conclusion
Aussi accepté? Sous chaque article pour faire une courte conclusion?
Nous avons donc choisi le réseau Klose à
trois niveaux à l'intérieur du DC, car nous attendons beaucoup de trafic Est-Ouest et voulons ECMP.
Nous avons divisé le réseau en physique (sous-couche) et virtuel (superposition). Dans ce cas, la superposition commence à partir de l'hôte - simplifiant ainsi les exigences pour la sous-couche.
Nous avons choisi BGP comme protocole de routage pour les réseaux non relayés pour son évolutivité et la flexibilité des politiques.
Nous aurons des nœuds séparés pour l'organisation DCI - Edge-leaf.
Il y aura OSPF + LDP sur le tronc.
DCI sera implémenté sur la base de MPLS L3VPN.
Pour les liaisons P2P, nous calculerons les adresses IP de manière algorithmique en fonction des noms des appareils.
Les lupbacks seront attribués en fonction du rôle des périphériques et de leur emplacement de manière séquentielle.
Préfixes de calque sous-jacent - uniquement sur les commutateurs Leaf séquentiellement en fonction de leur emplacement.
Supposons que nous n'ayons pas installé l'équipement pour le moment.
Par conséquent, nos prochaines étapes seront de les intégrer dans les systèmes (IPAM, inventaire), d'organiser l'accès, de générer une configuration et de la déployer.
Dans le prochain article, nous traiterons de Netbox, le système de gestion de l'inventaire et de l'espace IP dans le DC.
Merci
- Andrey Glazkov aka @glazgoo pour la relecture et l'édition
- Alexander Klimenko aka @ v00lk pour la relecture et l'édition
- Artyom Chernobay pour KDPV