Aujourd'hui, nous voulons parler du concept Insight-Driven et comment le mettre en pratique à l'aide de DataOps et ModelOps. L'approche Insight-Driven est un sujet complet dont nous parlons en détail dans notre bibliothèque récemment créée de documents utiles sur la gestion des données (le lien sera ci-dessous). Dans le habratopica d'aujourd'hui, nous nous concentrerons sur les étapes clés du cycle de vie des modèles d'apprentissage automatique, comme C'est l'un des principaux sujets du concept.

Quelle est l'essence de l'approche Insight-Driven
De nombreux experts parlent de l'importance du
Data-Driven depuis longtemps, ce qui, bien sûr, est absolument correct en général, car cette approche implique de prendre des décisions de gestion plus efficaces en analysant les données, et pas seulement l'intuition et l'expérience de leadership personnel. Les analystes de Forrester
notent que les entreprises qui s'appuient sur l'analyse de données dans leurs activités croissent en moyenne 30% plus vite que leurs concurrents.
Mais nous comprenons tous que l'entreprise va de l'avant non pas de la disponibilité des données en tant que telles, mais de la capacité de travailler avec elles - c'est-à-dire de trouver des informations qui peuvent être monétisées et pour lesquelles cela vaut la peine d'accumuler, de traiter et d'analyser des données. Par conséquent, nous parlons spécifiquement de l'approche Insight-Driven, en tant que version plus avancée de Data-Driven.
Le plus souvent, lorsqu'il s'agit de travailler avec des données, la plupart des spécialistes parlent principalement d'informations structurées au sein de l'entreprise, mais il n'y a pas si longtemps, nous avons expliqué pourquoi la grande majorité des entreprises n'utilisaient pas environ 80% des données potentiellement disponibles. Insight-Driven crée simplement la base pour compléter l'image avec des informations externes non structurées, ainsi que les résultats de l'interprétation des données pour rechercher des dépendances implicites entre eux.
Le lien promis vers une bibliothèque complète de documents sur la gestion des données , où se trouve la vidéo mentionnée sur les données inutilisées.
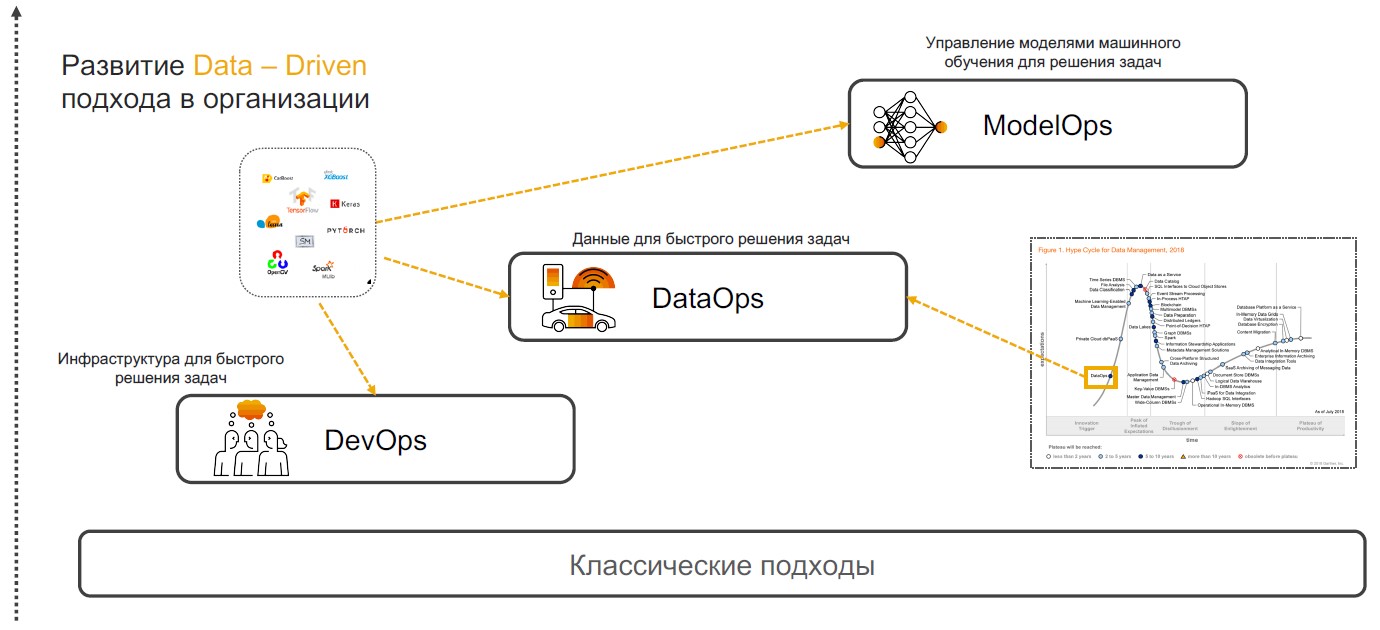
DevOps + DataOps + ModelOps
Les pratiques Insight-Driven sont basées sur DevOps, DataOps et ModelOps. Voyons pourquoi une combinaison de ces pratiques particulières est en mesure d'assurer la pleine mise en œuvre de l'approche.
 DevOps + DataOps
DevOps + DataOps . DevOps implique de réduire le temps de sortie du produit, ses mises à jour et de minimiser le coût d'une assistance supplémentaire grâce à l'utilisation d'outils de contrôle de version, d'intégration continue, de test et de surveillance, de gestion des versions. Si nous ajoutons à ces pratiques une compréhension des données à l'intérieur de l'entreprise, comment gérer leur format et leur structure, étiqueter, suivre la qualité, la transformation, l'agrégation et avoir la capacité d'analyser et de visualiser rapidement, alors nous obtenons
DataOps . L'objectif de cette approche est la mise en œuvre de scénarios utilisant des modèles d'apprentissage automatique qui fournissent une aide à la décision, une recherche et une prévision.
ModelOps . Dès que l'entreprise commence à utiliser activement les modèles d'apprentissage automatique, il devient nécessaire de les gérer, de surveiller les mesures de qualité, de recycler, de comparer, de mettre à jour et de version. ModOps est un ensemble de pratiques et d'approches qui simplifient la gestion du cycle de vie de ces modèles. Il est utilisé par les entreprises qui traitent un grand nombre de modèles dans divers domaines de l'entreprise, par exemple les services de streaming.
La mise en œuvre de l'approche Insight-Driven dans une entreprise n'est pas une tâche triviale. Mais pour ceux qui voudraient encore commencer à travailler avec lui, nous vous expliquerons comment procéder.
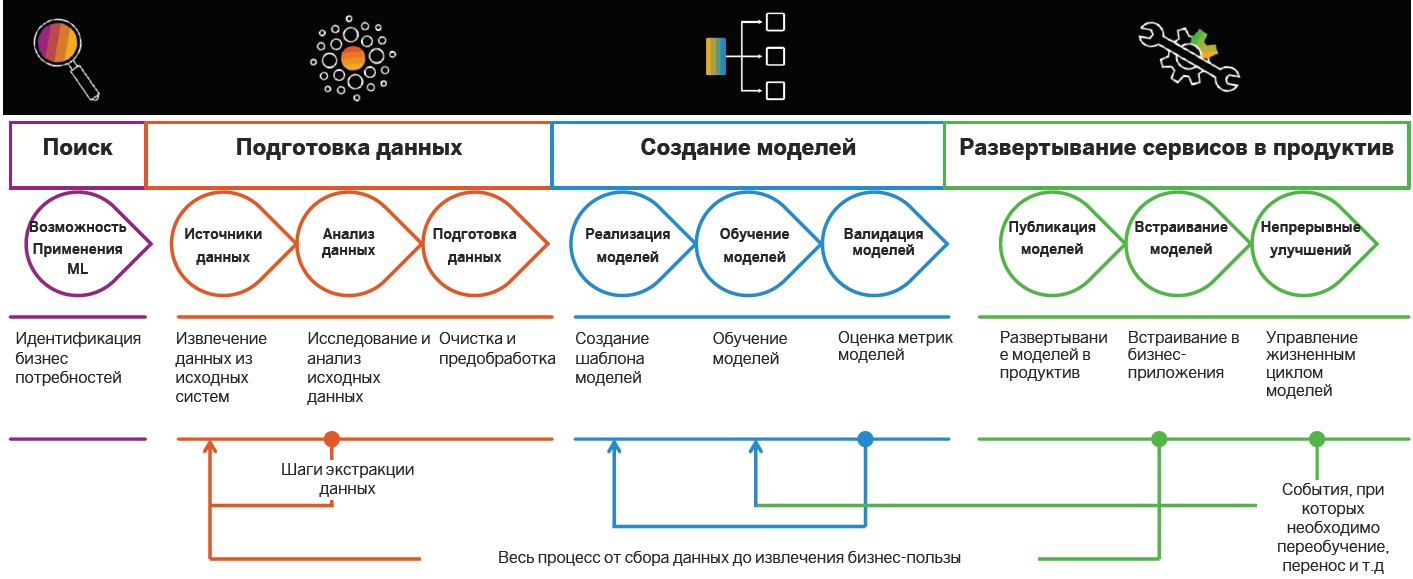
Recherche et préparation des données
La mise en œuvre des pratiques Insight-Driven commence par la recherche et la préparation des données. Plus tard, ils sont analysés et utilisés pour construire des modèles de MO, mais des cas sont préalablement déterminés dans lesquels des algorithmes intelligents peuvent être utiles.
Définition des tâches . À ce stade, l'entreprise fixe des objectifs commerciaux, par exemple, l'augmentation des bénéfices sur le marché. Ensuite, les mesures commerciales sont déterminées pour les atteindre, telles qu'une augmentation du nombre de nouveaux clients, la taille du chèque moyen et le pourcentage de conversion. Il existe donc des scénarios dans lesquels il est déjà possible de rechercher des données pertinentes.
 Sourcing et analyse des données
Sourcing et analyse des données . Lorsque les objectifs et les directions pour la récupération des données sont définis, le moment est venu d'analyser les sources. Ceci et les étapes ultérieures du développement de scénarios intelligents liés à la préparation
prennent 70 à 80% des budgets des entreprises dans la mise en œuvre. Le fait est que la qualité de l'ensemble de données affecte la précision des modèles d'apprentissage automatique conçus. Mais les informations nécessaires sont souvent "dispersées" sur différents systèmes - elles peuvent se trouver dans des bases de données relationnelles, telles que MS SQL, Oracle, PostgreSQL, sur la plate-forme Hadoop et de nombreuses autres sources. Et à ce stade, vous devez comprendre où se trouvent les données pertinentes et comment les collecter.
Souvent, les analystes déchargent et traitent tout manuellement, ce qui ralentit considérablement les processus et augmente le risque d'erreurs. Chez SAP, nous proposons à nos clients de mettre en œuvre un méta-système qui se connecte aux bonnes sources et collecte des données sur demande.
Ainsi, vous pouvez cataloguer toutes les tables, les pools externes avec des données non structurées et d'autres sources - définir des balises (y compris hiérarchiques) et collecter rapidement des informations pertinentes. Conditionnellement, si les informations sur un client se trouvent dans différentes bases de données, il suffit d'indiquer ces entités. La prochaine fois que vous aurez besoin d'un «ensemble de données client», vous choisirez une vitrine prête à l'emploi.
Une fois les sources de données identifiées, vous pouvez passer
au suivi et au profilage de la qualité des données . Cette opération est nécessaire pour comprendre le nombre de lacunes, les valeurs uniques et vérifier la qualité globale des données. Pour tout cela, vous pouvez créer des tableaux de bord avec des règles et suivre les modifications.
Transformation des données . L'étape suivante consiste à travailler directement avec des données qui devraient résoudre les tâches. Pour ce faire, les données sont effacées: vérifiées, dédupliquées, comblées. Ce processus peut être simplifié avec une programmation basée sur les flux. Dans ce cas, nous avons affaire à une séquence d'opérations - un pipeline. Sa sortie peut être envoyée à une interface graphique ou à un autre système pour un travail ultérieur. Ici, les gestionnaires de données sont assemblés en tant que constructeur (et selon le scénario). Il peut s'agir d'un traitement périodique ou en continu, ou d'un service REST.

Le concept de programmation basée sur les flux convient pour résoudre un large éventail de tâches: de la prévision des ventes et de l'évaluation de la qualité du service à la recherche des raisons de la sortie des clients. Il existe deux outils pour rechercher et préparer des données dans SAP. Le premier est
SAP Data Intelligence pour les analystes de données. Contrairement aux plates-formes similaires, cette solution fonctionne avec des données distribuées et ne nécessite pas de centralisation - elle fournit un environnement unifié pour l'implémentation, la publication, l'intégration, la mise à l'échelle et la prise en charge des modèles. Le deuxième outil est
SAP Agile Data Preparation , un petit service de préparation de données destiné aux analystes et aux utilisateurs professionnels. Il possède une interface simple qui permet de collecter un ensemble de données, de filtrer, de traiter et de cartographier les informations. Il peut être publié dans une vitrine pour le transfert de Self-Service BI - des systèmes en libre-service pour la création de scénarios analytiques (ils ne nécessitent pas de connaissances approfondies dans le domaine de la science des données).
Création de modèle
Après la préparation, c'est au tour de créer des modèles d'apprentissage automatique. On distingue ici: la recherche, le prototypage et la productivité. La dernière étape comprend la mise en place de pipelines pour la formation et l'application de modèles.
Recherche et prototypage . Actuellement, il existe de nombreux cadres thématiques et bibliothèques disponibles. Les leaders de la fréquence d'utilisation sont TensorFlow et PyTorch, dont la popularité au cours de la dernière année a
augmenté de 243%. La plateforme SAP vous permet d'utiliser n'importe lequel de ces cadres et peut être complétée de manière flexible avec des bibliothèques telles que CatBoost de Yandex, LightGBM de Microsoft, scikit-learn et pandas. Vous pouvez toujours utiliser le
HANA DataFrame dans la bibliothèque hanaml. Cette API imite les pandas et HANA vous permet de traiter de grandes quantités de données à l'aide de «l'informatique paresseuse».
Pour les modèles de prototypage, nous proposons Jupyter Lab. Il s'agit d'un outil open source pour les professionnels de la science des données. Nous l'avons intégré à l'écosystème SAP, tout en élargissant les fonctionnalités. Jupyter Lab fonctionne dans la plate-forme Data Intelligence et grâce à la bibliothèque sapdi intégrée, il peut se connecter à toutes les sources de données connectées aux étapes précédentes, surveiller les expériences et les mesures de qualité pour une analyse plus approfondie.
Par ailleurs, il convient de noter que les blocs-notes, les jeux de données,
les pipelines de formation et d'
inférence , ainsi que les services de déploiement de modèles doivent être cohérents. Pour combiner tous ces objets, utilisez le script ML (objet versionné).
Formation de modèle . Il existe deux options pour travailler avec des scripts ML. Il existe des modèles qui n'ont pas du tout besoin d'être formés. Par exemple, dans SAP Data Intelligence, nous proposons des systèmes de reconnaissance faciale, la traduction automatique, l'OCR (reconnaissance optique de caractères) et autres. Ils fonctionnent tous hors de la boîte. D'un autre côté, il y a ces modèles qui doivent être formés et productifs. Cette formation peut avoir lieu à la fois dans le cluster Data Intelligence lui-même et sur des ressources informatiques externes qui ne sont connectées que pendant la durée des calculs.
"Sous le capot" dans SAP Data Intelligence est la plate-forme Kubernetes, de sorte que tous les opérateurs sont liés aux conteneurs Docker. Pour travailler avec le modèle, il suffit de décrire le fichier docker et d'y attacher des balises pour les bibliothèques et les versions utilisées.
Une autre façon de créer des modèles est avec AutoML. Ce sont des systèmes MO automatisés. Ces outils sont développés par
H2O ,
Microsoft ,
Google, etc. Ils travaillent
dans ce sens
au MIT . Mais les ingénieurs universitaires ne se concentrent pas sur l'intégration et la productivité. SAP dispose également d'un système AutoML qui se concentre sur des résultats rapides. Elle travaille à HANA et a un accès direct aux données - elles n'ont pas besoin d'être déplacées ou modifiées n'importe où. Nous développons maintenant une solution qui se concentre sur la qualité des modèles - nous annoncerons une version plus tard.
Gestion du cycle de vie . Les conditions changent, les informations deviennent obsolètes, de sorte que la précision des modèles MO diminue avec le temps. En conséquence, après avoir accumulé de nouvelles données, nous pouvons recycler le modèle et affiner les résultats. Par exemple, un grand producteur de boissons
utilise les informations sur les préférences des consommateurs dans 200 pays différents pour recycler les systèmes intelligents. L'entreprise prend en compte les goûts des gens, la quantité de sucre, la teneur en calories des boissons et même les produits que les marques concurrentes proposent sur les marchés cibles. Les modèles MO déterminent automatiquement lequel des centaines de produits l'entreprise acceptera le mieux dans une région donnée.
 Réutilisation des composants basés sur l'agent dans SAP Data Hub
Réutilisation des composants basés sur l'agent dans SAP Data HubMais la version et la mise à jour des modèles doivent également être effectuées à mesure que de nouveaux algorithmes et des mises à jour des composants matériels sont publiés. Leur mise en œuvre peut améliorer la précision et la qualité des modèles utilisés dans le travail.
Insight-Driven for Business Growth
L'approche de la gestion des étapes du cycle de vie des modèles d'apprentissage automatique décrite ci-dessus est, en fait, un cadre universel qui permet à une entreprise de devenir guidée par la perspicacité et d'utiliser le travail avec les données comme un moteur clé de la croissance de l'entreprise. Les organisations qui incarnent ce concept en savent plus, grandissent plus vite et, à notre avis, travaillent beaucoup plus intéressant dans cette technologie de pointe!
En savoir plus sur la création du concept Insight-Driven dans notre
bibliothèque de documents de gestion de données utiles , où nous avons collecté des vidéos, des brochures utiles et des accès d'essai aux systèmes SAP.