Salut, je m'appelle Eugene. Je travaille dans l'infrastructure de recherche Yandex.Market. Je veux parler à la communauté Habr de la cuisine interne du marché - mais il y a quelque chose à dire. Tout d'abord, comment fonctionnent la recherche de marché, les processus et l'architecture. Comment gérer les situations d'urgence: que se passe-t-il si un serveur tombe en panne? Et s'il y a 100 serveurs de ce type?
Vous apprendrez également comment nous implémentons immédiatement de nouvelles fonctionnalités sur un groupe de serveurs. Et comment tester des services complexes directement en production, sans déranger les utilisateurs. En général, comment fonctionne la recherche du marché, pour que tout le monde aille bien.
Un peu sur nous: quel problème résolvons-nous
Lorsque vous saisissez du texte, recherchez des produits par paramètres ou comparez les prix dans différents magasins, toutes les demandes arrivent au service de recherche. La recherche est le plus grand service du marché.
Nous traitons toutes les requêtes de recherche: depuis market.yandex.ru, beru.ru, le service Supercheck, Yandex.Advisor et les applications mobiles. Nous incluons également des offres de produits dans les résultats de recherche sur yandex.ru.
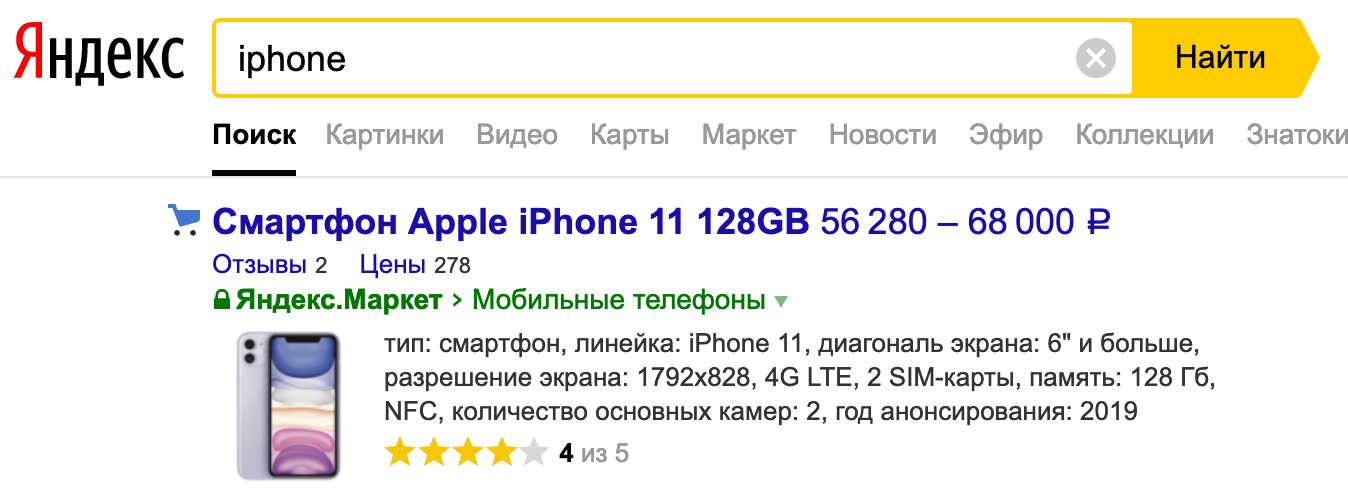
Par service de recherche, je veux dire non seulement la recherche directe, mais aussi une base de données avec toutes les offres sur le marché. L'échelle est la suivante: plus d'un milliard de requêtes de recherche sont traitées par jour. Et tout devrait fonctionner rapidement, sans interruption et toujours produire le résultat souhaité.
Qu'est-ce que: l'architecture du marché
Décrivez brièvement l'architecture actuelle du marché. Classiquement, il peut être décrit par le schéma ci-dessous:
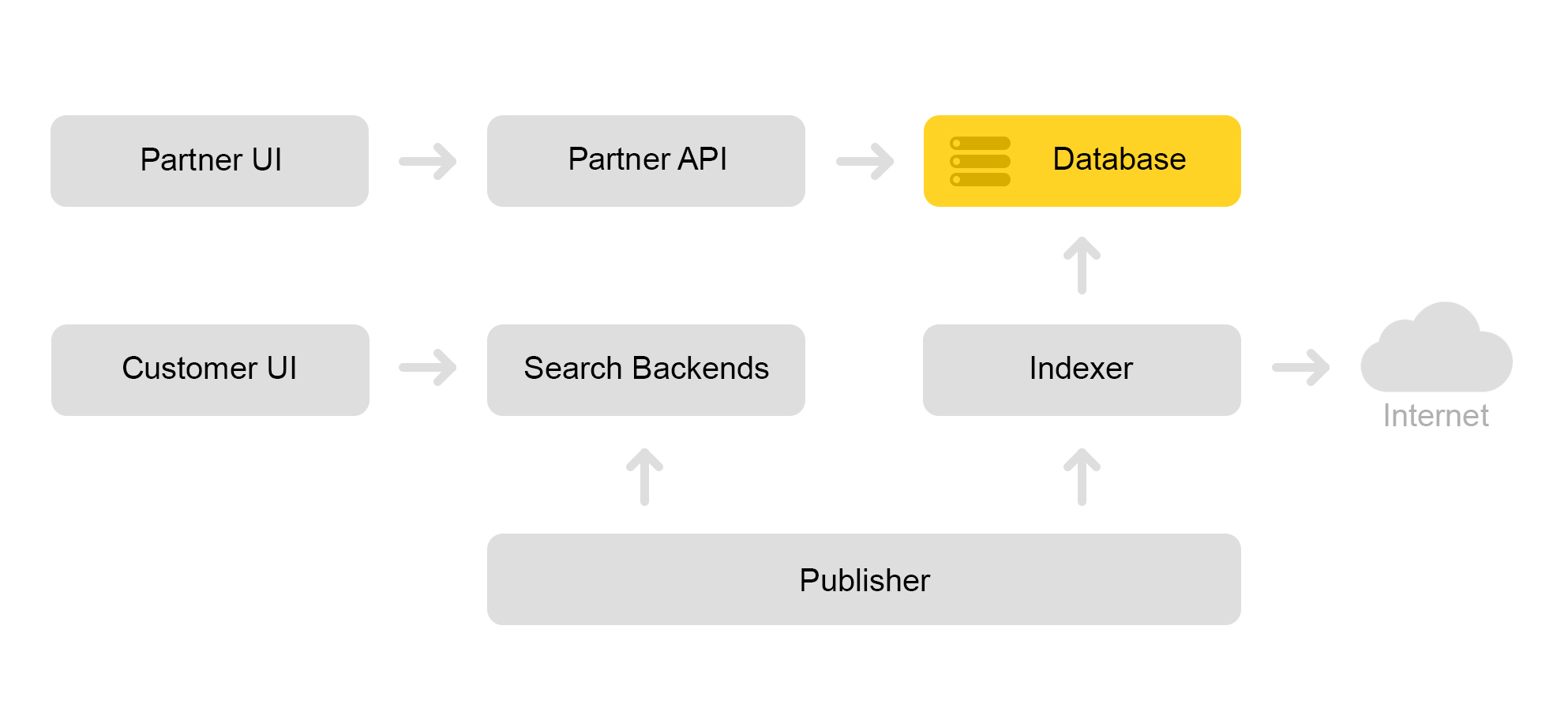
Disons qu'un magasin partenaire vient à nous. Il dit que je veux vendre un jouet: ce méchant chat avec un couineur. Et un chat diabolique sans tweeter. Et juste un chat. Ensuite, le magasin doit préparer des offres sur lesquelles le marché recherche. Le magasin forme un xml spécial avec des offres et communique le chemin vers ce xml via une interface partenaire. Ensuite, l'indexeur télécharge périodiquement ce fichier XML, vérifie les erreurs et stocke toutes les informations dans une énorme base de données.
Il existe de nombreux fichiers XML de ce type. Un index de recherche est créé à partir de cette base de données. L'index est stocké au format interne. Après avoir créé l'index, le service Layouts le télécharge sur les moteurs de recherche.
En conséquence, un chat maléfique avec un couineur apparaît dans la base de données et un index de chat apparaît sur le serveur.
Je vais parler de la façon dont nous recherchons un chat dans la partie sur l'architecture de recherche.
Architecture de recherche de marché
Nous vivons dans le monde des microservices: chaque demande entrante sur
market.yandex.ru provoque de nombreuses sous-requêtes, et des dizaines de services participent à leur traitement. Le diagramme n'en montre que quelques-uns:
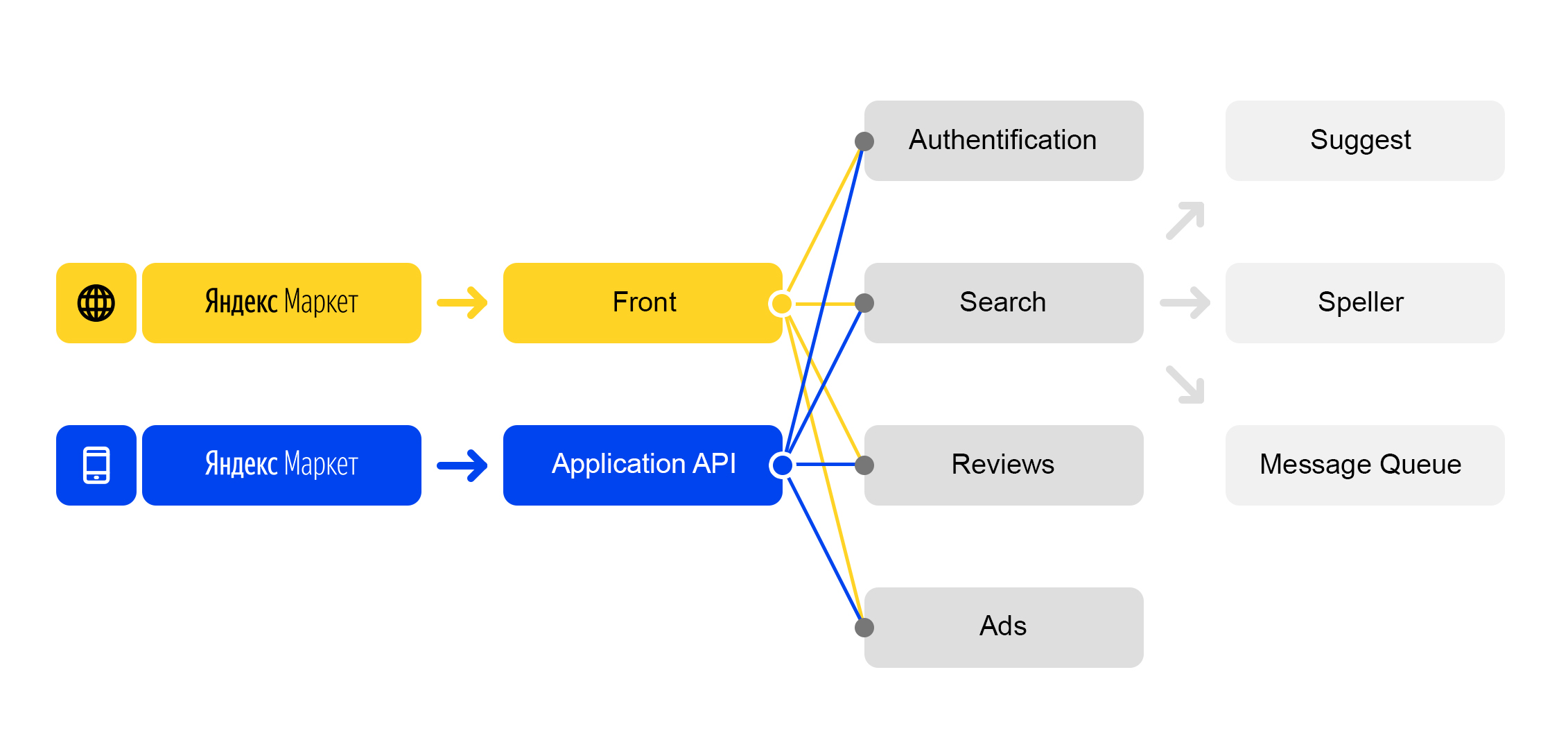 Schéma de traitement des demandes simplifié
Schéma de traitement des demandes simplifiéChaque service a une chose merveilleuse - son propre équilibreur avec un nom unique:
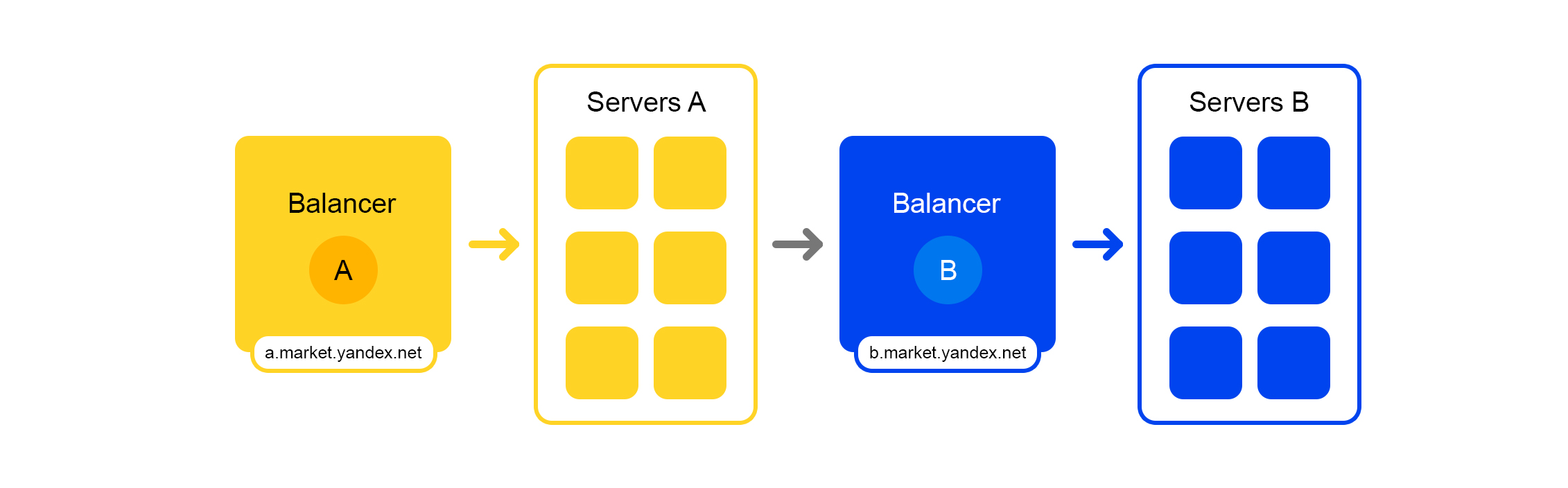
L'équilibreur nous offre une grande flexibilité dans la gestion du service: par exemple, vous pouvez désactiver les serveurs, ce qui est souvent nécessaire pour les mises à jour. L'équilibreur voit que le serveur n'est pas disponible et redirige automatiquement les demandes vers d'autres serveurs ou centres de données. Lorsque vous ajoutez ou supprimez un serveur, la charge est automatiquement redistribuée entre les serveurs.
Le nom unique de l'équilibreur ne dépend pas du centre de données. Lorsque le service A fait une demande à B, alors par défaut, l'équilibreur B redirige la demande vers le centre de données actuel. Si le service n'est pas disponible ou absent dans le centre de données actuel, la demande est redirigée vers d'autres centres de données.
Un FQDN unique pour tous les centres de données permet au service A de se désengager généralement des emplacements. Sa demande au service B sera toujours traitée. Une exception est le cas lorsque le service est dans tous les centres de données.
Mais tout n'est pas si rose avec cet équilibreur: nous avons un composant intermédiaire supplémentaire. L'équilibreur peut être instable et ce problème est résolu par des serveurs redondants. Il existe également un délai supplémentaire entre les services A et B. Mais en pratique, il est inférieur à 1 ms et pour la plupart des services, ce n'est pas critique.
Lutter contre l'inattendu: services de recherche équilibrés et résilients
Imaginez qu'un effondrement se soit produit: vous devez trouver un chat avec un couinement, mais le serveur tombe en panne. Ou 100 serveurs. Comment sortir? Allons-nous vraiment laisser l'utilisateur sans chat?
La situation est terrible, mais nous y sommes prêts. Je vais te le dire dans l'ordre.
L'infrastructure de recherche est située dans plusieurs centres de données:
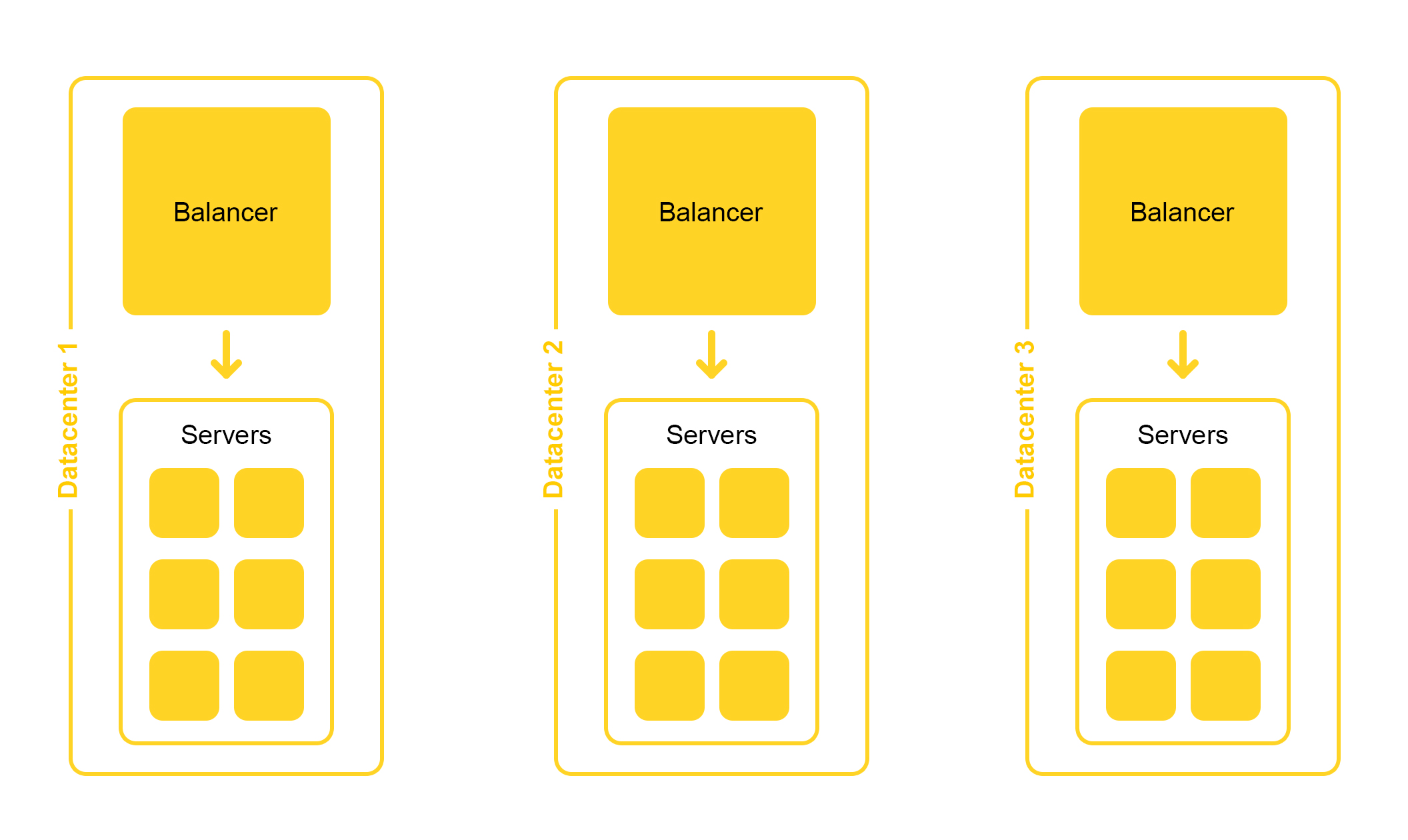
Lors de la conception, nous laissons la possibilité de désactiver un centre de données. La vie est pleine de surprises - par exemple, une excavatrice peut couper un câble souterrain (oui, c'était comme ça). Les capacités des autres centres de données devraient être suffisantes pour résister à la charge de pointe.
Prenons un seul centre de données. Dans chaque centre de données, le même schéma d'équilibreurs:
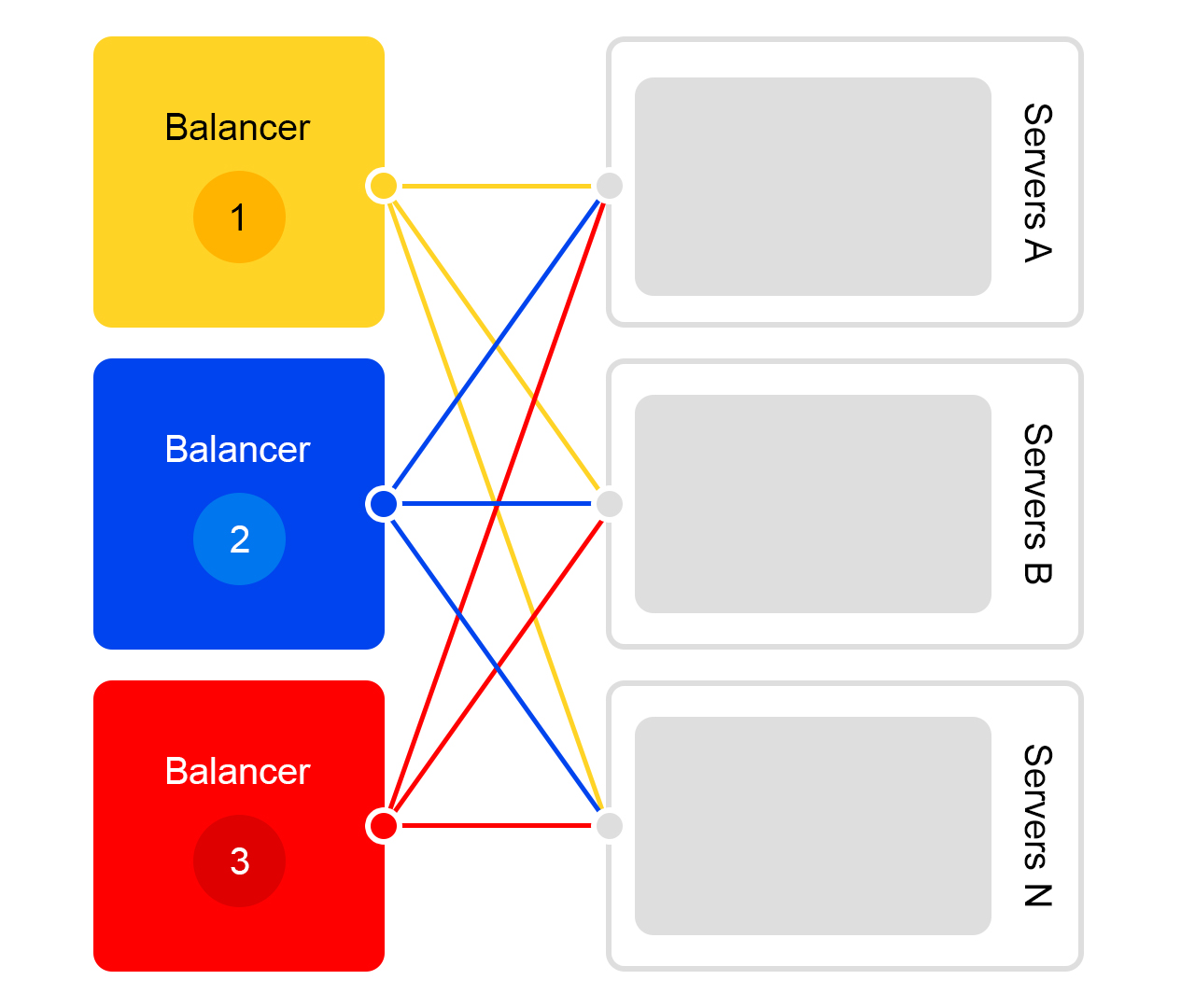
Un équilibreur est composé d'au moins trois serveurs physiques. Une telle redondance est faite pour la fiabilité. Les équilibreurs travaillent sur HAProx.
Nous avons choisi HAProx en raison de ses performances élevées, de ses faibles besoins en ressources et de ses nombreuses fonctionnalités. À l'intérieur de chaque serveur, notre logiciel de recherche fonctionne.
La probabilité de défaillance d'un serveur est faible. Mais si vous avez plusieurs serveurs, la probabilité qu'au moins une chute augmente.
C'est ce qui se passe en réalité: les serveurs se bloquent. Par conséquent, vous devez constamment surveiller l'état de tous les serveurs. Si le serveur ne répond plus, il est automatiquement déconnecté du trafic. Pour cela, HAProxy a un bilan de santé intégré. Il va à tous les serveurs avec la requête HTTP «/ ping» une fois par seconde.
Une autre fonctionnalité de HAProxy: l'agent-check vous permet de charger tous les serveurs de manière uniforme. Pour ce faire, HAProxy se connecte à tous les serveurs et renvoie leur poids en fonction de la charge actuelle de 1 à 100. Le poids est calculé en fonction du nombre de demandes dans la file d'attente de traitement et de la charge sur le processeur.
Maintenant sur la recherche d'un chat. Demandes du formulaire
/ recherche? Texte = en colère + chat arrive à la
recherche . Pour que la recherche soit rapide, l'index de chat entier doit être placé dans la RAM. Même la lecture à partir d'un SSD n'est pas assez rapide.
Il était une fois, la base de l'offre était petite et il y avait suffisamment de RAM pour un serveur. Au fur et à mesure que la base de données des propositions s'est développée, tout a cessé de tenir dans cette RAM et les données ont été divisées en deux parties: le fragment 1 et le fragment 2.

Mais cela arrive toujours: toute solution, même bonne, pose d'autres problèmes.
L'équilibreur est toujours allé sur n'importe quel serveur. Mais sur la machine d'où venait la demande, il n'y avait que la moitié de l'index. Le reste était sur d'autres serveurs. Par conséquent, le serveur devait se rendre sur une machine voisine. Après avoir reçu les données des deux serveurs, les résultats ont été combinés et réorganisés.
Étant donné que l'équilibreur distribue les demandes de manière égale, tous les serveurs ont été impliqués dans la réorganisation, et pas seulement dans la transmission des données.
Le problème s'est produit si le serveur voisin n'était pas disponible. La solution a été de spécifier plusieurs serveurs avec des priorités différentes comme serveur "voisin". Tout d'abord, la demande a été envoyée aux serveurs du rack actuel. Si aucune réponse n'a été reçue, la demande a été envoyée à tous les serveurs de ce centre de données. Enfin et surtout, la demande a été envoyée à d'autres centres de données.
À mesure que le nombre de propositions augmentait, les données étaient divisées en quatre parties. Mais ce n'était pas la limite.
Maintenant, une configuration de huit fragments est utilisée. De plus, pour économiser davantage de mémoire, l'index a été divisé en la partie de recherche (par laquelle la recherche a lieu) et la partie d'extrait de code (qui n'est pas impliquée dans la recherche).
Un serveur contient des informations sur un seul fragment. Par conséquent, pour effectuer une recherche sur l'index complet, vous devez rechercher sur huit serveurs contenant des fragments différents.
Les serveurs sont regroupés en clusters. Chaque cluster contient huit moteurs de recherche et un extrait.
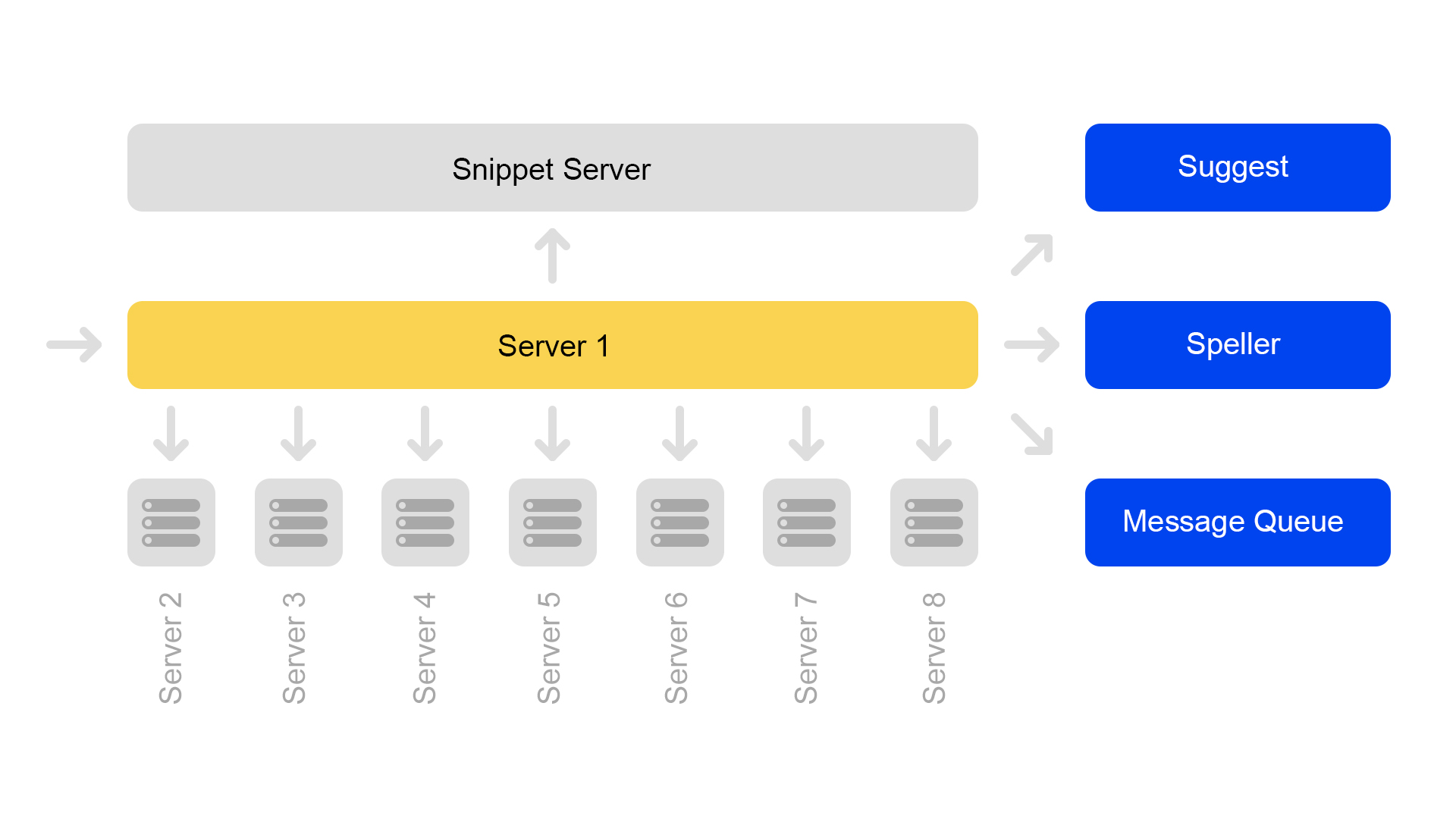
La base de données de valeurs-clés avec des données statiques s'exécute sur le serveur d'extraits de code. Ils sont nécessaires pour délivrer des documents, par exemple, une description d'un chat avec un couineur. Les données sont spécialement extraites sur un serveur séparé afin de ne pas charger la mémoire des moteurs de recherche.
Étant donné que les ID de document sont uniques uniquement dans le cadre d'un index, une situation peut se produire en l'absence de documents dans les extraits de code. Eh bien ou que sur un ID il y aura un autre contenu. Par conséquent, pour que la recherche fonctionne et que la recherche se produise, un besoin est apparu pour la cohérence de l'ensemble du cluster. Je parlerai de la façon dont nous surveillons la cohérence un peu plus tard.
La recherche elle-même est organisée comme suit: une requête de recherche peut arriver à l'un des huit serveurs. Disons qu'il est venu sur le serveur 1. Ce serveur traite tous les arguments et comprend quoi et comment chercher. Selon la demande entrante, le serveur peut faire des demandes supplémentaires aux services externes pour les informations nécessaires. Une demande peut être suivie par jusqu'à dix demandes adressées à des services externes.
Après avoir collecté les informations nécessaires, une recherche commence dans la base de données des offres. Pour ce faire, des sous-requêtes sont effectuées pour les huit serveurs du cluster.
Après avoir reçu les réponses, les résultats sont combinés. Au final, pour générer le problème, vous devrez peut-être plusieurs sous-requêtes supplémentaires sur le serveur d'extraits de code.
Les requêtes de recherche au sein du cluster sont:
/ shard1? Text = angry + cat . De plus, des sous-requêtes de la forme:
/ status sont constamment effectuées entre tous les serveurs du cluster une fois par seconde.
La demande
/ status détecte une situation où le serveur n'est pas disponible.
Il contrôle également que sur tous les serveurs, la version du moteur de recherche et la version d'index sont identiques, sinon il y aura des données incohérentes à l'intérieur du cluster.
Malgré le fait qu'un serveur d'extraits de code traite les demandes de huit moteurs de recherche, son processeur est très légèrement chargé. Par conséquent, nous transférons maintenant les données d'extrait de code vers un service distinct.
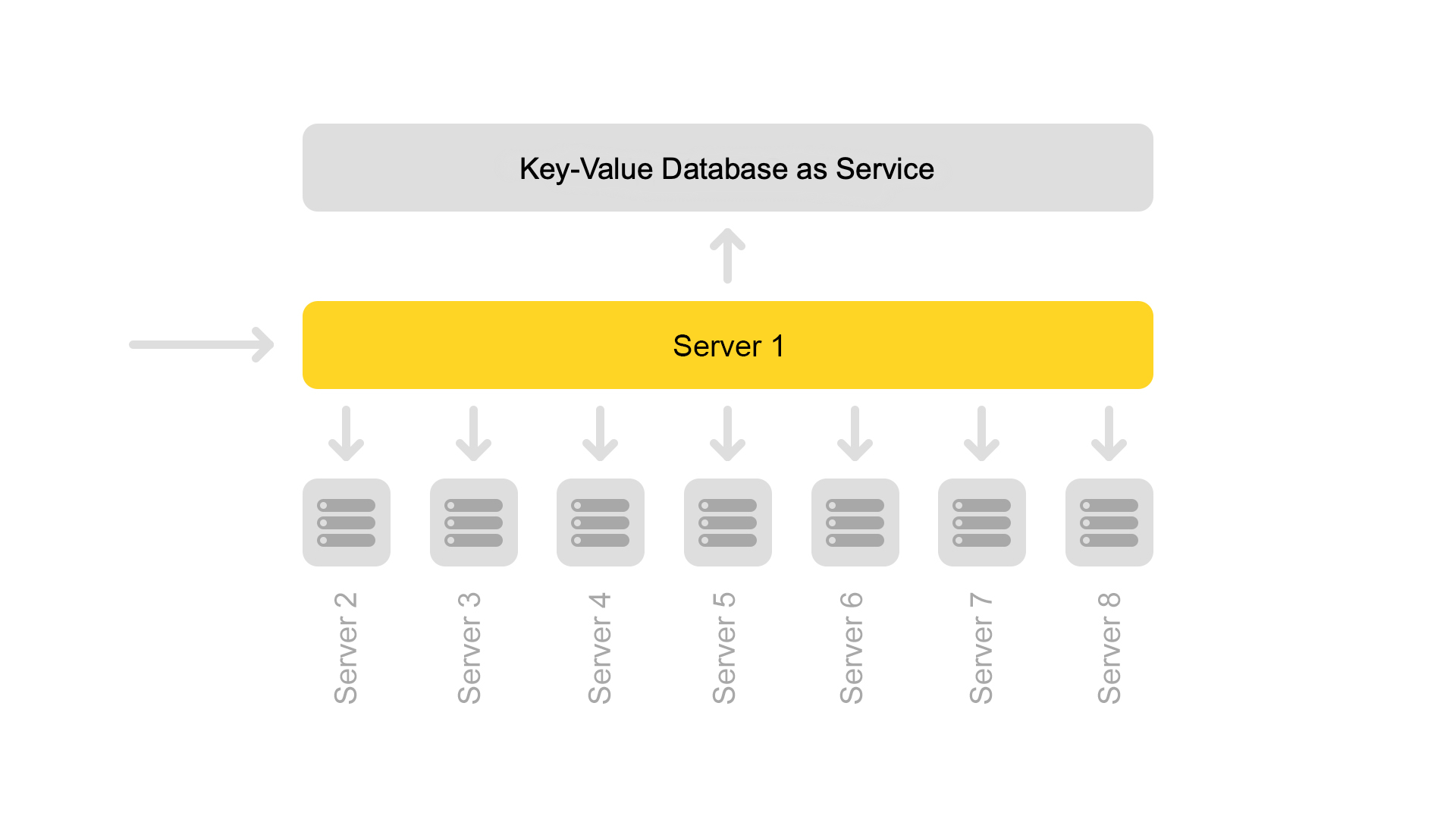
Pour transférer des données, nous avons introduit des clés universelles pour les documents. Maintenant, la situation est impossible lorsqu'une clé renvoie le contenu d'un autre document.
Mais la transition vers une autre architecture n'est pas encore terminée. Nous voulons maintenant nous débarrasser du serveur d'extraits dédié. Et ensuite, éloignez-vous généralement de la structure du cluster. Cela nous permettra de continuer à évoluer facilement. Un bonus supplémentaire est une importante économie de fer.
Et maintenant aux histoires effrayantes avec une fin heureuse. Considérez plusieurs cas d'indisponibilité du serveur.
Terrible s'est produit: un serveur n'est pas disponible
Disons qu'un serveur n'est pas disponible. Les autres serveurs du cluster peuvent alors continuer de répondre, mais les résultats de la recherche seront incomplets.
Grâce à une vérification de l'état, les serveurs voisins comprennent que l'un n'est pas disponible. Par conséquent, pour maintenir l'exhaustivité, tous les serveurs du cluster commencent à répondre à la demande
/ ping à l'équilibreur qu'ils sont également indisponibles. Il s'avère que tous les serveurs du cluster sont morts (ce qui n'est pas le cas). C'est le principal inconvénient de notre schéma de cluster - par conséquent, nous voulons nous en éloigner.
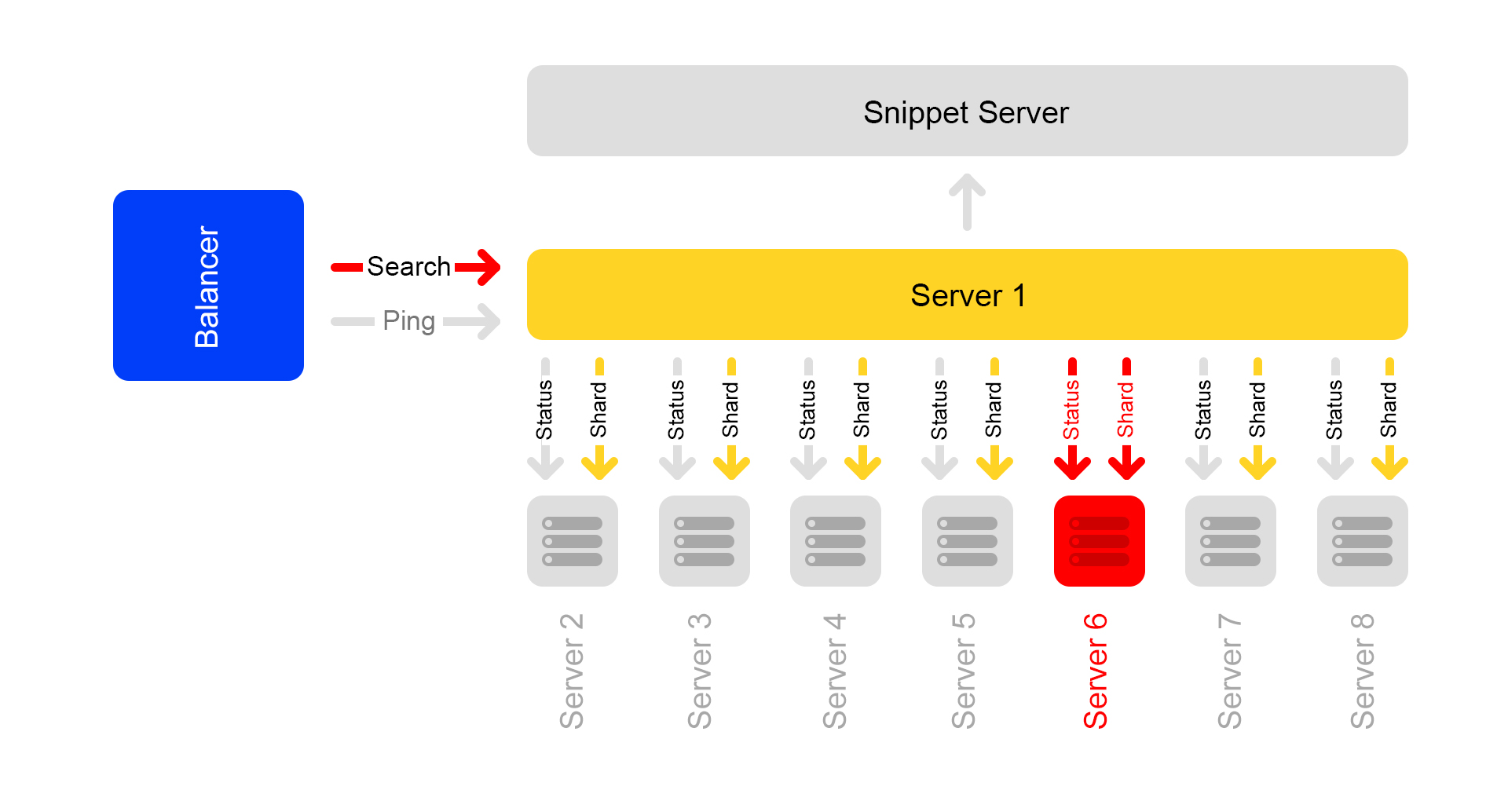
Demandes qui se sont terminées par une erreur, l'équilibreur demande à nouveau sur d'autres serveurs.
De plus, l'équilibreur cesse d'envoyer du trafic utilisateur aux serveurs morts, mais continue de vérifier leur état.
Lorsque le serveur devient disponible, il commence à répondre à
/ ping . Dès que les réponses normales aux pings des serveurs morts commencent à arriver, les équilibreurs commencent à y envoyer du trafic utilisateur. Le cluster est rétabli, applaudissements.
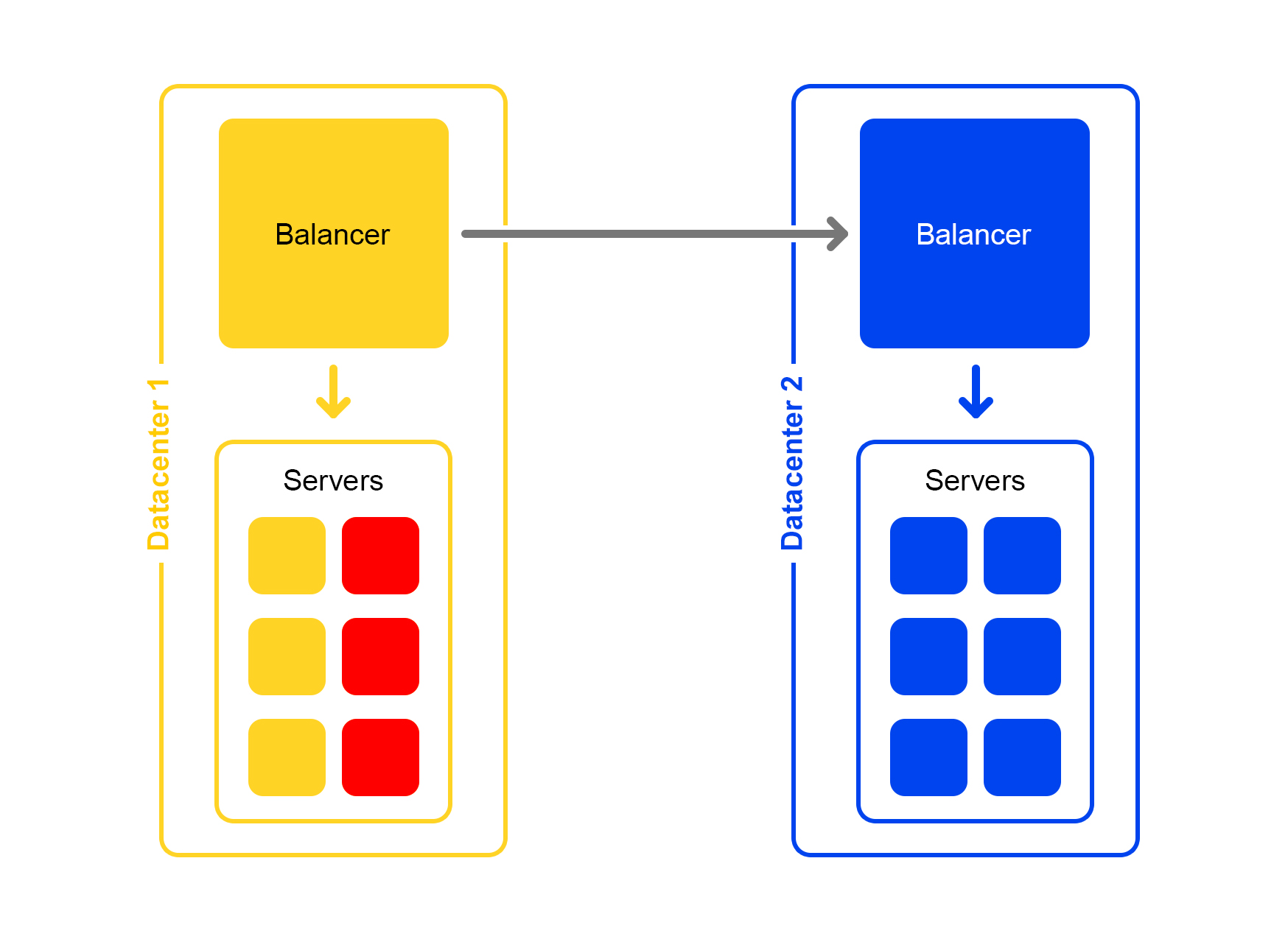
Pire encore: de nombreux serveurs indisponibles
Une partie importante des serveurs du centre de données est coupée. Que faire, où courir? L'équilibreur vient à nouveau à la rescousse. Chaque équilibreur garde constamment en mémoire le nombre actuel de serveurs actifs. Il considère toujours la quantité maximale de trafic que le centre de données actuel peut gérer.
Lorsque de nombreux serveurs du centre de données tombent, l'équilibreur comprend que ce centre de données ne peut pas traiter tout le trafic.
Ensuite, le trafic excédentaire commence distribué de manière aléatoire vers d'autres centres de données. Tout fonctionne, tout le monde est content.
Comment nous le faisons: versions de sortie
Maintenant, comment nous publions les modifications apportées au service. Ici, nous avons emprunté la voie de la rationalisation des processus: le déploiement d'une nouvelle version est presque entièrement automatisé.
Lorsqu'un certain nombre de modifications sont accumulées dans le projet, une nouvelle version est automatiquement créée et son assemblage est lancé.
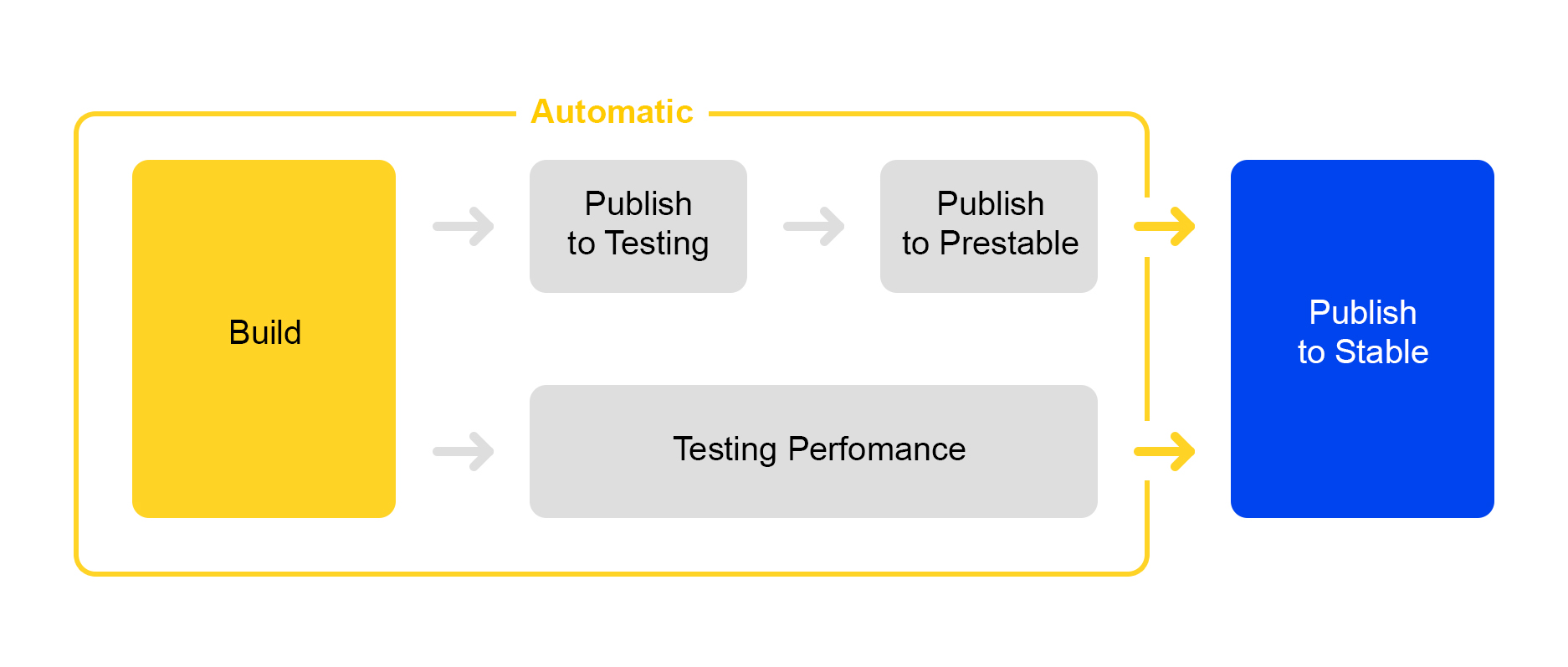
Ensuite, le service est déployé pour les tests, où la stabilité est vérifiée.
Parallèlement, les tests de performances automatiques sont lancés. Il est engagé dans un service spécial. Je ne parlerai pas de lui maintenant - sa description mérite un article séparé.
Si la publication dans testing est réussie, la publication de la version dans prestable démarre automatiquement. Prestable est un cluster spécial où le trafic utilisateur normal est dirigé. S'il renvoie une erreur, l'équilibreur fait une nouvelle demande en production.
En pré-stable, les temps de réponse sont mesurés et comparés à la version précédente en production. Si tout va bien, la personne se connecte: vérifie les graphiques et les résultats des tests de charge, puis commence le déploiement en production.
Tout le meilleur pour l'utilisateur: test A / B
Il n'est pas toujours évident que les changements apportés au service apporteront de réels avantages. Pour mesurer l'utilité du changement, les gens ont proposé des tests A / B. Je vais parler un peu de la façon dont cela fonctionne dans la recherche Yandex.Market.
Tout commence par l'ajout d'un nouveau paramètre CGI qui inclut de nouvelles fonctionnalités. Soit notre paramètre:
market_new_functionality = 1 . Ensuite, dans le code, activez cette fonctionnalité avec l'indicateur:
If (cgi.experiments.market_new_functionality) {
De nouvelles fonctionnalités sont déployées en production.
Il existe un service dédié à l'automatisation des tests A / B, qui est
décrit en détail
ici . Une expérience est créée dans le service. La part du trafic est fixée, par exemple, à 15%. L'intérêt n'est pas défini pour les demandes, mais pour les utilisateurs. Le temps de l'expérience, par exemple une semaine, est également indiqué.
Plusieurs expériences peuvent être lancées en même temps. Dans les paramètres, vous pouvez spécifier si l'intersection avec d'autres expériences est possible.
Par conséquent, le service ajoute automatiquement l'argument
market_new_functionality = 1 à 15% des utilisateurs. Il calcule également automatiquement les métriques sélectionnées. Après l'expérience, les analystes examinent les résultats et tirent des conclusions. Sur la base des résultats, une décision est prise de déployer en production ou en raffinement.
Agilité du marché: tests de production
Il arrive souvent qu'il soit nécessaire de vérifier le fonctionnement de nouvelles fonctionnalités en production, mais il n'y a aucune certitude sur la manière dont elles se comporteront dans des conditions de «combat» sous forte charge.
Il existe une solution: les indicateurs des paramètres CGI peuvent être utilisés non seulement pour les tests A / B, mais également pour tester de nouvelles fonctionnalités.
Nous avons créé un outil qui vous permet de modifier instantanément la configuration sur des milliers de serveurs sans exposer le service à des risques. Cela s'appelle "Stop Crane". L'idée originale était la possibilité de désactiver rapidement certaines fonctionnalités sans mise en page. Ensuite, l'outil s'est développé et est devenu plus complexe.
Le schéma du service est présenté ci-dessous:
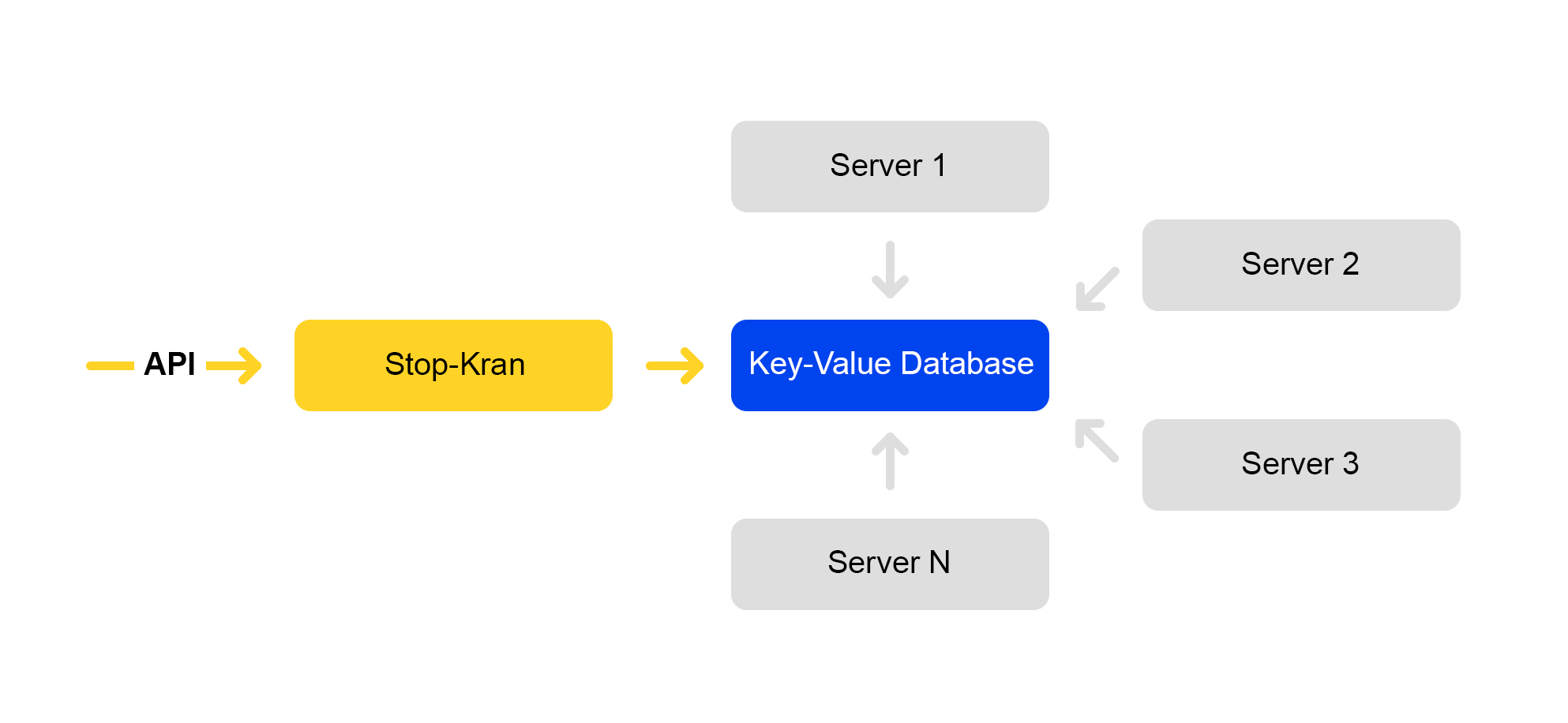
L'API définit des valeurs d'indicateur. Le service de gestion stocke ces valeurs dans une base de données. Tous les serveurs accèdent à la base de données toutes les dix secondes, pompent les valeurs des indicateurs et appliquent ces valeurs à chaque demande.
Dans Stop Crane, vous pouvez définir deux types de valeurs:
1) Expressions conditionnelles. Appliquer lorsque l'une des valeurs est exécutée. Par exemple:
{ "condition":"IS_DC1", "value":"3", }, { "condition": "CLUSTER==2 and IS_BERU", "value": "4!" }
La valeur «3» sera appliquée lorsque la demande sera traitée dans l'emplacement DC1. Et la valeur est «4» lorsque la demande est traitée sur le deuxième cluster pour le site beru.ru.
2) Valeurs inconditionnelles. Ils sont utilisés par défaut si aucune des conditions n'est remplie. Par exemple:
valeur, valeur!Si la valeur se termine par un point d'exclamation, elle reçoit une priorité plus élevée.
L'analyseur des paramètres CGI analyse l'URL. Applique ensuite les valeurs du robinet d'arrêt.
Les valeurs avec les priorités suivantes s'appliquent:
- Priorité plus élevée à l'arrêt du robinet (point d'exclamation).
- La valeur de la requête.
- La valeur par défaut provient du robinet d'arrêt.
- La valeur par défaut dans le code.
Il y a beaucoup de drapeaux qui sont indiqués dans des valeurs conditionnelles - ils sont suffisants pour tous les scénarios que nous connaissons:
- Centre de données.
- Environnement: production, tests, ombre.
- Lieu: marché, beru.
- Numéro de cluster.
Avec cet outil, vous pouvez activer de nouvelles fonctionnalités sur un groupe de serveurs (par exemple, uniquement dans un centre de données) et tester la fonctionnalité de cette fonctionnalité sans risque particulier pour l'ensemble du service. Même si vous avez fait une grave erreur quelque part, tout a commencé à tomber et tout le centre de données a baissé, les équilibreurs redirigeront les demandes vers un autre centre de données. Les utilisateurs finaux ne remarqueront rien.
Si vous remarquez un problème, vous pouvez immédiatement renvoyer la valeur précédente de l'indicateur et les modifications seront annulées.
Ce service a ses inconvénients: les développeurs l'aiment beaucoup et essaient souvent de pousser tous les changements dans le Stop Crane. Nous essayons de lutter contre les abus.
L'approche Stop Crane fonctionne bien lorsque vous disposez déjà d'un code stable, prêt à être déployé en production. Dans le même temps, vous avez encore des doutes et vous souhaitez vérifier le code dans des conditions de "combat".
Cependant, le robinet d'arrêt n'est pas adapté aux tests pendant le développement. Pour les développeurs, il existe un cluster séparé appelé «cluster virtuel».
Test secret: cluster fantôme
Les demandes de l'un des clusters sont dupliquées sur le cluster reflet. Mais l'équilibreur ignore complètement les réponses de ce cluster. Le schéma de son travail est présenté ci-dessous.
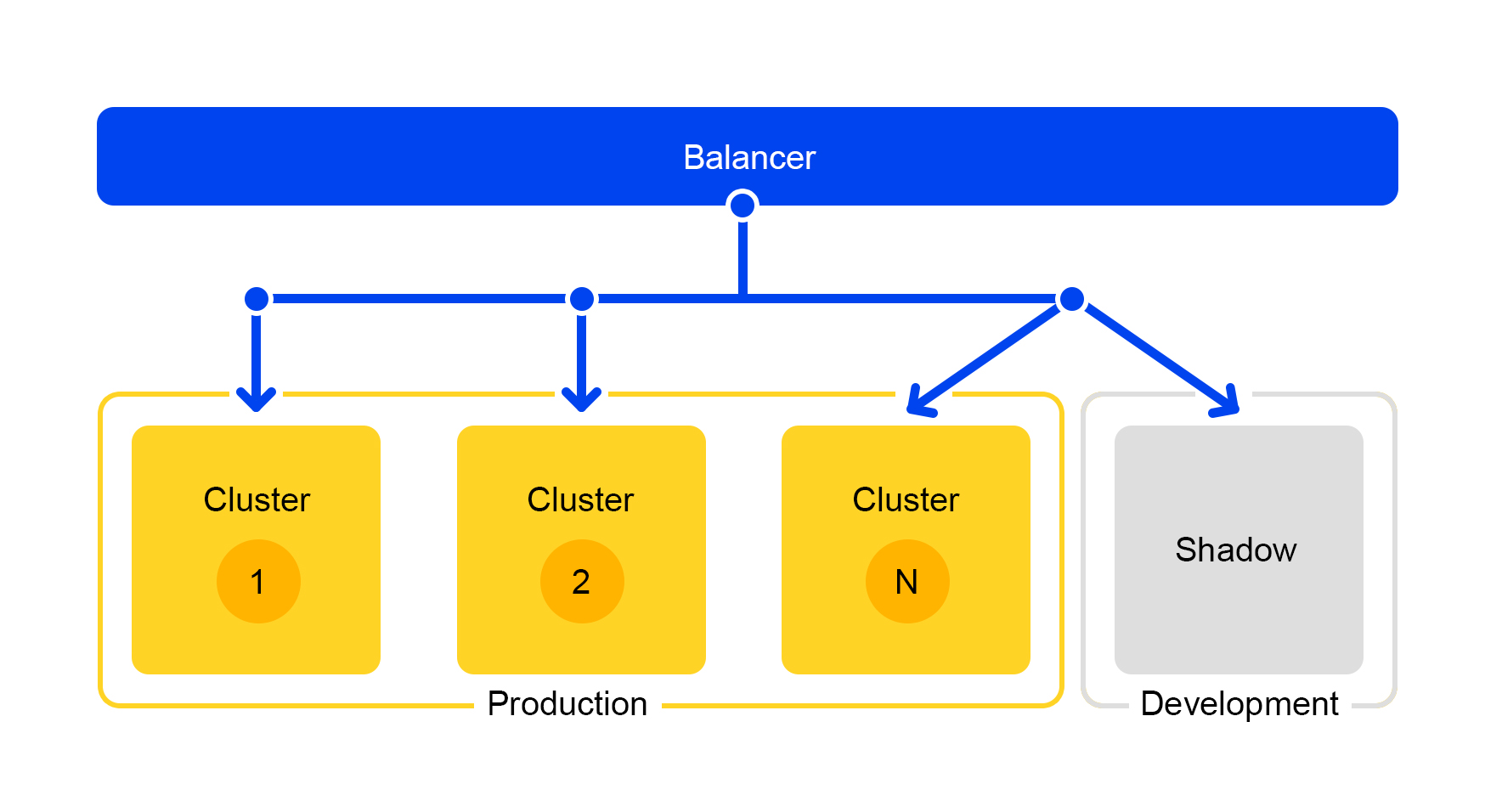
Nous obtenons un cluster de test qui est en conditions réelles de «combat». Le trafic normal des utilisateurs y circule. Le matériel des deux clusters est le même, vous pouvez donc comparer les performances et les erreurs.
Et puisque l'équilibreur ignore complètement les réponses, les utilisateurs finaux ne verront pas les réponses du cluster fantôme. Par conséquent, il n'est pas effrayant de se tromper.
Conclusions
Alors, comment avons-nous construit une recherche de marché?
Pour que tout se passe bien, nous séparons la fonctionnalité en services distincts. Vous ne pouvez donc mettre à l'échelle que les composants dont nous avons besoin et simplifier les composants. Il est facile de donner un composant séparé à une autre équipe et de partager les responsabilités pour y travailler. Et des économies importantes de fer avec cette approche sont un avantage évident.
Le cluster virtuel nous aide également: vous pouvez développer des services, les tester dans le processus et en même temps ne pas déranger l'utilisateur.
Eh bien et vérifiez la production, bien sûr. Besoin de changer la configuration sur mille serveurs? Facile, utilisez une grue d'arrêt. Ainsi, vous pouvez immédiatement déployer une solution complexe prête à l'emploi et revenir à une version stable en cas de problème.
J'espère avoir pu montrer comment nous rendons le marché rapide et stable avec une base d'offres toujours croissante. Comment résoudre les problèmes de serveur, traiter un grand nombre de demandes, améliorer la flexibilité des services et le faire sans interrompre les processus de travail.