
Présentation
Le réacteur d'E / S ( boucle d'événement à thread unique) est un modèle d'écriture de logiciels très chargés utilisé dans de nombreuses solutions populaires:
Dans cet article, nous allons examiner les tenants et aboutissants du réacteur d'E / S et le principe de son fonctionnement, écrire une implémentation pour moins de 200 lignes de code et forcer un simple serveur HTTP à traiter plus de 40 millions de requêtes / min.
Préface
- L'article a été rédigé dans le but d'aider à comprendre le fonctionnement du réacteur d'E / S, et donc à réaliser les risques lors de son utilisation.
- Pour maîtriser l'article, vous avez besoin de connaissances sur les bases du langage C et peu d'expérience dans le développement d'applications réseau.
- Tout le code est écrit en C strictement par ( soigneusement: long PDF ) la norme C11 pour Linux et est disponible sur GitHub .
Pourquoi est-ce nécessaire?
Avec la popularité croissante d'Internet, les serveurs Web devaient traiter un grand nombre de connexions en même temps, et donc deux approches ont été essayées: bloquer les E / S sur un grand nombre de threads du système d'exploitation et les E / S non bloquantes en combinaison avec un système de notification d'événements, également appelé «système sélecteur "( epoll / kqueue / IOCP / etc).
La première approche consistait à créer un nouveau thread OS pour chaque connexion entrante. Son inconvénient est sa faible évolutivité: le système d'exploitation devra effectuer de nombreuses transitions de contexte et appels système . Ce sont des opérations coûteuses et peuvent entraîner un manque de RAM libre avec un nombre impressionnant de connexions.
La version modifiée alloue un nombre fixe de threads (pool de threads), empêchant ainsi le système d'arrêter anormalement l'exécution, mais introduit en même temps un nouveau problème: si à un moment donné le pool de threads est bloqué par de longues opérations de lecture, alors d'autres sockets qui sont déjà capables de recevoir des données ne pourra pas le faire.
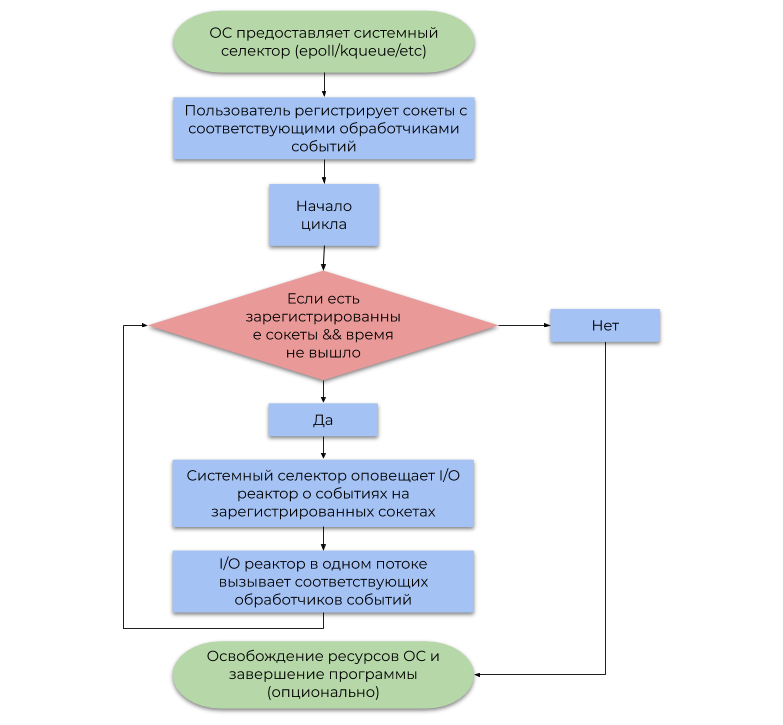
La deuxième approche utilise le système de notification d'événements (sélecteur de système) fourni par le système d'exploitation. Cet article décrit le type de sélecteur de système le plus courant basé sur des alertes (événements, notifications) sur l'état de préparation des opérations d'E / S, plutôt que des alertes sur leur achèvement . Un exemple simplifié de son utilisation peut être représenté par l'organigramme suivant:

La différence entre ces approches est la suivante:
- Le blocage des opérations d'E / S suspend le flux utilisateur jusqu'à ce que le système d'exploitation défragmente correctement les paquets IP entrants dans le flux d'octets ( TCP , réception de données) ou libère suffisamment d'espace dans les tampons d'écriture internes pour un envoi ultérieur via NIC (envoi de données).
- Après un certain temps, le sélecteur de système informe le programme que le système d'exploitation a déjà défragmenté les paquets IP (TCP, réception de données) ou que suffisamment d'espace dans les tampons d'enregistrement internes est déjà disponible (envoi de données).
Pour résumer, réserver un thread OS pour chaque E / S est une perte de puissance de calcul, car en réalité, les threads ne sont pas occupés par un travail utile (le terme "interruption logicielle" a ses racines). Le sélecteur de système résout ce problème en permettant au programme utilisateur de consommer les ressources CPU de manière beaucoup plus économique.
Modèle d'E / S du réacteur
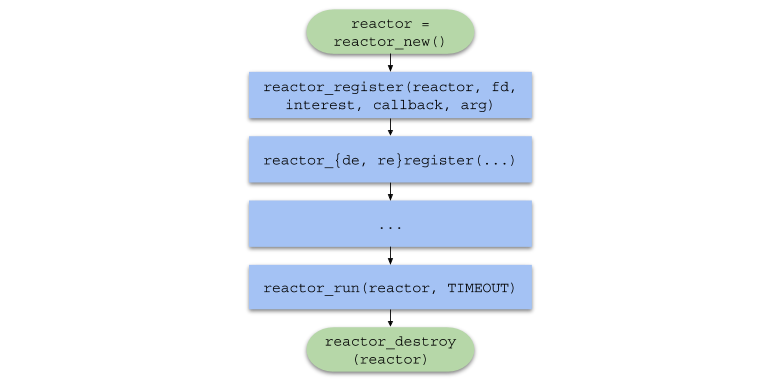
Un réacteur d'E / S agit comme une couche entre le sélecteur de système et le code utilisateur. Le principe de son fonctionnement est décrit par l'organigramme suivant:
- Permettez-moi de vous rappeler qu'un événement est une notification qu'un certain socket est capable d'effectuer une opération d'E / S non bloquante.
- Un gestionnaire d'événements est une fonction appelée par le réacteur d'E / S lorsqu'un événement est reçu, qui effectue ensuite une opération d'E / S non bloquante.
Il est important de noter que le réacteur d'E / S est par définition à un seul thread, mais rien n'empêche d'utiliser le concept dans un environnement multithread par rapport à un réacteur à 1 flux: 1, utilisant ainsi tous les cœurs de CPU.
Implémentation
Nous plaçons l'interface publique dans le fichier reactor.h , et l'implémentation dans reactor.c . reactor.h comprendra les déclarations suivantes:
Afficher les annonces dans reacteur.h typedef struct reactor Reactor; typedef void (*Callback)(void *arg, int fd, uint32_t events); Reactor *reactor_new(void); int reactor_destroy(Reactor *reactor); int reactor_register(const Reactor *reactor, int fd, uint32_t interest, Callback callback, void *callback_arg); int reactor_deregister(const Reactor *reactor, int fd); int reactor_reregister(const Reactor *reactor, int fd, uint32_t interest, Callback callback, void *callback_arg); int reactor_run(const Reactor *reactor, time_t timeout);
La structure d'E / S du réacteur se compose d'un descripteur de fichier de sélection epoll et d'une GHashTable hachage GHashTable , que chaque socket mappe sur CallbackData (une structure d'un gestionnaire d'événements et un argument utilisateur pour cela).
Afficher le réacteur et les données de rappel struct reactor { int epoll_fd; GHashTable *table;
Veuillez noter que nous avons utilisé la possibilité de gérer un type incomplet par pointeur. Dans reactor.h nous déclarons la structure du reactor , et dans reactor.c définissons, empêchant ainsi l'utilisateur de changer explicitement ses champs. C'est l'un des modèles de masquage de données qui s'intègre organiquement dans la sémantique de C.
Les fonctions reactor_register , reactor_deregister et reactor_reregister mettent à jour la liste des sockets d'intérêt et les gestionnaires d'événements correspondants dans le sélecteur de système et dans la table de hachage.
Afficher les fonctionnalités d'enregistrement #define REACTOR_CTL(reactor, op, fd, interest) \ if (epoll_ctl(reactor->epoll_fd, op, fd, \ &(struct epoll_event){.events = interest, \ .data = {.fd = fd}}) == -1) { \ perror("epoll_ctl"); \ return -1; \ } int reactor_register(const Reactor *reactor, int fd, uint32_t interest, Callback callback, void *callback_arg) { REACTOR_CTL(reactor, EPOLL_CTL_ADD, fd, interest) g_hash_table_insert(reactor->table, int_in_heap(fd), callback_data_new(callback, callback_arg)); return 0; } int reactor_deregister(const Reactor *reactor, int fd) { REACTOR_CTL(reactor, EPOLL_CTL_DEL, fd, 0) g_hash_table_remove(reactor->table, &fd); return 0; } int reactor_reregister(const Reactor *reactor, int fd, uint32_t interest, Callback callback, void *callback_arg) { REACTOR_CTL(reactor, EPOLL_CTL_MOD, fd, interest) g_hash_table_insert(reactor->table, int_in_heap(fd), callback_data_new(callback, callback_arg)); return 0; }
Après que le réacteur d'E / S a intercepté l'événement avec le descripteur fd , il appelle le gestionnaire d'événements correspondant, dans lequel il passe fd , le masque de bits des événements générés et le pointeur utilisateur à void .
Afficher la fonction reacteur_run () int reactor_run(const Reactor *reactor, time_t timeout) { int result; struct epoll_event *events; if ((events = calloc(MAX_EVENTS, sizeof(*events))) == NULL) abort(); time_t start = time(NULL); while (true) { time_t passed = time(NULL) - start; int nfds = epoll_wait(reactor->epoll_fd, events, MAX_EVENTS, timeout - passed); switch (nfds) {
Pour résumer, la chaîne d'appels de fonction dans le code utilisateur prendra la forme suivante:
Serveur à thread unique
Afin de tester le réacteur d'E / S sous forte charge, nous écrirons un simple serveur Web HTTP pour répondre à toute demande avec une image.
Référence rapide du protocole HTTPHTTP est un protocole de niveau application principalement utilisé pour l'interaction du serveur avec un navigateur.
HTTP peut facilement être utilisé en plus du protocole de transport TCP , pour envoyer et recevoir des messages au format défini par la spécification .
<> <URI> < HTTP>CRLF < 1>CRLF < 2>CRLF < N>CRLF CRLF <>
CRLF est une séquence de deux caractères: \r et \n , séparant la première ligne de requête, les en-têtes et les données.<> est l'un de CONNECT , DELETE , GET , HEAD , OPTIONS , PATCH , POST , PUT , TRACE . Le navigateur enverra une commande GET à notre serveur, ce qui signifie «Envoyez-moi le contenu du fichier».<URI> est l' identificateur de ressource unifié . Par exemple, si URI = /index.html , le client demande la page principale du site.< HTTP> - Version du protocole HTTP/XY format HTTP/XY . La version la plus couramment utilisée à ce jour est HTTP/1.1 .< N> est une paire clé-valeur au format <>: <> , envoyée au serveur pour une analyse plus approfondie.<> - données requises par le serveur pour terminer l'opération. Il s'agit souvent de JSON ou de tout autre format.
< HTTP> < > < >CRLF < 1>CRLF < 2>CRLF < N>CRLF CRLF <>
< > est un nombre représentant le résultat d'une opération. Notre serveur retournera toujours le statut 200 (opération réussie).< > - représentation sous forme de chaîne du code d'état. Pour le code d'état 200, c'est OK .< N> - un en-tête du même format que dans la demande. Nous renverrons les en Content-Length têtes Content-Length (taille du fichier) et Content-Type: text/html (return type data).<> - données demandées par l'utilisateur. Dans notre cas, c'est le chemin d'accès à l'image en HTML .
Le http_server.c (serveur à thread unique) inclut le fichier common.h , qui contient les prototypes de fonction suivants:
Afficher les prototypes de fonctions en commun.h static void on_accept(void *arg, int fd, uint32_t events); static void on_send(void *arg, int fd, uint32_t events); static void on_recv(void *arg, int fd, uint32_t events); static void set_nonblocking(int fd); static noreturn void fail(const char *format, ...); static int new_server(bool reuse_port);
La macro de fonction SAFE_CALL() également décrite et la fonction fail() est définie. La macro compare la valeur de l'expression avec l'erreur, et si la condition est remplie, elle appelle la fonction fail() :
#define SAFE_CALL(call, error) \ do { \ if ((call) == error) { \ fail("%s", #call); \ } \ } while (false)
La fonction fail() imprime les arguments passés au terminal (comme printf() ) et termine le programme avec le code EXIT_FAILURE :
static noreturn void fail(const char *format, ...) { va_list args; va_start(args, format); vfprintf(stderr, format, args); va_end(args); fprintf(stderr, ": %s\n", strerror(errno)); exit(EXIT_FAILURE); }
La fonction new_server() renvoie le descripteur de fichier du socket "serveur" créé par les appels système socket() , bind() et listen() et capable d'accepter les connexions entrantes en mode non bloquant.
Afficher la fonction new_server () static int new_server(bool reuse_port) { int fd; SAFE_CALL((fd = socket(AF_INET, SOCK_STREAM | SOCK_NONBLOCK, IPPROTO_TCP)), -1); if (reuse_port) { SAFE_CALL( setsockopt(fd, SOL_SOCKET, SO_REUSEPORT, &(int){1}, sizeof(int)), -1); } struct sockaddr_in addr = {.sin_family = AF_INET, .sin_port = htons(SERVER_PORT), .sin_addr = {.s_addr = inet_addr(SERVER_IPV4)}, .sin_zero = {0}}; SAFE_CALL(bind(fd, (struct sockaddr *)&addr, sizeof(addr)), -1); SAFE_CALL(listen(fd, SERVER_BACKLOG), -1); return fd; }
- Notez que le socket est initialement créé en mode non bloquant à l'aide de l'indicateur
SOCK_NONBLOCK , de sorte que dans la fonction on_accept() (pour en savoir plus), l'appel système accept() n'arrête pas l'exécution du flux. - Si
reuse_port est true , cette fonction configurera le socket avec l'option SO_REUSEPORT utilisant setsockopt() pour utiliser le même port dans un environnement multi-thread (voir la section "Serveur multi-thread").
Le gestionnaire d'événements on_accept() est appelé après que le système d'exploitation a généré un événement EPOLLIN , dans ce cas, ce qui signifie qu'une nouvelle connexion peut être acceptée. on_accept() accepte une nouvelle connexion, la met en mode non bloquant et s'enregistre auprès du gestionnaire d'événements on_recv() dans le réacteur d'E / S.
Afficher la fonction on_accept () static void on_accept(void *arg, int fd, uint32_t events) { int incoming_conn; SAFE_CALL((incoming_conn = accept(fd, NULL, NULL)), -1); set_nonblocking(incoming_conn); SAFE_CALL(reactor_register(reactor, incoming_conn, EPOLLIN, on_recv, request_buffer_new()), -1); }
Le gestionnaire d'événements on_recv() est appelé après que le système d'exploitation a généré un événement EPOLLIN , dans ce cas, ce qui signifie que la connexion enregistrée par on_accept() est prête à accepter des données.
on_recv() lit les données de la connexion jusqu'à la réception de la requête HTTP complète, puis il enregistre le gestionnaire on_send() pour envoyer la réponse HTTP. Si le client se déconnecte, le socket se désenregistre et se ferme avec close() .
Afficher la fonction on_recv () static void on_recv(void *arg, int fd, uint32_t events) { RequestBuffer *buffer = arg;
Le gestionnaire d'événements on_send() est appelé après que le système d'exploitation a généré un événement EPOLLOUT , ce qui signifie que la connexion enregistrée par on_recv() est prête à envoyer des données. Cette fonction envoie une réponse HTTP contenant du HTML avec l'image au client, puis change à nouveau le gestionnaire d'événements en on_recv() .
Afficher la fonction on_send () static void on_send(void *arg, int fd, uint32_t events) { const char *content = "<img " "src=\"https://habrastorage.org/webt/oh/wl/23/" "ohwl23va3b-dioerobq_mbx4xaw.jpeg\">"; char response[1024]; sprintf(response, "HTTP/1.1 200 OK" CRLF "Content-Length: %zd" CRLF "Content-Type: " "text/html" DOUBLE_CRLF "%s", strlen(content), content); SAFE_CALL(send(fd, response, strlen(response), 0), -1); SAFE_CALL(reactor_reregister(reactor, fd, EPOLLIN, on_recv, arg), -1); }
Et enfin, dans le fichier http_server.c , dans la fonction main() , nous créons un réacteur d'E / S à l'aide de reactor_new() , créons un socket serveur et l'enregistrons, démarrons le réacteur à l'aide de reactor_run() exactement une minute, puis libérons les ressources et quittez du programme.
Afficher http_server.c #include "reactor.h" static Reactor *reactor; #include "common.h" int main(void) { SAFE_CALL((reactor = reactor_new()), NULL); SAFE_CALL( reactor_register(reactor, new_server(false), EPOLLIN, on_accept, NULL), -1); SAFE_CALL(reactor_run(reactor, SERVER_TIMEOUT_MILLIS), -1); SAFE_CALL(reactor_destroy(reactor), -1); }
Vérifiez que tout fonctionne comme prévu. Nous compilons ( chmod a+x compile.sh && ./compile.sh à la racine du projet) et démarrons le serveur auto-écrit, ouvrons http://127.0.0.1:18470 dans le navigateur et observons ce qui était attendu:
Mesure du rendement
Montrer les caractéristiques de ma voiture $ screenfetch MMMMMMMMMMMMMMMMMMMMMMMMMmds+. OS: Mint 19.1 tessa MMm----::-://////////////oymNMd+` Kernel: x86_64 Linux 4.15.0-20-generic MMd /++ -sNMd: Uptime: 2h 34m MMNso/` dMM `.::-. .-::.` .hMN: Packages: 2217 ddddMMh dMM :hNMNMNhNMNMNh: `NMm Shell: bash 4.4.20 NMm dMM .NMN/-+MMM+-/NMN` dMM Resolution: 1920x1080 NMm dMM -MMm `MMM dMM. dMM DE: Cinnamon 4.0.10 NMm dMM -MMm `MMM dMM. dMM WM: Muffin NMm dMM .mmd `mmm yMM. dMM WM Theme: Mint-Y-Dark (Mint-Y) NMm dMM` ..` ... ydm. dMM GTK Theme: Mint-Y [GTK2/3] hMM- +MMd/-------...-:sdds dMM Icon Theme: Mint-Y -NMm- :hNMNNNmdddddddddy/` dMM Font: Noto Sans 9 -dMNs-``-::::-------.`` dMM CPU: Intel Core i7-6700 @ 8x 4GHz [52.0°C] `/dMNmy+/:-------------:/yMMM GPU: NV136 ./ydNMMMMMMMMMMMMMMMMMMMMM RAM: 2544MiB / 7926MiB \.MMMMMMMMMMMMMMMMMMM
Nous mesurons les performances d'un serveur monothread. Ouvrons deux terminaux: dans l'un, nous ./http_server , dans l'autre - wrk . Après une minute, les statistiques suivantes seront affichées dans le deuxième terminal:
$ wrk -c100 -d1m -t8 http://127.0.0.1:18470 -H "Host: 127.0.0.1:18470" -H "Accept-Language: en-US,en;q=0.5" -H "Connection: keep-alive" Running 1m test @ http://127.0.0.1:18470 8 threads and 100 connections Thread Stats Avg Stdev Max +/- Stdev Latency 493.52us 76.70us 17.31ms 89.57% Req/Sec 24.37k 1.81k 29.34k 68.13% 11657769 requests in 1.00m, 1.60GB read Requests/sec: 193974.70 Transfer/sec: 27.19MB
Notre serveur à thread unique a pu traiter plus de 11 millions de requêtes par minute, provenant de 100 connexions. Pas un mauvais résultat, mais peut-il être amélioré?
Serveur multithread
Comme mentionné ci-dessus, un réacteur d'E / S peut être créé dans des flux séparés, utilisant ainsi tous les cœurs de CPU. Appliquons cette approche dans la pratique:
Afficher http_server_multithreaded.c #include "reactor.h" static Reactor *reactor; #pragma omp threadprivate(reactor) #include "common.h" int main(void) { #pragma omp parallel { SAFE_CALL((reactor = reactor_new()), NULL); SAFE_CALL(reactor_register(reactor, new_server(true), EPOLLIN, on_accept, NULL), -1); SAFE_CALL(reactor_run(reactor, SERVER_TIMEOUT_MILLIS), -1); SAFE_CALL(reactor_destroy(reactor), -1); } }
Désormais, chaque thread possède son propre réacteur:
static Reactor *reactor; #pragma omp threadprivate(reactor)
Notez que l'argument de new_server() est true . Cela signifie que nous définissons le socket du serveur sur l'option SO_REUSEPORT pour l'utiliser dans un environnement multi-thread. Vous pouvez en lire plus ici .
Deuxième manche
Nous allons maintenant mesurer les performances d'un serveur multithread:
$ wrk -c100 -d1m -t8 http://127.0.0.1:18470 -H "Host: 127.0.0.1:18470" -H "Accept-Language: en-US,en;q=0.5" -H "Connection: keep-alive" Running 1m test @ http://127.0.0.1:18470 8 threads and 100 connections Thread Stats Avg Stdev Max +/- Stdev Latency 1.14ms 2.53ms 40.73ms 89.98% Req/Sec 79.98k 18.07k 154.64k 78.65% 38208400 requests in 1.00m, 5.23GB read Requests/sec: 635876.41 Transfer/sec: 89.14MB
Le nombre de demandes traitées en 1 minute a augmenté de ~ 3,28 fois! Mais jusqu'au chiffre rond, seulement ~ deux millions n'étaient pas suffisants, essayons de le réparer.
Tout d'abord, regardez les statistiques générées par perf :
$ sudo perf stat -B -e task-clock,context-switches,cpu-migrations,page-faults,cycles,instructions,branches,branch-misses,cache-misses ./http_server_multithreaded Performance counter stats for './http_server_multithreaded': 242446,314933 task-clock (msec) # 4,000 CPUs utilized 1 813 074 context-switches # 0,007 M/sec 4 689 cpu-migrations # 0,019 K/sec 254 page-faults # 0,001 K/sec 895 324 830 170 cycles # 3,693 GHz 621 378 066 808 instructions # 0,69 insn per cycle 119 926 709 370 branches # 494,653 M/sec 3 227 095 669 branch-misses # 2,69% of all branches 808 664 cache-misses 60,604330670 seconds time elapsed
En utilisant l'affinité CPU , la compilation avec -march=native , PGO , l'augmentation du nombre de hits dans le cache , l'augmentation de MAX_EVENTS et l'utilisation d' EPOLLET n'ont pas donné une augmentation significative des performances. Mais que se passe-t-il si vous augmentez le nombre de connexions simultanées?
Statistiques pour 352 connexions simultanées:
$ wrk -c352 -d1m -t8 http://127.0.0.1:18470 -H "Host: 127.0.0.1:18470" -H "Accept-Language: en-US,en;q=0.5" -H "Connection: keep-alive" Running 1m test @ http://127.0.0.1:18470 8 threads and 352 connections Thread Stats Avg Stdev Max +/- Stdev Latency 2.12ms 3.79ms 68.23ms 87.49% Req/Sec 83.78k 12.69k 169.81k 83.59% 40006142 requests in 1.00m, 5.48GB read Requests/sec: 665789.26 Transfer/sec: 93.34MB
Le résultat souhaité a été obtenu, et avec lui un graphique intéressant montrant la dépendance du nombre de demandes traitées en 1 minute sur le nombre de connexions:
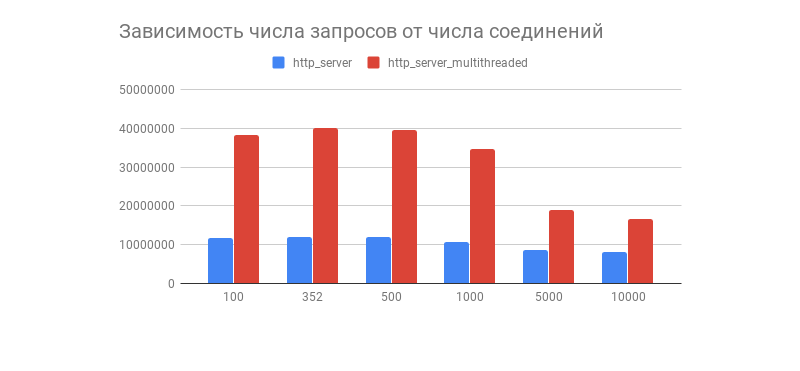
Nous voyons qu'après quelques centaines de connexions, le nombre de demandes traitées des deux serveurs diminue fortement (dans une version multithread, c'est plus visible). Est-ce lié à l'implémentation de la pile TCP / IP Linux? N'hésitez pas à écrire vos hypothèses sur ce comportement de graphique et les optimisations des options multithread et monothread dans les commentaires.
Comme indiqué dans les commentaires, ce test de performance ne montre pas le comportement du réacteur d'E / S à des charges réelles, car presque toujours le serveur interagit avec la base de données, affiche les journaux, utilise la cryptographie avec TLS , etc., à la suite de quoi la charge devient hétérogène (dynamique). Des tests ainsi que des composants tiers seront effectués dans un article sur le proacteur d'E / S.
Inconvénients du réacteur d'E / S
Vous devez comprendre que le réacteur d'E / S n'est pas sans inconvénients, à savoir:
- L'utilisation d'un réacteur d'E / S dans un environnement multithread est un peu plus difficile, car vous devez gérer manuellement les flux.
- La pratique montre que dans la plupart des cas, la charge est hétérogène, ce qui peut conduire au fait qu'un thread sera déposé tandis que l'autre est chargé de travail.
- Si un gestionnaire d'événements bloque le flux, le sélecteur de système lui-même sera également bloqué, ce qui peut entraîner des bogues difficiles à détecter.
Ces problèmes sont résolus par le processeur d'E / S , souvent avec un planificateur qui distribue uniformément la charge au pool de threads, et dispose également d'une API plus pratique. Il sera discuté plus tard dans mon autre article.
Conclusion
Sur ce point, notre voyage de la théorie directement au profileur d'échappement a pris fin.
Ne vous attardez pas là-dessus, car il existe de nombreuses autres approches tout aussi intéressantes pour écrire des logiciels réseau avec différents niveaux de commodité et de vitesse. À mon avis, les liens sont intéressants ci-dessous.
A très bientôt!
Projets intéressants
Que lire d'autre?