Salut Aujourd'hui, je vais expliquer aux lecteurs de Habr comment nous avons créé une technologie de reconnaissance de texte qui fonctionne dans 45 langues et est accessible aux utilisateurs de Yandex.Cloud, quelles tâches nous avons définies et comment nous les avons résolues. Il sera utile si vous travaillez sur des projets similaires ou si vous voulez savoir comment cela s'est passé. Aujourd'hui, il vous suffit de photographier une enseigne d'un magasin turc pour qu'Alice la traduise en russe.

La technologie de reconnaissance optique de caractères (OCR) se développe dans le monde depuis des décennies. Chez Yandex, nous avons commencé à développer notre propre technologie OCR pour améliorer nos services et offrir aux utilisateurs plus d'options. Les images représentent une grande partie d'Internet et sans la capacité de les comprendre, la recherche sur Internet sera incomplète.
Les solutions d'analyse d'images sont de plus en plus populaires. Cela est dû à la prolifération de réseaux de neurones artificiels et d'appareils dotés de capteurs de haute qualité. Il est clair que nous parlons tout d'abord de smartphones, mais pas seulement d'eux.
La complexité des tâches dans le domaine de la reconnaissance de texte est en constante augmentation - tout a commencé avec la reconnaissance des documents numérisés. Ensuite, la
reconnaissance des images Born-Digital avec du texte provenant d'Internet a été ajoutée. Ensuite, avec la popularité croissante des caméras mobiles, la reconnaissance des bons plans de caméra (
texte de scène focalisé ). Et plus les paramètres sont compliqués: le texte peut être flou (
texte de scène incidente ),
écrit avec n'importe quel coude ou en spirale, de différentes catégories - des
photographies de reçus aux
étagères et enseignes.
Dans quelle direction sommes-nous allés
La reconnaissance de texte est une classe distincte de tâches de vision par ordinateur. Comme de nombreux algorithmes de vision par ordinateur, avant la popularité des réseaux de neurones, il était largement basé sur des fonctionnalités manuelles et des heuristiques. Cependant, récemment, avec la transition vers des approches de réseau de neurones, la qualité de la technologie a considérablement augmenté. Regardez l'exemple sur la photo. Comment cela s'est produit, je le dirai plus loin.
Comparez les résultats de reconnaissance d'aujourd'hui avec les résultats de début 2018:
Quelles difficultés avons-nous rencontrées au début?
Au début de notre voyage, nous avons créé une technologie de reconnaissance pour le russe et l'anglais, et les principaux cas d'utilisation étaient des pages de texte et des images photographiées sur Internet. Mais au cours du travail, nous avons réalisé que cela ne suffisait pas: le texte sur les images se trouvait dans n'importe quelle langue, sur n'importe quelle surface, et les images s'avéraient parfois de qualité très différente. Cela signifie que la reconnaissance devrait fonctionner dans toutes les situations et sur tous les types de données entrantes.
Et ici, nous sommes confrontés à un certain nombre de difficultés. Voici quelques exemples:
- Détails Pour une personne habituée à obtenir des informations à partir d'un texte, le texte de l'image est constitué de paragraphes, de lignes, de mots et de lettres, mais pour un réseau de neurones, tout semble différent. En raison de la nature complexe du texte, le réseau est obligé de voir à la fois l'image dans son ensemble (par exemple, si les gens se sont joints la main et ont construit une inscription), et les plus petits détails (dans la langue vietnamienne, les symboles similaires ử et ừ changent la signification des mots). Des défis distincts consistent à reconnaître le texte arbitraire et les polices non standard.
- Multilinguisme . Plus nous ajoutions de langues, plus nous étions confrontés à leurs spécificités: en cyrillique et en latin, les mots sont composés de lettres séparées, en arabe ils sont écrits ensemble, en japonais aucun mot séparé n'est distingué. Certaines langues utilisent l'orthographe de gauche à droite, d'autres de droite à gauche. Certains mots sont écrits horizontalement, d'autres verticalement. Un outil universel devrait prendre en compte toutes ces fonctionnalités.
- La structure du texte . Pour reconnaître des images spécifiques, telles que des chèques ou des documents complexes, une structure qui prend en compte la disposition des paragraphes, des tableaux et d'autres éléments est cruciale.
- Performance . La technologie est utilisée sur une grande variété d'appareils, y compris hors ligne, nous avons donc dû tenir compte des exigences de performances strictes.
Sélection du modèle de détection
La première étape pour reconnaître un texte consiste à déterminer sa position (détection).
La détection de texte peut être considérée comme une tâche de reconnaissance d'objet, où des
caractères ,
mots ou
lignes individuels peuvent agir comme un objet.
Il était important pour nous que le modèle soit ensuite mis à l'échelle vers d'autres langues (nous prenons désormais en charge 45 langues).
De nombreux articles de recherche sur la détection de texte utilisent des modèles qui prédisent la position des
mots individuels. Mais dans le cas d'un
modèle universel, cette approche a plusieurs limites - par exemple, le concept même d'un mot pour la langue chinoise est fondamentalement différent du concept d'un mot, par exemple, en anglais. Les mots individuels en chinois ne sont pas séparés par un espace. En thaï, seules les phrases simples sont supprimées avec un espace.
Voici des exemples du même texte en russe, chinois et thaï:
. .
今天天气很好 这是一个美丽的一天散步。
สภาพอากาศสมบูรณ์แบบในวันนี้ มันเป็นวันที่สวยงามสำหรับเดินเล่นกันหน่อยแล้วLes lignes , à leur tour, sont très variables en termes de rapport d'aspect. De ce fait, les possibilités de ces modèles de détection communs (par exemple, basés sur SSD ou RCNN) pour la prédiction de ligne sont limitées, car ces modèles sont basés sur des régions / boîtes d'ancrage candidates avec de nombreux rapports d'aspect prédéfinis. De plus, les lignes peuvent avoir une forme arbitraire, par exemple courbe, donc pour une description qualitative des lignes il ne suffit pas de décrire exclusivement un quad, même avec un angle de rotation.
Malgré le fait que les positions des
caractères individuels
sont locales et décrites, leur inconvénient est qu'une étape de post-traitement distinct est requise - vous devez sélectionner des heuristiques pour coller des caractères en mots et en lignes.
Par conséquent, nous avons pris
le modèle SegLink comme base de détection, dont l'idée principale est de décomposer les lignes / mots en deux entités plus locales: les segments et les relations entre eux.
Architecture du détecteur
L'architecture du modèle est basée sur SSD, qui prédit la position des objets à plusieurs échelles de fonctionnalités. Ce n'est qu'en plus de prédire les coordonnées des «segments» individuels que sont également prédites les «connexions» entre les segments adjacents, c'est-à-dire si deux segments appartiennent à la même ligne. Des «connexions» sont prévues à la fois pour les segments voisins sur la même échelle d'entités et pour les segments situés dans des zones adjacentes à des échelles adjacentes (les segments d'échelles d'entités différentes peuvent varier légèrement en taille et appartiennent à la même ligne).
Pour chaque échelle, chaque cellule d'entité est associée à un «segment» correspondant. Pour chaque segment s
(x, y, l) au point (x, y) sur une échelle l, on suit:
- p
s si le segment donné est du texte;
- x
s , y
s , w
s , h
s , θ
s - le décalage des coordonnées de base et l'angle d'inclinaison du segment;
- 8 scores pour la présence de «connexions» avec des segments adjacents à la l-ième échelle (L
w s, s ' , s' from {s
(x ', y', l) } / s
(x, y, l) , où x –1 ≤ x '≤ x + 1, y - 1 ≤ y' ≤ y + 1);
- 4 scores pour la présence de «connexions» avec des segments adjacents à l'échelle l-1 (L
c s, s ' , s' de {s
(x ', y', l-1) }, où 2x ≤ x '≤ 2x + 1 , 2y ≤ y '≤ 2y + 1) (ce qui est vrai du fait que la dimension des entités aux échelles voisines diffère exactement de 2 fois).
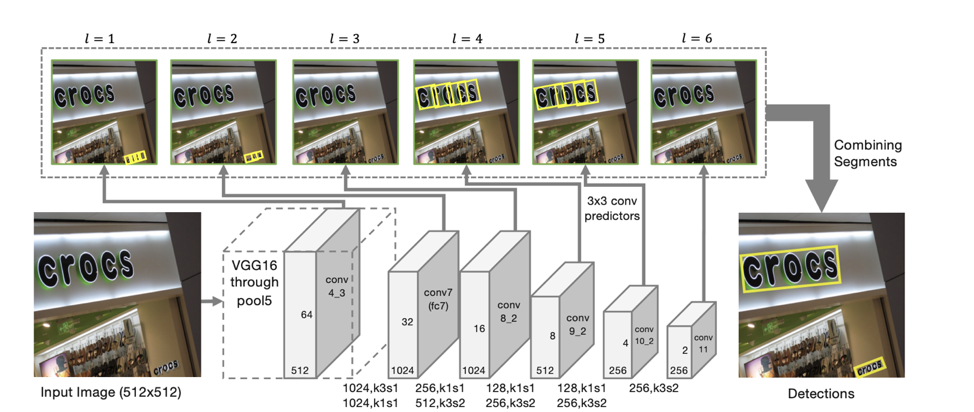
Selon de telles prédictions, si nous prenons comme sommets tous les segments pour lesquels la probabilité qu'ils soient du texte est supérieure au seuil α, et comme les arêtes sont toutes des liaisons dont la probabilité est supérieure au seuil β, alors les segments forment des composants connectés, chacun décrivant une ligne de texte .
Le modèle résultant a une
grande capacité de généralisation : même formé aux premières approches sur les données russes et anglaises, il a trouvé qualitativement du texte chinois et arabe.
Dix scripts
Si pour la détection, nous avons pu créer un modèle qui fonctionne immédiatement pour toutes les langues, alors pour la reconnaissance des lignes trouvées, un tel modèle est beaucoup plus difficile à obtenir. Par conséquent, nous avons décidé d'utiliser un
modèle distinct pour chaque script (cyrillique, latin, arabe, hébreu, grec, arménien, géorgien, coréen, thaï). Un modèle général distinct est utilisé pour le chinois et le japonais en raison de la grande intersection des hiéroglyphes.
Le modèle commun à l'ensemble du script diffère du modèle distinct pour chaque langue par moins de 1 p.p. la qualité. Dans le même temps, la création et la mise en œuvre d'un modèle est plus simple que, par exemple, 25 modèles (le nombre de langues latines prises en charge par notre modèle). Mais en raison de la présence fréquente de l'anglais dans toutes les langues, tous nos modèles sont capables de prédire, en plus du script principal, des caractères latins.
Pour comprendre quel modèle doit être utilisé pour la reconnaissance, nous déterminons d'abord si les lignes reçues appartiennent à l'un des 10 scripts disponibles pour la reconnaissance.
Il convient de noter séparément qu'il n'est pas toujours possible de déterminer de manière unique son script le long de la ligne. Par exemple, de nombreux scripts ou caractères latins uniques sont contenus dans de nombreux scripts, de sorte qu'une des classes de sortie du modèle est un script "non défini".
Définition de script
Pour définir le script, nous avons créé un classificateur distinct. La tâche de définir un script est beaucoup plus simple que la tâche de reconnaissance, et le réseau neuronal est facilement recyclé sur des données synthétiques. Par conséquent, dans nos expériences, une
pré-formation sur le problème de reconnaissance des cordes a permis une amélioration significative de la qualité du modèle. Pour ce faire, nous avons d'abord formé le réseau au problème de reconnaissance pour toutes les langues disponibles. Après cela, l'épine dorsale résultante a été utilisée pour initialiser le modèle à la tâche de classification de script.
Alors qu'un script sur une ligne individuelle est souvent assez bruyant, l'image dans son ensemble contient le plus souvent du texte dans une langue, soit en plus du principal entrecoupé d'anglais (ou dans le cas de nos utilisateurs russes). Par conséquent, pour
augmenter la stabilité, nous agrégons les prédictions des lignes de l'image afin d'obtenir une prédiction plus stable du script d'image. Les lignes avec une classe prédite «indéfinie» ne sont pas prises en compte dans l'agrégation.
Reconnaissance de ligne
L'étape suivante, lorsque nous avons déjà déterminé la position de chaque ligne et son script, nous devons
reconnaître la séquence de caractères du script donné qui y est affiché, c'est-à-dire de la séquence de pixels pour prédire la séquence de caractères. Après de nombreuses expériences, nous sommes arrivés au modèle suivant basé sur l'attention de sequence2sequence:

L'utilisation de CNN + BiLSTM dans l'encodeur vous permet d'obtenir des signes qui capturent les contextes local et mondial. Pour le texte, cela est important - il est souvent écrit dans une seule police (il est beaucoup plus facile de distinguer des lettres similaires avec des informations sur la police). Et pour distinguer deux lettres écrites avec un espace de celles consécutives, des statistiques globales sont également nécessaires pour la ligne.
Une observation intéressante : dans le modèle résultant, les sorties du masque d'attention pour un symbole particulier peuvent être utilisées pour prédire sa position dans l'image.
Cela nous a inspiré pour essayer de
«concentrer» clairement l’attention du modèle . De telles idées ont également été trouvées dans des articles - par exemple, dans l'article
Focusing Attention: Towards Accurate Text Recognition in Natural Images .
Étant donné que le mécanisme d'attention donne une distribution de probabilité sur l'espace des caractéristiques, si nous prenons comme perte supplémentaire la somme des sorties d'attention à l'intérieur du masque correspondant à la lettre prédite à cette étape, nous obtiendrons la partie de «l'attention» qui se concentre directement sur lui.
En introduisant la perte -log (∑
i, j∈M t α
i, j ), où M
t est le masque de la tième lettre, α est la sortie de l'attention, nous encouragerons «l'attention» à se concentrer sur le symbole donné et ainsi aider les réseaux de neurones apprennent mieux.
Pour les exemples d'entraînement pour lesquels l'emplacement des caractères individuels est inconnu ou inexact (toutes les données d'entraînement n'ont pas de marquages au niveau des caractères individuels, pas des mots), ce terme n'a pas été pris en compte dans la perte finale.
Autre fonctionnalité intéressante: cette architecture vous permet de prédire la
reconnaissance des lignes de droite à gauche sans modifications supplémentaires (ce qui est important, par exemple, pour des langues comme l'arabe, l'hébreu). Le modèle lui-même commence à émettre une reconnaissance de droite à gauche.
Modèles rapides et lents
Dans le processus, nous avons rencontré un problème:
pour les polices «hautes» , c'est-à-dire les polices allongées verticalement, le modèle fonctionnait mal. Cela est dû au fait que la dimension des signes au niveau de l'attention est 8 fois plus petite que la dimension de l'image d'origine en raison de foulées et de tiraillements dans l'architecture de la partie convolutionnelle du réseau. Et les emplacements de plusieurs caractères voisins dans l'image source peuvent correspondre à l'emplacement du même vecteur caractéristique, ce qui peut entraîner des erreurs dans de tels exemples. L'utilisation d'une architecture avec un rétrécissement moindre de la dimension des fonctionnalités a conduit à une augmentation de la qualité, mais aussi à une augmentation du temps de traitement.
Pour résoudre ce problème et
éviter d'augmenter le temps de traitement , nous avons apporté les améliorations suivantes au modèle:
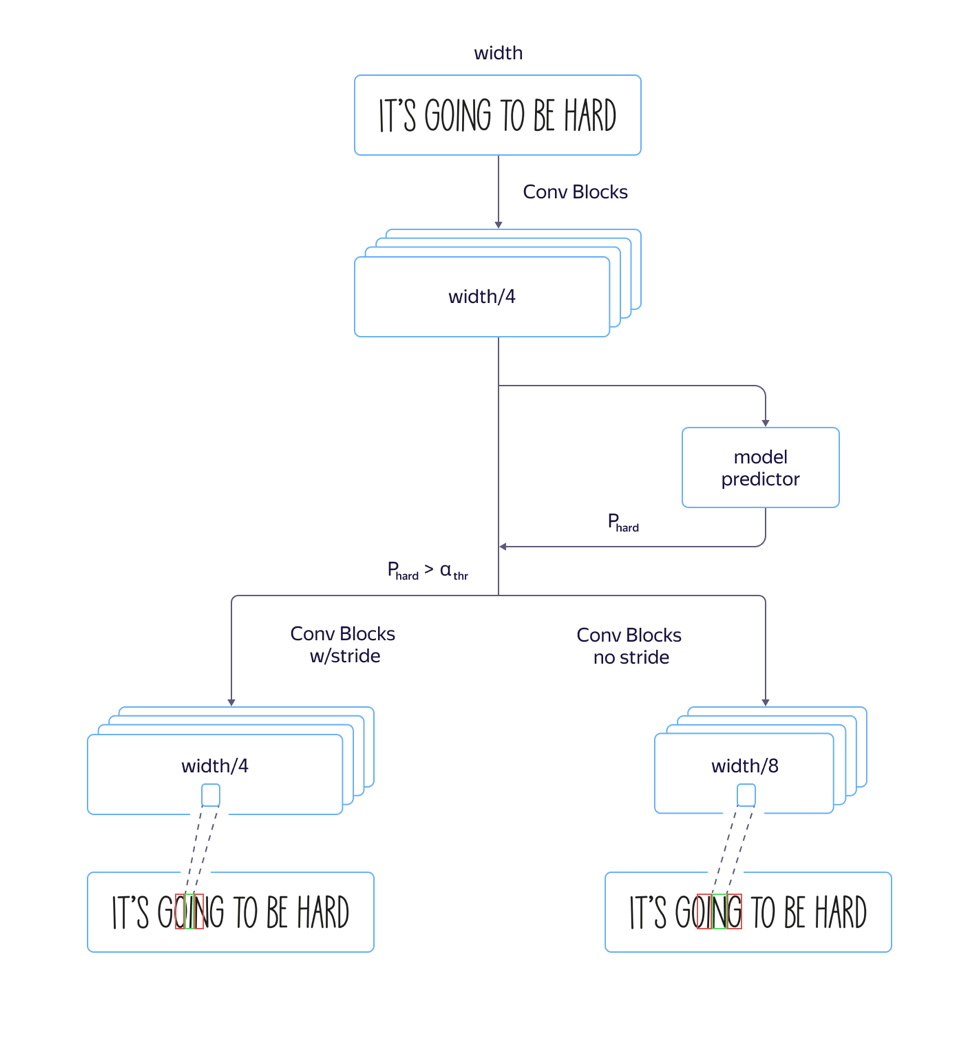
Nous avons formé à la fois un modèle rapide avec beaucoup de foulées et un modèle lent avec moins. Sur la couche où les paramètres du modèle ont commencé à différer, nous avons ajouté une sortie réseau distincte qui prédit quel modèle aurait moins d'erreur de reconnaissance. La perte totale du modèle était composée de la
qualité L
small + L
big + L. Ainsi, sur la couche intermédiaire, le modèle a appris à déterminer la «complexité» de cet exemple. De plus, au stade de l'application, la partie générale et la prédiction de la «complexité» de l'exemple ont été prises en compte pour toutes les lignes, et selon sa sortie, le modèle rapide ou le modèle lent a été utilisé à l'avenir en fonction de la valeur seuil. Cela nous a permis d'obtenir une qualité qui n'est presque pas différente de la qualité d'un modèle long, tandis que la vitesse n'a augmenté que de 5% au lieu des 30% estimés.
Données d'entraînement
Une étape importante dans la création d'un modèle de haute qualité est la préparation d'un échantillon de formation large et varié. La nature "synthétique" du texte permet de générer de grandes quantités d'exemples et d'obtenir des résultats décents sur des données réelles.
Après la première approche de la génération de données synthétiques, nous avons soigneusement examiné les résultats du modèle obtenu et avons constaté que le modèle ne reconnaît pas bien les lettres simples `` I '' en raison du biais dans les textes utilisés pour créer l'ensemble d'apprentissage. Par conséquent, nous avons clairement généré un
ensemble d'exemples «problématiques» , et lorsque nous l'avons ajouté aux données initiales du modèle, la qualité a considérablement augmenté. Nous avons répété ce processus à plusieurs reprises, en ajoutant des tranches de plus en plus complexes, sur lesquelles nous voulions améliorer la qualité de la reconnaissance.
Le point important est que les
données générées
doivent être diverses et similaires aux vraies . Et si vous souhaitez que le modèle fonctionne sur des photographies de texte sur des feuilles de papier et que l'ensemble de données synthétiques contient du texte écrit au-dessus de paysages, cela peut ne pas fonctionner.
Une autre étape importante consiste à utiliser pour la formation des exemples sur lesquels la reconnaissance actuelle est erronée. S'il y a un grand nombre d'images pour lesquelles il n'y a pas de majoration, vous pouvez prendre les sorties du système de reconnaissance actuel dans lesquelles elle n'est pas sûre, et les marquer uniquement, réduisant ainsi le coût du balisage.
Pour des exemples complexes, nous avons demandé aux utilisateurs du service Yandex.Tolok des frais pour photographier et nous envoyer des
images d'un certain groupe «complexe» - par exemple, des photos de colis de marchandises:


Qualité du travail sur les données "complexes"
Nous voulons donner à nos utilisateurs la possibilité de travailler avec des photographies de toute complexité, car il peut être nécessaire de reconnaître ou de traduire le texte non seulement sur la page du livre ou le document numérisé, mais également sur une plaque de rue, une annonce ou un emballage de produit. Par conséquent, tout en maintenant la haute qualité du travail sur le flux des livres et des documents (nous consacrerons une histoire distincte à ce sujet), nous accordons une attention particulière aux «ensembles d'images complexes».
De la manière décrite ci-dessus, nous avons compilé un ensemble d'images contenant du texte à l'état sauvage qui peuvent être utiles à nos utilisateurs: photographies d'enseignes, annonces, tablettes, couvertures de livres, textes sur les appareils électroménagers, les vêtements et les objets. Sur cet ensemble de données (dont le lien est ci-dessous), nous avons évalué la qualité de notre algorithme.
En tant que mesure de comparaison, nous avons utilisé la mesure standard d'exactitude et d'exhaustivité de la reconnaissance des mots dans l'ensemble de données, ainsi que la mesure F. Un mot reconnu est considéré comme correctement trouvé si ses coordonnées correspondent aux coordonnées du mot balisé (IoU> 0,3) et la reconnaissance coïncide avec le balisé exactement au cas. Chiffres sur l'ensemble de données résultant:
L'ensemble de données, les métriques et les scripts pour reproduire les résultats sont disponibles
ici .
Upd. Mes amis, la comparaison de notre technologie avec une solution similaire d'Abbyy a suscité beaucoup de controverses. Nous respectons les opinions de la communauté et des pairs de l'industrie. Mais en même temps, nous sommes confiants dans nos résultats, nous avons donc décidé de cette façon: nous retirerons les résultats d'autres produits de la comparaison, discuterons de nouveau de la méthodologie de test avec eux et reviendrons sur les résultats dans lesquels nous arriverons à un accord général.
Prochaines étapes
À la jonction d'étapes individuelles, telles que la détection et la reconnaissance, des problèmes surviennent toujours: les moindres changements dans le modèle de détection entraînent la nécessité de changer le modèle de reconnaissance, nous expérimentons donc activement la création d'une solution de bout en bout.
En plus des moyens déjà décrits d'améliorer la technologie, nous développerons une direction d'analyse de la structure du document, qui est fondamentalement importante lors de l'extraction d'informations et qui est demandée par les utilisateurs.
Conclusion
Les utilisateurs sont déjà habitués aux technologies pratiques et, sans hésitation, allumez l’appareil photo, pointez le signe du magasin, le menu du restaurant ou la page du livre dans une langue étrangère et recevez rapidement une traduction. Nous reconnaissons le texte dans 45 langues avec une précision éprouvée, et les opportunités ne feront que s'élargir. Un ensemble d'outils à l'intérieur de Yandex.Cloud permet à quiconque souhaite utiliser les meilleures pratiques que Yandex fait depuis longtemps.
Aujourd'hui, vous pouvez simplement prendre la technologie finie, l'intégrer dans votre propre application et l'utiliser pour créer de nouveaux produits et automatiser vos propres processus. La documentation de notre OCR est disponible
ici .
Que lire:
- D. Karatzas, SR Mestre, J. Mas, F. Nourbakhsh et PP Roy, «ICDAR 2011 robust reading competition-challenge 1: reading text in born-digital images (web and email)», in Document Analysis and Recognition (ICDAR ), Conférence internationale de 2011 sur. IEEE, 2011, pp. 1485-1490.
- Karatzas D. et al. Concours ICDAR 2015 sur la lecture robuste // 2015 13e Conférence internationale sur l'analyse et la reconnaissance des documents (ICDAR). - IEEE, 2015 .-- S. 1156-1160.
- Chee-Kheng Chng et. al. ICDAR2019 Défi de lecture robuste sur le texte de forme arbitraire (RRC-ArT) [ arxiv: 1909.07145v1 ]
- Défi de lecture robuste ICDAR 2019 sur les OCR des reçus numérisés et l'extraction d'informations rrc.cvc.uab.es/?ch=13
- ShopSign: ensemble de données de texte de scènes diverses d'enseignes chinoises dans les vues de rue [ arxiv: 1903.10412 ]
- Baoguang Shi, Xiang Bai, Serge Belongie Détecter du texte orienté dans des images naturelles en liant des segments [ arxiv: 1703.06520 ].
- Zhanzhan Cheng, Fan Bai, Yunlu Xu, Gang Zheng, Shiliang Pu, Shuigeng Zhou Attirer l'attention: Vers une reconnaissance précise du texte dans les images naturelles [ arxiv: 1709.02054 ].