La traduction de l'article a été préparée spécialement pour les étudiants du cours "DevOps Practices and Tools" .
Cet article explique la relation entre la structure du code et la structure de l'organisation dans le développement de logiciels. Je discute des raisons pour lesquelles les logiciels et les équipes ne peuvent pas évoluer facilement, quelles leçons nous pouvons tirer de la nature et d'Internet, et montre comment nous pouvons réduire la connectivité des logiciels et des équipes pour surmonter les problèmes de mise à l'échelle.
Cet article est basé sur mes 20 années d'expérience dans la création de grands systèmes logiciels et sur l'impression du livre
«Accelerate: The Science of Lean Software and DevOps: Building and Scaling High Performing Technology Organizations» (Nicole Forsgren, Jez Humble and Gene Kim) recherche des preuves pour sauvegarder la plupart de mes revendications ici. Ce livre est fortement recommandé pour la lecture.

Le logiciel et les commandes ne sont pas évolutifs
Souvent, la première version, peut-être écrite par une ou deux personnes, est étonnamment simple. Il peut avoir des fonctionnalités limitées, mais il est écrit rapidement et répond aux exigences du client. L'interaction avec le client à ce stade est excellente, car le client est généralement en contact direct avec les développeurs. Tous les bugs sont corrigés rapidement et de nouvelles fonctionnalités peuvent être ajoutées sans douleur. Après un certain temps, le rythme ralentit. La version 2.0 prend un peu plus de temps que prévu. Il est plus difficile de corriger les bugs, et de nouvelles fonctionnalités sont proposées, ce n'est pas si simple. La réponse naturelle à cela consiste à ajouter de nouveaux développeurs à l'équipe. Bien qu'il semble que chaque employé supplémentaire ajouté à l'équipe réduise la productivité. On a le sentiment qu'à mesure que la complexité du logiciel augmente, il s'atrophie. Dans des cas extrêmes, les organisations peuvent constater qu'elles utilisent des programmes avec un support très coûteux qui sont presque impossibles à apporter des modifications. Le problème est que vous n'avez pas besoin de faire des «erreurs» pour que cela se produise. Il est si courant qu'on peut dire qu'il s'agit d'une propriété «naturelle» du logiciel.
Pourquoi cela se produit-il? Il y a deux raisons: celles liées au code et à l'équipe. Le code et les commandes ne évoluent pas bien.
À mesure que la base de code se développe, il devient de plus en plus difficile pour une personne de la comprendre. Il y a des limites cognitives fixes d'une personne. Et, bien qu'une personne puisse garder à l'esprit les détails d'un petit système, mais seulement jusqu'à ce qu'il devienne plus que sa portée cognitive. Dès qu'une équipe compte cinq personnes ou plus, il devient presque impossible pour une seule personne de savoir comment toutes les parties du système fonctionnent. Et quand personne ne comprend tout le système, la peur apparaît. Dans un grand système étroitement couplé, il est très difficile de comprendre l'effet de tout changement significatif, car le résultat n'est pas localisé. Pour minimiser l'impact des modifications, les développeurs commencent à utiliser des solutions de contournement et la duplication de code au lieu d'identifier les fonctionnalités communes, de créer des abstractions et des généralisations. Cela complique encore le système, renforçant ces tendances négatives. Les développeurs ne se sentent plus responsables du code qu'ils ne comprennent pas et hésitent à refactoriser. La dette technique augmente. Cela rend également le travail désagréable et insatisfaisant et stimule une «fuite des talents» lorsque les meilleurs développeurs partent qui peuvent facilement trouver du travail ailleurs.
Les équipes ne sont pas non plus évolutives. À mesure que les équipes se développent, la communication devient plus complexe. Une formule simple entre en jeu:
c = n(n-1)/2(où n est le nombre de personnes et c est le nombre de connexions possibles entre les membres de l'équipe)À mesure que son équipe grandit, ses besoins en communication et en coordination augmentent de façon exponentielle. Si une certaine équipe est dépassée, il est très difficile pour une équipe de rester une structure intégrale, et la tendance sociale humaine naturelle à se diviser en petits groupes conduira à la formation de sous-groupes informels, même si la direction n'y participe pas. La communication avec les collègues devient plus difficile et sera naturellement remplacée par de nouveaux dirigeants et des communications descendantes. Les membres de l'équipe sont transformés de pairs du système en travailleurs de production réguliers. La motivation en souffre, il n'y a pas de sentiment d'appropriation dû à l'
effet de diffusion de la responsabilité .
La direction intervient souvent à ce stade et aborde formellement la création de nouvelles équipes et structures de gestion. Mais, peu importe formellement ou officieusement, il est difficile pour les grandes organisations de maintenir leur motivation et leur intérêt.
Des développeurs généralement inexpérimentés et une mauvaise gestion blâment ces pathologies de mise à l'échelle. Mais c'est injuste. Les problèmes de mise à l'échelle sont une propriété «naturelle» des logiciels en croissance et en évolution. C'est ce qui se produit toujours si vous ne trouvez pas le problème à un stade précoce, ne comprenez pas le point de déviation et ne faites aucun effort pour résoudre le problème. Des équipes de développement de logiciels sont constamment constituées, la quantité de logiciels dans le monde augmente constamment et la plupart des logiciels sont relativement petits. Par conséquent, très souvent, un produit réussi et en développement est créé par une équipe qui n'a pas d'expérience dans le développement à grande échelle. Et il est irréaliste de s'attendre à ce que les développeurs reconnaissent le point d'inflexion et comprennent quoi faire lorsque des problèmes d'échelle commencent à se manifester.
Leçons de mise à l'échelle de la nature
J'ai récemment lu l'excellent livre de
Geoffrey West «Scale» . Il parle de mathématiques d'échelle dans les systèmes biologiques et socio-économiques. Sa thèse est que tous les grands systèmes complexes obéissent aux lois fondamentales de l'échelle. C'est une lecture fascinante et je la recommande vivement. Dans cet article, je veux me concentrer sur son point de vue selon lequel de nombreux systèmes biologiques et sociaux évoluent étonnamment bien. Regardez le corps d'un mammifère. Tous les mammifères ont les mêmes types de cellules, la même structure osseuse, les mêmes systèmes nerveux et circulatoire. Cependant, la différence de taille entre la souris et la baleine bleue est d'environ 10 ^ 7. Comment la nature utilise-t-elle les mêmes matériaux et la même structure pour des organismes de tailles différentes? La réponse semble être que l'évolution a découvert des structures ramifiées fractales. Regardez l'arbre. Chaque partie ressemble à un petit arbre. Il en va de même pour les systèmes circulatoire et nerveux des mammifères, ce sont des réseaux fractaux ramifiés où une petite partie de vos poumons ou vaisseaux sanguins ressemble à une version plus petite de l'ensemble.

Pouvons-nous prendre ces idées de la nature et les appliquer aux logiciels? Je pense que nous pouvons tirer des leçons importantes. Si nous pouvons construire de grands systèmes constitués de petites pièces qui ressemblent elles-mêmes à des systèmes complets, il sera possible de contenir les pathologies qui affectent la plupart des programmes à mesure qu'ils grandissent et se développent.
Existe-t-il des systèmes logiciels qui évoluent avec succès de plusieurs ordres de grandeur? La réponse est évidente: Internet, un système logiciel mondial avec des millions de nœuds. Les sous-réseaux ressemblent et fonctionnent vraiment comme des versions plus petites de tout Internet.
Signes de logiciels faiblement couplés
La capacité d'isoler des composants séparés et faiblement couplés dans un grand système est la principale méthode de mise à l'échelle réussie. Internet, en fait, est un exemple d'architecture faiblement couplée. Cela signifie que chaque nœud, service ou application sur le réseau a les propriétés suivantes:
- Un protocole de communication commun est utilisé.
- Les données sont transférées à l'aide d'un contrat clair avec d'autres nœuds.
- La communication ne nécessite pas la connaissance de technologies de mise en œuvre spécifiques.
- La gestion des versions et le déploiement sont indépendants.
Internet est évolutif car il s'agit d'un réseau de nœuds qui communiquent via un ensemble de protocoles bien définis. Les nœuds n'interagissent que par des protocoles, dont les détails de mise en œuvre ne doivent pas être connus des nœuds en interaction. L'Internet mondial n'est pas déployé en tant que système unique. Chaque nœud possède sa propre version et sa propre procédure de déploiement. Les nœuds individuels apparaissent et disparaissent indépendamment les uns des autres. La soumission aux protocoles Internet est la seule chose qui compte vraiment pour l'ensemble du système. Qui a créé chaque site, quand il a été créé ou supprimé, quelle version il a, quelles technologies et plates-formes spécifiques qu'il utilise, tout cela n'a rien à voir avec Internet dans son ensemble. C'est ce que nous entendons par logiciel faiblement couplé.
Signes d'une organisation faiblement couplée
Nous pouvons faire évoluer les équipes selon les mêmes principes:
- Chaque sous-équipe devrait ressembler à une petite organisation de développement de logiciels.
- Les processus internes et la communication d'équipe ne doivent pas dépasser l'équipe.
- Les technologies et processus utilisés pour implémenter le logiciel ne doivent pas être discutés en dehors de l'équipe.
- Les équipes ne doivent communiquer entre elles que sur des questions externes: protocoles communs, fonctionnalités, niveaux de service et ressources.
Les petites équipes de développement sont plus efficaces que les grandes, vous devez donc diviser les grandes équipes en petits groupes. Les leçons de la nature et d'Internet sont que les sous-groupes devraient ressembler à de petites organisations de développement de logiciels. De quelle taille sont-ils? Idéalement, d'une à cinq personnes.
L'important est que chaque équipe ressemble à une petite organisation indépendante de développement de logiciels. D'autres façons d'organiser les équipes sont moins efficaces. Il y a souvent une tentation de diviser une grande équipe en fonctions. Par conséquent, nous avons une équipe d'architectes, une équipe de développement, une équipe DBA, une équipe de testeurs, une équipe de déploiement et une équipe de support, mais cela ne résout aucun des problèmes de mise à l'échelle dont nous avons parlé ci-dessus. Toutes les équipes doivent participer au développement d'une fonctionnalité et souvent de manière itérative si vous souhaitez éviter la gestion de projet à la manière d'une cascade.
Les barrières de communication entre ces équipes fonctionnelles deviennent un obstacle majeur à une livraison efficace et rapide. Les équipes sont étroitement connectées car elles doivent partager des détails internes importants pour travailler ensemble. De plus, les intérêts des différentes équipes ne coïncident pas: les développeurs reçoivent généralement un prix pour les nouvelles fonctionnalités, des testeurs pour la qualité, un support pour la stabilité. Ces différents intérêts peuvent conduire à des conflits et à de mauvais résultats. Pourquoi les développeurs devraient-ils s'inquiéter des journaux s'ils ne les lisent jamais? Pourquoi les testeurs devraient-ils se soucier de la livraison s'ils sont responsables de la qualité?
Au lieu de cela, nous devons organiser des équipes pour des services faiblement couplés qui prennent en charge les fonctions métier, ou pour un groupe logique de fonctions. Chaque sous-commande doit concevoir, coder, tester, déployer et maintenir son propre logiciel. Très probablement, les membres d'une telle équipe seront des spécialistes de profil large et non des spécialistes étroits, car dans une petite équipe, il sera nécessaire de séparer ces rôles. Ils doivent se concentrer sur l'automatisation maximale des processus: tests automatisés, déploiement, surveillance. Les équipes doivent choisir leurs propres outils et concevoir l'architecture de leurs systèmes. Bien que les protocoles utilisés pour l'interaction des services doivent être déterminés au niveau de l'organisation, le choix des outils utilisés pour les mettre en œuvre doit être délégué aux équipes. Et cela correspond très bien au modèle DevOps.
Le niveau d'indépendance d'une équipe est le reflet du niveau de connectivité de l'ensemble de l'organisation. Idéalement, l'organisation devrait prendre en charge la fonctionnalité du logiciel et, en fin de compte, la valeur commerciale que l'équipe fournit, ainsi que le coût des ressources de l'équipe.
Dans ce cas, l'architecte logiciel joue un rôle important. Il ne doit pas se concentrer sur des outils et technologies spécifiques que les équipes utilisent ou interférer avec les détails de l'architecture interne des services. Au lieu de cela, il devrait se concentrer sur les protocoles et les interactions entre les différents services et la santé du système dans son ensemble.
Loi inversée de Conway: la structure organisationnelle doit modeler l'architecture cible
Comment la faible cohérence logicielle et la faible cohérence d'équipe s'associent-elles?
La loi de Conway stipule:
"Les organisations qui conçoivent des systèmes se limitent à une conception qui copie la structure de communication de cette organisation."
Ceci est basé sur l'observation que l'architecture d'un système logiciel reflétera la structure de l'organisation qui le crée. Nous pouvons «pirater» la loi de Conway en la retournant. Organisez nos équipes pour refléter notre architecture souhaitée. Dans cette optique, nous devons aligner les équipes à couplage lâche avec les composants logiciels à couplage lâche. Mais devrait-il s'agir d'une relation individuelle? Je pense, idéalement, oui. Bien qu'il semble que ce soit bien si une petite équipe travaille sur plusieurs services faiblement couplés. Je dirais que le point d'inflexion pour la mise à l'échelle est plus grand pour les équipes que pour les logiciels, donc ce style d'organisation semble acceptable. Il est important que les composants logiciels restent séparés, avec leurs propres versions et déploiement, même si certains d'entre eux sont développés par une seule équipe. Nous aimerions pouvoir scinder l'équipe si elle devient trop importante, avec le transfert des services développés à différentes équipes. Mais nous ne pouvons pas le faire si les services sont étroitement couplés ou partagent un processus, un contrôle de version ou un déploiement.
Il faut éviter le travail de plusieurs équipes sur les mêmes composants. Ceci est un anti-modèle. Et, dans un sens, encore pire que le travail d'une grande équipe avec une grande base de code, car les barrières de communication entre les équipes conduisent à un sentiment encore plus fort de manque de propriété et de contrôle.
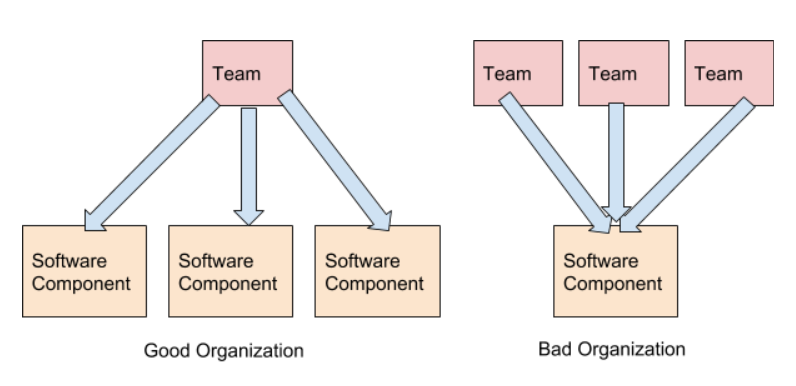
L'interaction entre des équipes faiblement couplées créant des logiciels faiblement couplés est minimisée. Reprenons l'exemple d'Internet. Souvent, vous pouvez utiliser l'API fournie par une autre entreprise sans aucune communication directe avec elle (si le processus est simple et qu'il existe de la documentation). Lorsque les équipes interagissent, les processus internes de développement et de mise en œuvre des équipes ne doivent pas être discutés. Au lieu de cela, la fonctionnalité, les niveaux de service et les ressources doivent être discutés.
La gestion d'équipes faiblement couplées créant des logiciels faiblement couplés devrait être plus facile que des alternatives. Une grande organisation doit se concentrer sur la fourniture aux équipes d'objectifs et d'exigences clairs en termes de fonctionnalités et de niveaux de service. Les besoins en ressources doivent provenir de l'équipe, bien qu'ils puissent être utilisés par l'organisation pour mesurer le retour sur investissement.
Les équipes à couplage lâche développent des logiciels à couplage lâche
Une faible connectivité dans les logiciels et entre les équipes est la clé pour bâtir une organisation hautement efficace. Et mon expérience confirme ce point. J'ai travaillé dans des organisations où les équipes étaient réparties par fonction, par niveau de logiciel, ou même où il y avait une séparation des clients. J'ai également travaillé dans de grandes équipes chaotiques sur une base de code unique. Mais dans tous ces cas, il y avait des problèmes de mise à l'échelle, qui ont été mentionnés ci-dessus. L'expérience la plus agréable a toujours été lorsque mon équipe était une unité à part entière, engagée indépendamment dans la création, les tests et le déploiement de services indépendants. Mais vous n'avez pas besoin de vous fier à mes histoires de vie. Accelerate (décrit ci-dessus) dispose de données de recherche pour étayer ce point de vue.
Si vous avez lu ce matériel jusqu'à la fin, nous vous recommandons de regarder un enregistrement d'un webinaire ouvert sur le sujet «Un jour dans la vie de DevOps» .