Bonjour et mon respect, lecteurs de Habr!
Contexte
Chez nous, il est d'usage d'échanger des résultats intéressants au sein des équipes de développement. Lors de la prochaine réunion, discutant de l'avenir de .NET et .NET 5 en particulier, mes collègues et moi nous sommes concentrés sur la vision d'une plate-forme unifiée à partir de cette image:
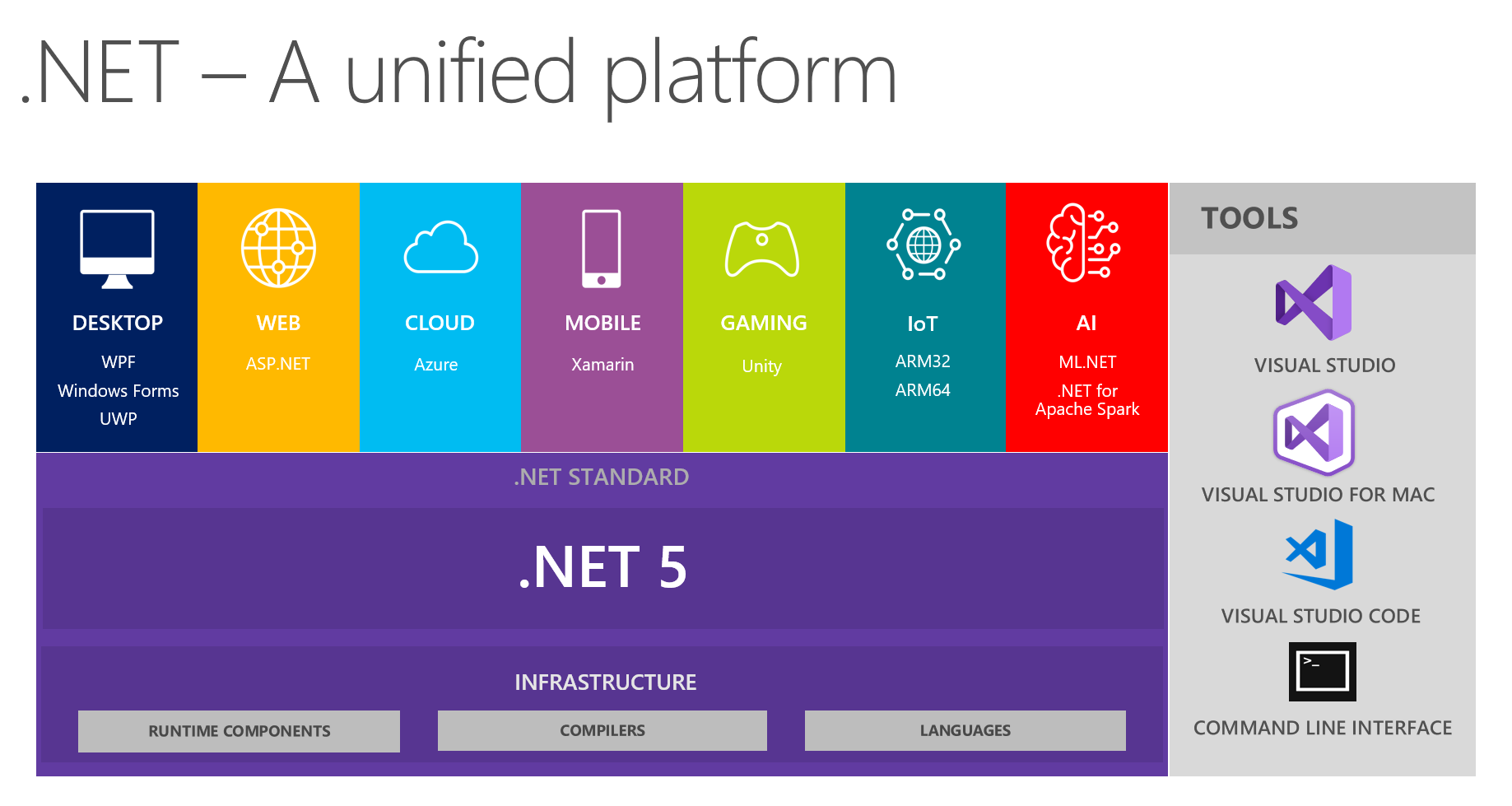
Cela montre que la plateforme combine DESKTOP, WEB, CLOUD, MOBILE, GAMING, IoT et AI. J'ai eu l'idée de mener une conversation sous la forme d'un petit rapport + questions / réponses sur chaque sujet lors des prochaines réunions. La personne responsable d'un sujet particulier se prépare au préalable, lit des informations sur les principales innovations, essaie de mettre en œuvre quelque chose en utilisant la technologie choisie, puis partage ses pensées et ses impressions avec nous. En conséquence, tout le monde reçoit de véritables commentaires sur les outils à partir d'une source de confiance - c'est très pratique, étant donné qu'essayer et prendre d'assaut tous les sujets vous-même peut ne pas être pratique, vos mains n'atteindront pas.
Depuis que je m'intéresse activement à l'apprentissage automatique comme passe-temps depuis un certain temps (et que je l'utilise parfois pour des tâches non professionnelles au travail), j'ai eu le sujet de l'IA et de ML.NET. Au cours de la préparation, je suis tombé sur de merveilleux outils et matériaux, à ma grande surprise, j'ai découvert qu'il y avait très peu d'informations à leur sujet sur Habré. Plus tôt dans le blog officiel, Microsoft a écrit sur la sortie de ML.Net , et de Model Builder en particulier. Je voudrais partager comment je suis venu à lui et quelles impressions j'ai eues en travaillant avec lui. L'article est plus sur Model Builder que ML dans .NET dans son ensemble; nous allons essayer de voir ce que MS offre au développeur .NET moyen, mais avec les yeux d'une personne avertie en ML. En même temps, j'essaierai de garder un équilibre entre la répétition du tutoriel, à mâcher absolument pour les débutants et la description des détails pour les spécialistes ML, qui pour une raison quelconque devaient venir sur .NET.
Corps principal
Ainsi, une recherche rapide sur ML dans .NET m'amène à la page du didacticiel :
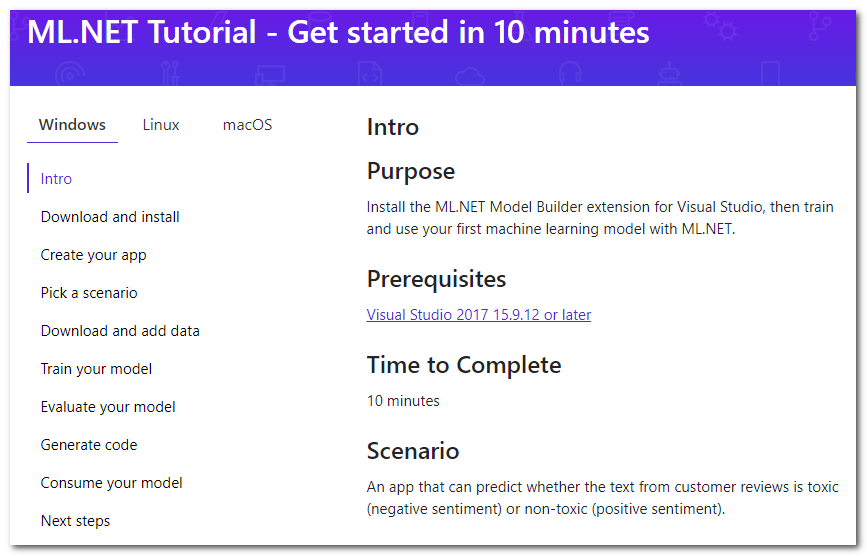
Il s'avère qu'il existe une extension spéciale pour Visual Studio appelée Model Builder, qui "vous permet d'ajouter l'apprentissage automatique à votre projet avec le bouton droit de la souris" (traduction gratuite). Je passerai brièvement en revue les principales étapes du tutoriel qui sont proposées à faire, j'ajouterai des détails et mes réflexions.
Téléchargez et installez
Appuyez sur le bouton, téléchargez, installez. Le studio devra redémarrer.
Créez votre appli
Tout d'abord, créez une application C # régulière. Dans le tutoriel, il est proposé de créer Core, mais convient également au Framework. Et puis, en fait, ML commence - faites un clic droit sur le projet, puis Ajouter -> Machine Learning. La fenêtre qui apparaîtra pour créer le modèle sera analysée, car c'est en elle que toute la magie opère.
Choisissez un scénario
Sélectionnez le "script" de votre application. Pour le moment, 5 sont disponibles (le tutoriel est un peu dépassé, il y en a 4 pour l'instant):
- Analyse des sentiments - analyse de la tonalité, classification binaire (classification binaire), le texte détermine sa couleur émotionnelle, positive ou négative.
- Classification des problèmes - la classification multiclasse, l'étiquette cible du problème (ticket, erreurs, appels d'assistance, etc.) peuvent être sélectionnées comme l'une des trois options mutuellement exclusives
- Prédiction des prix - régression, le problème de régression classique lorsque la sortie est un nombre continu; Dans l'exemple, il s'agit d'une estimation d'appartement
- Classification d'images - classification multiclasse, mais déjà pour les images
- Scénario personnalisé - votre scénario; Je suis obligé de pleurer qu’il n’y aura rien de nouveau dans cette option. À un stade ultérieur, ils me laisseront choisir l’une des quatre options décrites ci-dessus.
Notez qu'il n'y a pas de classification multi-étiquettes lorsque la méthode cible peut être multiple en même temps (par exemple, une déclaration peut être offensante, raciste et obscène en même temps, et ce n'est peut-être rien de tout cela). Pour les images, il n'y a pas d'option pour sélectionner une tâche de segmentation. Je suppose qu'avec l'aide du cadre, ils sont généralement résolubles, mais aujourd'hui nous nous concentrons sur le constructeur. Il semble que la mise à l'échelle de l'assistant pour augmenter le nombre de tâches n'est pas une tâche difficile, vous devez donc vous y attendre à l'avenir.
Télécharger et ajouter des données
Il est proposé de télécharger l'ensemble de données. De la nécessité de télécharger sur votre machine, nous concluons automatiquement que la formation aura lieu sur notre machine locale. Cela a les deux avantages:
- Vous contrôlez toutes les données, vous pouvez les corriger, les modifier localement et répéter les expériences.
- Vous ne téléchargez pas de données dans le cloud, préservant ainsi la confidentialité. Après tout, ne téléchargez pas, oui Microsoft ? :)
et contre:
- La vitesse d'apprentissage est limitée par les ressources de votre machine locale.
Il est en outre proposé de sélectionner l'ensemble de données téléchargé comme entrée de type "Fichier". Il existe également une option pour utiliser "SQL Server" - vous devrez spécifier les détails du serveur nécessaires, puis sélectionner la table. Si je comprends bien, il n'est pas encore possible de spécifier un script spécifique. Ci-dessous, j'écris sur les problèmes que j'ai rencontrés avec cette option.
Former votre modèle
À cette étape, différents modèles sont entraînés séquentiellement, la vitesse est affichée pour chacun et, à la fin, le meilleur est sélectionné. Oh oui, j'ai oublié de mentionner qu'il s'agit d'AutoML - c'est-à-dire le meilleur algorithme et les meilleurs paramètres (pas sûr, voir ci-dessous) seront sélectionnés automatiquement, vous n'avez donc rien à faire! Il est proposé de limiter le temps d'entraînement maximal au nombre de secondes. Heuristique pour la définition de cette période: https://github.com/dotnet/machinelearning-samples/blob/master/modelbuilder/readme.md#train . Sur ma machine, dans les 10 secondes par défaut, un seul modèle apprend, donc je dois miser beaucoup plus. On commence, on attend.
Ici, je veux vraiment ajouter que les noms des modèles me semblaient un peu inhabituels, par exemple: AveragedPerceptronBinary, FastTreeOva, SdcaMaximumEntropyMulti. Le mot «Perceptron» n'est pas utilisé très souvent de nos jours, «Ova» est probablement un contre tous et «FastTree», j'ai du mal à dire quoi.
Un autre fait intéressant est que LightGbmMulti fait partie des algorithmes candidats. Si je comprends bien, il s'agit du même LightGBM, le moteur de renforcement de gradient qui, avec CatBoost, est maintenant en concurrence avec la règle une fois seule de XGBoost. Il est un peu frustré par sa vitesse dans la performance actuelle - selon mes données, son entraînement a pris le plus de temps (environ 180 secondes). Bien que l'entrée soit du texte, après avoir vectorisé des milliers de colonnes de plus que les exemples d'entrée, ce n'est pas le meilleur cas pour le boosting et les arbres en général.
Évaluez votre modèle
En fait, l'évaluation des résultats du modèle. À cette étape, vous pouvez voir quelles mesures cibles ont été atteintes et piloter le modèle en direct. Les métriques elles-mêmes peuvent être lues ici: MS et sklearn .
J'étais principalement intéressé par la question - sur quoi a été testé? Une recherche sur la même page d'aide donne une réponse - la partition est très conservatrice, 80% à 20%. Je n'ai pas trouvé la possibilité de configurer cela dans l'interface utilisateur. En pratique, je voudrais contrôler cela, car quand il y a vraiment beaucoup de données, la partition peut même être de 99% et 1% (selon Andrew Ng, je n'ai pas moi-même travaillé avec de telles données). Il serait également utile de pouvoir définir un échantillonnage aléatoire des données sur les semences, car la répétabilité pendant la construction et la sélection du meilleur modèle est difficile à surestimer. Il semble que l'ajout de ces options ne soit pas difficile, pour maintenir la transparence et la simplicité, vous pouvez les masquer derrière certaines cases d'options supplémentaires.
Dans le processus de construction du modèle, des tablettes avec des indicateurs de vitesse sont affichées sur la console, dont le code de génération peut être trouvé dans les projets de l'étape suivante. Nous pouvons conclure que le code généré fonctionne vraiment, et sa sortie honnête est sortie, pas de faux.
Une observation intéressante - en écrivant l'article, j'ai une fois de plus parcouru les étapes du constructeur, utilisé le jeu de données proposé de commentaires de Wikipedia. Mais comme tâche, j'ai choisi "Personnalisé", puis une classification multiclasse comme cible (bien qu'il n'y ait que deux classes). En conséquence, la vitesse s'est avérée être environ 10% pire (environ 73% contre 83%) que la vitesse de la capture d'écran avec une classification binaire. Pour moi, c'est un peu étrange, car le système aurait pu deviner qu'il n'y avait que deux classes. En principe, les classificateurs du type un contre tous (à la fois contre tous, lorsque le problème de classification multiclasse est réduit à la solution séquentielle de problèmes N-binaires pour chacune des N classes) devraient également afficher une vitesse binaire similaire dans cette situation.
Générer du code
À cette étape, deux projets seront générés et ajoutés à la solution. L'un d'eux a un exemple à part entière de l'utilisation du modèle, et l'autre ne doit être examiné que si les détails de mise en œuvre sont intéressants.
Pour moi, j'ai découvert que l'ensemble du processus d'apprentissage est concisément formé dans un pipeline (bonjour aux disciplines de sk-learn):
// Data process configuration with pipeline data transformations var processPipeline = mlContext.Transforms.Conversion.MapValueToKey("Sentiment", "Sentiment") .Append(mlContext.Transforms.Text.FeaturizeText("SentimentText_tf", "SentimentText")) .Append(mlContext.Transforms.CopyColumns("Features", "SentimentText_tf")) .Append(mlContext.Transforms.NormalizeMinMax("Features", "Features")) .AppendCacheCheckpoint(mlContext);
(légèrement touché la mise en forme du code pour s'adapter parfaitement)
Rappelez-vous, je parlais des paramètres? Je ne vois aucun paramètre personnalisé, toutes les valeurs par défaut. Soit dit en passant, en utilisant l'étiquette SentimentText_tf sur la sortie de FeaturizeText nous pouvons conclure qu'il s'agit d'une fréquence de terme (la documentation indique qu'il s'agit de n-grammes et de char-grammes du texte; je me demande s'il existe une IDF, fréquence de document inversée).
Consommez votre modèle
En fait, un exemple d'utilisation. Je peux seulement noter que Predict se fait de manière élémentaire.
Eh bien, c'est tout, en fait - nous avons examiné toutes les étapes du constructeur et noté les points clés. Mais cet article serait incomplet sans un test sur ses propres données, car quiconque a déjà rencontré ML et AutoML sait très bien que n'importe quelle machine est bonne pour les tâches standard, les tests synthétiques et les jeux de données sur Internet. Par conséquent, il a été décidé de vérifier le constructeur sur leurs tâches; ci-après, c'est toujours travailler avec du texte ou du texte + des caractéristiques catégorielles.
Ce n'était pas une coïncidence si j'avais en main un ensemble de données avec quelques erreurs / problèmes / défauts enregistrés sur l'un des projets. Il a 2949 lignes, 8 classes cibles déséquilibrées, 4 Mo.
ML.NET (chargement, conversions, algorithmes de la liste ci-dessous; a pris 219 secondes)
| Top 2 models explored | -------------------------------------------------------------------------------- | Trainer MicroAccuracy MacroAccuracy Duration #Iteration| |1 SdcaMaximumEntropyMulti 0,7475 0,5426 176,7 1| |2 AveragedPerceptronOva 0,7128 0,4492 42,4 2| --------------------------------------------------------------------------------
(vides piqués dans la plaque pour tenir dans Markdown)
Ma version Python (chargement, nettoyage , conversion, puis LinearSVC; a pris 41 secondes):
Classsification report: precision recall f1-score support Class 1 0.71 0.61 0.66 33 Class 2 0.50 0.60 0.55 5 Class 3 0.65 0.58 0.61 59 Class 4 0.75 0.60 0.67 5 Class 5 0.78 0.86 0.81 77 Class 6 0.75 0.46 0.57 13 Class 7 0.82 0.90 0.86 227 Class 8 0.86 0.79 0.82 169 accuracy 0.80 588 macro avg 0.73 0.67 0.69 588 weighted avg 0.80 0.80 0.80 588
0,80 vs 0,747 Micro et 0,73 vs 0,542 Macro (il peut y avoir une inexactitude dans la définition de Macro, si c'est intéressant, je vous le dirai dans les commentaires).
Je suis agréablement surpris, seulement 5% de la différence. Sur certains autres ensembles de données, la différence était encore plus petite, et parfois pas du tout. Lors de l'analyse de l'ampleur de la différence, il convient de prendre en compte le fait que le nombre d'échantillons dans les jeux de données est petit, et parfois, après le prochain téléchargement (quelque chose est supprimé, quelque chose est ajouté), j'ai observé des mouvements de vitesse de 2 à 5%.
Pendant que j'expérimentais par moi-même, il n'y avait aucun problème en utilisant le constructeur. Cependant, lors de la présentation, les collègues ont quand même rencontré plusieurs jambages:
- Nous avons essayé de charger honnêtement l'un des ensembles de données de la table dans la base de données, mais nous sommes tombés sur un message d'erreur non informatif. J'ai eu une idée approximative du type de plan des données textuelles et j'ai immédiatement compris que le problème pouvait être lié aux sauts de ligne. Eh bien, j'ai téléchargé le jeu de données à l'aide de pandas.read_csv , l' ai nettoyé de \ n \ r \ t, l'ai enregistré dans tsv et j'ai continué .
- Au cours de la formation du modèle suivant, ils ont reçu une exception signalant qu'une matrice de taille ~ 220 000 pour 1000 ne peut pas tenir confortablement en mémoire, de sorte que la formation est arrêtée. Le modèle n'a pas non plus été généré. Que faire ensuite n'est pas clair, nous sommes sortis de la situation en substituant la limite de temps d'apprentissage «à l'œil» - pour que l'algorithme de chute n'ait pas le temps de commencer à fonctionner.
Soit dit en passant, à partir du deuxième paragraphe, nous pouvons conclure que le nombre de mots et de n-grammes pendant la vectorisation n'est pas vraiment limité par la limite supérieure, et "n" est probablement égal à deux. Je peux dire de ma propre expérience que 200k est clairement trop. Habituellement, il est soit limité aux occurrences les plus fréquentes, soit appliqué à différents types d'algorithmes de réduction dimensionnelle, par exemple SVD ou PCA.
Conclusions
Le constructeur propose un choix de plusieurs scénarios dans lesquels je n'ai pas trouvé d'endroits critiques nécessitant une immersion en ML. De ce point de vue, il est parfait comme outil de "démarrage" ou de résolution de problèmes simples typiques ici et maintenant. Les cas d'utilisation réels dépendent entièrement de votre imagination. Vous pouvez opter pour les options offertes par MS:
- pour résoudre le problème de l'évaluation des sentiments (analyse des sentiments), par exemple, dans les commentaires sur les produits sur le site
- classer les billets par catégories ou équipes (classification des numéros)
- continuer à se moquer des billets, mais à l'aide de la prévision des prix - estimer les coûts de temps
Et vous pouvez ajouter quelque chose de votre choix, par exemple, pour automatiser la tâche de distribution des erreurs / incidents entrants entre les développeurs, en la réduisant à la tâche de classification par texte (étiquette cible - ID / nom de famille du développeur). Ou vous pouvez faire plaisir aux opérateurs du poste de travail interne qui remplissent les champs de la carte avec un ensemble fixe de valeurs (liste déroulante) pour d'autres champs ou description textuelle. Pour ce faire, il vous suffit de préparer une sélection en csv (même plusieurs centaines de lignes suffisent pour les expériences), d'enseigner le modèle directement depuis UI Visual Studio et de l'appliquer dans votre projet en copiant le code de l'exemple généré. Je mène au fait que ML.NET, à mon avis, est tout à fait approprié pour résoudre des tâches pratiques, pragmatiques et banales qui ne nécessitent pas de qualifications spéciales et mangent en vain du temps. De plus, il peut être appliqué dans le projet le plus ordinaire, qui ne prétend pas être innovant. Tout développeur .NET prêt à maîtriser une nouvelle bibliothèque peut devenir l'auteur d'un tel modèle.
J'ai un peu plus d'expérience en ML que le développeur .NET moyen, alors j'ai décidé par moi-même: pour les images, probablement pas, pour les cas complexes, mais pour les tâches de table simples, certainement oui. Pour le moment, il est plus pratique pour moi d'effectuer n'importe quelle tâche ML sur la pile de technologie Python / numpy / pandas / sk-learn / keras / pytorch plus familière, cependant, j'aurais fait un cas typique pour l'incorporation ultérieure dans une application .NET utilisant ML.NET .
Soit dit en passant, il est agréable que le cadre de texte fonctionne parfaitement sans aucun geste inutile et sans besoin de réglage par l'utilisateur. En général, cela n'est pas surprenant, car en pratique, sur de petites quantités de données, les bons vieux TfIDF avec des classificateurs comme SVC / NaiveBayes / LR fonctionnent assez bien. Cela a été discuté lors du DataFest d'été dans un rapport d'iPavlov - sur certaines suites de tests, word2vec, GloVe, ELMo (en quelque sorte) et BERT ont été comparés à TfIdf. Sur le test, il a été possible d'atteindre une supériorité de quelques pour cent dans un seul cas sur 7 à 10 cas, bien que le montant des ressources consacrées à la formation ne soit pas du tout comparable.
PS La vulgarisation du ML parmi les masses est désormais à la mode, prenant même «l' outil Google pour créer l'IA, que même un écolier peut utiliser ». Tout est drôle et intuitif pour l'utilisateur, mais ce qui se passe réellement dans les coulisses du cloud n'est pas clair. En cela, pour les développeurs .NET, ML.NET avec un générateur de modèle ressemble à une option plus attrayante.
La présentation de PSS s'est bien déroulée, les collègues étaient motivés pour essayer :)
Rétroaction
Soit dit en passant, l'une des newsletters avec le titre "ML.NET Model Builder" a déclaré:
Donnez-nous votre avis
Si vous rencontrez des problèmes, sentez qu'il manque quelque chose ou aimez vraiment quelque chose à propos de ML.NET Model Builder, faites-le nous savoir en créant un problème dans notre référentiel GitHub.
Model Builder est toujours dans la prévisualisation, et vos commentaires sont super importants pour guider la direction que nous prenons avec cet outil!
Cet article peut être considéré comme une rétroaction!
Les références
Sur ML.NET
Vers un article plus ancien avec des conseils