Nous voulons toujours écrire du code rapidement, mais vous devez payer pour cela. Dans les langages flexibles de haut niveau ordinaires, les programmes peuvent être développés rapidement, mais ils s'exécutent lentement après le lancement. Par exemple, il est monstrueusement lent de lire quelque chose de lourd en Python pur. Les langages de type C fonctionnent beaucoup plus rapidement, mais il est plus facile d'y faire des erreurs, dont la recherche réduira à néant tout le gain de vitesse.
Habituellement, ce dilemme est résolu comme suit: ils écrivent d'abord un prototype sur quelque chose de flexible, par exemple, sur Python ou R, puis le réécrivent sur C / C ++ ou Fortran. Mais ce cycle est trop long, pouvez-vous vous en passer?

Il y a peut-être une solution. Julia est un langage de programmation de haut niveau, flexible mais rapide. Julia dispose de plusieurs répartiteurs, d'un compilateur intelligent intégré et d'outils de métaprogrammation.
Gleb Ivashkevich (
phtRaveller ), le fondateur de datarythmics, qui développe des systèmes d'apprentissage automatique pour l'industrie et d'autres industries, un ancien physicien, vous en dira plus sur ce que Julia a.
Gleb expliquera pourquoi de nouveaux langages sont nécessaires et pourquoi parfois Python manque. Il vous expliquera ce qui est intéressant chez Julia, ses forces et ses faiblesses, le comparera avec d'autres langues, et montrera ce que la langue a de la perspective de l'apprentissage automatique et de l'informatique en général.
Clause de non-responsabilité. Il n'y aura pas d'analyse syntaxique. Habrazhiteli, développeurs expérimentés, il est donc inutile de montrer comment écrire une boucle, par exemple.Le problème des deux langues
Si vous écrivez du code rapidement, les programmes s'exécutent lentement. Si les programmes fonctionnent rapidement, écrivez-les pendant longtemps.
Le Python classique tombe dans la première catégorie. Si vous supprimez NumPy, considérez lentement quelque chose en pur Python. D'un autre côté, il existe des langages comme C et C ++. Il est difficile de trouver un équilibre. Le plus souvent, ils écrivent d'abord un prototype sur quelque chose de flexible et après avoir débogué l'algorithme, ils le réécrivent plus rapidement dans la langue. Ceci est un exemple d'un
problème clair dans deux langues : un long cycle lorsque vous devez écrire en Python, et le réécrire en C ou en Cython, par exemple.
Les spécialistes de l'apprentissage automatique et de la science des données ont NumPy, Sklearn, TensorFlow. Ils résolvent leurs problèmes depuis des années sans une seule ligne en C, et il semble que le problème des deux langues ne les concerne pas. Ce n'est pas le cas, le problème se manifeste
implicitement , car le code dans NumPy ou dans TensorFlow n'est en fait pas vraiment Python. Il est utilisé comme métalangage pour lancer ce qui est à l'intérieur. L'intérieur est exactement C / Fortran (dans le cas de NumPy) ou C ++ (dans le cas de TensorFlow).
Cette «fonctionnalité» est mal visible, par exemple, dans PyTorch, mais dans Numpy, elle est clairement visible. Par exemple, si un cycle Python classique est apparu dans les calculs, alors quelque chose s'est mal passé. Dans le code productif, les boucles ne sont pas nécessaires; vous devez tout réécrire pour que NumPy puisse le vectoriser et le calculer rapidement.
En même temps, il semble à beaucoup que NumPy est rapide et tout va bien. Voyons ce que NumPy a sous le capot pour voir cela.
- NumPy essaie de résoudre le problème de flexibilité du type Python, il a donc un système de type assez strict . Si le tableau a un certain type, il ne peut rien y avoir d'autre; si
Float64 est Float64 , rien ne peut être fait à ce sujet. - Envoi. Selon les types de tableaux et les opérations que vous devez effectuer, NumPy décidera en lui-même quelle fonction appeler pour effectuer les calculs le plus rapidement possible. La bibliothèque essaiera de jeter Python classique hors de la boucle de calcul.
Il s'avère que Numpy n'est pas aussi rapide qu'il n'y paraît. C'est pourquoi il existe des projets comme
Cython ou
Numba . Le premier génère du code C à partir de "l'hybride" de Python et C, et le second compile le code en Python et généralement c'est plus rapide.
Si NumPy était vraiment aussi rapide qu'il y paraît, alors l'existence de Cython et Numba n'aurait aucun sens.
Nous réécrivons tout en Cython si nous voulons trouver rapidement quelque chose de grand et de complexe. L'un des critères de qualité d'un wrapper en Cython est la présence ou l'absence d'appels Python purs dans le code généré.
Un exemple simple: nous ajoutons le type (bon) ou n'ajoutons pas (mauvais), et nous obtenons deux codes complètement différents, bien qu'en plus des types les options initiales ne soient pas différentes.

Lorsque nous générons le code C, dans le premier cas, nous obtenons ce qui suit:
__pyx_t_4 = __pyx_v_i; __pyx_v_result = (__pyx_v_result + (*((double *) ( (__pyx_v_a.data + __pyx_t_4 * __pyx_v_a.strides[0]) ))));
Et dans le deuxième
result =0. se transformera en ceci:
__pyx_t_6 = PyFloat_FromDouble((*((double *) ( (__pyx_v_a.data + __pyx_t_4 * __pyx_v_a.strides[0]) )))); if (unlikely(!__pyx_t_6)) __PYX_ERR(0, 9, __pyx_L1_error) __Pyx_GOTREF(__pyx_t_6); __pyx_t_7 = PyNumber_InPlaceAdd(__pyx_v_result, __pyx_t_6); if (unlikely(!__pyx_t_7)) __PYX_ERR(0, 9, __pyx_L1_error) __Pyx_GOTREF(__pyx_t_7); __Pyx_DECREF(__pyx_t_6); __pyx_t_6 = 0; __Pyx_DECREF_SET(__pyx_v_result, __pyx_t_7); __pyx_t_7 = 0;
Lorsqu'un type est spécifié, le code C s'exécute rapidement comme l'éclair. Si le type n'est pas spécifié, nous voyons Python normal, mais du côté C: les appels Python standard, où pour une raison quelconque, des
float sont créés à partir de
double , les liens sont comptés et beaucoup d'autres codes inutiles. Ce code est lent car il appelle Python pour chaque opération.
Est-il possible de résoudre tous les problèmes à la fois
C'est drôle que lorsque nous pensons à quelque chose, nous essayons de supprimer du Python pur. Il existe deux options pour ce faire.
- Utilisation de Cython ou d'autres outils. Il existe de nombreuses façons d'optimiser votre code Cython afin de vous retrouver avec presque aucun appel Python. Mais ce n'est pas l'activité la plus agréable: tout n'est pas si évident en Cython, et seulement un peu moins de temps est passé que si vous écrivez tout en C. Le module résultant peut être utilisé en Python, mais cela prend encore beaucoup de temps, des erreurs se produisent, le code n'est pas toujours évident et on ne sait pas toujours comment l’optimiser.
- Utiliser Numba, qui fait une compilation JIT .
Mais peut-être qu'il y a une meilleure façon, et je pense que c'est
Julia .
Julia
Les créateurs affirment qu'il s'agit d'un langage
rapide , de
haut niveau et
flexible , comparable à Python en termes de facilité d'écriture de code. À mon avis, Julia est comme un
langage de script: vous n'avez pas besoin de faire ce que vous avez à faire en C, où tout est de très bas niveau, y compris les structures de données. Dans le même temps, vous pouvez travailler dans une console standard, comme avec Python et d'autres langages.
Julia utilise
la compilation Just-In-Time - c'est l'un des éléments qui donne de la vitesse. Mais le langage est bon avec les calculs, car il a été développé pour eux. Julia est utilisée pour des tâches scientifiques et obtient des performances décentes.
Bien que Julia essaie de ressembler à un langage polyvalent, Julia est bonne pour l'informatique et pas très bonne pour les services Web. Utiliser Julia au lieu de Django, par exemple, n'est pas le meilleur choix.
Regardons les caractéristiques du langage comme exemple d'une fonction primitive.
function f(x) α = 1 + 2x end julia> methods(f)
Quatre caractéristiques sont visibles dans ce code.
- Il n'y a pratiquement aucune restriction sur l'utilisation d'Unicode . Vous pouvez prendre des formules d'un article sur l'apprentissage en profondeur ou la modélisation numérique, réécrire avec les mêmes caractères, et tout fonctionnera - Unicode est cousu presque partout.
- Il n'y a pas de signe de multiplication. Cependant, il n'est pas toujours possible de s'en passer, par exemple, par 2.x (un nombre à virgule flottante fois x) Julia jurera.
- Pas de
return . En général, il est recommandé d'écrire return pour voir ce qui se passe, mais l'exemple retournera α , car l'affectation est une expression. - Pas de types . Il semblerait que s'il y a de la vitesse, à un moment donné, les types devraient apparaître? Oui, ils apparaîtront, mais plus tard.
Julia a trois fonctionnalités qui offrent flexibilité et rapidité:
répartition multiple, métaprogrammation et parallélisme . Nous parlerons des deux premiers, et laisserons la parallélisation à l'étude indépendante pour les utilisateurs avancés.
Planification multiple
L'appel aux
methods(f) dans l'exemple ci-dessus semble inattendu - quel type de méthodes possède la fonction? Nous sommes habitués au fait que nous avons des objets de classe, les classes ont des méthodes. Mais chez Julia tout est retourné: les fonctions ont des méthodes, car le langage utilise plusieurs répartitions.
L'ordonnancement multiple signifie que la variante d'une fonction particulière qui sera exécutée est déterminée par l'ensemble des types de paramètres de cette fonction.
Je vais décrire brièvement comment cela fonctionne sur un exemple déjà familier.
function f(x) α = 1 + 2x end function f(x::AbstractFloat) α = 1 + sin(x) end julia> methods(f)
Les variantes de la même fonction pour différents ensembles de types sont appelées méthodes. Il y en a deux dans le code: le premier pour tous les nombres à virgule flottante et le second pour tout le reste. Lorsque nous appelons la fonction pour la première fois, Julia décidera de la méthode à utiliser et de la compilation. S'il a déjà été appelé et compilé, il prendra celui qui l'est.
Étant donné que dans Julia, tout n'est pas la façon dont nous sommes habitués, ici vous pouvez ajouter des fonctions aux types définis par l'utilisateur, mais ce ne seront pas des méthodes de type au sens de la POO. Ce sera simplement le champ dans lequel la fonction est écrite, car la
fonction est le même objet à part entière que tout le reste.
Pour savoir exactement ce qui sera déclenché, il existe des macros spéciales. Ils commencent par
@ . Dans l'exemple, la macro
@which permet de savoir quelle méthode a été appelée pour un cas spécifique.

Dans le premier cas, Julia a décidé que puisque 2 est un entier, il ne correspond pas à
AbstractFloat et a appelé la première option. Dans le deuxième cas, elle a décidé qu'il s'agissait de
Float et avait déjà demandé une version spécialisée. Cela fonctionnera approximativement si vous ajoutez d'autres méthodes pour certains types spécifiques.
LLVM et JIT
Julia utilise le framework LLVM pour compiler. La bibliothèque de compilation JIT est fournie dans un pack de langue. La première fois que la fonction est appelée, Julia cherche à voir si la fonction a été utilisée avec cet ensemble de types et la compile si nécessaire. Le premier lancement prendra un certain temps, puis tout fonctionnera rapidement.
La fonction sera compilée lors du premier appel pour cet ensemble de paramètres.
Caractéristiques du compilateur
- Le compilateur est raisonnablement raisonnable car LLVM est un bon produit.
- La plupart des développeurs avancés peuvent examiner le processus de compilation et voir ce qu'il génère.
- La compilation de Julia et Numba est similaire . Dans Numba, vous créez également un décorateur JIT, mais dans Numba, vous ne pouvez pas "entrer" autant et décider quoi optimiser ou changer.
Pour illustrer le travail du compilateur, je vais donner un exemple de fonction simple:
function f(x) α = 1 + 3x end julia> @code_llvm f(2) define i64 @julia_f_35897(i64) { top: %1 = mul i64 %0, 3 %2 = add i64 %1, 1 ret i64 %2 }
La macro
@code_llvm vous permet de voir le résultat de la génération. Ce
LLVM IR est
une représentation intermédiaire , une sorte d'assembleur.
Dans le code, l'argument de la fonction est multiplié par 3, 1 est ajouté au résultat, le résultat est renvoyé. Tout est aussi simple que possible. Si vous définissez la fonction un peu différemment, par exemple, remplacez 3 par 2, alors tout changera.
function f(x) α = 1 + 2x end julia> @code_llvm f(2) define i64 @julia_f_35894(i64) { top: %1 = shl i64 %0, 1 %2 = or i64 %1, 1 ret i64 %2 }
Il semblerait, quelle est la différence: 2, 3, 10? Mais Julia et LLVM voient que lorsque vous appelez une fonction pour un entier, vous pouvez faire un peu plus intelligemment. La multiplication par deux d'un entier est un décalage vers la gauche d'un bit - c'est plus rapide que le produit. Mais, bien sûr, cela ne fonctionne que pour les entiers, cela ne fonctionnera pas pour décaler
Float gauche de 1 bit et obtenir le résultat de la multiplication par 2.
Types personnalisés
Les types personnalisés dans Julia sont aussi rapides que les types intégrés. La planification multiple est effectuée sur eux, et ce sera aussi rapide que pour les types intégrés. En ce sens, le mécanisme de répartition multiple est profondément ancré dans le langage.
Il est logique de s'attendre à ce que les variables n'aient pas de types, seules les valeurs en ont. Les variables sans type ne sont qu'un marqueur, une étiquette sur un conteneur.
Le système de type est hiérarchique. Nous ne pouvons pas créer des descendants de types concrets; les types abstraits ne peuvent les avoir que. Cependant, les types abstraits ne peuvent pas être instanciés. Cette nuance ne plaira pas à tout le monde.
Comme les auteurs de la langue l'ont expliqué lorsqu'ils ont développé Julia, ils voulaient obtenir le résultat, et si quelque chose était difficile à faire, ils l'ont refusé. Un tel système de type hiérarchique était plus facile à développer. Ce n'est pas un problème catastrophique, mais si vous ne tournez pas la tête au début, ce ne sera pas pratique.
Les types peuvent être paramétrés , ce qui est un peu comme C / C ++. Par exemple, nous pouvons avoir une structure dans laquelle il y a des champs, mais les types de ces champs ne sont pas spécifiés - ce sont des paramètres. Nous spécifions un type spécifique à l'instanciation.
Dans la plupart des cas, les types peuvent être ignorés . Habituellement, ils sont nécessaires lorsque le type aide le compilateur à deviner la meilleure façon de compiler. Dans ce cas, les types sont mieux à spécifier. Vous devez également spécifier des types si vous souhaitez obtenir de meilleures performances.
Voyons ce qui est possible et ce qui ne peut pas être instancié.

Le premier type de
AbstractPoint ne peut pas être instancié. Ceci est juste un parent commun pour tout le monde que nous pouvons spécifier dans les méthodes, par exemple. La deuxième ligne indique que
PlanarPoint{T} est un descendant de ce point abstrait. Sous les champs commencent - ici vous pouvez voir le paramétrage. Vous pouvez mettre ici un
float ,
int ou un autre type.
Le premier type ne peut pas être instancié, et pour tout le reste, il est impossible de créer des descendants. De plus, par défaut, ils sont
immuables . Pour pouvoir modifier les champs, cela doit être spécifié explicitement.
Lorsque tout est prêt, vous pouvez par exemple continuer à calculer la distance pour différents types de points. Dans l'exemple, le premier point sur le plan est
PlanarPoint , puis sur la sphère et sur le cylindre. Selon les deux points dont nous calculons la distance, nous devons utiliser différentes méthodes. En général, la fonction ressemblera à ceci:
function describe(p::AbstractPoint) println("Point instance: $p") end
Pour
Float64 ,
Float32 ,
Float16 ce sera:
function distance(pf::PlanarPoint{T}, ps::PlanarPoint{T}) where T<:AbstractFloat sqrt((pf.x-ps.x)^2 + (pf.y-ps.y)^2) end
Et pour les entiers, la méthode de calcul de la distance ressemblera à ceci:
function distance(pf::PlanarPoint{T}, ps::PlanarPoint{T}) where T<:Integer abs(pf.x-ps.x) + abs(pf.y-ps.y) end
Pour les points de chaque type, différentes méthodes seront appelées.
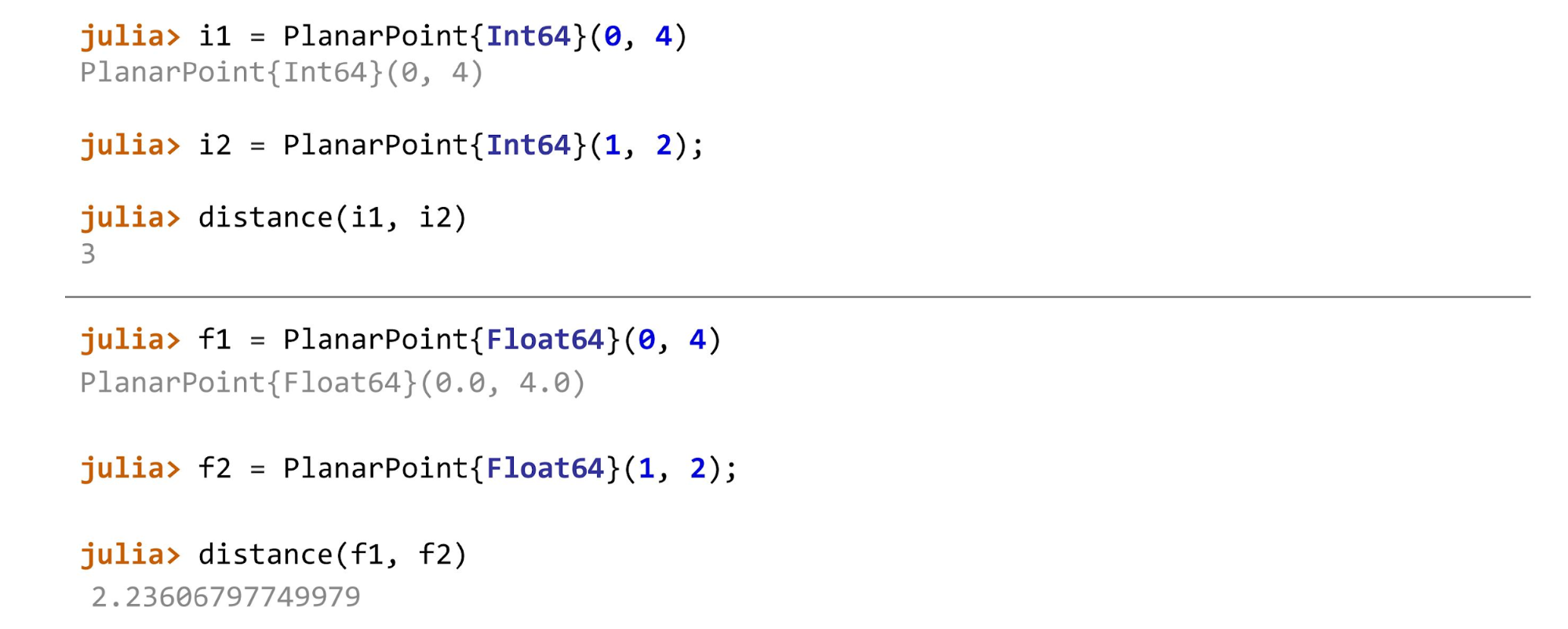
Si vous trichez et appliquez par exemple la
distance(f1, i2) , Julia jurera: «Je ne connais pas cette méthode! Vous m'avez demandé de telles méthodes et avez dit qu'elles sont toutes les deux du même type. Vous ne m'avez pas dit comment compter cela quand un paramètre est
float et l'autre est
int . "
La vitesse
Vous avez peut-être déjà été ravi: «Il y a une compilation JIT: l'écriture est facile, elle fonctionnera rapidement. Jetez Python et commencez à écrire en Julia! »
Mais pas si simple. Toutes les fonctionnalités de Julia ne seront pas rapides. Cela dépend de deux facteurs.
- Du développeur . Il n'y a pas de langues dans lesquelles une fonction sera rapide. Un développeur inexpérimenté écrira même du code en C qui fonctionnera beaucoup plus lentement que le code Python d'un développeur expérimenté. Chaque langue a ses propres astuces et nuances dont dépendent les performances. Le compilateur, qu'il soit statique ou JIT, ne peut pas fournir toutes les options imaginables et tout optimiser du tout.
- De la stabilité du type . Dans une version plus rapide, les fonctions stables par type seront compilées.
Stabilité du type
Qu'est-ce que la stabilité de type? Lorsque le compilateur ne peut pas deviner de manière suffisamment fiable ce qui se passe avec les types, il doit générer beaucoup de code wrapper pour que tout ce qui arrive à l'entrée fonctionne.
Un exemple simple pour comprendre la stabilité du type.

Les spécialistes du machine learning diront qu'il s'agit d'une activation relu normale: si x> 0, retournez-la telle quelle, sinon retournez zéro. Un problème est le zéro après l'entier du point d'interrogation. Cela signifie que si nous appelons cette fonction pour un nombre à virgule flottante, alors dans un cas, un nombre à virgule flottante sera retourné, et dans l'autre, un entier.
Le compilateur ne peut pas deviner le type de résultat uniquement par le type d'argument de fonction. Il a également besoin d'en connaître le sens. Par conséquent, il génère beaucoup de code.
Ensuite, nous créons un tableau de 100 pour 100 nombres aléatoires de 0 à 1, le décalons de 0,5 pour répartir uniformément les nombres positifs et négatifs et mesurons le résultat. Il y a deux points intéressants: le point et la fonction. Le point après
rand(100,100) signifie "appliquer à chaque élément". Si vous avez une sorte de collection et de fonction scalaire, vous y mettez un terme, et Julia fera le reste. Nous pouvons supposer que c'est aussi efficace qu'une boucle normale dans un langage compilé normal. Pas besoin d'écrire
for - tout sera fait pour vous.
Il n'y a aucun problème à ce stade - le
problème est à l'intérieur de la fonction elle-même . Le temps d'exécution estimé d'une telle option sur un ordinateur décent pour une telle matrice est de microsecondes. Mais en réalité - millisecondes, ce qui est trop pour une si petite matrice.
Modifiez une seule ligne.

La fonction
zero(x) s'exécute génère un zéro du même type que l'argument
(x) . Cela signifie que quelle que soit la valeur de
x , le type de résultat sera toujours connu par le type de
x lui-même.
Lorsque nous examinons uniquement le type d'arguments et connaissons déjà le type de résultat, ce sont des fonctions dont le type est stable.
Si nous devons examiner la signification des arguments, ce ne sont pas des fonctions stables.
Lorsque le compilateur peut optimiser le code, la différence de temps d'exécution est obtenue de deux ordres de grandeur. Dans le deuxième exemple, il n'a été alloué exactement qu'à un nouveau tableau, quelques dizaines d'octets de plus et rien de plus. Cette option est beaucoup plus efficace que la précédente.
C'est la principale chose à surveiller lorsque nous écrivons du code dans Julia. Si vous écrivez comme en Python, cela fonctionnera comme en Python. Si vous effectuez les mêmes opérations sur NumPy, zéro avec ou sans point ne joue pas de rôle. Mais dans Julia, cela peut considérablement compromettre les performances.
Heureusement, il existe une méthode pour savoir s'il existe un problème. Il s'agit de la macro
@code_warntype , qui vous permet de savoir si le compilateur peut deviner où se trouvent les types et optimiser si tout va bien.

Dans la première option (à gauche), le compilateur n'est pas sûr du type et l'affiche en rouge. Dans le second cas, il y aura toujours
Float64 pour un tel argument, vous pouvez donc générer du code beaucoup plus court.
Ce n'est pas encore LLVM, mais le code Julia étiqueté,
return 0 ou
return 0.0 donne une différence de performance de deux ordres de grandeur.
Métaprogrammation
La métaprogrammation consiste à créer des programmes dans un programme et à les exécuter en déplacement.
Il s'agit d'une méthode puissante qui vous permet de faire de nombreuses choses intéressantes. Un exemple classique est Django ORM, qui crée des champs à l'aide de métaclasses.
Beaucoup de gens connaissent l'avertissement de
Tim Peters , auteur de Zen of Python:
«Les métaclasses sont une magie plus profonde dont 99% des utilisateurs ne devraient jamais s'inquiéter. Si vous vous demandez si des métaclasses sont nécessaires en Python, vous n'en avez pas besoin. Si vous en avez besoin, vous savez exactement pourquoi et comment les utiliser. »
Avec la métaprogrammation, la situation est similaire, mais chez Julia, elle est cousue beaucoup plus profondément, c'est une caractéristique importante de toute la langue. Le code Julia est la même structure de données que n'importe quel autre, vous pouvez manipuler, combiner, créer des expressions, et tout cela fonctionnera.
julia> x = 4; julia> typeof(:(x+1)) Expr julia> expr = :(x+1) :(x + 1) julia> expr.head :call julia> expr.args 3-element Array{Any,1}: :+ :x 1
Les macros sont l'un des outils de métaprogrammation de Julia : nous leur donnons quelque chose, elles regardent, ajoutent le bon, suppriment l'inutile et donnent le résultat. Dans tous les exemples précédents, nous avons passé l'appel de fonction et la macro à l'intérieur a analysé l'appel. Tout cela se passe au niveau du travail avec l'arbre de syntaxe.
Vous pouvez analyser des expressions très simples: si c'est par exemple
(x+1) , alors c'est un appel à la fonction
+ (l'addition n'est pas un opérateur, comme dans beaucoup d'autres langues, mais une fonction) et deux arguments: un caractère (un deux-points signifie qu'il s'agit d'un caractère ), et le second n'est qu'une constante.
Un autre exemple de macro simple:
macro named(name, expr) println("Starting $name") return quote $(esc(expr)) end end julia> @named "some process" x=5; Starting some process julia> x 5
À l'aide de macros, par exemple, des indicateurs de progression ou des filtres pour les trames de données sont créés - c'est un mécanisme courant dans Julia.
Les macros ne sont pas exécutées au moment de l'appel, mais lors de l'analyse du code.
Il s'agit de la principale fonction macro de Julia. - , . , , .
,
Julia — . .
- Julia . .
- , . , , C .
- Julia JIT- . , , , , .
- — . .
- ( ). , . , , .
- Julia — .
Écosystème
, , Julia . , , data science , , , Python. , Python Pandas, , , , Julia .
Julia , Python 2008 . Python, , Julia. , . , Julia.
( ) Python Julia
. Julia: , , .…
. .
- DataFrames.jl .
- JuliaDB , .
- Query.jl . Pandas — - , ..
Plotting .
Matplotlib , Julia. :
VegaLite.jl ,
Plots.jl , ,
Gadfly.jl .
.
TensorFlow , Flux.jl. Flux , , , Keras TensorFlow, . .
Scikit-learn . , , sklearn, , .
XGBoost . , Julia .
?
Jupyter . IDE — Juno, Visual Studio, .
. GPU/TPU . CUDAnative.jl Julia . Julia-, - , . , , , , .
: C, Fortran, Python .
, .
Packaging : Julia: , , ..
, , . , , . ,
PyTorch , TensorFlow, , .
, , , . Julia, , , . ,
,
Zygote.jl . Flux.jl.
julia> using Zygote julia> φ(x) = x*sin(x) julia> Zygote.gradient(φ, π/2.) (1.0,) julia> model = Chain(Dense(768, 128, relu), Dense(128, 10), softmax) julia> loss(x, y) = crossentropy(model(x), y) + sum(norm, params(model)) julia> optimizer = ADAM(0.001) julia> Flux.train!(loss, params(model), data, optimizer) julia> model = Chain(x -> sqrt(x), x->x-1)
φ , , , .
Zygote «source-to-source»: , , .
differentiable programming — — backpropagation , .
Julia : «source-to-source» , . , .
Julia ?
, — . .
- , , , — .
, , .
Julia , .
- , , . Julia «» .
- , API, , .
Moscow Python Conf++ , 27 , Python Julia. , , telegram- MoscowPython.