Nous avons développé une conception d'un réseau de centres de données, qui vous permet de déployer des clusters informatiques de plus de 100 000 serveurs avec une bande passante de bissection de plus d'un pétabit par seconde.
À partir du rapport de Dmitry Afanasyev, vous découvrirez les principes de base de la nouvelle conception, la mise à l'échelle des topologies qui surviennent avec ces problèmes, les options pour les résoudre, les caractéristiques du routage et la mise à l'échelle des fonctions du plan de transfert des périphériques réseau modernes dans des topologies fortement connectées avec un grand nombre de routes ECMP. . En outre, Dima a brièvement parlé de l'organisation de la connectivité externe, du niveau physique, du système de câbles et des moyens d'augmenter encore la capacité.

- Bonjour tout le monde! Je m'appelle Dmitry Afanasyev, je suis architecte réseau de Yandex et je m'occupe principalement de la conception de réseaux de centres de données.

Mon histoire portera sur le réseau de centres de données Yandex mis à jour. Il s'agit en grande partie d'une évolution de la conception que nous avions, mais en même temps, il y a de nouveaux éléments. Il s'agit d'une présentation de revue, car il a fallu ajuster beaucoup d'informations en peu de temps. Nous commençons par choisir une topologie logique. Ensuite, il y aura une vue d'ensemble du plan de contrôle et des problèmes d'évolutivité du plan de données, le choix de ce qui se passera au niveau physique, regardons quelques fonctionnalités des appareils. Nous aborderons également ce qui se passe dans le centre de données avec MPLS, dont nous avons parlé il y a quelque temps.

Alors, qu'est-ce que Yandex en termes de charges de travail et de services? Yandex est un hyperscaler typique. Si vous regardez dans la direction des utilisateurs, nous traitons principalement les demandes des utilisateurs. En outre, divers services de streaming et sortie de données, car nous avons également des services de stockage. S'il est plus proche du backend, les charges et les services d'infrastructure y apparaissent, tels que les magasins d'objets distribués, la réplication de données et, bien sûr, les files d'attente persistantes. L'un des principaux types de charges est MapReduce et similaires, le traitement en streaming, l'apprentissage automatique, etc.

Comment est l'infrastructure au-dessus de laquelle tout cela se produit? Encore une fois, nous sommes un hyperskaler très typique, bien que nous soyons peut-être un peu plus près du côté du spectre où se trouvent les plus petits hyperskalers. Mais nous avons tous les attributs. Dans la mesure du possible, nous utilisons du matériel de base et une mise à l'échelle horizontale. Nous avons une croissance complète de la mise en commun des ressources: nous ne travaillons pas avec des machines distinctes, des racks séparés, mais les combinons en un grand pool de ressources interchangeables avec quelques services supplémentaires qui sont engagés dans la planification et l'allocation, et nous travaillons avec tout ce pool.
Nous avons donc le niveau suivant - le cluster de calcul au niveau du système d'exploitation. Il est très important que nous contrôlions entièrement la pile technologique que nous utilisons. Nous contrôlons les terminaux (hôtes), le réseau et la pile logicielle.
Nous avons plusieurs grands centres de données en Russie et à l'étranger. Ils sont unis par une épine dorsale utilisant la technologie MPLS. Notre infrastructure interne est presque entièrement basée sur IPv6, mais comme nous devons gérer le trafic externe, qui est toujours principalement acheminé via IPv4, nous devons en quelque sorte livrer les demandes provenant d'IPv4 aux serveurs frontaux et continuer à aller un peu vers IPv4 externe. Internet - par exemple, pour l'indexation.
Les dernières itérations de la conception de réseaux de centres de données utilisent des topologies Clos à plusieurs niveaux, et seul L3 y est utilisé. Nous avons quitté L2 il y a quelque temps et avons poussé un soupir de soulagement. Enfin, notre infrastructure comprend des centaines de milliers d'instances informatiques (serveur). Il y a quelque temps, la taille maximale du cluster était d'environ 10 000 serveurs. Cela est largement dû à la façon dont les mêmes systèmes d'exploitation au niveau du cluster - ordonnanceurs, allocation des ressources, etc., peuvent fonctionner. Depuis que des progrès ont été réalisés du côté des logiciels d'infrastructure, l'objectif est désormais d'environ 100 000 serveurs dans un cluster informatique, et nous avions une tâche - être en mesure de construire des usines de réseau qui permettent une mise en commun efficace des ressources dans un tel cluster.

Que voulons-nous d'un réseau de centres de données? Tout d'abord - beaucoup de bande passante bon marché et assez uniformément répartie. Parce que le réseau est ce substrat à travers lequel nous pouvons faire la mise en commun des ressources. La nouvelle taille cible est d'environ 100 000 serveurs dans un cluster.
Bien sûr, nous voulons également un plan de contrôle évolutif et stable, car sur une si grande infrastructure, beaucoup de maux de tête surviennent même à cause d'événements aléatoires, et nous ne voulons pas que le plan de contrôle nous apporte un mal de tête. En même temps, nous voulons minimiser l'état en son sein. Plus l'état est petit, mieux tout est stable et plus il est facile à diagnostiquer.
Bien sûr, nous avons besoin d'automatisation, car il est impossible de gérer une telle infrastructure manuellement, et c'était impossible il y a quelque temps. Dans la mesure du possible, nous avons besoin d'un soutien opérationnel et d'un soutien CI / CD dans la mesure du possible.
Avec de telles tailles de centres de données et de grappes, la tâche de prise en charge du déploiement et de l'expansion incrémentiels sans interruption de service est devenue assez aiguë. Si sur des clusters la taille d'un millier de voitures est probablement proche de dix mille voitures, elles pourraient toujours être déployées en une seule opération - c'est-à-dire que nous prévoyons d'étendre l'infrastructure, et plusieurs milliers de machines sont ajoutées en une seule opération, puis un cluster de la taille de cent mille voitures ne se pose pas juste comme ça, il a été construit depuis un certain temps. Et il est souhaitable que pendant tout ce temps ce qui a déjà été pompé, l'infrastructure qui est déployée, soit disponible.
Et une exigence que nous avions et que nous avons quittée: il s'agit du support de la mutualisation, c'est-à-dire de la virtualisation ou de la segmentation du réseau. Maintenant, nous n'avons plus besoin de le faire au niveau de l'usine du réseau, car la segmentation est allée aux hôtes, ce qui a rendu la mise à l'échelle très facile pour nous. Grâce à IPv6 et à un grand espace d'adressage, nous n'avons pas eu besoin d'utiliser des adresses en double dans l'infrastructure interne, tout l'adressage était déjà unique. Et du fait que nous avons appliqué le filtrage et la segmentation du réseau aux hôtes, nous n'avons pas besoin de créer d'entités de réseau virtuel dans les réseaux de centres de données.

Une chose très importante est que nous n'en avons pas besoin. Si certaines fonctions peuvent être supprimées du réseau, cela simplifie considérablement la vie et, en règle générale, élargit le choix du matériel et des logiciels disponibles, et simplifie considérablement les diagnostics.
Alors, de quoi n'avons-nous pas besoin, de quoi avons-nous pu refuser, pas toujours avec joie au moment où cela s'est produit, mais avec grand soulagement, une fois le processus terminé?
Tout d'abord, le rejet de L2. Nous n'avons pas besoin de L2 réel ou émulé. Non utilisé dans une large mesure en raison du fait que nous contrôlons la pile d'applications. Nos applications sont mises à l'échelle horizontalement, elles fonctionnent avec l'adressage L3, elles ne se soucient pas vraiment qu'une instance particulière soit désactivée, elles en déploient simplement une nouvelle, elle n'a pas besoin de se déployer sur l'ancienne adresse, car il existe un niveau distinct de découverte de service et de surveillance des machines situées dans le cluster . Nous ne transférons pas cette tâche au réseau. La tâche du réseau est de livrer des paquets du point A au point B.
De plus, nous n'avons aucune situation où les adresses se déplacent au sein du réseau, et cela doit être surveillé. Dans de nombreuses conceptions, cela est généralement nécessaire pour prendre en charge la mobilité des machines virtuelles. Nous n'utilisons pas la mobilité des machines virtuelles dans l'infrastructure interne du grand Yandex exactement, et, en outre, nous pensons que, même si cela est fait, cela ne devrait pas se produire avec le support réseau. Si vous avez vraiment besoin de le faire, vous devez le faire au niveau de l'hôte et conduire les adresses qui peuvent migrer dans des superpositions afin de ne pas toucher ou apporter trop de modifications dynamiques au système de routage lui-même sous-jacent (réseau de transport).
Une autre technologie que nous n'utilisons pas est la multidiffusion. Je peux vous expliquer en détail pourquoi. Cela rend la vie beaucoup plus facile, car si quelqu'un s'occupe de lui et regarde à quoi ressemble exactement le plan de contrôle d'une multidiffusion - dans toutes les installations, sauf la plus simple, c'est un gros casse-tête. Et de plus, il est difficile de trouver une implémentation open source qui fonctionne bien, par exemple.
Enfin, nous concevons nos réseaux pour qu'ils n'aient pas trop de changements. Nous pouvons compter sur le fait que le flux d'événements externes dans le système de routage est faible.

Quels problèmes surviennent et quelles limites doivent être prises en compte lorsque nous développons un réseau de centre de données? Coût bien sûr. Évolutivité, à quel niveau nous voulons grandir. La nécessité d'une expansion sans arrêter le service. Disponibilité de la bande passante. La visibilité de ce qui se passe sur le réseau, pour les systèmes de surveillance, pour les équipes opérationnelles. La prise en charge de l'automatisation est, là encore, autant que possible, car différentes tâches peuvent être résolues à différents niveaux, y compris l'introduction de couches supplémentaires. Eh bien et non - [dans la mesure du possible] - dépendance vis-à-vis des fournisseurs. Bien que dans différentes périodes historiques, selon la section à examiner, cette indépendance était plus facile ou plus difficile à réaliser. Si nous prenons une tranche des puces des périphériques réseau, alors jusqu'à récemment, parlons d'indépendance vis-à-vis des fournisseurs, si nous voulions également des puces à haut débit, cela pourrait être très arbitraire.

Quelle topologie logique utiliserons-nous pour construire notre réseau? Ce sera un Clos à plusieurs niveaux. En fait, il n'existe actuellement aucune véritable alternative. Et la topologie Clos est assez bonne, même si nous la comparons avec diverses topologies avancées qui sont désormais plus dans la sphère d'intérêt académique, si nous avons des commutateurs avec une grande radix.
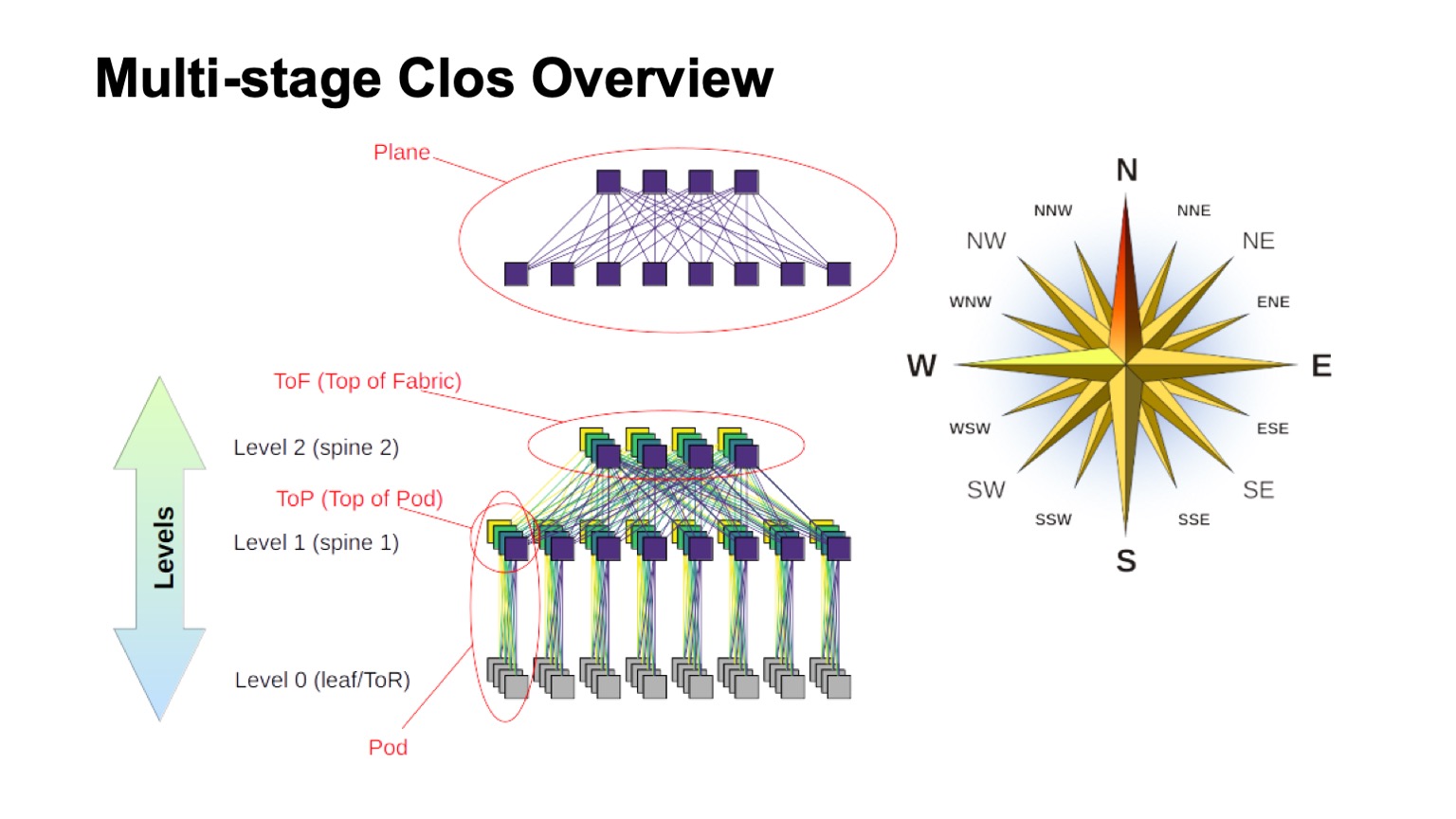
Comment le réseau de Clos en couches est-il approximativement structuré et quels sont les différents éléments qui y sont appelés? Tout d'abord, le vent s'est levé, pour savoir où le nord, où le sud, où l'est, où l'ouest. Les réseaux de ce type sont généralement construits par ceux qui ont un très gros trafic ouest - est. Comme pour le reste des éléments, un commutateur virtuel assemblé à partir de commutateurs plus petits est illustré en haut. C'est l'idée de base de la construction récursive de réseaux Clos. Nous prenons des éléments avec une sorte de radix et les connectons afin que ce qui s'est passé puisse être considéré comme un commutateur avec une radix plus grande. Si vous en avez besoin de plus, la procédure peut être répétée.
Dans les cas, par exemple, avec un Clos à deux niveaux, lorsqu'il est possible de distinguer clairement les composants verticaux dans mon diagramme, ils sont généralement appelés plans. Si nous construisions Clos-avec trois niveaux de commutateurs vertébraux (tous ceux qui ne sont pas des commutateurs borderline et non ToR et qui ne sont utilisés que pour le transit), les avions auraient l'air plus compliqués, les deux niveaux ressembleraient exactement à cela. Le bloc de commutateurs ToR ou feuille et les commutateurs vertébraux associés de premier niveau que nous appelons Pod. Les commutateurs de niveau 1 de la colonne vertébrale en haut du pod sont le haut du pod, le haut du pod. Les commutateurs qui sont situés en haut de l'usine entière sont la couche supérieure de l'usine, le haut du tissu.

Bien sûr, la question se pose: les Clos-réseaux sont construits depuis un certain temps, l'idée elle-même vient généralement de l'époque de la téléphonie classique, les réseaux TDM. Peut-être que quelque chose de mieux est apparu, peut-être que vous pouvez faire quelque chose de mieux d'une manière ou d'une autre? Oui et non. Théoriquement, oui, dans la pratique, dans un proche avenir, certainement pas. Parce qu'il existe un certain nombre de topologies intéressantes, certaines d'entre elles sont même utilisées en production, par exemple, Dragonfly est utilisé dans les applications HPC; Il existe également des topologies intéressantes telles que Xpander, FatClique, Jellyfish. Si vous regardez des rapports lors de conférences telles que SIGCOMM ou NSDI ces derniers temps, vous pouvez trouver un assez grand nombre d'articles sur des topologies alternatives qui ont de meilleures propriétés (l'une ou l'autre) que Clos.
Mais toutes ces topologies ont une propriété intéressante. Il empêche leur mise en œuvre dans les réseaux de centres de données, que nous essayons de construire sur du matériel de base et qui coûtent de l'argent raisonnablement raisonnable. Dans toutes ces topologies alternatives, la majeure partie de la bande n'est malheureusement pas accessible via les chemins les plus courts. Par conséquent, nous perdons immédiatement la possibilité d'utiliser le plan de contrôle traditionnel.
Théoriquement, la solution au problème est connue. Ce sont, par exemple, des modifications de l'état de la liaison utilisant le chemin le plus court k, mais, encore une fois, il n'y a pas de protocoles qui seraient mis en œuvre en production et massivement disponibles sur l'équipement.
De plus, comme la majeure partie de la capacité n'est pas accessible via les chemins les plus courts, nous devons modifier non seulement le plan de contrôle afin qu'il sélectionne tous ces chemins (et, en passant, c'est un état beaucoup plus grand dans le plan de contrôle). Nous devons encore modifier le plan de transfert et, en règle générale, au moins deux fonctionnalités supplémentaires sont requises. C'est l'occasion de prendre toutes les décisions concernant le transfert de packages une seule fois, par exemple, sur un hôte. Il s'agit en fait d'un routage source, parfois dans la littérature sur les réseaux d'interconnexion, il est appelé décision de transfert tout à la fois. Et le routage adaptatif est déjà une fonction dont nous avons besoin sur les éléments du réseau, ce qui se résume, par exemple, au fait que nous sélectionnons le saut suivant en fonction des informations sur la moindre charge dans la file d'attente. A titre d'exemple, d'autres options sont possibles.
Ainsi, la direction est intéressante, mais, hélas, nous ne pouvons pas l'appliquer maintenant.

D'accord, réglé sur la topologie logique de Clos. Comment allons-nous l'adapter? Voyons comment cela fonctionne et ce qui peut être fait.

Dans le réseau Clos, il existe deux paramètres principaux que nous pouvons en quelque sorte varier et obtenir certains résultats: les éléments radix et le nombre de niveaux dans le réseau. Je décris schématiquement comment l'un et l'autre affectent la taille. Idéalement, nous combinons les deux.
On peut voir que la largeur totale du réseau Clos est un produit de tous les niveaux de commutateurs vertébraux du radix sud, du nombre de liens que nous avons, de la façon dont il se ramifie. C'est ainsi que nous adaptons la taille du réseau.
En ce qui concerne la capacité, en particulier sur les commutateurs ToR, il existe deux options de mise à l'échelle. Soit nous pouvons, tout en conservant la topologie générale, utiliser des liens plus rapides, soit nous pouvons ajouter plus de plans.
Si vous regardez la version détaillée du réseau Clos (dans le coin inférieur droit) et revenez à cette image avec le réseau Clos ci-dessous ...
... alors c'est exactement la même topologie, mais sur cette diapositive, elle est réduite de manière plus compacte et les plans d'usine sont superposés les uns aux autres. C'est une seule et même chose.

À quoi ressemble la mise à l'échelle d'un réseau Clos en chiffres? Ici, j'ai des données sur la largeur maximale qu'un réseau peut obtenir, sur le nombre maximal de racks, de commutateurs ToR ou de commutateurs feuille, s'ils ne sont pas dans des racks, nous pouvons les obtenir en fonction de la gamme de commutateurs que nous utilisons pour les épines niveaux et combien de niveaux nous utilisons.
Il montre combien de racks nous pouvons avoir, combien de serveurs et combien tout cela peut consommer à raison de 20 kW par rack. Un peu plus tôt, j'ai mentionné que nous visons une taille de cluster d'environ 100 000 serveurs.
On peut voir que dans toute cette construction, deux options et demie sont intéressantes. Il y a une option avec deux couches d'épines et des commutateurs 64 ports, ce qui est un peu court. Ensuite, des options parfaitement adaptées pour les commutateurs de colonne vertébrale à 128 ports (avec 128 radix) à deux niveaux, ou les commutateurs à 32 radix à trois niveaux. Et dans tous les cas où il y a plus de radix et plus de niveaux, vous pouvez faire un très grand réseau, mais si vous regardez la consommation attendue, en règle générale, il y a des gigawatts. Vous pouvez poser le câble, mais il est peu probable que nous obtenions autant d'électricité sur un seul site. Si vous regardez les statistiques, les données publiques sur les centres de données - très peu de centres de données peuvent être trouvés pour une capacité estimée à plus de 150 MW. De plus, en règle générale, les campus de centres de données, plusieurs grands centres de données situés assez près les uns des autres.
Il y a un autre paramètre important. Si vous regardez la colonne de gauche, la bande passante utilisable y est indiquée. Il est facile de remarquer que dans un réseau Clos, une partie importante des ports est consacrée à la connexion des commutateurs entre eux. La bande passante utilisable est ce que vous pouvez distribuer, vers les serveurs. Naturellement, je parle des ports conditionnels et de la bande. En règle générale, les liaisons au sein du réseau sont plus rapides que les liaisons vers les serveurs, mais par unité de bande, dans la mesure où nous pouvons la distribuer à notre équipement serveur, il y a encore plus de bandes au sein du réseau lui-même. Et plus nous faisons de niveaux, plus les coûts unitaires pour fournir cette bande à l'extérieur sont élevés.
De plus, même cette bande supplémentaire n'est pas exactement la même. Bien que les portées soient courtes, nous pouvons utiliser quelque chose comme le DAC (cuivre à connexion directe, c'est-à-dire des câbles twinax) ou l'optique multimode, qui coûte encore plus ou moins raisonnable. Dès que nous passons à des portées plus authentiques - en règle générale, il s'agit d'optiques monomodes, et le coût de cette bande supplémentaire augmente considérablement.
Et encore une fois, en revenant à la diapositive précédente, si nous créons un réseau Clos sans réabonnement, il est facile de regarder le diagramme, de voir comment le réseau est construit - en ajoutant chaque niveau de commutateurs vertébraux, nous répétons la bande entière qui était en dessous. Niveau plus - plus toute la même bande, le même nombre de ports sur les commutateurs qu'au niveau précédent, le même nombre d'émetteurs-récepteurs. Par conséquent, le nombre de niveaux de commutateurs vertébraux est très souhaitable pour minimiser.
Sur la base de cette image, il est clair que nous voulons vraiment construire sur quelque chose comme des commutateurs avec 128 radix.

Ici, en principe, tout est le même que je viens de le dire, cette diapositive est plus susceptible d'être examinée plus tard.

, ? , - . , . , . , . , , , , . ( ), control plane , , , , . , , .
, , , SerDes- — - . forwarding . , , , , , Clos-, . .
, , . , , , , , , , , , .

— , . , , . , , , - , . , , , , .
, , , . -, , . , , 128 , .
, , , data plane. . , , . , , , . , , , , 128 , . . . .
, - , . ( ), , — ToR- leaf-, . - , , , , - . , , , - .

, , .

? . , , , : leaf-, 1, 2. , — twinax, multimode, single mode. , , , , , .
. , , multimode , , , 100- . , , , single mode , , single mode, - CWDM, single mode (PSM) , , , .
: , 100 425 . SFP28 , QSFP28 100 . multimode .
- , - , - - . , . , - Pods twinax- ( ).
, , , CWDM. .
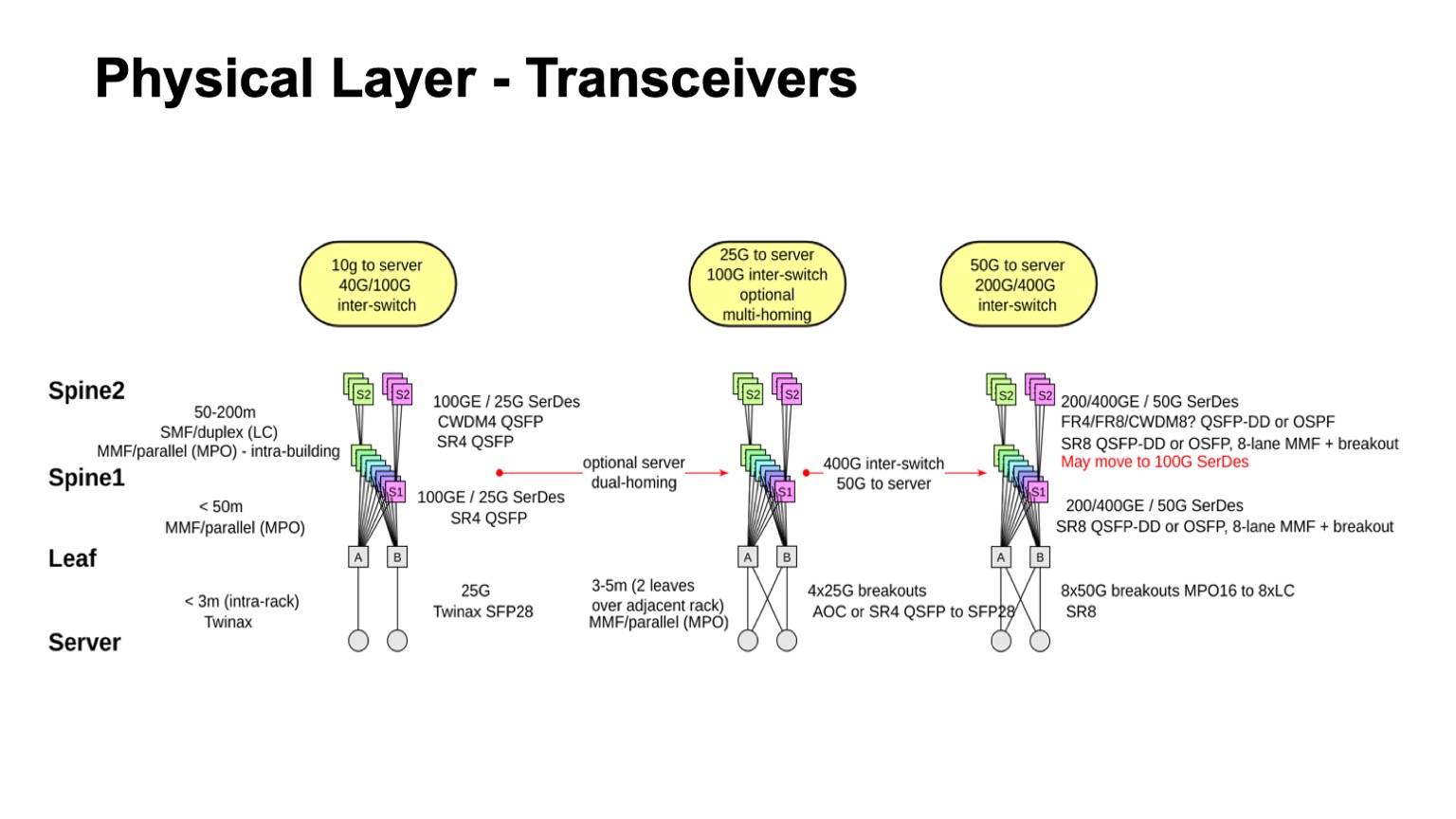
, , . , , 50- SerDes . , , 400G, 50G SerDes- , 100 Gbps per lane. , 50 100- SerDes 100 Gbps per lane, . , 50G SerDes , , , 100G SerDes . - , , .
. , 400- 200- 50G SerDes. , , , , , , . 128. , , , , .
, , . , , , , , 100- , .

— , . , . leaf- — , . , , — .
, , , -. , , - -, . . , , , . - -, -, , , , . : . - , « », Clos-, . , , .
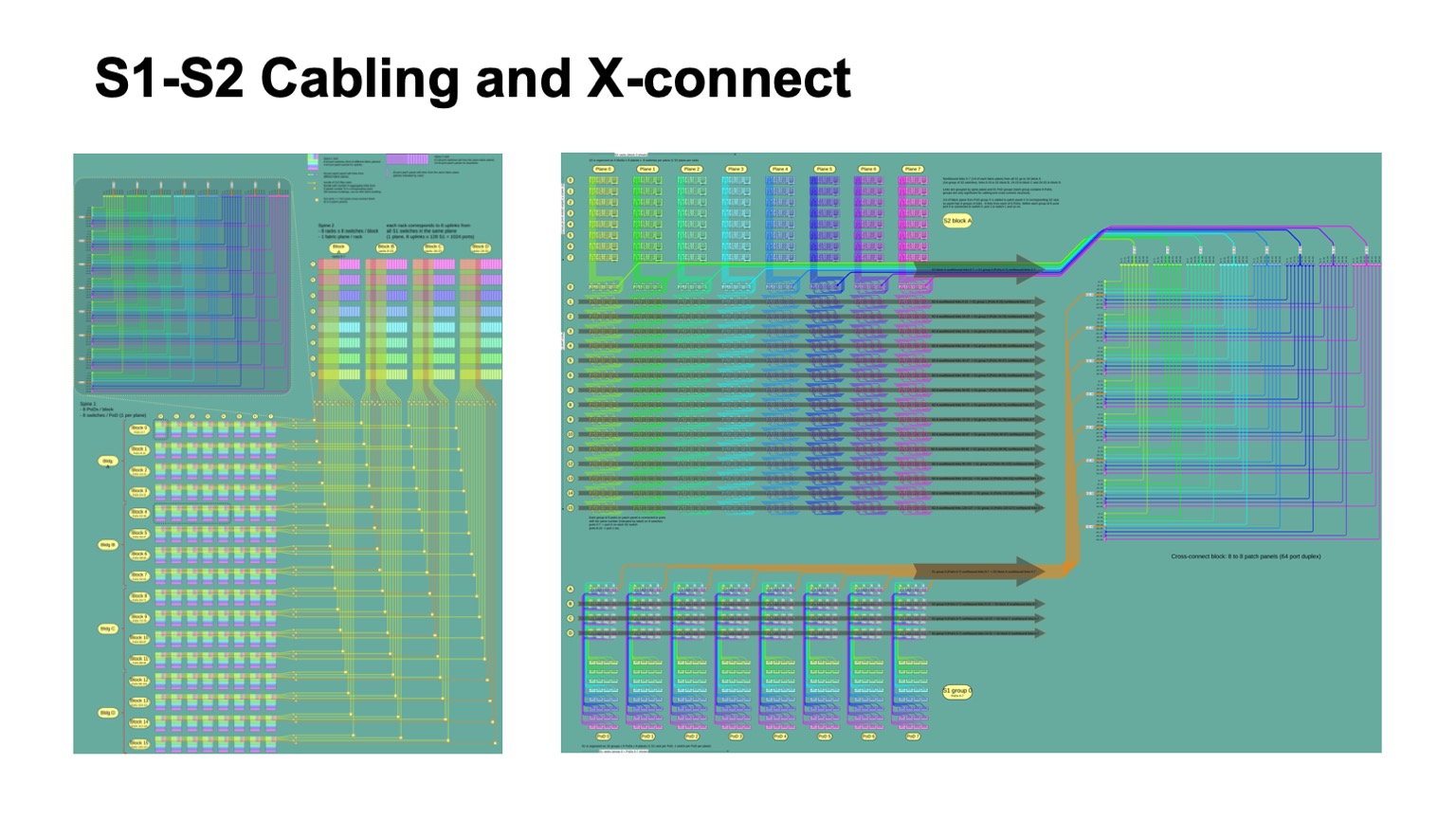
. - , , , , -2-.
. , - 512 512 , , , -2. Pods -1, -, -2.

Voici à quoi ça ressemble. -2 () -. , . -, . , , .

: , . control plane-? , - , link state , , , , . , — , link state . , , , , fanout, control plane . link state .
— BGP. , RFC 7938 BGP -. : , , , path hunting. , , , valley free. , , , . , , . . .
, , BGP. eBGP, link local, : ToR, -1- Pod, Top of Fabric. , BGP , .

, , , , control plane. L3 , , . — , , , multi-path, multi-path , , , . , , , , , . , multi-path, ToR-.

, , — . , , , , BGP, . , corner cases , BGP .
RIFT, .

— , data plane , . : ECMP , Next Hop.
, , Clos- , , , , , . , ECMP, single path-. . , Clos- , Top of fabric, , . , , . , ECMP state.
data plane ? LPM (longest prefix match), , 100 . Next Hop , , 2-4 . , Next Hops ( adjacencies), - 16 64. . : MPLS -? , .

. , . white boxes MPLS. MPLS, , , , ECMP. Et voici pourquoi.

ECMP- IP. Next Hops ( adjacencies, -). , -, Next Hop. IP , , Next Hops.

MPLS , . Next Hops . , , .
, 4000 ToR-, — 64 ECMP, -1 -2. , , ECMP-, ToR , Next Hops.

, Segment Routing . Next Hops. wild card: . , .
, - . ? Clos- . , Top of fabric. . , , Top of fabric, , , . , , , , .
— . , Clos- , , , ToR, Top of fabric , . Pod, Edge Pod, .
. , , Facebook. Fabric Aggregator HGRID. -, -. , . , touch points, . , , -. , - , , . , , . overlays, .

? — CI/CD-. , , , . , , . , , .
, . . — .
. , RIFT. congestion control , , , , RDMA .
, , , , overhead. — HPC Cray Slingshot, commodity Ethernet, . overhead .

, , . — . — . - scale out — . , . . Je vous remercie