Salut
Voyez-vous souvent des commentaires toxiques sur les réseaux sociaux? Cela dépend probablement du contenu que vous regardez. Je propose d'expérimenter un peu sur ce sujet et d'enseigner au réseau neuronal à déterminer les commentaires haineux.
Donc, notre objectif global est de déterminer si un commentaire est agressif, c'est-à-dire que nous avons affaire à une classification binaire. Nous allons écrire un réseau neuronal simple, le former sur un ensemble de données de commentaires provenant de différents réseaux sociaux, puis nous ferons une analyse simple avec visualisation.
Pour le travail, j'utiliserai Google Colab. Ce service vous permet d'exécuter Jupyter Notebooks et d'avoir accès gratuitement au GPU (NVidia Tesla K80), ce qui accélérera l'apprentissage. J'aurai besoin du backend TensorFlow, la version par défaut de Colab 1.15.0, il suffit donc de passer à 2.0.0.
Nous importons le module et le mettons à jour.
from __future__ import absolute_import, division, print_function, unicode_literals import tensorflow as tf !tf_upgrade_v2 -h
Vous pouvez voir la version actuelle comme ceci.
print(tf.__version__)
Le travail préparatoire est terminé, nous importons tous les modules nécessaires.
import os import numpy as np
Description des bibliothèques utilisées
- os - pour travailler avec le système de fichiers
- numpy - pour travailler avec des tableaux
- pandas - une bibliothèque pour analyser les données tabulaires
- keras - pour construire un modèle
- keras.preprocessing.Text - pour le traitement de texte, pour le soumettre sous forme numérique pour la formation d'un réseau de neurones
- sklearn.train_test_split - pour séparer les données de test de la formation
- matplotlib - pour visualiser le processus d'apprentissage
- sklearn.normalize - pour normaliser les données de test et d'entraînement
Analyser les données avec Kaggle
Je charge les données directement dans l'ordinateur portable Colab lui-même. De plus, sans aucun problème, je les extrait déjà.
path = 'labeled.csv' df = pd.read_csv(path) df.head()
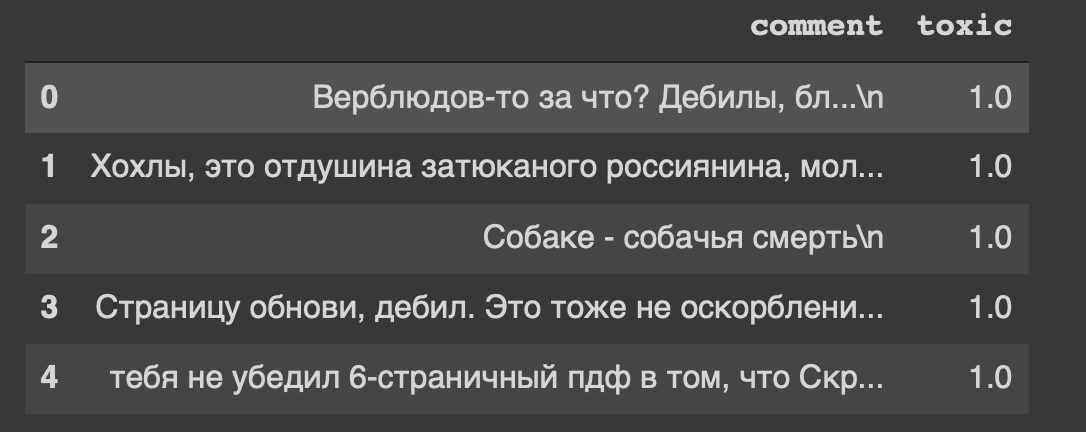
Et c'est le titre de notre jeu de données ... Moi aussi, je me sens mal à l'aise de "rafraîchir la page, crétin".
Donc, nos données sont dans le tableau, nous allons les diviser en deux parties: les données pour la formation et pour le modèle de test. Mais ce n'est que du texte, quelque chose doit être fait.
Traitement des données
Supprimez les caractères de nouvelle ligne du texte.
def delete_new_line_symbols(text): text = text.replace('\n', ' ') return text
df['comment'] = df['comment'].apply(delete_new_line_symbols) df.head()
Les commentaires ont un vrai type de données, nous devons les traduire en entier. Ensuite, enregistrez-le dans une variable distincte.
target = np.array(df['toxic'].astype('uint8')) target[:5]
Nous allons maintenant traiter légèrement le texte à l'aide de la classe Tokenizer. Écrivons-en une copie.
tokenizer = Tokenizer(num_words=30000, filters='!"#$%&()*+,-./:;<=>?@[\\]^_`{|}~\t\n', lower=True, split=' ', char_level=False)
Rapidement sur les paramètres- num_words - nombre de mots fixes (les plus courants)
- filtres - une séquence de caractères à supprimer
- lower - un paramètre booléen qui contrôle si le texte sera en minuscules
- split - le symbole principal pour diviser une phrase
- char_level - indique si un seul caractère sera considéré comme un mot
Et maintenant, nous allons traiter le texte à l'aide de la classe.
tokenizer.fit_on_texts(df['comment']) matrix = tokenizer.texts_to_matrix(df['comment'], mode='count') matrix.shape
Nous avons obtenu 14 000 lignes d'échantillons et 30 000 colonnes d'entités.

Je construis un modèle à partir de deux couches: Dense et Dropout.
def get_model(): model = Sequential() model.add(Dense(32, activation='relu')) model.add(Dropout(0.3)) model.add(Dense(16, activation='relu')) model.add(Dropout(0.3)) model.add(Dense(16, activation='relu')) model.add(Dense(1, activation='sigmoid')) model.compile(optimizer=RMSprop(lr=0.0001), loss='binary_crossentropy', metrics=['accuracy']) return model
Nous normalisons la matrice et divisons les données en deux parties, comme convenu (formation et test).
X = normalize(matrix) y = target X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2) X_train.shape, y_train.shape
Formation modèle
model = get_model() history = model.fit(X_train, y_train, epochs=150, batch_size=500, validation_data=(X_test, y_test)) history
Je montrerai le processus d'apprentissage lors des dernières itérations.

Visualisation du processus d'apprentissage
history = history.history fig = plt.figure(figsize=(20, 10)) ax1 = fig.add_subplot(221) ax2 = fig.add_subplot(223) x = range(150) ax1.plot(x, history['acc'], 'b-', label='Accuracy') ax1.plot(x, history['val_acc'], 'r-', label='Validation accuracy') ax1.legend(loc='lower right') ax2.plot(x, history['loss'], 'b-', label='Losses') ax2.plot(x, history['val_loss'], 'r-', label='Validation losses') ax2.legend(loc='upper right')
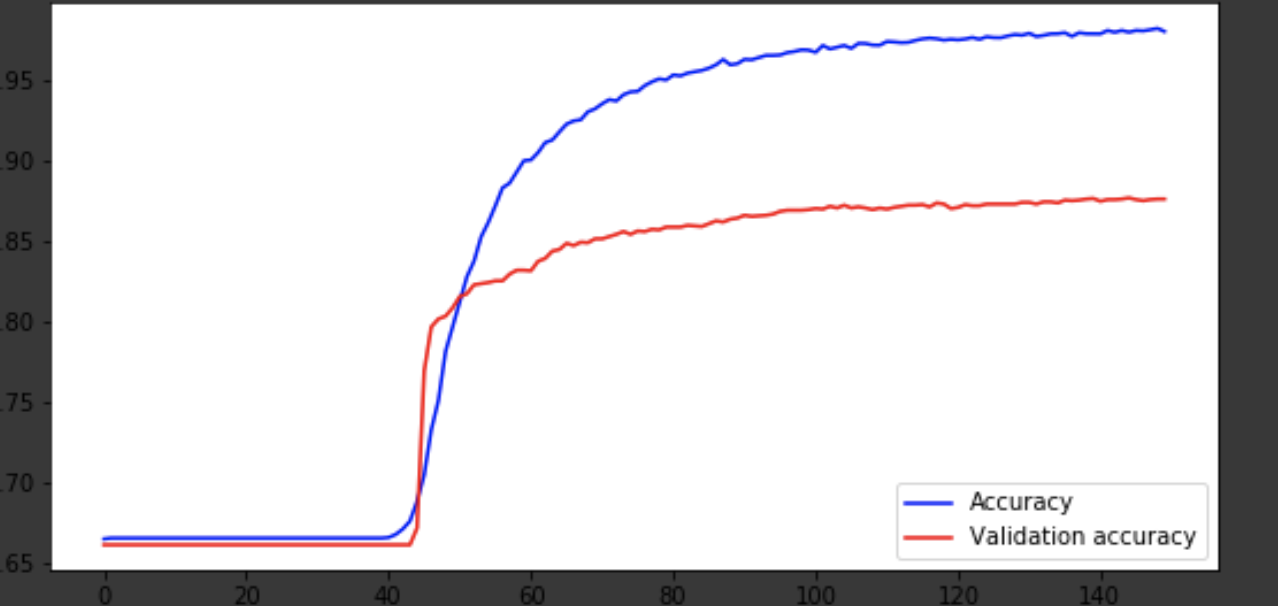
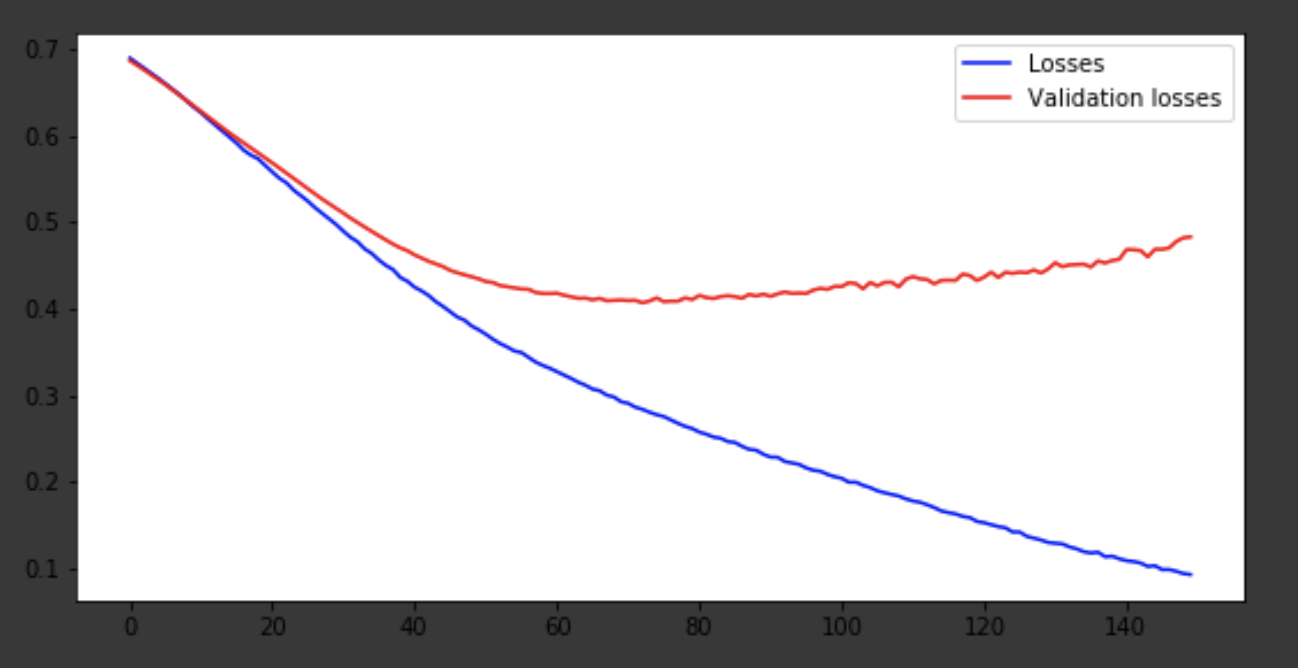
Conclusion
Le modèle est sorti vers la 75e ère, puis il se comporte mal. La précision de 0,85 ne dérange pas. Vous pouvez vous amuser avec le nombre de calques, d'hyperparamètres et essayer d'améliorer le résultat. C'est toujours intéressant et fait partie du métier. Écrivez sur vos pensées dans les commentaires, nous verrons combien de chapeaux cet article gagnera.