Comment rendre la chute douce?

Je n'ai pas trouvé de guide complet sur la gestion des erreurs dans les applications React, j'ai donc décidé de partager l'expérience acquise dans cet article. L'article est destiné aux développeurs débutants et peut être un point de départ pour systématiser la gestion des erreurs dans l'application.
Problèmes et définition d'objectifs
Lundi matin, vous buvez calmement du café et vous vantez d'avoir corrigé plus de bugs que la semaine dernière puis le manager vient en courant et agite les mains - «nous sommes tombés, tout est très triste, nous perdons de l'argent». Vous exécutez et ouvrez votre Mac, accédez à la version de production de votre SPA, faites quelques clics pour jouer au bug, voyez l'écran blanc et seul le Tout-Puissant sait ce qui s'y est passé, montez dans la console, commencez à creuser, à l'intérieur du composant t il y a un composant avec le nom parlant b, dans lequel l'erreur ne peut pas lire la propriété getId d'undefined. N heures de recherche et vous vous précipitez avec un cri victorieux pour lancer le correctif. Ces raids se produisent avec une certaine fréquence et sont devenus la norme, mais si je dis que tout peut être différent? Comment réduire le temps de débogage des erreurs et construire le processus pour que le client ne remarque pratiquement pas d'erreurs de calcul inévitables lors du développement?
Examinons dans l'ordre les problèmes que nous avons rencontrés:- Même si l'erreur est insignifiante ou localisée dans le module, dans tous les cas l'application entière devient inopérante
Avant React version 16, les développeurs ne disposaient pas d'un mécanisme de capture d'erreur standard unique et il y avait des situations où la corruption des données entraînait une baisse du rendu uniquement dans les étapes suivantes ou un comportement d'application étrange. Chaque développeur a traité les erreurs parce qu'il y était habitué, et le modèle impératif avec try / catch ne correspond généralement pas bien aux principes déclaratifs de React. Dans la version 16, l'outil Error Boundaries est apparu, qui a essayé de résoudre ces problèmes, nous verrons comment l'appliquer. - L'erreur est reproduite uniquement dans l'environnement de production ou ne peut pas être reproduite sans données supplémentaires.
Dans un monde idéal, l'environnement de développement est le même que la production, et nous pouvons reproduire n'importe quel bogue localement, mais nous vivons dans le monde réel. Il n'y a pas d'outils de débogage sur le système de combat. Il est difficile et non productif de découvrir de tels incidents, fondamentalement, vous devez faire face au code obscurci et au manque d'informations sur l'erreur, et non à l'essence du problème. Nous ne considérerons pas la question de savoir comment rapprocher les conditions de l'environnement de développement des conditions de production, cependant, nous considérerons des outils qui vous permettent d'obtenir des informations détaillées sur les incidents qui se sont produits.
Tout cela réduit la vitesse de développement et la fidélité des utilisateurs au produit logiciel, je me suis donc fixé les 3 objectifs les plus importants:
- Améliorez l'expérience utilisateur avec l'application en cas d'erreurs;
- Réduisez le délai entre la mise en production de l'erreur et sa détection;
- Accélérez le processus de recherche et de débogage des problèmes dans l'application pour le développeur.
Quelles tâches doivent être résolues?- Gérer les erreurs critiques avec la limite d'erreur
Pour améliorer l'expérience utilisateur avec l'application, nous devons intercepter les erreurs d'interface utilisateur critiques et les traiter. Dans le cas où l'application est constituée de composants indépendants, une telle stratégie permettra à l'utilisateur de travailler avec le reste du système. Nous pouvons également essayer de prendre des mesures pour restaurer l'application après un plantage, si possible.
- Enregistrer les informations d'erreur étendues
Si une erreur se produit, envoyez des informations de débogage au serveur de surveillance, qui filtrera, stockera et affichera des informations sur les incidents. Cela nous aidera à détecter rapidement et à déboguer facilement les erreurs après le déploiement.
Gestion des erreurs critiquesDepuis la version 16, React a modifié le comportement standard de gestion des erreurs. Désormais, les exceptions qui n'ont pas été détectées à l'aide de Error Boundary entraîneront le démontage de l'arborescence React entière et, par conséquent, l'inopérabilité de l'application entière. Cette décision est argumentée par le fait qu'il vaut mieux ne rien montrer que de donner à l'utilisateur la possibilité d'obtenir des résultats imprévisibles. Vous pouvez en lire plus dans la
documentation officielle de React .
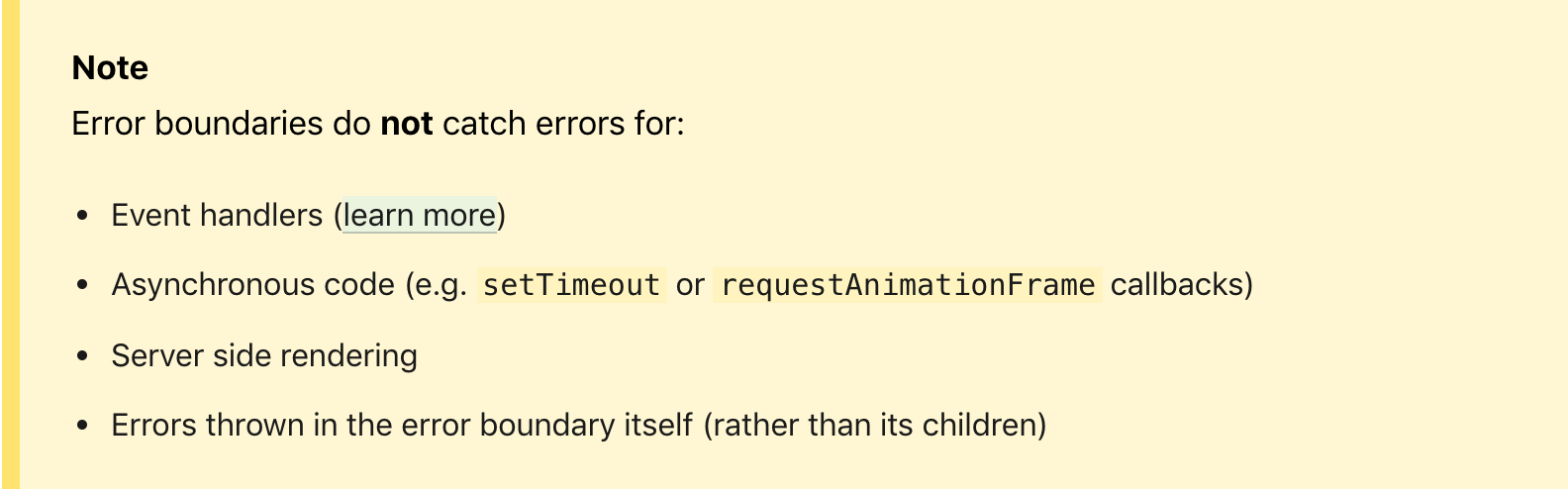
De plus, beaucoup sont confus par la note que la limite d'erreur ne détecte pas les erreurs des gestionnaires d'événements et du code asynchrone, mais si vous y pensez, tout gestionnaire peut finalement changer l'état, en fonction du nouveau cycle de rendu qui sera appelé, ce qui, finalement, compte peut provoquer une erreur dans le code de l'interface utilisateur. Sinon, il ne s'agit pas d'une erreur critique pour l'interface utilisateur et elle peut être gérée de manière spécifique à l'intérieur du gestionnaire.
De notre point de vue, une erreur critique est une exception qui s'est produite à l'intérieur du code de l'interface utilisateur et si elle n'est pas traitée, l'arborescence React entière sera démontée. Les erreurs restantes ne sont pas critiques et peuvent être traitées selon la logique de l'application, par exemple, à l'aide de notifications.
Dans cet article, nous nous concentrerons sur la gestion des erreurs critiques, malgré le fait que les erreurs non critiques peuvent également entraîner une inopérabilité de l'interface dans le pire des cas. Leur traitement est difficile à séparer en un bloc commun et chaque cas individuel nécessite une décision en fonction de la logique d'application.
En général, les erreurs non critiques peuvent être très critiques (un jeu de mots), donc les informations les concernant doivent être enregistrées de la même manière que pour les erreurs critiques.
Nous concevons maintenant la limite d'erreur pour notre application simple, elle se composera d'une barre de navigation, d'un en-tête et d'un espace de travail principal. Il est assez simple pour se concentrer uniquement sur la gestion des erreurs, mais il a une structure typique pour de nombreuses applications.
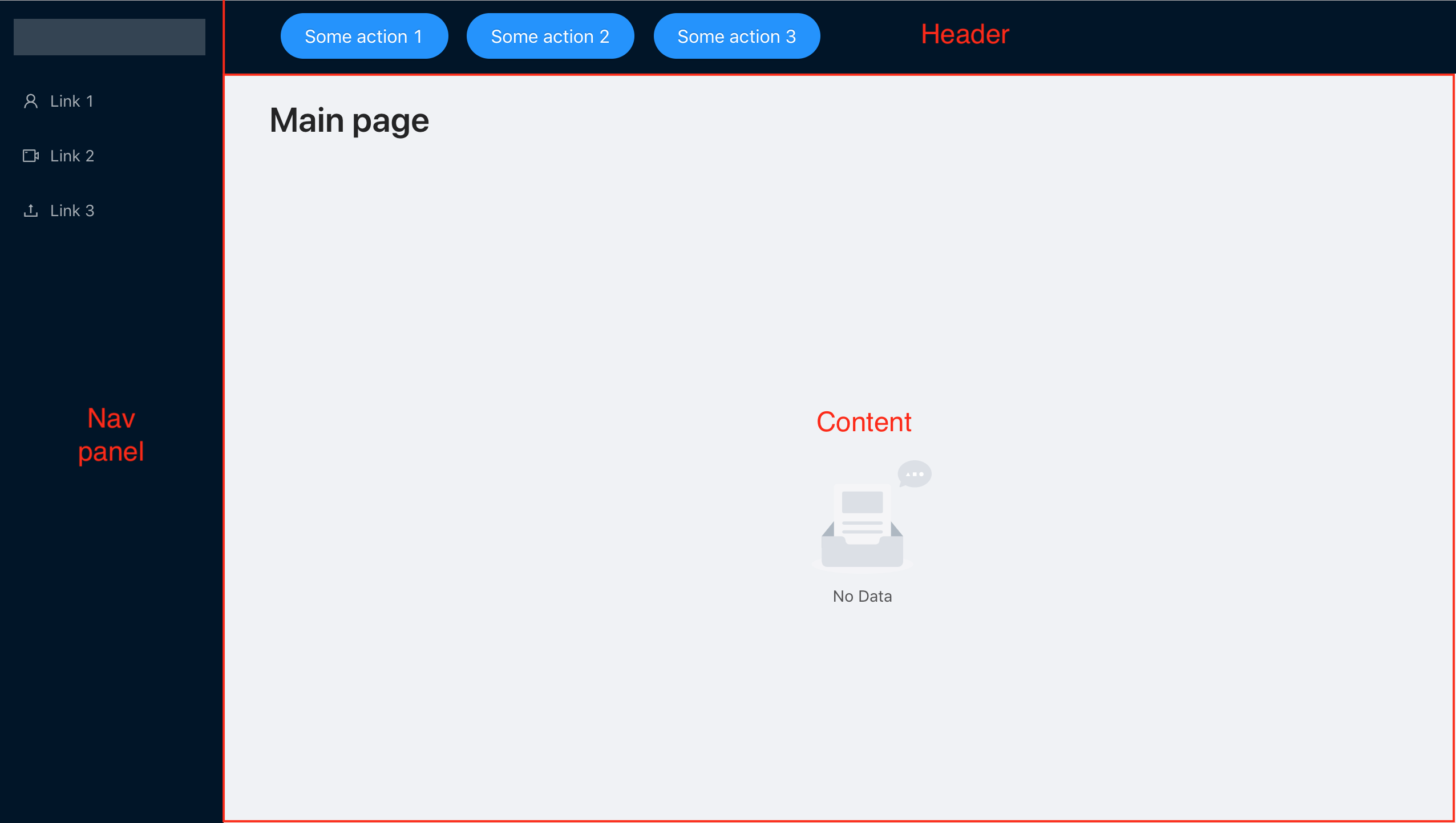
Nous avons un panneau de navigation de 3 liens, chacun menant à des composants indépendants les uns des autres, nous voulons donc obtenir un comportement tel que même si l'un des composants ne fonctionne pas, nous pouvons continuer à travailler avec les autres.
Par conséquent, nous aurons ErrorBoundary pour chaque composant accessible via le menu de navigation et le ErrorBoundary général, qui informe sur le plantage de l'application entière, dans le cas où une erreur s'est produite dans le composant d'en-tête, le panneau de navigation ou dans ErrorBoundary, mais nous ne l'avons pas résolu traiter et jeter plus loin.
Envisagez de répertorier une application entière enveloppée dans ErrorBoundary
const AppWithBoundary = () => ( <ErrorBoundary errorMessage="Application has crashed"> <App/> </ErrorBoundary> )
function App() { return ( <Router> <Layout> <Sider width={200}> <SideNavigation /> </Sider> <Layout> <Header> <ActionPanel /> </Header> <Content> <Switch> <Route path="/link1"> <Page1 title="Link 1 content page" errorMessage="Page for link 1 crashed" /> </Route> <Route path="/link2"> <Page2 title="Link 2 content page" errorMessage="Page for link 2 crashed" /> </Route> <Route path="/link3"> <Page3 title="Link 3 content page" errorMessage="Page for link 3 crashed" /> </Route> <Route path="/"> <MainPage title="Main page" errorMessage="Only main page crashed" /> </Route> </Switch> </Content> </Layout> </Layout> </Router> ); }
Il n'y a pas de magie dans ErrorBoundary, c'est juste un composant de classe dans lequel la méthode componentDidCatch est définie, c'est-à-dire que n'importe quel composant peut devenir ErrorBoundary, si vous y définissez cette méthode.
class ErrorBoundary extends React.Component { state = { hasError: false, } componentDidCatch(error) {
Voici à quoi ressemble ErrorBoundary pour le composant Page, qui sera rendu dans le bloc Content:
const PageBody = ({ title }) => ( <Content title={title}> <Empty className="content-empty" /> </Content> ); const MainPage = ({ errorMessage, title }) => ( <ErrorBoundary errorMessage={errorMessage}> <PageBody title={title} /> </ErrorBoundary>
Étant donné que ErrorBoundary est un composant React normal, nous pouvons utiliser le même composant ErrorBoundary pour encapsuler chaque page dans son propre gestionnaire, en passant simplement différents paramètres à ErrorBoundary, car ce sont des instances différentes de la classe, leur état ne dépendra pas les uns des autres .
IMPORTANT: ErrorBoundary peut détecter des erreurs uniquement dans les composants qui se trouvent en dessous dans l'arborescence.Dans la liste ci-dessous, l'erreur ne sera pas interceptée par le ErrorBoundary local, mais sera levée et interceptée par le gestionnaire au-dessus de l'arborescence:
const Page = ({ errorMessage }) => ( <ErrorBoundary errorMessage={errorMessage}> {null.toString()} </ErrorBoundary> );
Et ici, l'erreur est détectée par la limite d'erreur locale:
const ErrorProneComponent = () => null.toString(); const Page = ({ errorMessage }) => ( <ErrorBoundary errorMessage={errorMessage}> <ErrorProneComponent /> </ErrorBoundary> );
Après avoir encapsulé chaque composant séparé dans notre ErrorBoundary, nous avons obtenu le comportement nécessaire, mis le code délibérément erroné dans le composant à l'aide de link3 et voir ce qui se passe. Nous oublions intentionnellement de passer le paramètre steps:
const PageBody = ({ title, steps }) => ( <Content title={title}> <Steps current={2} direction="vertical"> {steps.map(({ title, description }) => (<Step title={title} description={description} />))} </Steps> </Content> ); const Page = ({ errorMessage, title }) => ( <ErrorBoundary errorMessage={errorMessage}> <PageBody title={title} /> </ErrorBoundary> );
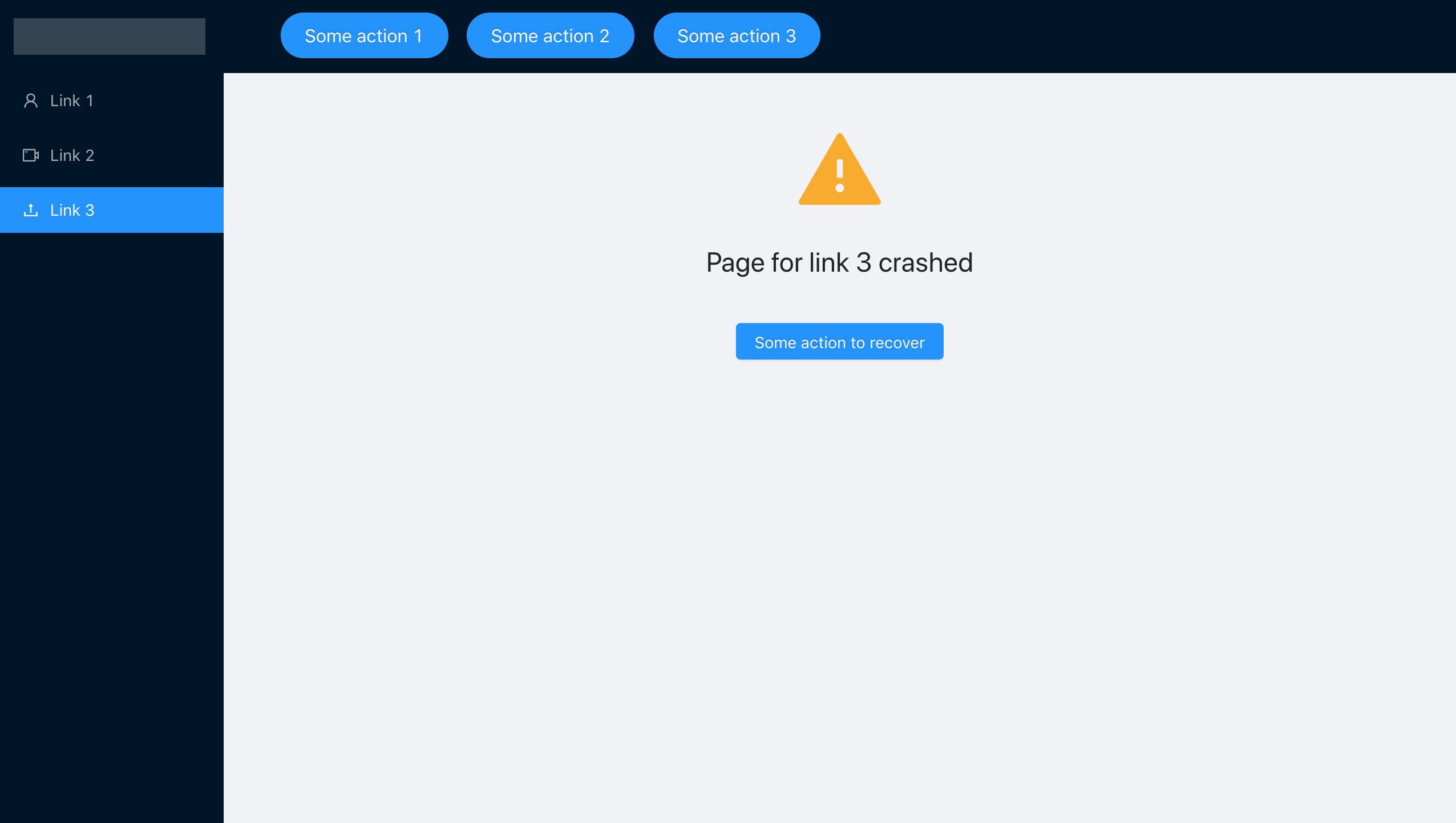
L'application nous informera qu'une erreur s'est produite, mais elle ne tombera pas complètement, nous pouvons naviguer dans le menu de navigation et travailler avec d'autres sections.
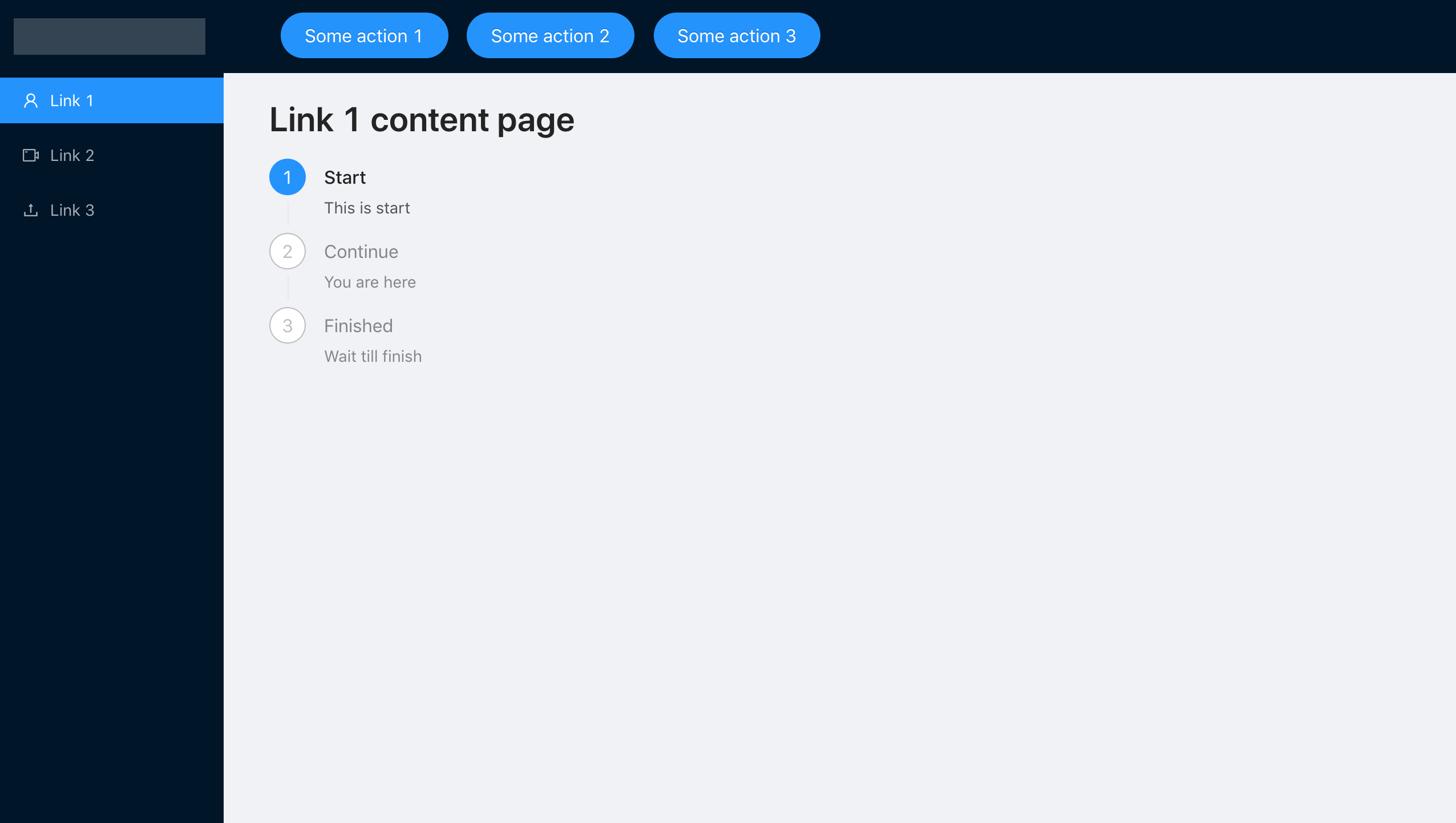
Une configuration aussi simple nous permet d'atteindre facilement notre objectif, mais dans la pratique, peu de gens accordent beaucoup d'attention au traitement des erreurs, ne planifiant que l'exécution régulière de l'application.
Enregistrement des informations d'erreurMaintenant que nous avons placé suffisamment de ErrorBoundary dans notre application, il est nécessaire de sauvegarder les informations sur les erreurs afin de les détecter et de les corriger le plus rapidement possible. Le moyen le plus simple consiste à utiliser les services SaaS, tels que Sentry ou Rollbar. Ils ont des fonctionnalités très similaires, vous pouvez donc utiliser n'importe quel service de surveillance des erreurs.
Je vais montrer un exemple de base sur Sentry, car en quelques minutes, vous pouvez obtenir des fonctionnalités minimales. Dans le même temps, Sentry lui-même intercepte les exceptions et modifie même console.log pour obtenir toutes les informations d'erreur. Après cela, toutes les erreurs qui se produiront dans l'application seront envoyées et stockées sur le serveur. Sentry dispose de mécanismes de filtrage des événements, d'obscurcissement des données personnelles, de liens vers les versions et bien plus encore. Nous ne considérerons que le scénario d'intégration de base.
Pour vous connecter, vous devez vous inscrire sur leur site officiel et parcourir le guide de démarrage rapide, qui vous dirigera immédiatement après l'inscription.
Dans notre application, nous ajoutons seulement quelques lignes et tout décolle.
import * as Sentry from '@sentry/browser'; Sentry.init({dsn: “https:
Encore une fois, cliquez sur le lien / link3 dans notre application et obtenez l'écran d'erreur, après quoi nous allons à l'interface sentinelle, apparemment qu'un événement s'est produit et échoue à l'intérieur.
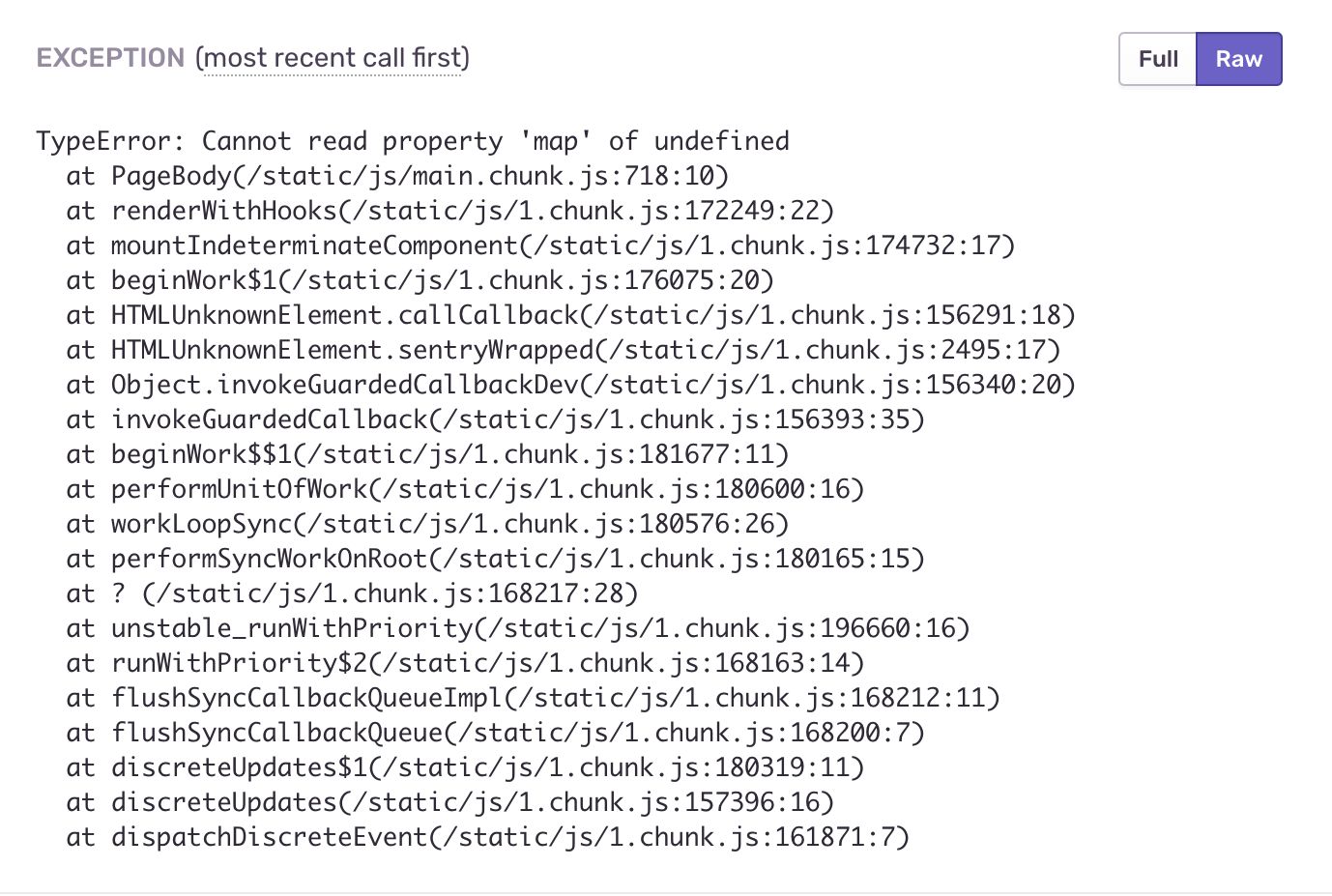
Les erreurs sont automatiquement regroupées par type, fréquence et heure d'occurrence; divers filtres peuvent être appliqués. Nous avons un événement - nous y tombons et sur l'écran suivant, nous voyons un tas d'informations utiles, par exemple, la trace de la pile

et la dernière action de l'utilisateur avant l'erreur (fil d'Ariane).
Même avec une configuration aussi simple, nous pouvons accumuler et analyser les informations sur les erreurs et les utiliser pour un débogage ultérieur. Dans cet exemple, une erreur est envoyée par le client en mode développement, afin que nous puissions observer les informations complètes sur le composant et les erreurs. Afin d'obtenir des informations similaires à partir du mode de production, vous devez en outre configurer la synchronisation des données de version avec Sentry, qui stockera le sourcemap en lui-même, vous permettant ainsi d'enregistrer suffisamment d'informations sans augmenter la taille du bundle. Nous ne considérerons pas une telle configuration dans le cadre de cet article, mais j'essaierai de parler des pièges d'une telle solution dans un article séparé après sa mise en œuvre.
Le résultat:La gestion des erreurs à l'aide de ErrorBoundary nous permet de lisser les coins avec un plantage partiel de l'application, augmentant ainsi l'expérience utilisateur du système et l'utilisation de systèmes de surveillance des erreurs spécialisés pour réduire le temps de détection et de débogage des problèmes.
Réfléchissez soigneusement à une stratégie de traitement et de surveillance des erreurs de votre application, cela vous fera gagner beaucoup de temps et d'efforts à l'avenir.
Une stratégie bien pensée améliorera principalement le processus de traitement des incidents, et ce n'est qu'alors qu'elle affectera la structure du code.PS Vous pouvez essayer différentes options de configuration ErrorBoundary ou connecter vous-même Sentry à l'application dans la branche feature_sentry, en remplaçant les clés par celles obtenues lors de l'inscription sur le site.
Application de démonstration Git-hubDocumentation officielle de React's Error Boundary