En prévision du début d'un nouveau fil de discussion sur le cours "Neural Networks in Python", nous avons préparé pour vous la traduction d'un article intéressant.
L'un des principaux problèmes de mise en œuvre de la nouvelle génération d'ordinateurs quantiques réside dans leur client le plus élémentaire: le
qubit . Les Qubits peuvent interagir avec tout objet dans le voisinage immédiat qui transfère de l'
énergie à proximité de leurs propres
photons errants (c'est-à-dire des champs électromagnétiques indésirables, des
phonons (vibrations mécaniques d'un appareil quantique) ou des défauts quantiques (irrégularités sur la surface de la puce apparues lors de la phase de fabrication), qui peut changer de façon imprévisible l'état des qubits par eux-mêmes.
La question est compliquée par de nombreuses tâches qui mettent les outils utilisés pour contrôler les qubits. Les Qubits sont traités et lus par
des méthodes
classiques : des signaux analogiques sous forme de champs électromagnétiques, couplés à une carte physique dans laquelle un qubit est intégré, par exemple, un microcircuit supraconducteur. Les imperfections de l'électronique de commande (entraînant un bruit blanc), les interférences provenant de sources de rayonnement externes et les fluctuations des convertisseurs numérique-analogique conduisent à des erreurs stochastiques encore plus importantes qui aggravent le fonctionnement des microcircuits quantiques. Ces problèmes pratiques affectent la précision des calculs et, par conséquent, limitent l'application de la prochaine génération d'appareils quantiques.
Afin d'augmenter la puissance de calcul des ordinateurs quantiques et d'ouvrir la voie à l'informatique quantique à grande échelle, il est d'abord nécessaire de construire des modèles physiques qui décrivent avec précision ces problèmes expérimentaux.
Dans l'article
«Universal Quantum Control through Deep Reinforcement Learning» , publié dans le Nature Partner Journal (npj) Quantum Information (https://www.nature.com/npjqi/articles), nous avons présenté une nouvelle structure de contrôle quantique créée à l'aide de l'apprentissage en profondeur avec renforcement dans lequel les problèmes pratiques d'optimisation du contrôle quantique peuvent être résumés avec une seule fonction de
perte . La structure considérée fournit une diminution de l'erreur moyenne de la
porte quantique à deux ordres de grandeur par rapport aux solutions stochastiques standard de descente de gradient et une réduction significative du temps de porte aux valeurs optimales des analogues de synthèse de porte. Nos résultats ouvrent de nouveaux horizons pour la modélisation quantique, la chimie quantique et les tests d'excellence quantique utilisant des dispositifs quantiques dans un avenir proche.
L'innovation de ce paradigme de contrôle quantique est basée sur le développement d'une fonction de contrôle quantique et d'une méthode d'optimisation efficace basée sur l'apprentissage profond avec renforcement. Pour développer une fonction de perte complète, nous devons d'abord développer un modèle physique d'un processus de contrôle quantique réaliste dans lequel nous pouvons prédire avec précision l'ampleur de l'erreur. L'une des erreurs les plus ennuyeuses dans l'évaluation de la précision de l'informatique quantique est la fuite: la quantité d'informations quantiques perdues pendant le calcul. Une telle fuite se produit généralement lorsque l'état quantique d'un qubit passe à un niveau d'énergie supérieur ou à un niveau inférieur en raison d'une émission spontanée. En raison d'une erreur de fuite, non seulement les informations quantiques utiles sont perdues, mais elles dégradent également la «quanticité» et réduisent finalement les performances d'un ordinateur quantique aux performances d'un ordinateur avec une architecture classique.
Une pratique courante pour estimer avec précision les informations perdues pendant un calcul quantique consiste à modéliser tout le calcul en premier. Cependant, cela nie tout l'intérêt de créer des ordinateurs quantiques à grande échelle, car leur avantage est qu'ils sont capables d'effectuer des calculs impossibles pour les ordinateurs classiques. Avec l'amélioration de la modélisation physique, notre fonction de perte commune nous permet d'optimiser conjointement les erreurs de fuite accumulées, les violations des conditions aux limites de contrôle, le temps total de la vanne et la précision de la vanne.
Avec la nouvelle fonction de gestion des pertes, l'étape suivante consiste à utiliser un outil d'optimisation efficace pour le minimiser. Les méthodes d'optimisation existantes ne sont pas assez bonnes pour rechercher des solutions de haute précision fiables pour contrôler les fluctuations. Au lieu de cela, nous utilisons une méthode basée sur la méthode de l'apprentissage en profondeur avec renforcement (RL),
RL - un domaine de confiance . Étant donné que cette méthode présente de bonnes performances dans toutes les tâches de test, elle est intrinsèquement résistante au bruit des échantillons et peut optimiser les problèmes de contrôle complexes avec des centaines de millions de paramètres de contrôle. Une différence significative entre cette méthode RL sur politique et les méthodes RL hors politique précédemment étudiées est que la politique de gestion est présentée indépendamment de la gestion des pertes. D'un autre côté, toutes les politiques RL, telles que l'
apprentissage Q , utilisent un seul réseau neuronal pour représenter le chemin de contrôle et la récompense associée, où la trajectoire de contrôle détermine les signaux de contrôle qui devraient être associés aux qubits sur différentes mesures, et la récompense associée mesure la qualité du tact. contrôle quantique.
Le RL sur stratégie est bien connu pour sa capacité à utiliser des fonctionnalités non locales dans les chemins de contrôle, ce qui devient critique lorsque le paysage de contrôle est multidimensionnel et contient un grand nombre combinatoire de solutions non globales, comme c'est souvent le cas avec les systèmes quantiques.
Nous codons le chemin de contrôle dans un réseau neuronal à trois couches, entièrement connecté - politique NN, et la fonction de perte de contrôle dans le deuxième réseau neuronal - valeur NN, qui reflète la future récompense actualisée. Des solutions de contrôle fiables ont été obtenues avec des agents d'apprentissage par renforcement qui entraînent les deux réseaux de neurones dans un environnement stochastique simulant un contrôle du bruit réaliste. Nous proposons une solution pour contrôler un ensemble de portes quantiques à deux qubits paramétrées en continu, qui sont d'une importance particulière dans l'application à la chimie quantique, mais sont trop coûteuses à mettre en œuvre en utilisant un ensemble universel de portes standard.
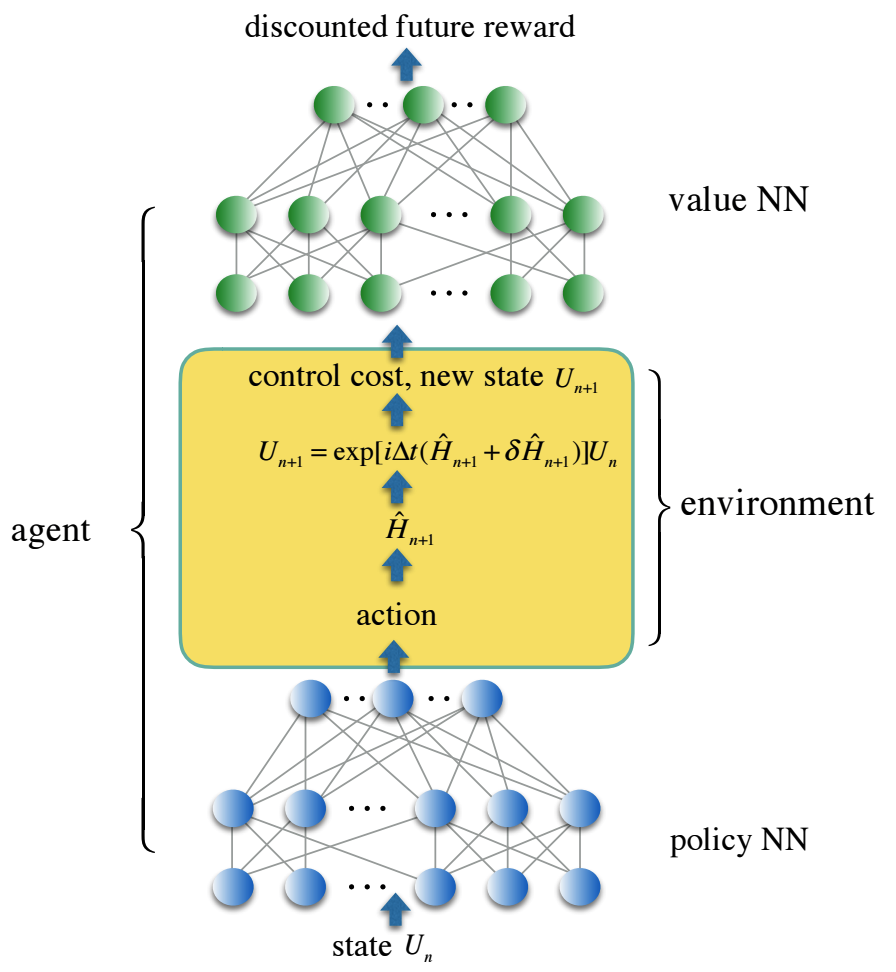
Dans le cadre de cette nouvelle structure, notre simulation numérique montre une diminution au centuple des erreurs des portes quantiques et une réduction du temps des portes pour la famille des portes quantiques de simulation paramétrées en continu d'une moyenne d'un ordre de grandeur par rapport aux approches traditionnelles utilisant un ensemble universel de portes.
Ce travail souligne l'importance d'utiliser de nouvelles méthodes d'apprentissage automatique et les derniers algorithmes quantiques qui utilisent la flexibilité et la puissance de traitement supplémentaire d'un circuit de commande quantique universel. Afin d'intégrer pleinement l'apprentissage automatique et d'augmenter les capacités de calcul, il est nécessaire de mener des expériences supplémentaires, similaires à ce qui a été donné dans ce travail.