
Selon les analystes, le marché des centres de données augmentera de 38% par an et atteindra 35 milliards de dollars en cinq ans, et le créneau le plus gourmand en ressources (en termes d'intensité informatique) est l'apprentissage en profondeur, les réseaux de neurones et les tâches d'IA.
Bien sûr, Intel ne sera pas indifférent à regarder comment Nvidia (et AMD, dans une moindre mesure) avec ses GPU capturer ce marché, y compris le secteur à la croissance la plus rapide. La semaine dernière, le géant de l'industrie microélectronique a fait plusieurs annonces à la fois:
Modules informatiques Aurora
Sur ces CPU, GPU et oneAPI, ils composeront des modules informatiques Aurora pour le supercalculateur éponyme avec un niveau de performance de 1 exaflops (10 ^ 18 opérations par seconde). Il est supposé que cette machine sera installée au Argonne National Laboratory du US Department of Energy.

Chaque module de calcul possède deux processeurs Sapphire Rapids et six GPU connectés via le bus CXL.

Selon les
estimations d'AnandTech , dans un système de 200 racks, comme indiqué, si vous soustrayez la réserve pour le réseau et les lecteurs, environ 2400 nœuds Aurora à deux unités conviendront. Cela représente un total d'environ 5 000 processeurs Sapphire Rapids et 15 000 Ponte Vecchio. Si nous divisons les performances déclarées de 1 exaflops par le nombre de GPU, alors environ 66,6 téraflops par GPU sortent. De plus, en supposant une performance CPU de 14 téraflops, nous obtenons toujours environ 50 téraflops, c'est-à-dire qu'il s'agit d'une multiplication par cinq des performances GPU dans les centres de données d'ici 2021.
Bien sûr, les plans ne se limitent pas à un supercalculateur pour le ministère de l'Énergie. Intel a annoncé que Lenovo et Atos se préparaient déjà à publier des plates-formes de serveurs basées sur le processeur Xeon,
le GPU X
e et oneAPI. Ainsi, les modules informatiques Aurora sous une forme quelconque trouveront application dans d'autres centres de données.
Le supercalculateur devrait être lancé en 2021. Dans le même temps, des GPU X
e 7 nanomètres devraient apparaître sur le marché.
Selon Intel, les solutions haute performance (HPC) traditionnelles convergent maintenant avec l'IA, passant à des charges de travail qui utilisent l'apprentissage en profondeur. Le HPC, l'IA et l'analytique sont les trois principales charges de travail qui stimulent la demande de ressources informatiques: «Une telle variété de besoins informatiques encourage une informatique hétérogène.
Dit Rajeeb Hazra, vice-président et directeur général d'Intel Enterprise and Government. - Les solutions universelles ne conviennent plus ici. À l'ère de la convergence, vous devriez envisager des architectures adaptées aux différents besoins des différents types de charges de travail. »
GPU pour centres de données

Ponte Vecchio est le premier GPU sur la nouvelle architecture X
e . L'architecture elle-même deviendra la base du GPU dans divers segments:
- calcul haute performance;
- apprentissage en profondeur;
- Cloud computing
- graphiques;
- transcodage des médias;
- postes de travail
- ordinateurs de jeu;
- PC de bureau ordinaires;
- appareils mobiles et ultramobiles.

Ari Rauch, vice-président de l'architecture, des graphiques et des logiciels d'Intel, affirme qu'une architecture GPU donnera aux développeurs un «cadre commun», mais dans le cadre de cette architecture, la société développe «beaucoup de microarchitectures qui fournissent les performances les plus efficaces pour chacun d'entre eux». ces charges de travail. "
Le GPU Ponte Vecchio est basé sur la microarchitecture X
e spécifiquement pour HPC et AI, et les caractéristiques de la microarchitecture incluent un moteur de matrice parallèle flexible avec des matrices vectorielles, un débit élevé de calculs en virgule flottante double précision (FP64) et un débit ultra-élevé de cache et de mémoire. Pour les formats INT8, Bfloat16 et FP32, il y aura un moteur de matrice distinct pour le traitement parallèle des matrices (éventuellement un analogue de TensorCore), et pour FP64 l'accélération sera jusqu'à 40 fois pour chaque unité de calcul.
«Cette charge de travail nécessite des performances de calcul élevées, nous nous sommes donc concentrés sur l'ajout d'un grand nombre de modules vectoriels et matriciels et de calcul parallèle adaptés et optimisés pour cette charge de travail», a déclaré Rauch.
Ponte Vecchio sera le premier GPU de la nouvelle génération. Il met en œuvre plusieurs nouvelles technologies développées par Intel ces dernières années:
- processus de production 7 nm;
- disposition en couches des circuits intégrés Foveros 3D;
- EMIB (Embedded Multi-Die Interconnect Bridge) pour connecter plusieurs cristaux sur un même substrat;
- X e Link sur la nouvelle norme d'interconnexion CXL (basée sur PCI Express 5.0) - accès au GPU via un seul espace mémoire.

 Circuits intégrés Foveros 3D en couches de la présentation d'Intel de décembre 2018
Circuits intégrés Foveros 3D en couches de la présentation d'Intel de décembre 2018Les spécifications techniques de la puce n'ont pas encore été annoncées. Ils disent que dans ces GPU, il y aura des milliers d'unités exécutives connectées via XEMF (XE Memory Fabric) avec mémoire et cache.

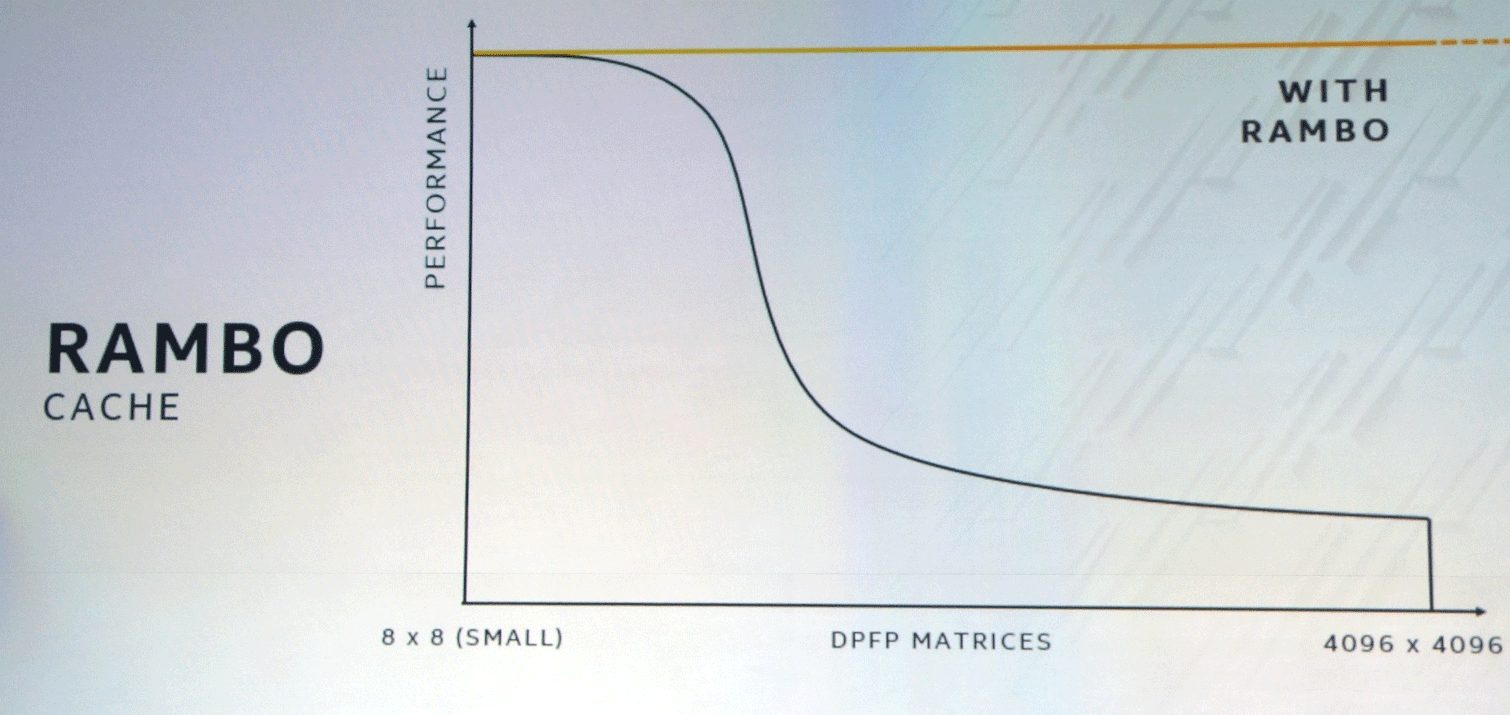
Le bus XEMF fonctionne avec le cache Rambo Cache ultra-rapide spécial pour éliminer le goulot d'étranglement de l'accès à la mémoire. Ce cache se connecte aux unités de calcul via Foveros et EMIB sera utilisé pour connecter la mémoire HBM.
La combinaison d'approches SIMT et SIMD spécifiques au GPU et au CPU, respectivement, et des instructions vectorielles de longueur variable fourniront une amélioration significative des performances dans certaines classes de tâches.

Beaucoup s'attendent à ce qu'Intel soit en concurrence avec Nvidia et AMD sur le marché des centres de données et de l'IA. Il ne s'agit pas seulement de la concurrence par les prix, mais aussi de l'émergence de plateformes technologiques alternatives, qui stimuleront le progrès technologique global.
OneAPI: sommet d'abstraction pour le fer hétérogène
En plus de l'annonce de nouveaux équipements, Intel a publié une version bêta des interfaces logicielles unifiées oneAPI. Ils sont conçus pour faciliter le travail des développeurs qui, pour optimiser au maximum leurs programmes, ont traditionnellement dû basculer entre différents langages de programmation et bibliothèques à l'aide de middleware et de frameworks.
Par défaut, il est admis dans l'industrie qu'à un faible niveau, un code différent doit être préparé pour chaque architecture. Par exemple, TensorFlow était initialement complètement optimisé au moment de la sortie pour le GPU d'un fournisseur (pour Nvidia CUDA).
"OneAPI tente de résoudre ces problèmes en offrant une interface commune de bas niveau pour du matériel hétérogène aux performances sans compromis", a déclaré Bill Savage, vice-président de la division architecture, graphiques et logiciels d'Intel. «Pour que les développeurs puissent écrire des programmes directement sur le matériel via des langages et des bibliothèques communs à différentes architectures et fournisseurs, ainsi que pour s'assurer que les middleware et les frameworks fonctionnent sur une seule API et sont entièrement optimisés pour les développeurs qui sont au sommet de cette abstraction.»
Intel présente oneAPI comme un «standard ouvert pour la prise en charge communautaire et industrielle», qui permettra de «réutiliser le code entre les architectures et le matériel de différents fabricants»
La spécification oneAPI comprendra le langage de programmation DPC ++ inter-architecture standard basé sur C ++ et SYCL, ainsi que des «API puissantes pour accélérer les fonctions clés spécifiques au domaine».
En plus du compilateur DPC ++ et de la bibliothèque d'API, des outils spéciaux seront publiés, notamment VTune Inspector Advisor, un débogueur et un "outil de compatibilité" pour le portage du code CUDA (Nvidia) vers DPC ++.
Pour stimuler la transition vers oneAPI, Intel a lancé un bac à sable dans
DevCloud pour développer et tester des programmes sur un certain nombre de CPU, GPU et FPGA. Travailler avec le bac à sable ne nécessite l'installation d'aucun matériel ou logiciel.
Pendant ce temps, les revenus de Nvidia pour le trimestre
ont atteint 3 milliards de dollars , tandis que sur le marché des centres de données, la croissance sur les trois mois était de 11% (726 millions de dollars). Les ventes de processeurs V100 et T4 battent tous les records. Intel la regarde toujours de l'extérieur, mais nous savons déjà quelle sera la réponse. Le plus intéressant ne fait que commencer.