
Lors du forum RAIF 2019, qui s'est tenu à Skolkovo dans le cadre d'Open Innovations, j'ai parlé de la manière dont l'introduction des modèles d'apprentissage automatique est mise en œuvre. En lien avec les caractéristiques du métier, je passe plusieurs jours par semaine en production, introduisant des modèles de machine learning, et le reste du temps développant ces modèles. Ce message est un enregistrement d'un rapport dans lequel j'ai essayé de résumer mon expérience.
Nous commençons par décrire le processus en grands traits, en entrant progressivement dans les détails de chaque étape.
Que nous comptions sur l'optimisation de la production sur la base des résultats d'une enquête à part entière (idéalement), ou simplement sur la collecte d'idées, «l'optimisation du patchwork», le résultat est en quelque sorte la
formation d'une liste d'initiatives . Il est nécessaire de comprendre quels domaines de production nous allons optimiser. Ce processus prend généralement environ deux mois.
Ensuite, nous passons à la phase de
pilotage , cela prendra de trois à quatre mois - nous devons construire un modèle de base et comprendre si le machine learning lui est applicable et quels avantages il peut apporter aux entreprises.
La prochaine étape, qui est beaucoup plus longue, ne nécessite pas beaucoup d'apprentissage automatique - la
mise en œuvre est le moment où vous devez intégrer, construire des systèmes actuels et commencer à obtenir le profit que nous avions prévu dans la deuxième étape. La mise en œuvre prend généralement de six mois à neuf mois.
L'étape de
contrôle termine le processus. C'est une chose de faire un modèle et de montrer, et une autre de maintenir le modèle pendant un certain temps. La production évolue, les machines-outils sont remplacées. Dans ces conditions, le modèle doit constamment «tourner» et rechercher de nouvelles opportunités d'optimisation.
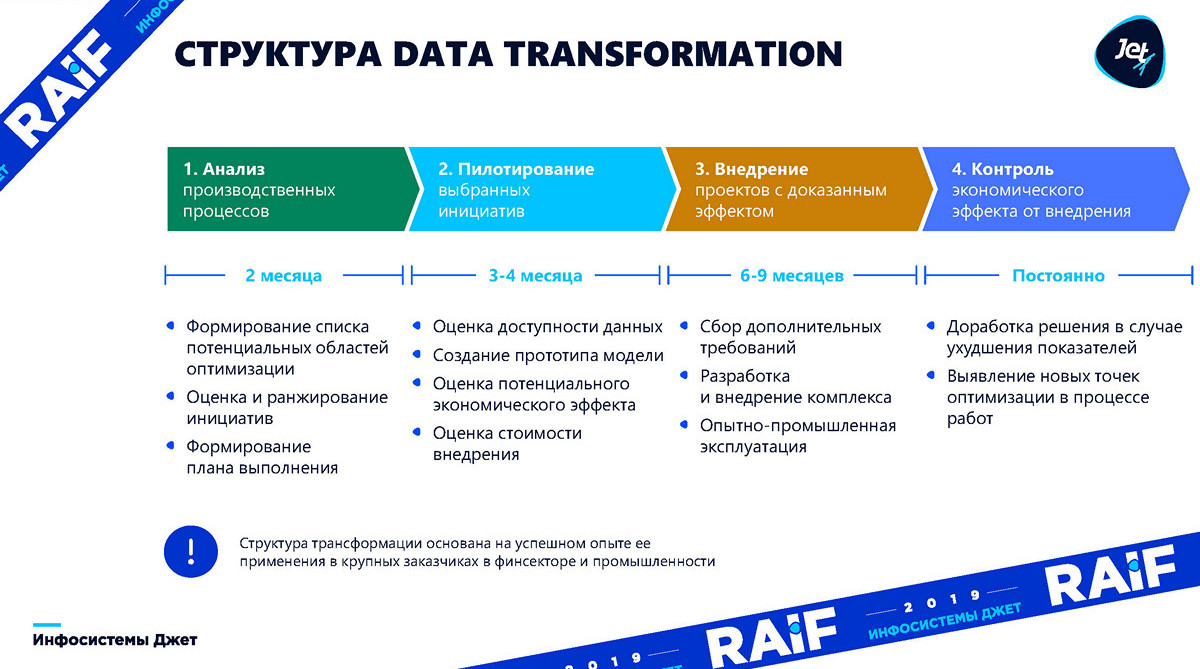
Maintenant plus en détail dans l'ordre:
À la recherche d'une hypothèse
D'où vient l'hypothèse? Qui la nommera?
Habituellement, il est habituel d'aller au service informatique pour des hypothèses, mais les personnes qui peuvent configurer des systèmes y travaillent, connaissent l'intégration et ne connaissent rien au machine learning. De plus, ils ne connaissent pas très bien la production. Ils n'ont aucune compétence pour comprendre dans la pratique comment fonctionne l'apprentissage automatique.
La tentative numéro deux est d'aller à l'hypothèse de production. En effet, les spécialistes proches de la production connaissent les caractéristiques techniques du procédé, mais ... ne connaissent pas le machine learning. Par conséquent, ils ne peuvent pas dire où cela s'applique et où ce n'est pas le cas.
Dans ce cas, d'où peut provenir l'hypothèse? Pour ce faire, ils ont créé un poste spécial - chef de la transformation numérique. Il s'agit d'une personne engagée dans la transformation numérique. Ou Chief Date Officer - une personne qui connaît les données et comment elles peuvent être appliquées. Si ces deux personnes ne sont pas dans l'entreprise, alors les hypothèses devraient provenir de la haute direction. Autrement dit, des spécialistes qui comprennent parfaitement l'entreprise et sont engagés dans la technologie moderne.
Si l'entreprise n'a ni le Chief Digital Transformation Officer, ni le Chief Date Officer, et que la direction n'est pas en mesure de donner naissance à une hypothèse, alors ... les concurrents viendront à la rescousse. S'ils ont mis en œuvre quelque chose, cela ne peut pas leur être retiré. Mais, une entreprise intégratrice connectée au projet peut dire quoi et comment être optimisé.

Comment choisir une idée?
Quatre facteurs sont importants ici:
- Le chiffre d'affaires du processus à optimiser.
- Écarts importants dans le processus. Il existe une méthodologie à six sigma, ce qui suggère que tous les processus devraient s'écarter d'au plus six écarts-types de leurs résultats. Si vous avez plus de ces écarts, vous devez les analyser et l'apprentissage automatique vous aidera.
- Disponibilité et disponibilité des données. Si, par exemple, vous recevez des données de capteurs sur le fonctionnement de l'équipement après 12 mois, vous ne mettrez pas en œuvre l'apprentissage automatique.
- La complexité de la mise en œuvre de la numérisation dans le processus. Le coût de l'introduction de votre modèle, comparé au coût de ce qu'il peut économiser.
Quelles sont les données?
La structure des données est la suivante:
Structuré: quelques tableaux, lectures - tout est simple. Lorsque nous voulons utiliser des données provenant de réseaux sociaux ou de séries de photos, nous devons traiter des données non structurées. Il est nécessaire de dire que ces données doivent également être structurées, se transformant en nombres que l'apprentissage automatique peut percevoir. Le troisième type de données est enfilé. Si nous travaillons avec des données qui changent toutes les millisecondes, nous devons immédiatement penser à l'équilibrage de charge: notre système peut-il résister à la vitesse de sa réception?

Par origine, les données sont réparties en:
Automatisé - les capteurs génèrent des nombres, nous leur faisons confiance ou non. Mais ils sont à peu près les mêmes. Saisie manuelle - ici, vous devez comprendre qu'il peut y avoir une erreur liée au facteur humain. Et le modèle doit y résister. Données externes - nous serons peut-être intéressés par les taux de change, si la mise en œuvre est liée à des transactions financières, ou des prévisions météorologiques, si nous prévoyons des échanges de chaleur et de température. Les données statiques sont tout ce qui peut être réutilisé.

Problèmes de données
- Complétude - le moment où certaines données / mois peuvent être ignorés.
- L'erreur de changement - si, par exemple, votre capteur a une erreur de 5 millisecondes, alors le modèle avec une précision de deux millisecondes - vous ne pourrez pas, car les données d'entrée commencent à diverger.
- Accessibilité en ligne - si vous voulez faire une prévision «maintenant», les données doivent être prêtes.
- Durée de stockage - si vous souhaitez utiliser les tendances annuelles et que vous devez prévoir la demande et que les données ne sont stockées que pendant six mois - vous ne construirez pas de modèle.
Travailler avec des données
Écoutez les professionnels, mais ne croyez que les données. Vous devez aller à l'atelier, parler à des professionnels, aller à l'usine, parler aux opérateurs, comprendre leur métier. Mais croyez seulement aux données. Il y avait beaucoup d'exemples où les opérateurs disent que cela ne peut pas être - nous montrons les données - il s'avère que cela se produit vraiment. Un exemple intéressant: une fois que le modèle a montré que le jour de la semaine affecte la production. Le lundi - un coefficient, le vendredi - un autre.
L'effet n'est compréhensible qu'en combat - un prototypage rapide est très important. Le plus important est de voir rapidement comment fonctionne le modèle au quotidien. Dans les présentations et sur les ordinateurs portables locaux, le projet peut sembler complètement différent de ce qu'il est réellement: en règle générale, en fait, des problèmes complètement différents viennent en premier.
Seul un modèle interprété a une chance d'amélioration. Vous devez toujours comprendre clairement pourquoi le modèle a décidé de cette façon et non autrement.
Travailler avec des métriques
En réalité, la dépendance de l'exactitude du profit peut être quelconque. Jusqu'à ce que nous comprenions comment cette précision affecte l'effet, la question de la précision n'a aucun sens. Vous devez toujours vous traduire en profit. Les graphiques ci-dessous montrent que les bénéfices peuvent varier en fonction de la précision du modèle. Le premier graphique illustre à quel point il est difficile de déterminer à l'avance exactement à quel point la précision du modèle est suffisante pour la croissance des bénéfices:
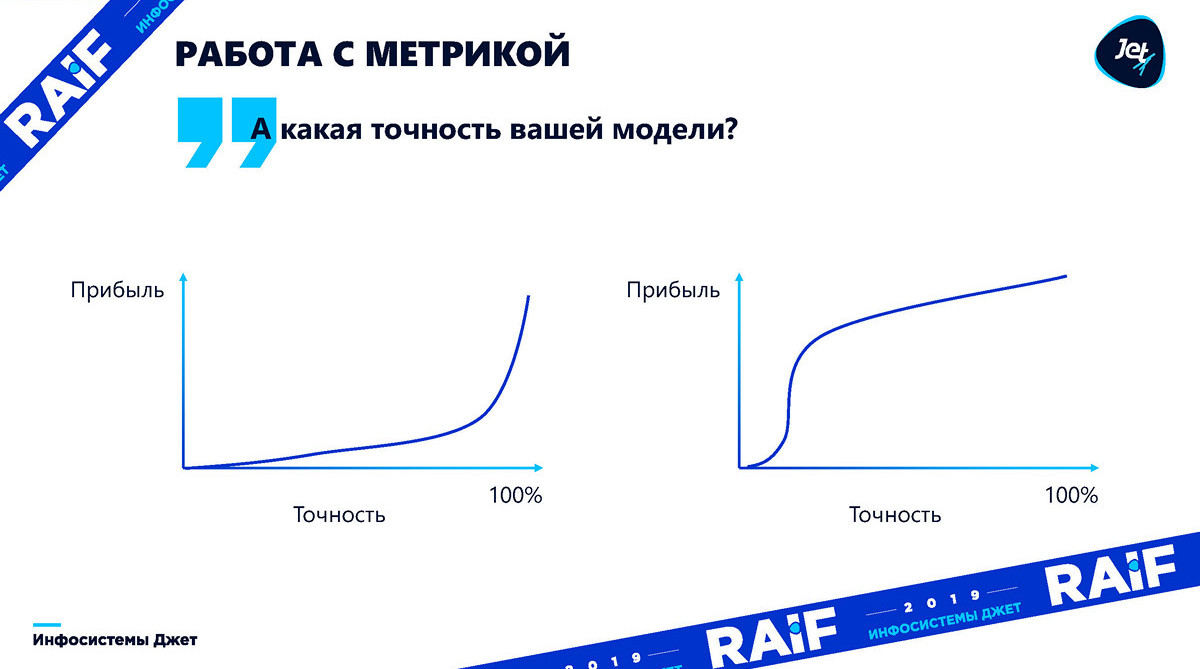
De plus, pour certains cas avec une précision insuffisante du modèle, cela entraînera simplement une perte:

Points clés sur l'intégration:
- L'intégration prend plus de temps que le développement de modèles.
- De nouvelles idées. Parfois, il s'avère que le projet profite là où il n'était pas prévu.
- La formation. Les gens s'adaptent plus vite que le fer.
Un autre point que les spécialistes des données oublient souvent est l'objectif de l'introduction du modèle: prévision ou recommandation. Habituellement, les recommandations sont basées sur le modèle prédictif, mais dans ce cas, le modèle prédictif doit être construit en particulier, car il est assez difficile de trouver la boîte noire minimale avec des effets désagréables soudains. Si nous parlons de mesures de performance, alors en fonction de l'objectif de la mise en œuvre:
- Émettre une prévision, - évaluer le résultat de l'application des connaissances;
- Donnez des recommandations - évaluez la comparaison avec l'ancien processus.
Nuances importantes de la phase de mise en œuvre:
Mise en œuvre / formation
- Connaissances statistiques - la mise en œuvre est beaucoup plus réussie lorsque les employés locaux commencent à fonctionner avec des termes statistiques corrects.
- La motivation des différentes unités structurelles - tout le monde doit comprendre pourquoi cela se produit et ne pas avoir peur du changement.
- Changements organisationnels - au moins un employé verra le résultat du modèle, ce qui signifie qu'il changera son approche du processus. Il s'avère souvent que les gens ne sont pas prêts pour cela.
Le soutien
N'oubliez pas que les conditions changent et que le modèle doit constamment «se tordre» et chercher de nouvelles opportunités d'optimisation. Voici importants:
- Les stratégies de gestion des modèles et la réaction aux prévisions sont un peu d'autopromotion: chez Jet Infosystems, nous y avons réfléchi et avons développé notre propre système JET GALATEA.
- Le facteur humain - les principaux problèmes du modèle sont souvent associés à son utilisation, ou à l'intervention humaine, que le modèle ne pouvait pas prévoir.
- Analyse régulière du travail avec des professionnels du terrain - il est peu probable que tout soit réduit à un seul chiffre, ce qui indiquera ce qui doit être amélioré, il faudra analyser chaque prévision ou recommandation douteuse. Soyez prêt à apprendre une autre profession pour parler la même langue avec les technologues et les opérateurs d'appareils en milieu de travail.

Publié par Nikolay Knyazev, chef du groupe d'apprentissage automatique, Jet Infosystems