
Je suis sûr que le titre a provoqué une réaction saine - "Eh bien, ça a recommencé ..."
La structure de l'article sera la suivante: une déclaration stéréotypée est prise et la «nature» de l'émergence de ce stéréotype est révélée. J'espère que cela vous permet de considérer le choix du paradigme d'échange de données dans vos projets sous un nouvel angle.
Afin de clarifier ce qu'est le RPC, je propose de considérer la norme JSON-RPC 2.0 . Il n'y a aucune clarté avec REST. Et ça ne devrait pas l'être. Tout ce que vous devez savoir sur REST - il est impossible de le distinguer de HTTP .
Les demandes RPC sont plus rapides et plus efficaces car elles autorisent les demandes par lots.
Le fait est que dans RPC, il est possible d'appeler plusieurs procédures en une seule demande. Par exemple, créez un utilisateur, ajoutez-lui un avatar et, dans la même demande, signez-le sur certains sujets. Une seule demande, et combien de bien!
En effet, si vous n'avez qu'un seul nœud backend, cela vous semblera plus rapide avec une requête batch. Parce que trois demandes REST nécessiteront trois fois plus de ressources à partir d'un nœud pour établir des connexions.
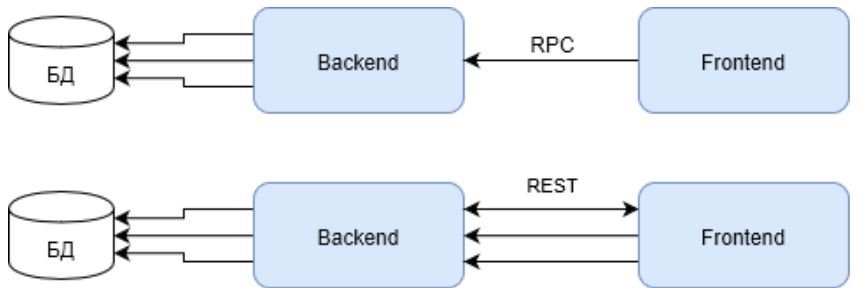
Veuillez noter que la première demande dans le cas de REST doit renvoyer l'ID utilisateur pour les demandes suivantes. Ce qui affecte également négativement le résultat global.
Mais de telles infrastructures peuvent être trouvées, peut-être, dans des solutions internes et Enterprise. En dernier recours, dans les petits projets WEB. Mais les solutions WEB à part entière, et également appelées HighLoad, ne devraient pas être construites comme ça. Leur infrastructure doit répondre aux critères de haute disponibilité et de charge de travail. Et l'image change.
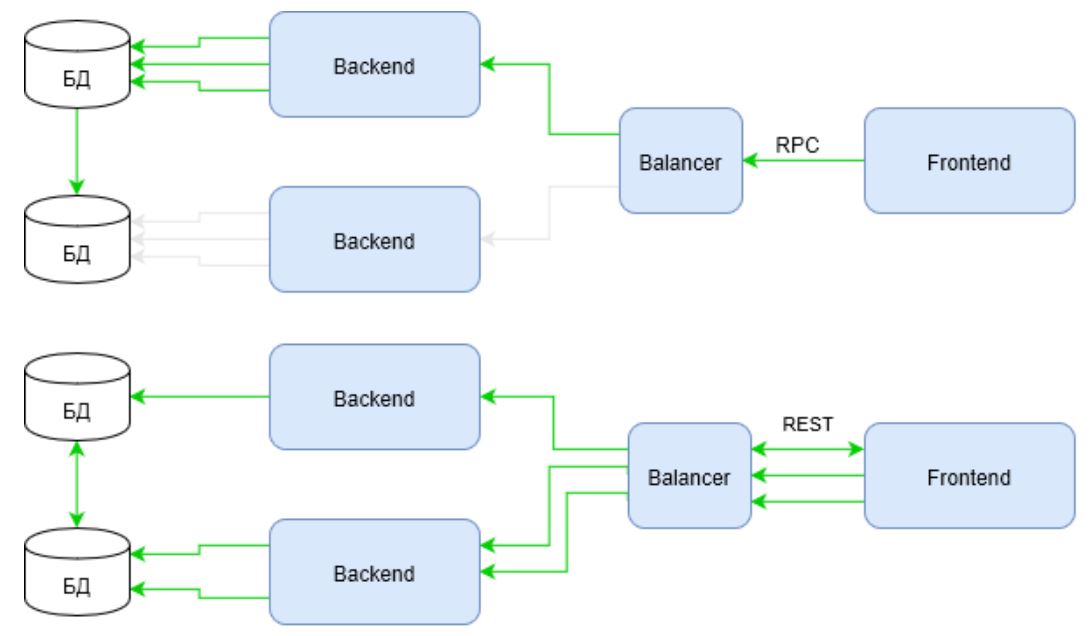
Le vert indique les canaux d'activité d'infrastructure dans le même scénario. Remarquez comment RPC se comporte maintenant. La demande n'utilise l'infrastructure qu'une seule épaule de l'équilibreur au serveur principal. Alors que REST perd toujours dans la première demande, mais compense le temps perdu en utilisant toute l'infrastructure.
Il suffit d'entrer dans le script non pas deux demandes d'enrichissement, mais, disons, cinq ou dix ... et la réponse à la question «qui gagne maintenant?» Ne devient pas évidente.
Je propose d'étudier encore plus le problème. Le diagramme montre comment les canaux d'infrastructure sont utilisés, mais l'infrastructure n'est pas limitée aux canaux. Les caches constituent un élément important d'une infrastructure fortement chargée. Prenons maintenant un artefact utilisateur. Plusieurs fois. Dites 32 fois.
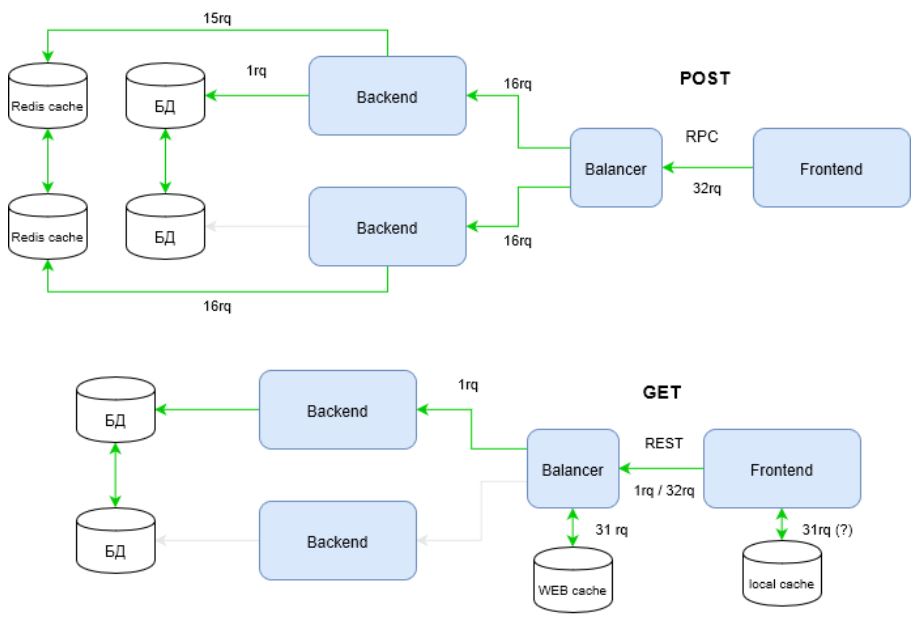
Découvrez comment l'infrastructure du RPC s'est visiblement «rétablie» pour répondre aux exigences d'une charge élevée. Le fait est que REST utilise toute la puissance du protocole HTTP, contrairement à RPC. Dans le diagramme ci-dessus, cette puissance est réalisée par la méthode de demande - GET.
Les méthodes HTTP, entre autres, ont des stratégies de mise en cache. Vous pouvez les connaître dans la documentation HTTP . Pour RPC, des requêtes POST qui ne sont pas considérées comme idempotentes sont utilisées, c'est-à-dire que la répétition répétée des mêmes requêtes POST peut retourner des résultats différents (par exemple, après l'envoi de chaque commentaire, une autre copie de ce commentaire apparaîtra) ( source ).
Par conséquent, les RPC ne sont pas en mesure d'utiliser efficacement les caches d'infrastructure. Cela conduit au fait que vous devez «importer» des caches logiciels. Le diagramme montre Redis dans ce rôle. Le cache virtuel, à son tour, nécessite pour le développeur une couche de code supplémentaire et des changements importants dans l'architecture.
Calculons maintenant combien de demandes "ont donné naissance" à REST et RPC dans l'infrastructure considérée?
[*] dans le meilleur des cas (si le cache local est utilisé) 1 requête (une!), dans les 32 pires requêtes entrantes.
Par rapport au premier schéma, la différence est frappante. La victoire au REST est maintenant apparente. Mais je propose de ne pas en rester là. L'infrastructure développée comprend CDN. Souvent, il résout également le problème de la lutte contre les attaques DDoS et DoS. Nous obtenons:

Ici pour RPC, tout devient très déplorable. RPC n'est tout simplement pas en mesure de déléguer le travail avec le chargement CDN. On ne peut compter que sur des systèmes pour contrer les attaques.
Est-il possible de mettre fin à cela? Et encore une fois, non. Les méthodes HTTP, comme mentionné ci-dessus, ont leur propre «magie». Et pour cause, la méthode GET est totalement utilisée sur Internet. Veuillez noter que cette méthode est capable d'accéder à une partie du contenu, est capable de définir des conditions qui peuvent interpréter les éléments d'infrastructure avant de transférer le contrôle à votre code, etc. Tout cela vous permet de créer des infrastructures flexibles et gérables qui peuvent digérer de très gros flux de demandes. Et dans RPC, cette méthode ... est ignorée.
Alors pourquoi le mythe est-il si persistant que les requêtes par lots (RPC) sont plus rapides? Personnellement, il me semble que la plupart des projets n'atteignent tout simplement pas un tel niveau de développement lorsque REST est en mesure de montrer sa force. De plus, dans les petits projets, il est plus susceptible de montrer sa faiblesse.
Le choix de REST ou RPC n'est pas un choix volontaire d'un individu dans le projet. Ce choix doit répondre aux exigences du projet. Si le projet est capable d'extraire de REST tout ce qu'il peut vraiment, et c'est vraiment nécessaire, alors REST sera un excellent choix.
Mais si pour obtenir tous les bénéfices REST, vous devrez embaucher des développeurs pour faire évoluer rapidement l'infrastructure, des administrateurs pour gérer l'infrastructure, un architecte pour concevoir toutes les couches du service WEB ... et le projet vendra trois packs de margarine par jour ... I arrêterait sur RPC depuis ce protocole est plus utilitaire. Il ne nécessite pas une connaissance approfondie du fonctionnement des caches et de l'infrastructure, mais concentre le développeur sur des appels simples et compréhensibles aux procédures nécessaires. L'entreprise sera ravie.
Les demandes RPC sont plus fiables car elles peuvent exécuter des demandes par lots en une seule transaction
Cette propriété de RPC est un avantage certain, car facile à maintenir la base de données dans un état cohérent. Mais avec REST, tout est plus compliqué. Les demandes peuvent arriver de manière incohérente sur différents nœuds principaux.
Cet «inconvénient» de REST est le revers de ses avantages décrits ci-dessus - la capacité d'utiliser efficacement toutes les ressources de l'infrastructure. Si l'infrastructure est mal conçue, et encore plus si l'architecture du projet et la base de données en particulier sont mal conçues, alors c'est vraiment une grosse douleur.
Mais les demandes par lots sont-elles aussi fiables qu'elles le paraissent? Regardons le cas: créer un utilisateur, enrichir son profil avec une description et lui envoyer un SMS avec un secret pour terminer l'enregistrement. C'est-à-dire trois appels en une seule demande groupée.
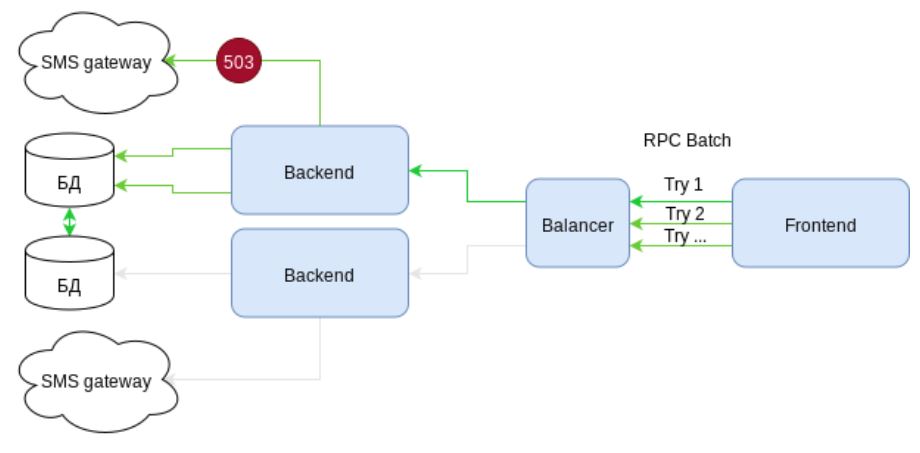
Prenons le schéma. Il présente l'infrastructure avec des éléments de haute disponibilité. Il existe deux canaux de communication indépendants avec des passerelles SMS. Mais ... que voyons-nous? Lors de l'envoi de SMS, l'erreur 503 se produit - le service est temporairement indisponible. Parce que l'envoi de SMS est conditionné dans une demande par lots, puis la demande entière doit être annulée. Les actions dans le SGBD sont annulées. Le client reçoit une erreur.
La prochaine tentative est une loterie. Soit la demande va de nouveau au même nœud et renvoie une erreur, soit vous avez de la chance et elle sera exécutée. Mais l'essentiel est qu'au moins une fois que notre infrastructure a déjà fonctionné en vain. Il y avait une charge, mais pas de profit.
Eh bien, imaginons que nous avons tendu (!) Et pensé à l'option où la demande pourrait être partiellement terminée avec succès. Et le reste, nous essaierons à nouveau de remplir après un certain intervalle de temps (lequel? Décide du front?). Mais la loterie est restée. Une demande d'envoi d'un SMS avec une probabilité de 50/50 échouera à nouveau.
D'accord, côté client, le service ne semble pas aussi fiable que nous le souhaiterions ... mais qu'en est-il de REST?

REST utilise à nouveau la magie HTTP, mais maintenant avec des codes de réponse. Si une erreur 503 se produit sur la passerelle SMS, le backend diffuse cette erreur à l'équilibreur. L'équilibreur recevant cette erreur et sans rompre la connexion avec le client envoie une demande à un autre nœud qui traite correctement la demande. C'est-à-dire le client obtient le résultat escompté et l'infrastructure confirme son rang élevé de «très accessible». L'utilisateur est content.
Et encore une fois, ce n'est pas tout. L'équilibreur n'a pas simplement reçu le code de réponse 503. Il est conseillé de fournir ce code avec l'en-tête "Réessayer après" lors de la réponse. L'en-tête indique clairement à l'équilibreur que vous ne devez pas perturber ce nœud sur cette route pendant une durée spécifiée. Et les SMS suivants envoyant des demandes sera envoyé immédiatement à un nœud qui n'a aucun problème avec la passerelle SMS.
Comme nous pouvons le voir, la fiabilité de JSON-RPC est surévaluée. En effet, il est plus facile d'organiser la cohérence de la base de données. Mais la victime, dans ce cas, sera la fiabilité du système dans son ensemble.
La conclusion est largement similaire à la précédente. Lorsque l'infrastructure est simple, l'évidence de JSON-RPC est sans aucun doute son plus. Si un projet implique une haute disponibilité avec une charge élevée, REST ressemble à une solution plus précise, quoique plus complexe.
Seuil d'entrée REST en dessous
Je pense que l'analyse ci-dessus, démystifiant les stéréotypes établis sur le RPC, a clairement montré que le seuil d'entrée dans le REST est sans aucun doute plus élevé que dans le RPC. Cela est dû à la nécessité d'une compréhension approfondie de HTTP, ainsi qu'à la nécessité d'avoir une connaissance suffisante des éléments d'infrastructure existants qui peuvent et doivent être utilisés dans les projets WEB.
Alors pourquoi beaucoup de gens pensent que REST sera plus facile? Mon opinion personnelle est que cette apparente simplicité vient du REST qui se manifeste. C'est-à-dire REST n'est pas un protocole, mais un concept ... REST n'a pas de standard, il y a quelques recommandations ... REST n'est pas plus compliqué que HTTP. La liberté et l'anarchie apparentes attirent les «artistes libres».
Sans aucun doute, REST n'est pas plus compliqué que HTTP. Mais HTTP lui-même est un protocole bien conçu qui a fait ses preuves depuis des décennies. S'il n'y a pas de compréhension approfondie de HTTP lui-même, alors REST ne peut pas être jugé.
Mais à propos de RPC - vous le pouvez. Il suffit de prendre sa spécification. Avez-vous donc besoin d'un JSON-RPC stupide ? Ou est-ce un REST rusé? Ça dépend de vous.
J'espère sincèrement que je n'ai pas perdu votre temps en vain.