 Le diagramme de l'ordinateur CS-1 montre que la plupart sont dédiés à l'alimentation et au refroidissement du WSE (Engine-on-plate) Wafer Scale Engine géant. Photo: Cerebras Systems
Le diagramme de l'ordinateur CS-1 montre que la plupart sont dédiés à l'alimentation et au refroidissement du WSE (Engine-on-plate) Wafer Scale Engine géant. Photo: Cerebras SystemsEn août 2019, Cerebras Systems et son partenaire de fabrication TSMC ont annoncé la
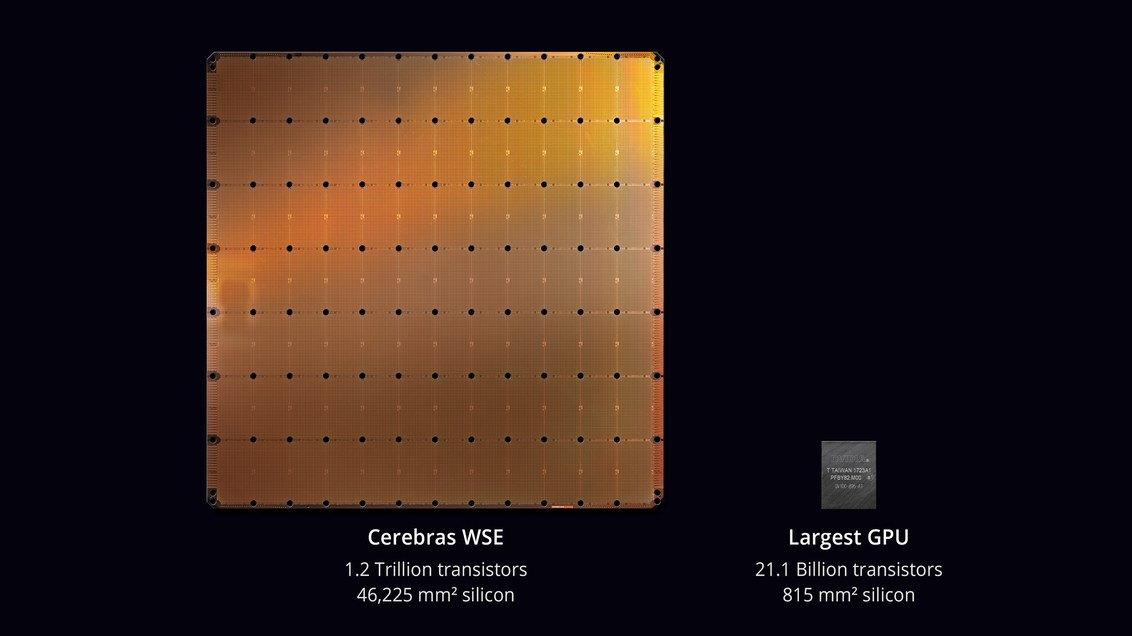
plus grande puce de l'histoire de la technologie informatique . Avec une surface de 46 225 mm² et 1,2 billion de transistors, la puce Wafer Scale Engine (WSE) est environ 56,7 fois plus grande que le plus grand GPU (21,1 milliards de transistors, 815 mm²).
Les sceptiques ont déclaré que le développement d'un processeur n'est pas la tâche la plus difficile. Mais voici comment cela fonctionnera dans un vrai ordinateur? Quel est le pourcentage de travail défectueux? Quelle puissance et quel refroidissement seront nécessaires? Combien coûtera une telle machine?
Il semble que les ingénieurs de Cerebras Systems et TSMC ont pu résoudre ces problèmes. Le 18 novembre 2019, lors de la conférence
Supercomputing 2019 , ils ont officiellement dévoilé le
CS-1 , "l'ordinateur le plus rapide au monde pour l'informatique dans le domaine de l'apprentissage automatique et de l'intelligence artificielle".
Les premiers exemplaires de CS-1 ont déjà été envoyés aux clients. L'un d'eux est installé au Argonne National Laboratory du US Department of Energy, celui dans lequel va commencer l'assemblage du supercalculateur le plus puissant des États-Unis à partir de
modules Aurora sur la nouvelle architecture GPU Intel . Un autre client était le Livermore National Laboratory.
Le processeur avec 400 000 cœurs est conçu pour les centres de données pour le traitement de l'informatique dans le domaine de l'apprentissage automatique et de l'intelligence artificielle. Cerebras affirme que l'ordinateur entraîne les systèmes d'IA par ordre de grandeur plus efficacement que l'équipement existant. La performance CS-1 équivaut à «des centaines de serveurs basés sur GPU» consommant des centaines de kilowatts. Dans le même temps, il n'occupe que 15 unités dans le rack de serveur et consomme environ 17 kW.
 Processeur WSE. Photo: Cerebras Systems
Processeur WSE. Photo: Cerebras SystemsAndrew Feldman, PDG et co-fondateur de Cerebras Systems, affirme que le CS-1 est "l'ordinateur d'IA le plus rapide au monde". Il l'a comparé aux clusters TPU de Google et a noté que chacun d'eux "prend 10 racks et consomme plus de 100 kilowatts pour fournir un tiers des performances d'une seule installation CS-1".
 Ordinateur CS-1. Photo: Cerebras Systems
Ordinateur CS-1. Photo: Cerebras SystemsL'apprentissage de grands réseaux de neurones peut prendre des semaines sur un ordinateur standard. L'installation d'un CS-1 avec une puce processeur de 400 000 cœurs et 1,2 billion de transistors effectue cette tâche en quelques minutes, voire quelques secondes,
écrit IEEE Spectrum. Cependant, Cerebras n'a pas fourni de résultats de test réels pour tester des déclarations de haute performance telles que les
tests MLPerf . Au lieu de cela, l'entreprise a directement établi des contacts avec des clients potentiels - et a permis de former ses propres modèles de réseaux de neurones sur CS-1.
Cette approche n'est pas inhabituelle, selon les analystes: «Tout le monde gère ses propres modèles qu'ils ont développés pour leur propre entreprise», a déclaré
Karl Freund , analyste en intelligence artificielle chez Moor Insights & Strategies. «C'est la seule chose qui compte pour les clients.»
De nombreuses entreprises développent des puces spécialisées pour l'IA, notamment des représentants traditionnels de l'industrie tels qu'Intel, Qualcomm, ainsi que diverses startups aux États-Unis, au Royaume-Uni et en Chine. Google a développé une puce spécifiquement pour les réseaux de neurones - un processeur tensoriel ou TPU. Plusieurs autres fabricants ont emboîté le pas. Les systèmes d'IA fonctionnent en mode multithread, et le goulot d'étranglement déplace les données entre les puces: "La connexion des puces les ralentit et nécessite beaucoup d'énergie",
explique Subramanian Iyer, professeur à l'Université de Californie à Los Angeles qui se spécialise dans développer des puces pour l'intelligence artificielle. Les fabricants d'équipement explorent de nombreuses options différentes. Certains tentent d'étendre les connexions interprocessus.
Fondée il y a trois ans, la startup Cerebras, qui a reçu plus de 200 millions de dollars de financement en capital-risque, a proposé une nouvelle approche. L'idée est de sauvegarder toutes les données sur une puce géante - et d'accélérer ainsi les calculs.

La plaque de microcircuit entière est divisée en 400 000 sections plus petites (noyaux), étant donné que certaines d'entre elles ne fonctionneront pas. La puce est conçue avec la possibilité de contourner les zones défectueuses. Les noyaux programmables SLAC (Sparse Linear Algebra Cores) sont optimisés pour l'algèbre linéaire, c'est-à-dire pour les calculs dans l'espace vectoriel. La société a également développé une technologie de «récolte clairsemée» pour améliorer les performances de calcul sous des charges de travail éparses (contenant des zéros), telles que le deep learning. Les vecteurs et les matrices dans l'espace vectoriel contiennent généralement beaucoup d'éléments nuls (de 50% à 98%), donc sur les GPU traditionnels, la majeure partie du calcul est gaspillée. En revanche, SLAC pré-filtre les données nulles.
Les communications entre les cœurs sont assurées par le système Swarm avec un débit de 100 pétabits par seconde. Routage matériel, latence mesurée en nanosecondes.
Le coût d'un ordinateur n'est pas appelé. Des experts indépendants estiment que le prix réel dépend du pourcentage de mariage. De plus, les performances de la puce et le nombre de cœurs opérationnels dans des échantillons réels ne sont pas connus de manière fiable.
Logiciels
Cerebras a annoncé quelques détails sur la partie logicielle du système CS-1. Le logiciel permet aux utilisateurs de créer leurs propres modèles d'apprentissage automatique à l'aide de cadres standard tels que
PyTorch et
TensorFlow . Le système distribue ensuite 400 000 cœurs et 18 gigaoctets de mémoire SRAM sur la puce aux couches du réseau neuronal afin que toutes les couches terminent leur travail à peu près en même temps que leurs voisins (tâche d'optimisation). En conséquence, les informations sont traitées par toutes les couches sans délai. Avec un sous-système d'E / S Ethernet 100 Gigabits à 12 ports, le CS-1 peut traiter 1,2 térabits de données par seconde.
La conversion du réseau neuronal source en une représentation exécutable optimisée (représentation intermédiaire de l'algèbre linéaire Cerebras, CLAIR) est effectuée par le compilateur de graphes Cerebras (CGC). Le compilateur alloue des ressources informatiques et de la mémoire pour chaque partie du graphique, puis les compare avec le tableau informatique. Ensuite, le chemin de communication est calculé en fonction de la structure interne de la plaque, propre à chaque réseau.
 Distribution des opérations mathématiques d'un réseau neuronal par cœurs de processeur. Photo : Cerebras
Distribution des opérations mathématiques d'un réseau neuronal par cœurs de processeur. Photo : CerebrasEn raison de l'énorme taille de WSE, toutes les couches d'un réseau de neurones se trouvent simultanément sur celui-ci et fonctionnent en parallèle. Cette approche est unique à WSE - aucun autre appareil n'a suffisamment de mémoire interne pour s'adapter à toutes les couches sur une seule puce à la fois, explique Cerebras. Une telle architecture avec le placement de l'ensemble du réseau neuronal sur une puce offre d'énormes avantages en raison de son débit élevé et de sa faible latence.
Le logiciel peut effectuer la tâche d'optimisation pour plusieurs ordinateurs, permettant au cluster d'ordinateurs d'agir comme une seule grande machine. Un cluster de 32 ordinateurs CS-1 affiche une augmentation des performances d'environ 32 fois, ce qui indique une très bonne évolutivité. Feldman dit que cela est différent des clusters basés sur GPU: «Aujourd'hui, lorsque vous créez un cluster de GPU, il ne se comporte pas comme une grosse machine. Vous obtenez beaucoup de petites voitures. "
Le
communiqué de presse indique que le Laboratoire national d'Argonne travaille avec Cerebras depuis deux ans: "En déployant CS-1, nous avons considérablement augmenté la vitesse de formation des réseaux de neurones, ce qui nous a permis d'augmenter la productivité de nos recherches et d'obtenir un succès significatif."
L'une des premières charges pour CS-1 sera une
simulation de réseau neuronal d'une collision de trous noirs et d'ondes gravitationnelles, qui sont créées à la suite de cette collision. La version précédente de cette tâche fonctionnait sur 1024 des 4392 nœuds du supercalculateur
Theta .