 D'après mes performances à Highload ++ et DataFest Minsk 2019
D'après mes performances à Highload ++ et DataFest Minsk 2019Pour beaucoup, le courrier d'aujourd'hui fait partie intégrante de la vie en ligne. Avec son aide, nous menons la correspondance commerciale, stockons toutes sortes d'informations importantes liées aux finances, aux réservations d'hôtel, au paiement et bien plus encore. À la mi-2018, nous avons formulé une stratégie de produit de développement de courrier. Quel devrait être le courrier moderne?
Le courrier doit être
intelligent , c'est-à-dire aider les utilisateurs à naviguer dans la quantité croissante d'informations: filtrer, structurer et les fournir de la manière la plus pratique. Cela devrait être
utile , permettant directement dans la boîte aux lettres de résoudre divers problèmes, par exemple, payer des amendes (une fonction que j'utilise malheureusement). Et en même temps, bien sûr, le courrier doit fournir une protection des informations en supprimant le spam et en protégeant contre les hacks, c'est-à-dire en
toute sécurité .
Ces domaines déterminent un certain nombre de tâches clés, dont beaucoup peuvent être résolues efficacement à l'aide de l'apprentissage automatique. Voici des exemples de fonctionnalités existantes développées dans le cadre de la stratégie - une pour chaque direction.
- Réponse intelligente . Il y a une fonction de réponse intelligente dans l'e-mail. Le réseau de neurones analyse le texte de la lettre, en comprend le sens et le but, et propose par conséquent les trois options de réponse les plus appropriées: positive, négative et neutre. Cela permet de gagner beaucoup de temps lors de la réponse aux lettres, et répond également souvent non standard et amusant pour vous-même.
- Regroupement des lettres liées aux commandes dans les boutiques en ligne. Nous effectuons souvent des achats sur Internet et, en règle générale, les magasins peuvent envoyer plusieurs lettres pour chaque commande. Par exemple, sur AliExpress, le plus grand service, il y a beaucoup de lettres pour une commande, et nous avons pensé que dans le cas du terminal, leur nombre peut atteindre 29. Par conséquent, en utilisant le modèle de reconnaissance d'entité nommée, nous sélectionnons le numéro de commande et d'autres informations dans le texte et le groupe toutes les lettres dans un seul fil. Nous montrons également les informations de base sur la commande dans une boîte séparée, ce qui facilite le travail avec ce type de lettres.
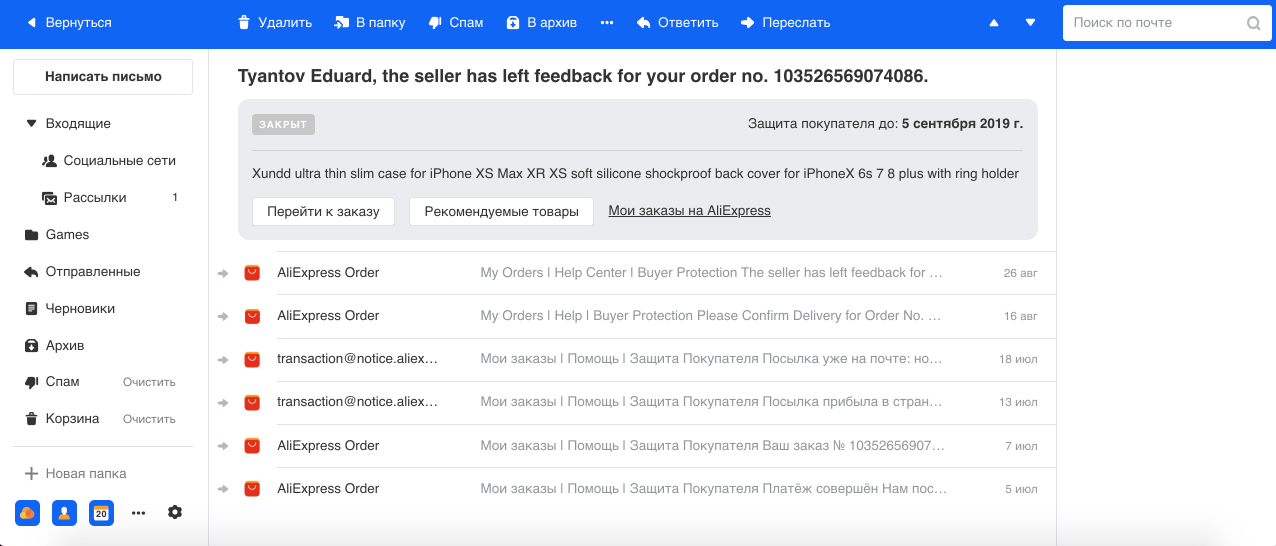
- Antiphishing . Le phishing est un type de courrier électronique frauduleux particulièrement dangereux à l'aide duquel les attaquants tentent d'obtenir des informations financières (y compris les cartes bancaires des utilisateurs) et des connexions. Ces lettres imitent les vraies envoyées par le service, y compris visuellement. Par conséquent, avec l'aide de Computer Vision, nous reconnaissons les logos et le style des lettres des grandes entreprises (par exemple, Mail.ru, Sberbank, Alpha) et en tenons compte avec le texte et les autres signes dans nos classificateurs de spam et de phishing.
Apprentissage automatique
Un peu sur l'apprentissage automatique dans le courrier en général. Le courrier est un système très chargé: sur nos serveurs, une moyenne de 1,5 milliard de lettres par jour passe à 30 millions d'utilisateurs DAU. Servir toutes les fonctions et caractéristiques nécessaires d'environ 30 systèmes d'apprentissage automatique.
Chaque lettre passe par un convoyeur de classification complet. D'abord, nous supprimons le spam et laissons de bons e-mails. Souvent, les utilisateurs ne remarquent pas le fonctionnement de l'anti-spam, car 95 à 99% du spam ne pénètre même pas dans le dossier correspondant. La reconnaissance du spam est une partie très importante de notre système, et la plus difficile, car dans la sphère anti-spam, il y a une adaptation constante entre les systèmes de défense et d'attaque, ce qui constitue un défi d'ingénierie continu pour notre équipe.
Ensuite, nous séparons les lettres des personnes et des robots. Les lettres de personnes sont les plus importantes, donc pour elles, nous fournissons des fonctions comme Smart Reply. Les lettres des robots sont divisées en deux parties: transactionnelles - ce sont des lettres importantes des services, par exemple, la confirmation des achats ou des réservations d'hôtel, les finances et l'information - ce sont la publicité commerciale, les remises.
Nous pensons que les lettres transactionnelles ont la même valeur que la correspondance personnelle. Ils doivent être à portée de main, car il est souvent nécessaire de trouver rapidement des informations sur la commande ou la réservation d'un billet, et nous passons du temps à rechercher ces lettres. Par conséquent, pour plus de commodité, nous les divisons automatiquement en six catégories principales: voyages, réservations, finances, billets, inscriptions et enfin, amendes.
Les newsletters sont le groupe le plus important et probablement le moins important qui ne nécessite pas de réaction instantanée, car rien de significatif ne changera dans la vie de l'utilisateur s'il ne lit pas une telle lettre. Dans notre nouvelle interface, nous les regroupons en deux fils: les réseaux sociaux et les newsletters, effaçant ainsi visuellement la boîte aux lettres et ne laissant que les lettres importantes en vue.

Fonctionnement
Un grand nombre de systèmes entraîne de nombreuses difficultés de fonctionnement. Après tout, les modèles se dégradent avec le temps, comme n'importe quel logiciel: les panneaux tombent en panne, les machines tombent en panne, un code roule. De plus, les données changent constamment: de nouvelles sont ajoutées, le modèle de comportement de l'utilisateur est transformé, etc., par conséquent, le modèle sans support approprié fonctionnera de plus en plus mal avec le temps.
Nous ne devons pas oublier que plus l'apprentissage automatique approfondit la vie des utilisateurs, plus leur impact sur l'écosystème est important et, par conséquent, plus les acteurs du marché peuvent obtenir de pertes ou de bénéfices financiers. Par conséquent, dans un nombre croissant de domaines, les joueurs s'adaptent au travail des algorithmes ML (les exemples classiques sont la publicité, la recherche et l'anti-spam déjà mentionnés).
De plus, les tâches d'apprentissage automatique ont une particularité: toute modification du système, bien qu'insignifiante, peut entraîner beaucoup de travail avec le modèle: travailler avec les données, recycler, déployer, ce qui peut prendre des semaines ou des mois. Par conséquent, plus l'environnement dans lequel fonctionnent vos modèles est rapide, plus leur assistance nécessite d'efforts. Une équipe peut créer de nombreux systèmes et en profiter, puis dépenser presque toutes les ressources pour son support, sans avoir la possibilité de faire quelque chose de nouveau. Une fois, nous avons rencontré une telle situation dans une équipe anti-spam. Et ils ont clairement conclu que la maintenance devait être automatisée.
Automatisation
Qu'est-ce qui peut être automatisé? En fait, presque tout. J'ai identifié quatre domaines qui définissent l'infrastructure du machine learning:
- collecte de données;
- formation continue;
- déploiement;
- tests et surveillance.
Si l'environnement est instable et en constante évolution, alors toute l'infrastructure autour du modèle est beaucoup plus importante que le modèle lui-même. C'est peut-être le bon vieux classificateur linéaire, mais si vous appliquez correctement les signes et établissez une bonne rétroaction des utilisateurs, cela fonctionnera beaucoup mieux que les modèles de pointe avec toutes les cloches et les sifflets.
Boucle de rétroaction
Ce cycle combine la collecte de données, la formation continue et le déploiement - en fait, tout le cycle de mise à jour du modèle. Pourquoi est-ce important? Regardez le calendrier d'inscription dans l'e-mail:

Le développeur de l'apprentissage automatique a introduit un modèle antibot qui empêche les bots de s'enregistrer dans l'e-mail. Le graphique tombe à une valeur où seuls les utilisateurs réels restent. Tout est super! Mais quatre heures s'écoulent, les botvods resserrent leurs scripts, et tout revient à la case départ. Dans cette implémentation, le développeur a passé un mois à ajouter des fonctionnalités et un modèle de formation, mais le spammeur a pu s'adapter en quatre heures.
Pour ne pas être si douloureusement douloureux et ne pas avoir à tout refaire plus tard, nous devons d'abord penser à quoi ressemblera la boucle de rétroaction et à ce que nous ferons si l'environnement change. Commençons par collecter des données - c'est le carburant de nos algorithmes.
Collecte de données
Il est clair que les réseaux de neurones modernes, plus il y a de données, mieux c'est, et ils génèrent en fait des utilisateurs du produit. Les utilisateurs peuvent nous aider en balisant les données, mais vous ne pouvez pas en abuser, car à un moment donné, les utilisateurs seront fatigués de terminer vos modèles et ils passeront à un autre produit.
L'une des erreurs les plus courantes (je fais ici une référence à Andrew Ng) est que l'orientation vers les métriques sur l'ensemble de données de test est trop forte, et non vers les commentaires de l'utilisateur, qui est en fait la principale mesure de la qualité du travail, car nous créons un produit pour l'utilisateur. Si l'utilisateur ne comprend pas ou n'aime pas le travail du modèle, alors tout est périssable.
Par conséquent, l'utilisateur devrait toujours pouvoir voter, devrait lui donner un outil de rétroaction. Si nous pensons qu'une lettre liée à la finance est arrivée dans la boîte, nous devons la marquer «finance» et dessiner un bouton sur lequel l'utilisateur peut cliquer et dire que ce n'est pas de la finance.
Qualité des commentaires
Parlons de la qualité des commentaires des utilisateurs. Premièrement, vous et l'utilisateur pouvez mettre différentes significations dans un même concept. Par exemple, vous et les chefs de produit pensez que «finance» est une lettre de la banque, et l'utilisateur pense que la lettre de ma grand-mère sur la retraite fait également référence à la finance. Deuxièmement, il y a des utilisateurs qui aiment sans réfléchir appuyer sur des boutons sans aucune logique. Troisièmement, l'utilisateur peut se tromper profondément dans ses conclusions. Un exemple frappant de notre pratique est l'introduction du classificateur de
spam nigérian , un type de spam très amusant, lorsque l'utilisateur est invité à collecter plusieurs millions de dollars auprès d'un parent éloigné soudainement trouvé en Afrique. Après avoir introduit ce classificateur, nous avons vérifié les clics «Pas de spam» sur ces lettres, et il s'est avéré que 80% d'entre elles sont du spam nigérian juteux, ce qui suggère que les utilisateurs peuvent faire extrêmement confiance.
Et n'oublions pas que non seulement les gens peuvent pousser les boutons, mais toutes sortes de bots qui se font passer pour un navigateur. La rétroaction brute n'est donc pas bonne pour l'apprentissage. Que faire de ces informations?
Nous utilisons deux approches:
- Commentaires du ML correspondant . Par exemple, nous avons un système antibot en ligne qui, comme je l'ai mentionné, prend une décision rapide en fonction d'un nombre limité de signes. Et il existe un deuxième système lent qui fonctionne ex post. Elle a plus de données sur l'utilisateur, sur son comportement, etc. En conséquence, la décision la plus équilibrée est prise, respectivement, elle a une précision et une exhaustivité plus élevées. Vous pouvez diriger la différence dans le travail de ces systèmes dans le premier comme données pour la formation. Ainsi, un système plus simple tentera toujours de se rapprocher d'une performance plus complexe.
- Classification des clics . Vous pouvez simplement classer chaque clic de l'utilisateur, évaluer sa validité et sa capacité d'utilisation. Nous le faisons dans le courrier anti-spam en utilisant les attributs de l'utilisateur, son historique, les attributs de l'expéditeur, le texte lui-même et le résultat des classificateurs. En conséquence, nous obtenons un système automatique qui valide les commentaires des utilisateurs. Et comme il est nécessaire de le former beaucoup moins fréquemment, son travail peut devenir le principal pour tous les autres systèmes. La précision est la principale priorité de ce modèle, car la formation d'un modèle sur des données inexactes est lourde de conséquences.
Pendant que nous nettoyons les données et recyclons nos systèmes ML, nous ne devons pas oublier les utilisateurs, car pour nous des milliers, des millions d'erreurs sur le graphique sont des statistiques, et pour un utilisateur, chaque bug est une tragédie. En plus du fait que l'utilisateur doit en quelque sorte vivre avec votre erreur dans le produit, il s'attend, après les commentaires, à l'exclusion d'une situation similaire à l'avenir. Par conséquent, vous devez toujours donner aux utilisateurs non seulement la possibilité de voter, mais également corriger le comportement des systèmes ML, en créant, par exemple, une heuristique personnelle pour chaque clic de rétroaction, dans le cas du courrier, il peut être possible de filtrer ces messages par expéditeur et en-tête pour cet utilisateur.
Vous devez également béquiller le modèle sur la base de certains rapports ou appels à l'assistance en mode semi-automatique ou manuel, afin que les autres utilisateurs ne souffrent pas non plus de problèmes similaires.
Heuristique pour l'apprentissage
Il y a deux problèmes avec ces heuristiques et ces béquilles. La première est que le nombre toujours croissant de béquilles est difficile à entretenir, sans parler de leur qualité et de leurs performances sur de longues distances. Le deuxième problème est que l'erreur n'est peut-être pas fréquentielle, et quelques clics pour recycler le modèle ne suffiront pas. Il semblerait que ces deux effets non liés peuvent être sensiblement nivelés si l'approche suivante est appliquée.
- Créez une béquille temporaire.
- Nous en dirigeons les données vers le modèle; elles sont régulièrement récupérées, y compris les données reçues. Ici, bien sûr, il est important que l'heuristique ait une grande précision afin de ne pas réduire la qualité des données dans l'ensemble d'apprentissage.
- Ensuite, nous suspendons la surveillance du fonctionnement de la béquille, et si après un certain temps la béquille ne fonctionne plus et est complètement couverte par le modèle, vous pouvez la retirer en toute sécurité. Maintenant, ce problème est peu susceptible de se reproduire.
L'armée de béquilles est donc très utile. L'essentiel est que leur service soit urgent et non permanent.
Formation continue
La reconversion est le processus consistant à ajouter de nouvelles données obtenues à la suite des commentaires des utilisateurs ou d'autres systèmes et à former le modèle existant à leur sujet. Il peut y avoir plusieurs problèmes de recyclage:
- Un modèle peut tout simplement ne pas soutenir la poursuite des études et apprendre uniquement à partir de zéro.
- Nulle part dans le livre de la nature il n'est écrit que la formation continue améliorera certainement la qualité du travail en production. Souvent, cela se produit au contraire, c'est-à-dire que seule la détérioration est possible.
- Les changements peuvent être imprévisibles. C'est un point assez subtil que nous avons identifié pour nous-mêmes. Même si le nouveau modèle du test A / B montre des résultats similaires par rapport au modèle actuel, cela ne signifie pas du tout qu'il fonctionnera de manière identique. Leur travail peut différer d'un pour cent, ce qui peut entraîner de nouvelles erreurs ou renvoyer des anciennes déjà corrigées. Les utilisateurs et nous savons déjà comment vivre avec les erreurs actuelles, et lorsqu'un grand nombre de nouvelles erreurs se produisent, l'utilisateur peut également ne pas comprendre ce qui se passe, car il s'attend à un comportement prévisible.
Par conséquent, la chose la plus importante dans le recyclage est garantie d'améliorer le modèle, ou du moins de ne pas l'aggraver.
La première chose qui me vient à l'esprit lorsque nous parlons de formation continue est l'approche Active Learning. Qu'est-ce que cela signifie? Par exemple, le classificateur détermine si la lettre se rapporte à la finance, et autour de sa frontière de prise de décision, nous ajoutons une sélection d'exemples balisés. Cela fonctionne bien, par exemple, dans la publicité, où il y a beaucoup de commentaires et où vous pouvez former le modèle en ligne. Et s'il y a peu de rétroaction, alors nous obtenons un échantillon fortement biaisé par rapport à la production de la distribution des données, sur la base duquel il est impossible d'évaluer le comportement du modèle pendant le fonctionnement.
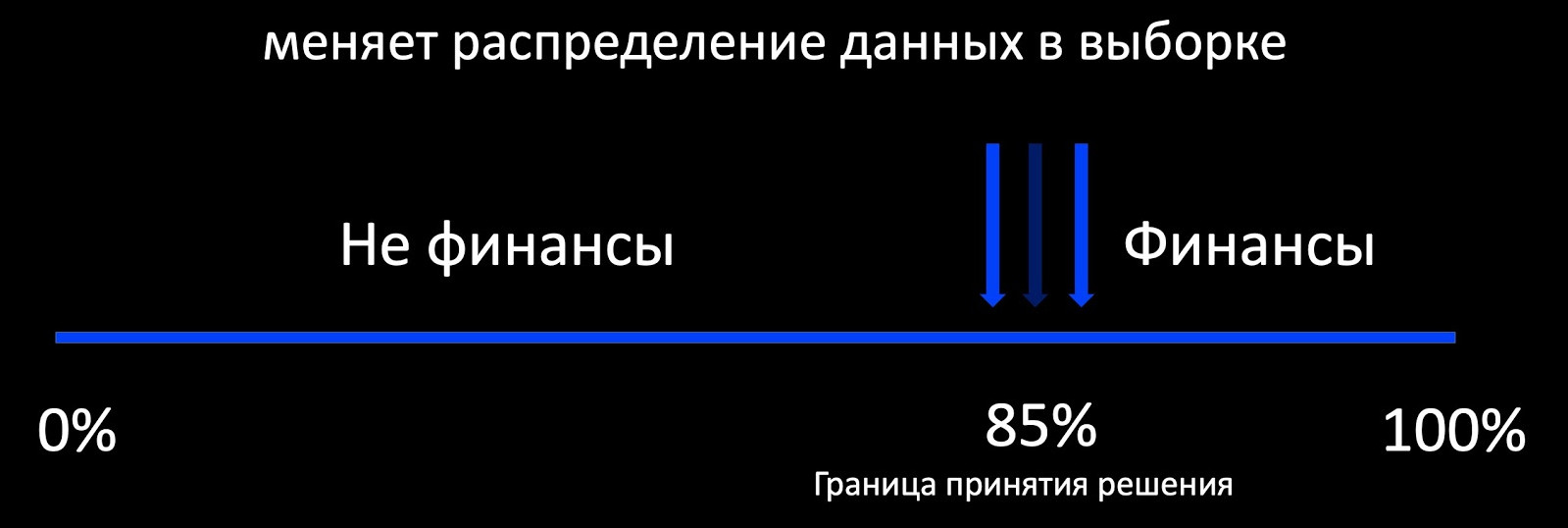
En fait, notre objectif est de conserver les anciens modèles, les modèles déjà connus et d'en acquérir de nouveaux. Ici, la continuité est importante. Le modèle, que nous avons souvent déployé avec beaucoup de difficulté, fonctionne déjà, nous pouvons donc nous concentrer sur ses performances.
Dans l'e-mail, différents modèles sont utilisés: arbres, réseaux linéaires, neuronaux. Pour chacun, nous créons notre propre algorithme de recyclage. Dans le processus de recyclage, nous obtenons non seulement de nouvelles données, mais souvent de nouvelles fonctionnalités que nous prendrons en compte dans tous les algorithmes ci-dessous.
Modèles linéaires
Disons que nous avons une régression logistique. Nous composons le modèle de perte à partir des composants suivants:
- LogLoss sur les nouvelles données;
- nous régularisons le poids des nouveaux panneaux (nous ne touchons pas aux anciens);
- nous apprenons d'anciennes données afin de conserver les anciens schémas;
- et, peut-être, le plus important: nous attachons la régularisation harmonique, qui garantit un léger changement de poids par rapport à l'ancien modèle selon la norme.
Étant donné que chaque composant de perte a des coefficients, nous pouvons choisir les valeurs optimales pour notre tâche pour la validation croisée ou en fonction des exigences du produit.

Les arbres
Passons aux arbres de décision. Nous avons filmé l'algorithme de recyclage des arbres suivant:
- Une forêt de 100-300 arbres travaille sur le prod, qui a été formé sur l'ancien ensemble de données.
- À la fin, nous supprimons M = 5 pièces et en ajoutons 2M = 10 nouvelles, entraînées sur l'ensemble des données, mais avec un poids élevé à partir des nouvelles données, ce qui garantit naturellement un changement incrémentiel dans le modèle.
De toute évidence, au fil du temps, le nombre d'arbres augmente de manière significative, et ils doivent être périodiquement réduits afin de s'adapter aux horaires. Pour ce faire, nous utilisons la distillation désormais omniprésente des connaissances (KD). Brièvement sur le principe de son travail.
- Nous avons le modèle «complexe» actuel. Nous le commençons sur l'ensemble de données d'apprentissage et obtenons la distribution de probabilité des classes en sortie.
- Ensuite, nous enseignons au modèle étudiant (un modèle avec moins d'arbres dans ce cas) de répéter les résultats du modèle, en utilisant la distribution des classes comme variable cible.
- Il est important de noter ici que nous n'utilisons aucun balisage d'ensemble de données, et que nous pouvons donc utiliser des données arbitraires. Bien sûr, nous utilisons un échantillon de données du flux de combat comme échantillon d'entraînement pour le modèle étudiant. Ainsi, l'ensemble d'apprentissage nous permet d'assurer la précision du modèle, et un échantillon du flux garantit une performance similaire sur la distribution de la production, compensant le décalage de l'échantillon d'apprentissage.
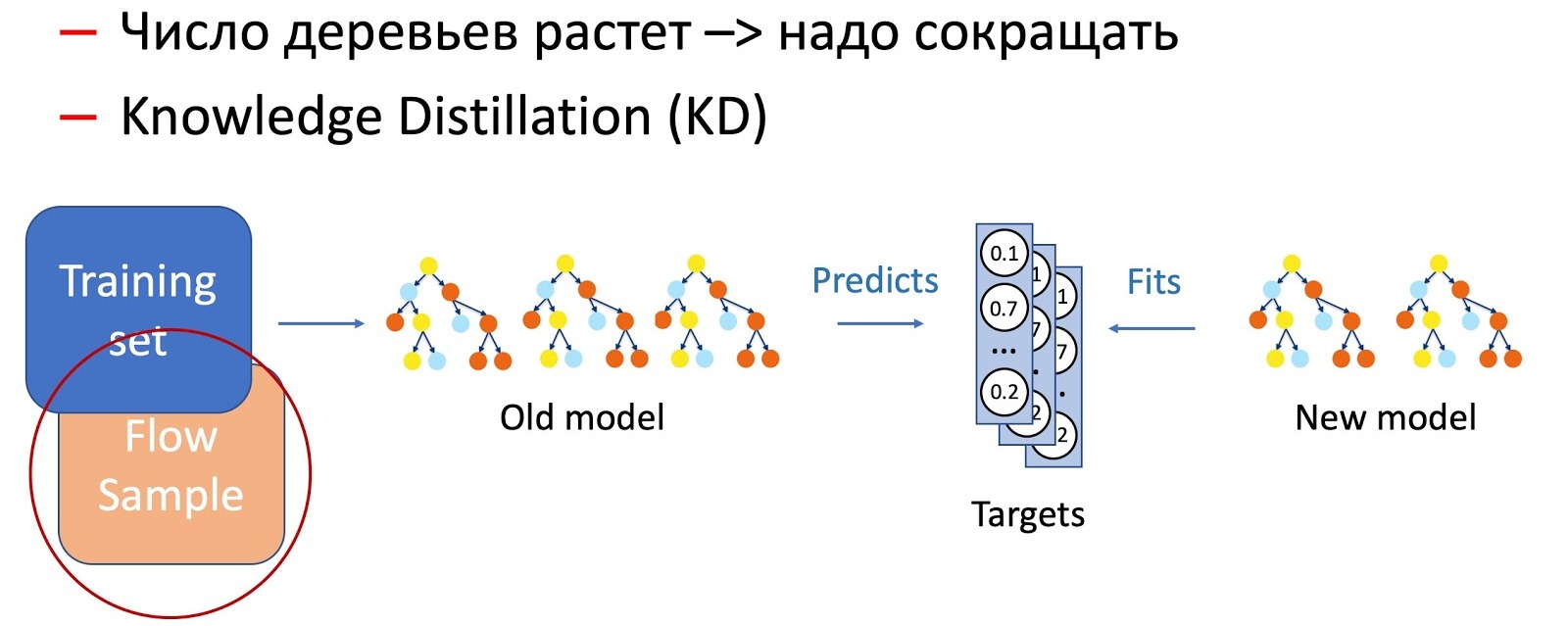
La combinaison de ces deux techniques (ajout d'arbres et réduction périodique de leur nombre grâce à la distillation des connaissances) assure l'introduction de nouveaux schémas et une continuité complète.
Avec l'aide de KD, nous effectuons également la distinction des opérations avec les caractéristiques d'un modèle, par exemple, la suppression des caractéristiques et le travail sur les passes. Dans notre cas, nous avons un certain nombre de fonctionnalités statistiques importantes (par expéditeurs, hachages de texte, URL, etc.) qui sont stockées dans une base de données qui a la propriété de refuser. Le modèle, bien sûr, n'est pas prêt pour un tel développement des événements, car il n'y a pas de situations d'échec dans l'ensemble d'entraînement. Dans de tels cas, nous combinons KD et techniques d'augmentation: lorsque nous nous entraînons pour une partie des données, nous supprimons ou mettons à zéro les signes nécessaires, et nous prenons les étiquettes (sorties du modèle actuel) comme initiales, le modèle étudiant nous apprend à répéter cette distribution.
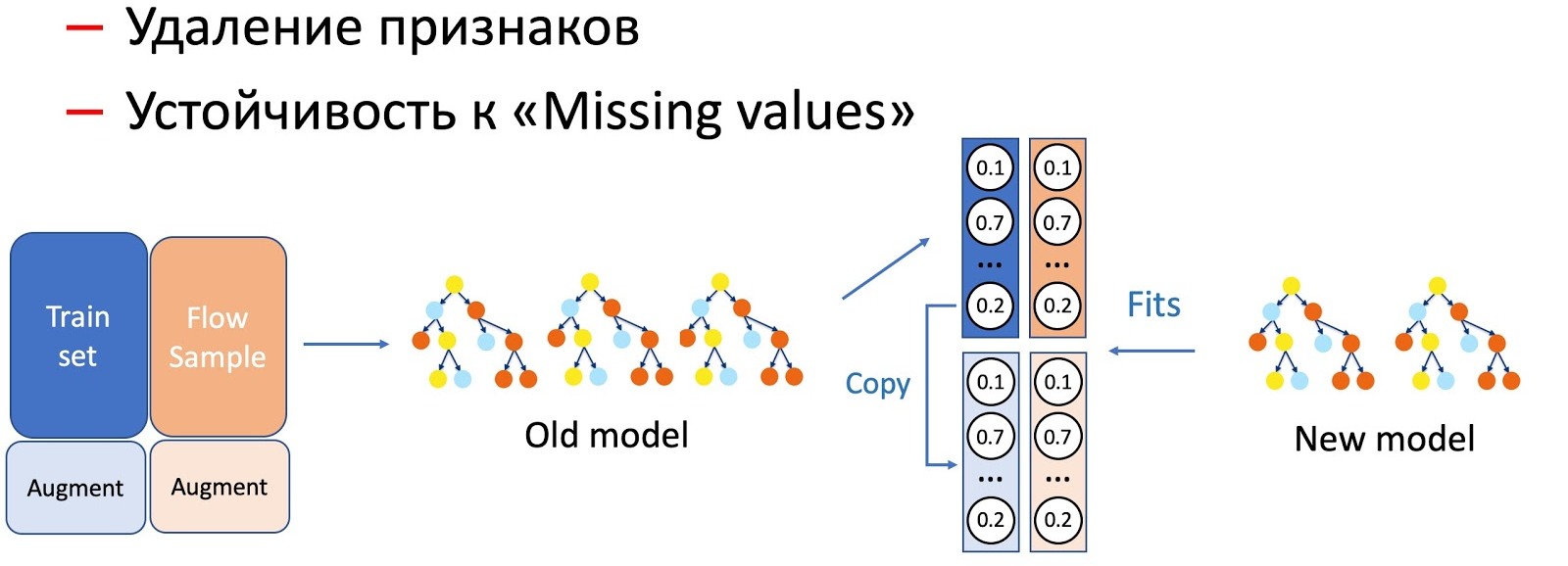
Nous avons remarqué que plus la manipulation des modèles est sérieuse, plus le pourcentage d'écoulement d'échantillon requis est élevé.
Pour supprimer des fonctionnalités, l'opération la plus simple, seule une petite partie du flux est requise, car seules quelques fonctionnalités changent, et le modèle actuel étudié sur le même ensemble - la différence est minime. Pour simplifier le modèle (en réduisant le nombre d'arbres de plusieurs fois), 50 à 50 sont déjà nécessaires. Et omettre des caractéristiques statistiques importantes qui affectent sérieusement les performances du modèle nécessitent encore plus de flux pour équilibrer le travail du nouveau modèle, qui résiste aux omissions, sur tous les types de lettres.
Fasttext
Passons à FastText. Permettez-moi de vous rappeler que la représentation (incorporation) d'un mot consiste en la somme de l'incorporation du mot lui-même et de toutes ses lettres N-grammes, généralement des trigrammes. Étant donné que les trigrammes peuvent être beaucoup, Bucket Hashing est utilisé, c'est-à-dire la conversion de tout l'espace en une certaine table de hachage fixe. En conséquence, la matrice de poids est obtenue par la dimension de la couche intérieure par le nombre de mots + seau.
Au cours de la formation continue, de nouveaux signes apparaissent: mots et trigrammes. Dans la post-formation standard de Facebook, rien de significatif ne se produit. Seuls les anciens poids avec entropie croisée sur les nouvelles données sont recyclés. , , , , . FastText. ( ), - , .

CNN
. CNN , , , . , , . Triplet Loss (
).
Triplet Loss
Triplet Loss. , . , , .

, , . , . , .
- . (Finetuning): , . , — . , v1 v2. .

, , . , , CNN Fast Text . , ( , , ). . , .

. CNN Fast Text , — . Knowledge Distillation.
, . , , .
Déployer
, .
/B-
, , , , - . , , , A/B-. . 5 %, 30 %, 50 % 100 % , . - , , , . 50 % , , .
A/B- . , A/B- ( 6 24 ), . , /B- ( ), A/B- . , , .
, A/B-. , Precision, Recall , . , , (Complexity) . , -, , , A/B-.

A/B-.
&
, , , , , . , — , .
, — . , . , — - , .
, . ( ). - . , , «» . , , . .

. , , . KL- A/B- , .
, . , NER- -, , . !
Résumé
.
- . : , . , — , ML-. , , , .
- . — , -. , .
- Déployer . Les mesures automatiques réduisent considérablement le temps de mise en œuvre des modèles. Suivi des statistiques et répartition de la prise de décision, le nombre de chutes des utilisateurs est obligatoire pour votre bon sommeil et vos jours de repos productifs.
Eh bien, j'espère que ce que vous lirez vous aidera à améliorer vos systèmes ML plus rapidement, à accélérer leur lancement sur le marché et à les rendre plus fiables, réduisant ainsi le stress du travail.