Les processeurs multicœurs sont courants. Tôt ou tard, tout programmeur pratique devra entrer dans le dédale de la programmation multi-thread et rencontrer les "monstres" qui l'habitent. Parlons par où commencer de cette façon et quels outils et approches aideront à sortir victorieux. J'ai fait ce rapport aux futurs participants au
stage à l'
année de Yandex.
- Je m'appelle Seva Minkov. Je travaille au sein du département infrastructure cloud du service recherche. Je m'occupe principalement du backend. J'écris dans différents langages, mais le plus souvent, c'est Java et les langages fonctionnant sur la machine virtuelle Java (JVM).
Notre équipe développe un cloud interne dans lequel presque tous les services Yandex sont lancés - tous deux connus publiquement tels que Search, Mail et Alice, ainsi que divers services internes, machines virtuelles, ainsi que des tâches MapReduce de courte durée et des tâches d'apprentissage automatique.
Notre cloud n'est pas statique: l'entreprise se développe, le nombre de services et les ressources qu'ils consomment augmentent. Et notre équipe est très souvent confrontée aux défis de l'évolutivité et de l'amélioration des performances. Nous y parvenons en utilisant tous les outils disponibles, y compris la mise à l'échelle verticale, c'est-à-dire en accélérant les composants individuels du système jusqu'à la réécriture de certains algorithmes à un seul thread afin qu'ils fonctionnent plus rapidement. Nous effectuons une mise à l'échelle horizontale: écraser le système en petites pièces afin d'obtenir de meilleures performances en ajoutant des serveurs, des processeurs, des cœurs, etc.
Et la programmation multithread nous aide beaucoup dans ce domaine. Nous parlerons de lui aujourd'hui - d’où cela vient-il, pourquoi est-il pertinent; qu'est-ce qu'un modèle de mémoire et comment est-il généralement représenté en Java? Nous aborderons certains aspects pratiques de la façon de tester vos applications et de vérifier leur exactitude.
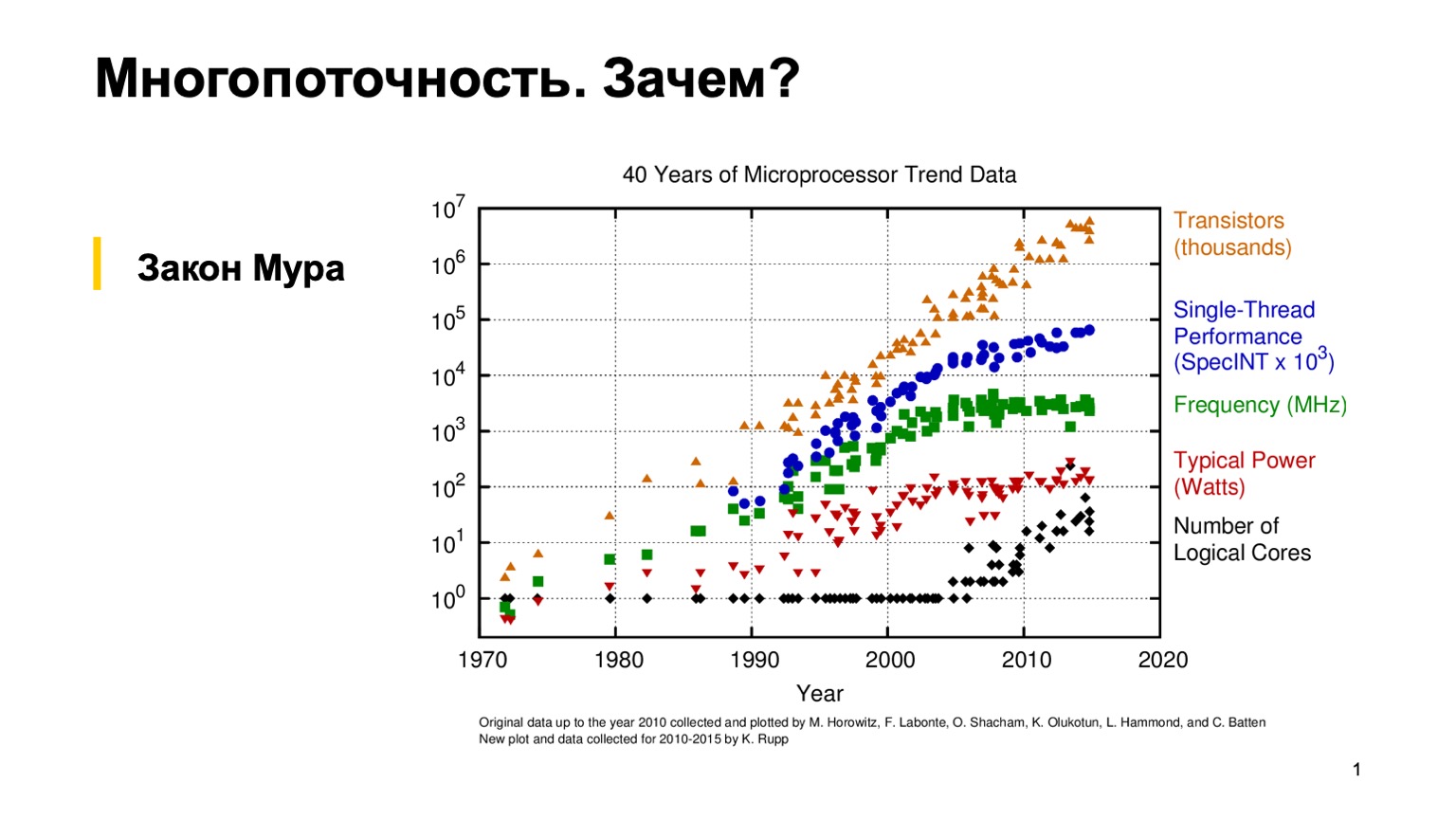
Pour commencer, regardons ce graphique intéressant, qui montre les tendances des caractéristiques des microprocesseurs au cours des 40 dernières années. Il y a environ 10 à 15 ans, lorsque l'herbe était plus verte et que les processeurs étaient à un seul thread, un programmeur ordinaire pouvait une fois écrire un programme à un seul thread correct, puis s'appuyer sur la loi empirique de Moore. Il dit que les processeurs sont deux fois plus rapides tous les deux ans. Comme vous pouvez le constater, vers 2005, pour diverses raisons, les fabricants de microprocesseurs sont passés à une architecture multicœur et ont commencé à augmenter le nombre de cœurs logiques. Et le gain de performances d'un seul cœur a cessé d'obéir à la loi de Moore, et la puissance de traitement d'un cœur a commencé à croître plus lentement. Cela a fait une révolution, et les programmeurs ordinaires ont dû utiliser la programmation parallèle pour utiliser ce gain de performances.
Puisque nous nous entraînons, nous allons essayer d'écrire un simple programme multi-thread et de voir par vous-même comment cela fonctionne.
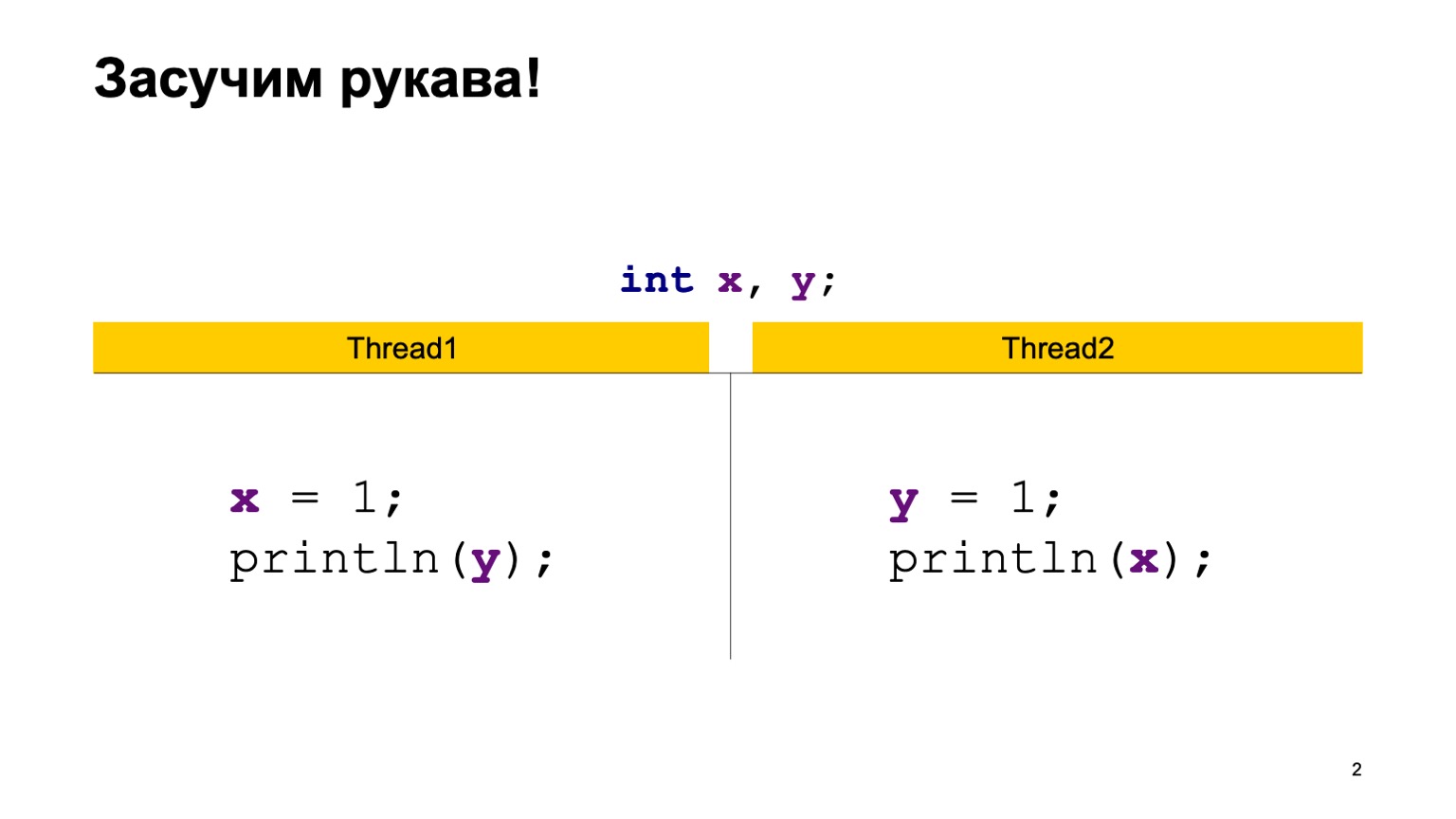
À titre d'exemple, prenons une tâche assez simple de lecture croisée d'enregistrements. Ayons deux variables partagées X et Y, d'abord initialisées avec la valeur par défaut (zéro), et deux flux. Chaque thread écrit dans une variable et en lit une autre. Dans ce cas, Thread1 écrit une unité en X et lit Y. Le deuxième thread fait de même, uniquement à l'envers.
Une implémentation Java simple pourrait ressembler à ceci.

Nous allons écrire la classe ReadWriteTest, elle aura deux variables statiques X et Y. Directement dans la méthode principale, nous construisons deux threads Thread1 et Thread2, donnons à chacun d'entre eux une fonction lambda qui sera exécutée au moment de l'exécution du thread. Mettez-y le code de la diapositive précédente et démarrez deux threads.
L'ordre dans lequel les threads commencent est, dans un sens, imprévisible. Cela dépend de la façon dont le système d'exploitation threads threads. En conséquence, nous pouvons avoir différentes versions. Il semble comprendre comment tout cela fonctionne, nous devrons exécuter ce programme plusieurs fois, puis agréger la sortie et voir à quelle fréquence telle ou telle réponse sera trouvée dans le programme.

Afin de ne pas réinventer la roue, nous pouvons utiliser un outil prêt à l'emploi. Cela s'appelle jcstress, l'utilitaire de tests de stress de concurrence Java qui fait partie du projet OpenJDK.
Cet utilitaire fournit un cadre pour l'écriture de tests de résistance. Dans ce cas, le code de la diapositive précédente est assez facilement réécrit. Tout d'abord, nous accrocherons l'annotation jcstress Test à la classe, ce qui rendra simplement nos scripts de test visibles à l'utilitaire. Nous le marquons également avec la classe State, qui indique que la classe contient des données qui peuvent changer: à la fois en cours de modification et en lecture à partir de différents flux. Nous déclarons deux méthodes, thread1 et thread2, et les marquons avec l'annotation Actor. L'annotation d'acteur signifie que la méthode doit être exécutée dans un thread séparé. jcstress garantit que chacune de ces méthodes sera exécutée dans un thread séparé sur exactement une instance de la classe State. L'ordre dans lequel ils seront lancés n'est pas spécifiquement spécifié. Et le résultat sera écrit dans un objet II_Result montré sur la diapositive. Nous pouvons supposer qu'il s'agit d'un tuple de deux valeurs numériques, qui sont présentées uniquement par la méthode de l'injection de dépendance, dont Cyril a parlé dans un rapport précédent.
Avant de commencer ce test, réfléchissons aux conclusions que les commandes peuvent donner et aux valeurs que nous pouvons ajouter dans r1 et dans r2.

Pour ce faire, nous utilisons le modèle dit d'alternance. D'une manière ou d'une autre, chacune des opérations: lire ou écrire, s'effectue dans un certain ordre. Il suffit de parcourir toutes ces options et de voir quels résultats nous obtiendrons.

Supposons que l'une des variantes possibles des événements soit que le thread un soit complètement exécuté avant le thread deux. Tout d'abord, nous avons ajouté un à X, lu zéro à partir de Y, car il n'y avait aucune entrée. Puis ils en ont écrit un dans Y et en ont lu un dans X, puisque le premier flux avait déjà réussi à le faire.
La première réponse est zéro.

La deuxième variante du développement des événements est exactement le contraire: le flux deux a été exécuté avant le flux un.

En conséquence, nous obtenons un résultat miroir de un zéro.

Il y a environ quatre autres options qui donnent le même résultat lorsque l'exécution des threads est complètement confuse. Par exemple, nous avons enregistré une unité dans un flux en X, dans le second, nous avons réussi à avoir une unité en Y, et nous calculons un. Vous pouvez alors voir quelles autres options sont disponibles comme exercice à domicile.

Il semble que nous ayons passé en revue toutes les options possibles, il n'y a rien de plus. Lançons l'utilitaire et voyons quelle conclusion il donne.

La sortie ressemble à une table. La première colonne répertorie les résultats que nous avons ajoutés dans II_Result - l'utilitaire exécute ce code des millions de fois - et le nombre de cas où un résultat particulier a été rencontré. Mais ce rapport n'aurait probablement pas été le cas si tout avait été si simple.
En fait, dans cette conclusion, nous pouvons également voir le résultat zéro-zéro, ce qui est difficile à expliquer avec le modèle d'alternance. Il semble que l'une des options possibles est que quelqu'un directement dans le code du flux ait pris et réorganisé les lignes.
Voyons pourquoi cela s'est produit et comment vivre avec. Je vous demande également de prêter attention au fait que l'option one-one a été trouvée très rarement sur ma machine. Sur 130 millions de représentations, seulement 154 représentations ont donné lieu à un contre un. Et au contraire, zéro à zéro se produit très souvent, dans près de 30% des cas.

Donc, pour résumer un résultat intermédiaire que nous avons tous vu avec vous. Tout d'abord, nous pourrions comprendre que l'interaction des flux à travers la mémoire n'est pas triviale. Le modèle de rotation que nous avons utilisé ne fonctionne pas. Nous avons vu un certain réarrangement. Cela peut arriver pour plusieurs raisons.
Par exemple, nous pourrions voir certains «effets relativistes» du fer. Cela peut être pensé dans la veine suivante: dans un cycle d'horloge d'un processeur à 3 GHz, la lumière parcourt environ 10 cm dans le vide. Le protocole de lecture et d'écriture dans la mémoire du processeur est compliqué et il faut parfois plusieurs centaines de cycles d'horloge pour transférer la valeur d'un cœur à un autre. En conséquence, un noyau peut sembler voir le passé. Le résultat après l'enregistrement s'est produit, mais nous voyons l'ancienne valeur. De plus, les processeurs ne restent pas immobiles et peuvent modifier les instructions par endroits.
Les compilateurs d'optimisation modernes peuvent conduire à la même permutation. Pour obtenir des performances monothread maximales, ils peuvent également échanger des instructions afin que cela ne perturbe pas l'exactitude d'un programme monothread. Mais dans les programmes multithreads, cela peut conduire à des effets intéressants que nous avons vus.
Et la seconde - probablement la principale conclusion: nous avons vu que les programmes multithread ne sont pas fondamentalement déterminés. Les programmes à thread unique reposent principalement sur certains invariants en entrée et en sortie et sont déterministes; étant donné que le générateur de nombres aléatoires et l'entrée utilisateur sont des paramètres d'entrée.
Cela rend les choses très compliquées: il est difficile de comprendre ce que fait le programme et il est difficile de le tester.
Concernant la complexité des tests, nous pouvons ajouter que le même résultat n'a été trouvé que 154 fois sur 130 millions d'appels. La probabilité d'occurrence de ce résultat est d'un millionième. En production, cela signifie qu'un tel bug peut être reproduit après des semaines. Et cela arrivera certainement quelque part dimanche soir, alors que vous ne vous y attendiez pas du tout.

Réfléchissons à comment nous devrions être et à ce que nous voulons généralement de notre langue pour dormir paisiblement le dimanche soir. Premièrement, nous avons besoin d'un outil qui nous permet de prédire le comportement du programme et de juger de son exécution. Deuxièmement, nous avons besoin d'outils de langage qui nous permettraient d'influencer les permutations et les effets - ils peuvent provenir du matériel, du compilateur, etc. J'aimerais en savoir moins sur le fonctionnement d'un processeur particulier, les optimisations que le compilateur peut faire et utiliser l'abréviation qui venait du monde Java. Écrire une fois, exécuter n'importe où - écrivez une fois le code multithread correct pour qu'il fonctionne sur toutes les plateformes.

Ces questions et exigences que nous avons énumérées, elles ont surgi dans l'esprit des développeurs pendant très longtemps et des théoriciens et praticiens. Comme toute tâche complexe avec un haut niveau de complexité, elle a été résolue en introduisant le concept d'une machine abstraite. Nous tous, développeurs de langages de programmation de haut niveau, n'écrivons pas pour un matériel particulier, pas pour un tel modèle de processeur, mais écrivons une machine abstraite. Et la spécification du langage est conçue pour décrire son comportement de manière à réconcilier ces trois mondes. D'une part, laissons les développeurs de compilateurs et de processeurs faire leurs optimisations et nous faire légèrement réfléchir, programmeurs qui écrivent déjà dans un langage particulier.
Le modèle de mémoire occupe une position centrale dans cette machine abstraite. Elle devrait répondre à une question: si je lis une variable X dans un flux, le résultat de laquelle des dernières entrées puis-je y voir? Une tentative de formalisation du modèle de mémoire a été faite pour la première fois dans le langage Java, tous les autres modèles de mémoire sont apparus plus tard. Disons que C ++ 11 est presque un copier-coller du modèle de mémoire Java avec quelques modifications.
Il y avait plusieurs modèles de mémoire en Java. Initialement, le modèle de mémoire dit "en forme de cloche", il a été reconnu comme infructueux, car il gênait le travail des programmeurs qui écrivent en Java et interdisait certaines optimisations au compilateur, qui sont tout à fait appropriées pour elles-mêmes. En conséquence, dans le cadre du processus communautaire JSR-133, un modèle de mémoire moderne a été écrit.
Puisque nous avons l'Écriture sous la forme d'une spécification, essayons de l'examiner et de comprendre ce qui se passe réellement à l'intérieur.

Il y a un problème. Levez la main, qui a ouvert la spécification de la langue et lu ce qui s'y passait. Et combien d'entre vous ont lu le modèle de mémoire du paragraphe 17.4? Une petite surprise vous attend. La spécification du langage est essentiellement décrite dans un langage assez compréhensible. Mais le modèle de mémoire est plein, disons, de hardcore mathématique. Il y a des inclusions en grec, beaucoup de termes mathématiques de la fermeture transitive série, l'union de deux ordres, etc.
Malheureusement, il n'y a pas d'autre moyen. La seule chose sur laquelle vous pouvez compter lors de l'écriture de programmes multithread est la spécification. Elle devra lire et comprendre. Je vous recommande vivement. De plus, lorsque j'ai lu la spécification pour la première fois, j'avais de telles impressions.
Pourquoi est-ce si difficile? J'ai fait le mauvais chemin et je vous préviens vivement d'agir comme moi.
Je l'ai pris, j'ai cherché sur Internet ce qu'est un modèle de mémoire. J'ai trouvé un livre intitulé JSR-133 Cookbook for Compiler Writers. Elle décrit comment un développeur de compilateur peut implémenter ce modèle de mémoire de manière simple. Le problème est qu'il s'agit d'une implémentation spécifique et qu'elle ne peut pas être utilisée pour juger l'ensemble du modèle de mémoire en général.
Quoi qu'il en soit, essayons de faire une petite tentative sur les principales conclusions qui peuvent être comprises à partir du modèle de mémoire Java.

Il peut y avoir de nombreuses exécutions de votre programme multithread. Nous l'avons vu nous-mêmes sur l'exemple de notre programme auparavant. Dans l'exemple le plus simple, nous avons déjà eu quatre résultats de sa mise en œuvre. Et la tâche du modèle de mémoire Java est de dire lesquelles de ces exécutions sont correctes et lesquelles doivent être interdites. Et postule trois choses. La première est que dans le cadre d'un thread, votre tâche est exécutée de manière pseudo-séquentielle. Cela implique que le compilateur peut échanger des opérations, le processeur peut également exécuter des instructions en parallèle, les échanger. Mais ils doivent le faire pour que les effets visibles de l'exécution de votre programme soient les mêmes que s'ils étaient exécutés directement séquentiellement.
Deuxièmement, les soi-disant significations de nulle part prises de nulle part sont interdites dans la langue. Malheureusement, nous n'avons pas le temps de le montrer, mais il y a des cas où le compilateur peut vraiment faire une telle conversion que tout sera correct dans un programme à un seul thread, et vous pouvez avoir un enregistrement dans un programme à plusieurs threads que vous n'avez pas fait.
Par conséquent, le modèle de mémoire indique que la lecture de n'importe quelle variable retournera soit la valeur par défaut, soit certains des résultats de l'enregistrement qui a été effectué une fois par une autre commande. Et les actions restantes peuvent être interprétées comme séquentielles, si elles sont connectées par une relation d'ordre partiel qui se produit avant. Et c'est maintenant le seul endroit où nous avons besoin de mathématiques. Relation partielle, c'est parce que toutes les opérations de lecture, d'écriture des variables, elles sont reliées par relation. Il a les propriétés de réflexivité, transitivité et antisymétrie.

Parlons plus en détail de ce qui se passe avant lui-même. La première règle est qu'elle relie toutes les opérations au sein d'un même thread. Si vous avez écrit dans un thread que X est égal à un, Y est égal à un; il est indiqué que les opérations d'écriture dans X sont liées à ce qui se passe avant Y. C'est-à-dire que X se produit avant Y. Et il lie également certaines actions spéciales, les actions dites de synchronisation. En savoir plus dans la spécification. Par exemple, il s'agit d'écrire et de lire à partir d'une variable volatile, de verrouiller / déverrouiller sur un moniteur, d'entrer dans le bloc synchronisé et de sortir du bloc synchronisé. Un point très important est que toutes les actions de synchronisation de votre programme voient les threads exactement dans le même ordre, comme s'ils étaient exécutés un par un.
Et arrive-avant relie quelques paires de ces actions. Peu importe les actions de synchronisation des threads qui ont lieu. Il est important qu'elles passent, par exemple, sur une variable volatile. La spécification dit, disons, que l'écriture dans la variable volatile se produit avant toute autre action ultérieure. Cela se réfère précisément à la manière dont nous avons eu les actions de synchronisation.
Et le plus important de tout cela est la règle qui se produit avant la cohérence, qui ne fait que répondre à la question la plus importante sur le modèle de mémoire. Il peut être interprété comme suit. S'il y a une chaîne d'opérations de lecture / écriture dans une variable et qu'elles sont connectées par une chaîne de relations qui se produisent avant, alors la lecture devrait définitivement voir le dernier enregistrement de cette chaîne. S'il n'y est pas, vous pouvez voir toute autre valeur, tout autre enregistrement ou valeur par défaut. Vous pouvez maintenant expirer, avec les définitions de base que nous avons faites.
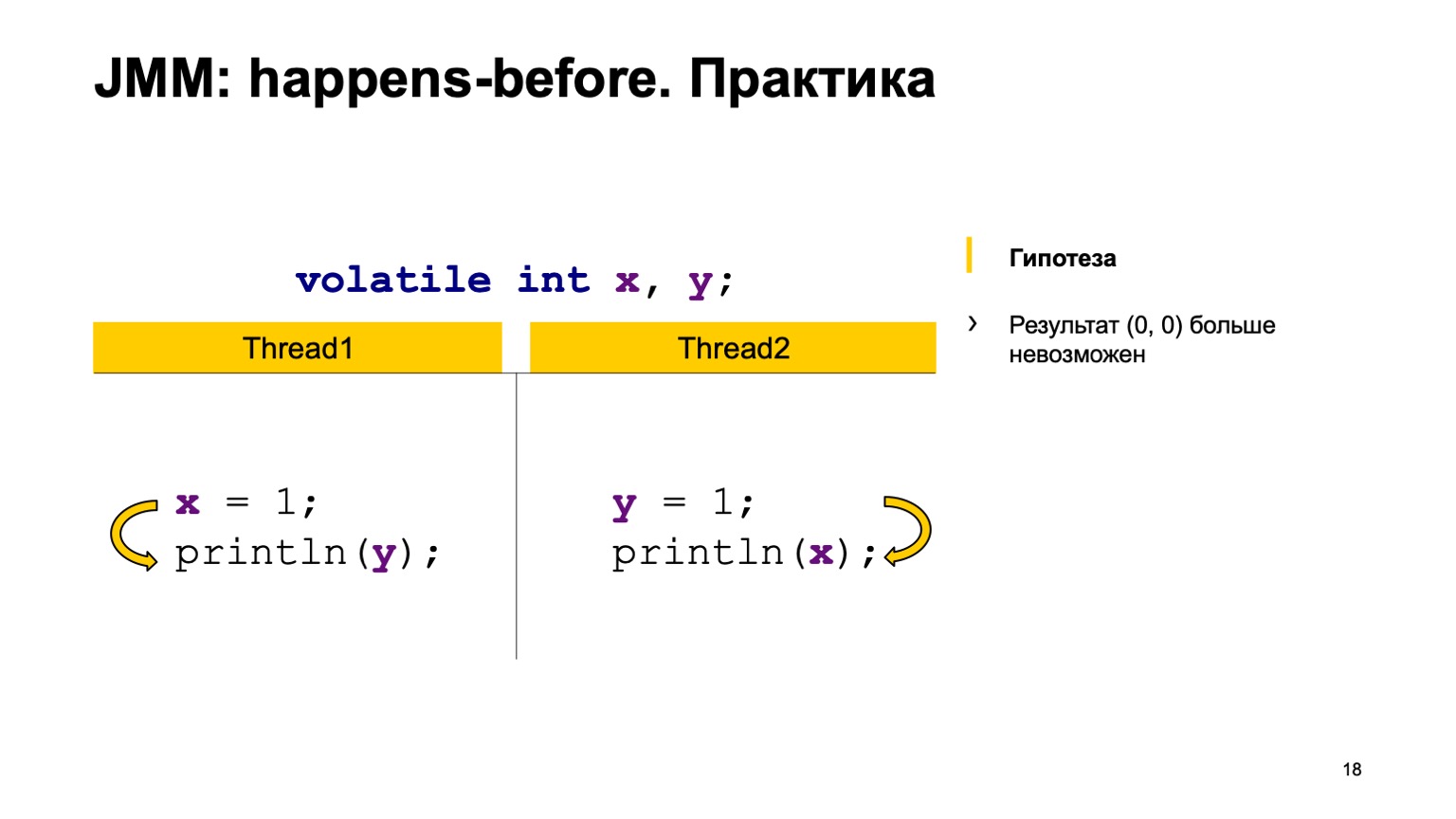
Essayons de tester la théorie dans la pratique? Prenons un exemple avec une lecture croisée des enregistrements et ajoutons simplement le modificateur volatile aux variables X et Y. Essayons de prouver l'hypothèse que nous ne verrons plus la valeur zéro-zéro. Pour ce faire, utilisez simplement les règles que j'ai exprimées ci-dessus.
Nous organiserons les événements avant dans un seul fil. L'écriture vers X se produit - avant la lecture de Y et dans le deuxième fil. Écrire à Y arrive avant de lire à partir de X.
Et puis nous avons quatre actions de synchronisation: écrire sur X, écrire sur Y, lire sur X, lire sur Y. Elles peuvent apparaître dans un certain ordre, et une paire peut se produire dans deux cas.
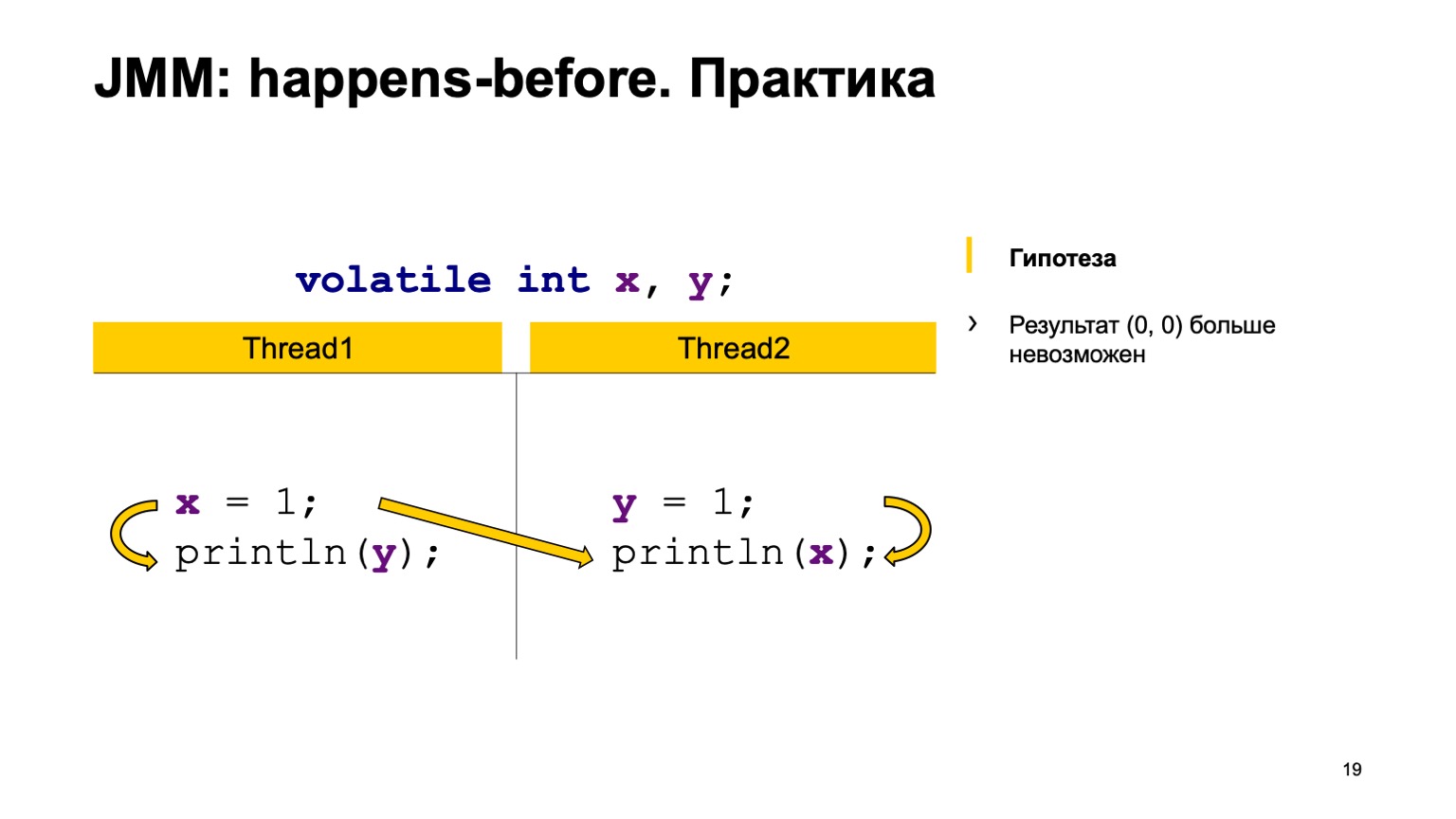
Par exemple, l'écriture sur X dans le flux un s'est produite plus tôt que la lecture sur X dans le flux deux (arrive-avant se produit). Comme vous pouvez le voir ici, la relation n'est pas liée à Y. Le résultat de la lecture de Y peut simplement nous renvoyer la valeur par défaut ou la valeur enregistrée par le deuxième flux. Une lecture de X doit toujours voir une unité. Par conséquent, nos options peuvent être nulles, égales à une.
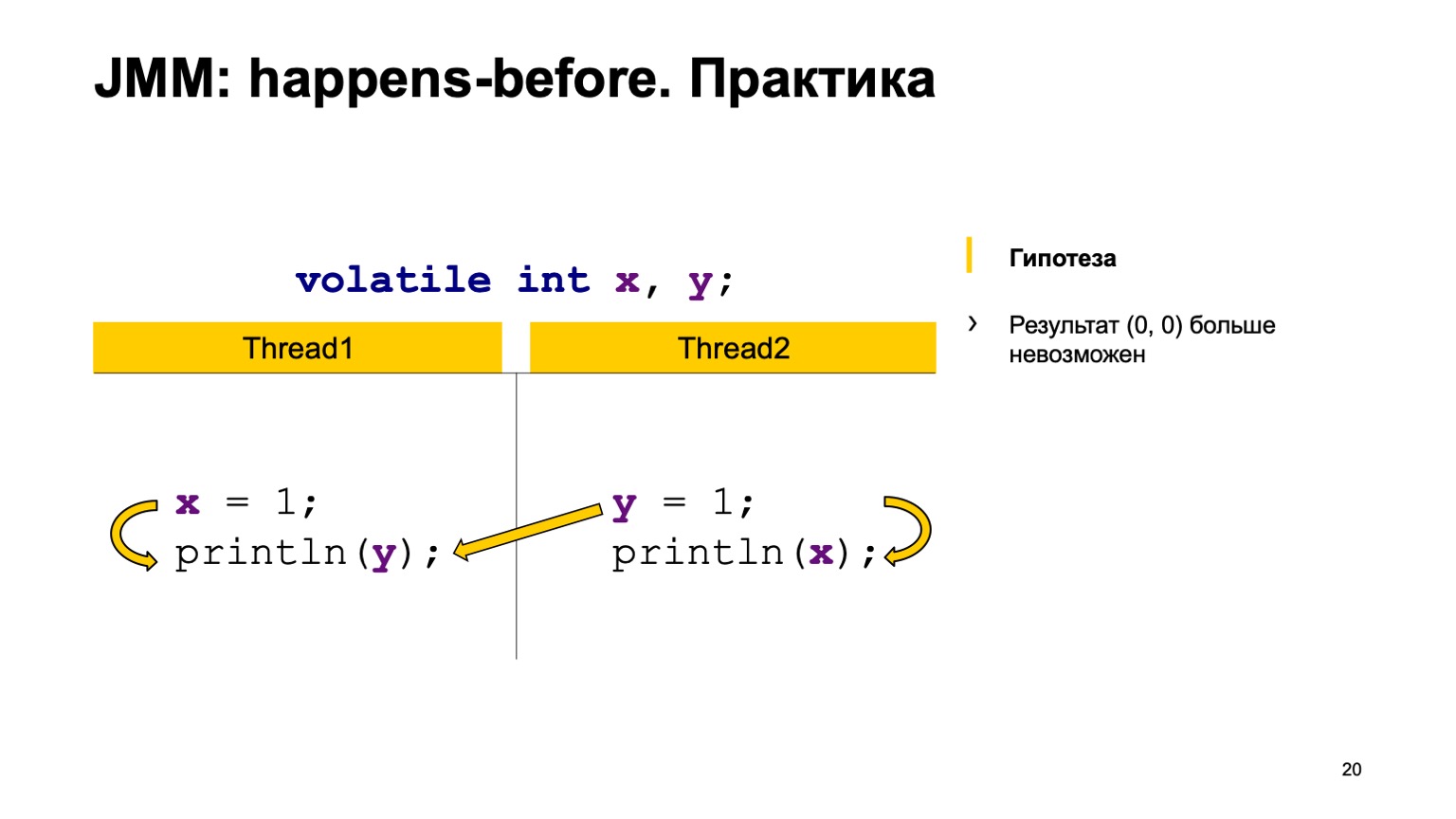
Le deuxième cas est lorsqu'une connexion se produit. C'est la même chose - écrire sur Y arrive - avant de lire sur Y. De plus, il n'y a pas de connexion entre X. En conséquence, le résultat est le même, seulement là vous obtenez un zéro, zéro un. Théoriquement, nous pouvons prouver notre nouveau comportement de programme.

Vous pouvez le vérifier en pratique. Prenez et ajoutez le mot-clé volatile dans notre test. Courez et voyez que, en effet, dans notre pays, cette valeur ne sera jamais reproduite. happens-before — . .

, . volatile Z volatile, . , Z; , , , Z. happens-before . , Z , . .
, , — put value. — get value . happens-before , , put value happens-before get value. , happens-before , volatile, . , , — put happens-before get.

, . -, . , , . , . , , . , . , , , , .
-, , jcstress. : , JVM . , .
, . — «The Art of Multiprocessor Programming» . , happens-before, , . . — «Java Concurrency in Practice» . , . , , . . .
, performance- Oracle, Red Hat. , Java- , . JMM.
Vous pouvez lire le blog de Roman Elizarov . Il a enseigné, à mon avis, la programmation multithread de l'ITMO. Il a un blog légèrement abandonné, mais vous pouvez lire, rechercher ses conférences et discours sur YouTube. En général, très approprié, je conseille. Merci à tous.