Les langages OO les plus populaires fournissent un outil tel qu'un modificateur pour accéder à une méthode ou un champ. Et c'est bon pour les programmeurs expérimentés, mais ce n'est pas par où commencer avec l'encapsulation. Ci-dessous, je vais expliquer pourquoi.
 Clause de non-responsabilité.
Clause de non-responsabilité. Cet article n'est pas un appel à l'action et n'indique pas qu'il existe le seul moyen raisonnablement correct de masquer les données. Cet article est destiné à offrir au lecteur une perspective éventuellement nouvelle sur l'encapsulation. Il existe de nombreuses situations où les modificateurs d'accès sont préférables, mais ce n'est pas une raison pour garder le silence sur les interfaces.
En général, l'encapsulation est définie comme un moyen de cacher l'implémentation interne d'un objet au client afin de maintenir l'intégrité de l'objet et de cacher la complexité de cette implémentation très interne.
Il existe plusieurs façons de parvenir à cette dissimulation. L'un est l'utilisation de modificateurs d'accès, l'autre est l'utilisation d'interfaces (protocoles, fichiers d'en-tête, ...). Il existe d'autres fonctionnalités délicates, mais l'article ne les concerne pas.
Les modificateurs d'accès à première vue peuvent sembler plus puissants en termes de masquage de l'implémentation, car ils donnent le contrôle de chaque champ individuellement et offrent plus d'options d'accès. En réalité, ce n'est en partie qu'un raccourci pour créer plusieurs interfaces vers la classe. Les modificateurs d'accès offrent des opportunités pas plus larges que les interfaces, car ils s'expriment à l'exception d'un détail. À propos d'elle ci-dessous.
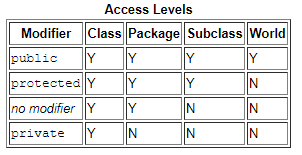 Visibilité du champ indiquée par différents modificateurs d'accès en Java.
Visibilité du champ indiquée par différents modificateurs d'accès en Java.L'extrait de code ci-dessous montre une classe avec des modificateurs d'accès aux méthodes et représentations équivalentes sous forme d'interfaces.
public class ConsistentObject { public void methodA() { } protected void methodB() { } void methodC() { } private void methodD() { } } public interface IPublicConsistentObject { void methodA() { } } public interface IProtectedConsistentObject: IPublicConsistentObject { void methodB() { } } public interface IDefaultConsistentObject: IProtectedConsistentObject { void methodC() { } }
Les protocoles présentent plusieurs avantages. Il suffit de mentionner que c'est le principal moyen de mettre en œuvre le polymorphisme dans la POO, qui atteint les nouveaux arrivants beaucoup plus tard qu'il ne le pourrait.
La seule difficulté à aborder les protocoles est que vous devez contrôler le processus de création d'objets. La génération de modèles est nécessaire précisément pour protéger le code dangereux contenant des types spécifiques du code pur qui fonctionne avec les interfaces. En observant cette règle simple, nous obtenons la même encapsulation que l'utilisation des qualificatifs, mais en même temps, nous obtenons plus de flexibilité.
Un tel code en C #
public class DataAccessObject { private void readDataFromFixedSource() {
sera équivalent à celui des capacités du client.
public class DataAccessObjectFactory { public IDataAccessObject createNew() { return new DataAccessObject(); } } public interface IDataAccessObject { byte[] getData(); } class DataAccessObject: IDataAccessObject { void readDataFromFixedSource() {
En raison de l'existence de modificateurs d'accès, les débutants ne connaîtront pas les interfaces pendant très longtemps. Pour cette raison, ils n'utilisent pas le véritable pouvoir de l'OLP. Autrement dit, il y a une certaine substitution de concepts. Les modificateurs d'accès sont sans aucun doute un attribut de la POO, mais ils font également glisser la couverture des interfaces qui ouvrent la POO beaucoup plus fortement.
De plus, les interfaces vous permettent de choisir consciemment les fonctionnalités qu'un client peut recevoir d'un objet. Autrement dit, nous avons la possibilité de fournir des protocoles complètement indépendants pour différents clients, tandis que les modificateurs ne font pas de distinction entre les clients. C'est un gros plus en faveur des interfaces.