Je veux partager avec vous ma première expérience réussie dans la restauration de toutes les fonctionnalités de la base de données Postgres. J'ai rencontré Postgres DBMS il y a six mois, avant cela, je n'avais aucune expérience en administration de base de données.

Je travaille en tant qu'ingénieur semi-DevOps dans une grande entreprise informatique. Notre entreprise développe des logiciels pour des services très chargés, mais je suis responsable des performances, de la maintenance et du déploiement. Ils m'ont fixé une tâche standard: mettre à jour l'application sur un serveur. L'application est écrite dans Django, pendant la mise à niveau, des migrations sont effectuées (modification de la structure de la base de données), et avant ce processus, nous supprimons le vidage complet de la base de données via le programme pg_dump standard au cas où.
Une erreur inattendue s'est produite lors de la suppression du vidage (la version Postgres est 9.5):
pg_dump: Oumping the contents of table “ws_log_smevlog” failed: PQgetResult() failed. pg_dump: Error message from server: ERROR: invalid page in block 4123007 of relatton base/16490/21396989 pg_dump: The command was: COPY public.ws_log_smevlog [...] pg_dunp: [parallel archtver] a worker process dled unexpectedly
L'erreur
"page non valide dans le bloc" indique des problèmes au niveau du système de fichiers, ce qui est très mauvais. Sur divers forums, ils ont suggéré de créer
FULL VACUUM avec l'option
zero_damaged_pages pour résoudre ce problème. Eh bien, popprobeum ...
Préparation de la récupération
ATTENTION! Assurez-vous de sauvegarder Postgres avant toute tentative de restauration de la base de données. Si vous avez une machine virtuelle, arrêtez la base de données et prenez un instantané. S'il n'est pas possible de prendre un instantané, arrêtez la base de données et copiez le contenu du répertoire Postgres (y compris les fichiers wal) dans un endroit sûr. L'essentiel de notre métier n'est pas d'aggraver les choses. Lisez
ceci .
Étant donné que la base de données fonctionnait pour moi dans son ensemble, je me suis limité au vidage de base de données habituel, mais j'ai exclu la table avec des données endommagées (option
-T, --exclude-table = TABLE dans pg_dump).
Le serveur était physique, il était impossible de prendre un instantané. La sauvegarde est supprimée, continuez.
Vérification du système de fichiers
Avant de tenter de restaurer la base de données, vous devez vous assurer que tout est en ordre avec le système de fichiers lui-même. Et en cas d'erreurs, corrigez-les, sinon vous ne pourrez qu'aggraver les choses.
Dans mon cas, le système de fichiers avec la base de données a été monté dans
«/ srv» et le type était ext4.
Nous arrêtons la base de données:
systemctl stop postgresql@9.5-main.service et vérifions que le système de fichiers n'est utilisé par personne et qu'il peut être démonté à l'aide de la
commande lsof :
lsof + D / srvJ'ai quand même dû arrêter la base de données redis, car elle utilisait également
"/ srv" . Ensuite, j'ai démonté
/ srv (umount).
La vérification du système de fichiers a été effectuée à l'aide de l'utilitaire
e2fsck avec l'option -f (
Forcer la vérification même si le système de fichiers est marqué comme propre ):
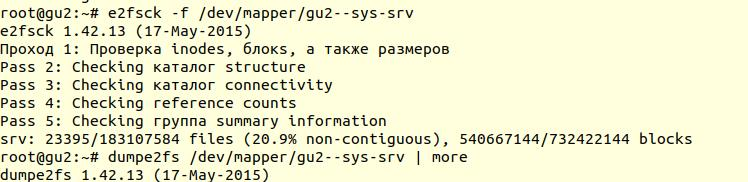
Ensuite, en utilisant l'utilitaire
dumpe2fs (
sudo dumpe2fs / dev / mapper / gu2 - sys-srv | grep vérifié ), vous pouvez vérifier que la vérification a bien été effectuée:
 e2fsck
e2fsck indique qu'aucun problème n'a été trouvé au niveau du système de fichiers ext4, ce qui signifie que vous pouvez continuer à essayer de restaurer la base de données, ou plutôt revenir au
vide complet (bien sûr, vous devez remonter le système de fichiers et démarrer la base de données).
Si votre serveur est physique, assurez-vous de vérifier l'état des disques (via
smartctl -a / dev / XXX ) ou le contrôleur RAID pour vous assurer que le problème n'est pas au niveau matériel. Dans mon cas, le RAID s'est avéré être «ironique», j'ai donc demandé à l'administrateur local de vérifier l'état du RAID (le serveur était à plusieurs centaines de kilomètres de moi). Il a dit qu'il n'y avait pas d'erreur, ce qui signifie que nous pouvons certainement commencer la restauration.
Tentative 1: zero_damaged_pages
Nous nous connectons à la base de données via le compte psql avec des droits de superutilisateur. Nous avons besoin exactement du superutilisateur, car lui seul peut changer l'option
zero_damaged_pages . Dans mon cas, ce sont des postgres:
psql -h 127.0.0.1 -U postgres -s [nom_base_de_données]L'option
zero_damaged_pages est nécessaire pour ignorer les erreurs de lecture (depuis le site Web de postgrespro):
Lorsqu'un titre de page endommagé est détecté, Postgres Pro signale généralement une erreur et abandonne la transaction en cours. Si le paramètre zero_damaged_pages est activé, le système émet à la place un avertissement, efface la page endommagée en mémoire et poursuit le traitement. Ce comportement détruit les données, à savoir toutes les lignes de la page endommagée.
Activez l'option et essayez de créer des tables de vide complètes:
VACUUM FULL VERBOSE
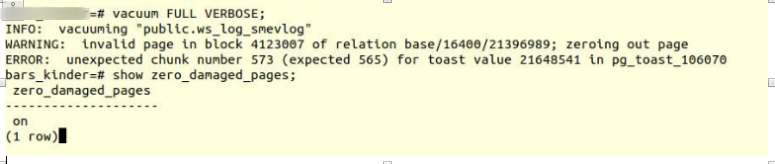
Malheureusement, l'échec.
Nous avons rencontré une erreur similaire:
INFO: vacuuming "“public.ws_log_smevlog” WARNING: invalid page in block 4123007 of relation base/16400/21396989; zeroing out page ERROR: unexpected chunk number 573 (expected 565) for toast value 21648541 in pg_toast_106070
pg_toast - le mécanisme de stockage des "données longues" dans Postgres, si elles ne tiennent pas sur la même page (8 Ko par défaut).
Tentative 2: réindexer
Le premier conseil google n'a pas aidé. Après quelques minutes de recherche, j'ai trouvé une deuxième astuce - pour faire
réindexer une table endommagée. J'ai rencontré ce conseil dans de nombreux endroits, mais il n'a pas inspiré confiance. Faire réindexer:
reindex table ws_log_smevlog
 réindexation
réindexation terminée sans problème.
Cependant, cela n'a pas aidé,
VACUUM FULL s'est écrasé avec une erreur similaire. Comme j'avais l'habitude des échecs, j'ai commencé à chercher des conseils sur Internet et suis tombé sur un
article assez intéressant.
Tentative 3: SELECT, LIMIT, OFFSET
L'article ci-dessus suggère de regarder le tableau ligne par ligne et de supprimer les données problématiques. Pour commencer, il fallait regarder toutes les lignes:
for ((i=0; i<"Number_of_rows_in_nodes"; i++ )); do psql -U "Username" "Database Name" -c "SELECT * FROM nodes LIMIT 1 offset $i" >/dev/null || echo $i; done
Dans mon cas, le tableau contenait 1
628 991 lignes! Dans le bon sens, il fallait s'occuper du
partitionnement des données , mais c'est un sujet à discuter séparément. C'était samedi, j'ai exécuté cette commande dans tmux et je me suis endormi:
for ((i=0; i<1628991; i++ )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog LIMIT 1 offset $i" >/dev/null || echo $i; done
Le matin, j'ai décidé de vérifier comment les choses se passaient. À ma grande surprise, j'ai trouvé qu'en 2 heures seulement 2% des données étaient scannées! Je ne voulais pas attendre 50 jours. Un autre échec complet.
Mais je n'ai pas abandonné. Je me demandais pourquoi l'analyse avait pris autant de temps. À partir de la documentation (toujours sur postgrespro), j'ai découvert:
OFFSET indique de sauter le nombre de lignes spécifié avant de commencer à produire des lignes.
Si OFFSET et LIMIT sont spécifiés, le système saute d'abord les lignes OFFSET puis commence à compter les lignes pour limiter LIMIT.
Lorsque vous utilisez LIMIT, il est également important d'utiliser la clause ORDER BY pour que les lignes de résultat soient renvoyées dans un ordre spécifique. Sinon, des sous-ensembles de chaînes imprévisibles seront retournés.
De toute évidence, la commande ci-dessus était erronée: tout d'abord, il n'y avait pas d'
ordre par , le résultat pouvait être erroné. Deuxièmement, Postgres a d'abord dû balayer et ignorer les lignes OFFSET, et avec une augmentation de
OFFSET, les performances diminueraient encore plus.
Tentative 4: supprimer le vidage sous forme de texte
De plus, une idée apparemment brillante m'est venue à l'esprit: supprimer le vidage sous forme de texte et analyser la dernière ligne enregistrée.
Mais d'abord, regardons la
structure de la table
ws_log_smevlog :

Dans notre cas, nous avons une colonne
«id» , qui contenait un identifiant unique (compteur) pour la ligne. Le plan était le suivant:
- Nous commençons à supprimer le vidage sous forme de texte (sous la forme de commandes sql)
- À un certain moment, le vidage serait interrompu en raison d'une erreur, mais le fichier texte serait toujours enregistré sur le disque
- Nous regardons la fin du fichier texte, ainsi nous trouvons l'identifiant (id) de la dernière ligne qui a été tournée avec succès
J'ai commencé à supprimer le vidage sous forme de texte:
pg_dump -U my_user -d my_database -F p -t ws_log_smevlog -f ./my_dump.dump
Le vidage de vidage, comme prévu, a été interrompu avec la même erreur:
pg_dump: Error message from server: ERROR: invalid page in block 4123007 of relatton base/16490/21396989
De plus, à travers
tail, j'ai regardé la fin du vidage (
tail -5 ./my_dump.dump ) et
j'ai constaté que le vidage était interrompu sur la ligne avec l'ID
186 525 . "Donc, le problème est dans la ligne avec l'ID 186 526, il est cassé, et il doit être supprimé!" J'ai pensé. Mais en faisant une demande à la base de données:
"
Sélectionnez * dans ws_log_smevlog où id = 186529 ", il s'est avéré que tout allait bien avec cette ligne ... Les lignes avec les indices 186 530 - 186 540 ont également fonctionné sans problème. Une autre «brillante idée» a échoué. Plus tard, j'ai réalisé pourquoi cela s'est produit: lors de la suppression / modification de données de la table, elles ne sont pas physiquement supprimées, mais sont marquées comme «tuples morts», puis l'
autovacuum vient et marque ces lignes comme supprimées et permet à nouveau l'utilisation de ces lignes. Pour comprendre, si les données du tableau sont modifiées et que le vide automatique est activé, elles ne sont pas stockées séquentiellement.
Tentative 5: SELECT, FROM, WHERE id =
Les échecs nous rendent plus forts. Vous ne devez jamais abandonner, vous devez aller jusqu'au bout et croire en vous et en vos capacités. Par conséquent, j'ai décidé d'essayer une autre option: il suffit de visualiser toutes les entrées de la base de données une par une. Connaissant la structure de ma table (voir ci-dessus), nous avons un champ id unique (clé primaire). Dans le tableau, nous avons 1 628 991 lignes et
id passe dans l'ordre, ce qui signifie que nous pouvons simplement les parcourir une par une:
for ((i=1; i<1628991; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done
Si quelqu'un ne comprend pas, la commande fonctionne comme suit: elle analyse la table ligne par ligne et envoie stdout à
/ dev / null , mais si la commande SELECT échoue, le texte d'erreur s'affiche (stderr est envoyé à la console) et une ligne contenant l'erreur est sortie (grâce à ||, qui signifie que select a eu des problèmes (le code retour de la commande n'est pas 0)).
J'ai eu de la chance, j'ai fait créer des index sur le champ
id :

Cela signifie que la recherche de la ligne avec l'ID souhaité ne devrait pas prendre beaucoup de temps. En théorie, cela devrait fonctionner. Eh bien, exécutez la commande dans
tmux et allez dormir.
Le matin, j'ai constaté qu'environ 90 000 enregistrements ont été consultés, ce qui représente un peu plus de 5%. Excellent résultat par rapport à la méthode précédente (2%)! Mais je ne voulais pas attendre 20 jours ...
Tentative 6: SELECT, FROM, WHERE id> = et id <
Un excellent serveur a été attribué au client dans la base de données:
Intel Xeon E5-2697 v2 à double processeur, dans notre emplacement il y avait jusqu'à 48 threads! La charge du serveur était moyenne, nous pouvions prendre environ 20 threads sans aucun problème. La RAM était également suffisante: jusqu'à 384 gigaoctets!
Par conséquent, la commande devait être parallélisée:
for ((i=1; i<1628991; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done
Ici, il était possible d'écrire un script beau et élégant, mais j'ai choisi le moyen le plus rapide de paralléliser: décomposer manuellement la plage 0-1628991 en intervalles de 100 000 enregistrements et exécuter 16 commandes du formulaire séparément:
for ((i=N; i<M; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done
Mais ce n’est pas tout. En théorie, la connexion à une base de données prend également du temps et des ressources système. Connecter 1 628 991 n'était pas très raisonnable, d'accord. Par conséquent, extrayons 1000 lignes dans une connexion au lieu d'une. En conséquence, l'équipe s'est transformée en ceci:
for ((i=N; i<M; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done
Ouvrez 16 fenêtres dans la session tmux et exécutez les commandes:
1) for ((i=0; i<100000; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done 2) for ((i=100000; i<200000; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done … 15) for ((i=1400000; i<1500000; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done 16) for ((i=1500000; i<1628991; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done
Un jour plus tard, j'ai obtenu les premiers résultats! A savoir (les valeurs XXX et ZZZ n'ont pas été conservées):
ERROR: missing chunk number 0 for toast value 37837571 in pg_toast_106070 829000 ERROR: missing chunk number 0 for toast value XXX in pg_toast_106070 829000 ERROR: missing chunk number 0 for toast value ZZZ in pg_toast_106070 146000
Cela signifie que nous avons trois lignes contenant une erreur. L'ID des premier et deuxième enregistrements de problème se situait entre 829 000 et 830 000, l'ID du troisième se situait entre 146 000 et 147 000. Ensuite, nous devions simplement trouver la valeur d'ID exacte des enregistrements de problème. Pour ce faire, parcourez notre gamme avec les enregistrements de problèmes à l'étape 1 et identifiez l'id:
for ((i=829000; i<830000; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done 829417 ERROR: unexpected chunk number 2 (expected 0) for toast value 37837843 in pg_toast_106070 829449 for ((i=146000; i<147000; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done 829417 ERROR: unexpected chunk number ZZZ (expected 0) for toast value XXX in pg_toast_106070 146911
Fin heureuse
Nous avons trouvé les lignes problématiques. Nous allons dans la base de données via psql et essayons de les supprimer:
my_database=# delete from ws_log_smevlog where id=829417; DELETE 1 my_database=# delete from ws_log_smevlog where id=829449; DELETE 1 my_database=# delete from ws_log_smevlog where id=146911; DELETE 1
À ma grande surprise, les entrées ont été supprimées sans aucun problème, même sans l'option
zero_damaged_pages .
Ensuite, je me suis connecté à la base de données, j'ai créé
VACUUM FULL (je pense que ce n'était pas nécessaire) et j'ai finalement réussi à supprimer la sauvegarde à l'aide de
pg_dump . La décharge a joué sans aucune erreur! Le problème a été résolu d'une manière si stupide. Il n'y avait pas de limite à la joie, après tant d'échecs, nous avons réussi à trouver une solution!
Remerciements et conclusions
C'est ma première expérience dans la restauration d'une vraie base de données Postgres. Je me souviendrai longtemps de cette expérience.
Et enfin, je voudrais remercier PostgresPro pour la documentation traduite en russe et pour les
cours en ligne entièrement gratuits qui ont beaucoup aidé lors de l'analyse du problème.