Dans le processus de travail sur un grand projet, l'emprunt de modules et de solutions clé en main d'autres personnes permet d'économiser énormément de temps de développeur et d'argent pour les investisseurs. L'un des plus grands référentiels de ces solutions est de loin github.
Il y a une petite astuce sous le chat que j'utilise lors de la recherche et du choix des solutions github.
Imaginez la tâche de développer un grand système
OSINT , disons que nous devons examiner toutes les solutions disponibles sur github dans cette direction. nous utilisons la recherche github globale standard pour le mot clé osint. Nous obtenons 1124 référentiels, la possibilité de filtrer par l'emplacement de la recherche par mot-clé (code, commits, issuse, etc.), par le langage d'exécution. Et trier par divers attributs (comme le plus / le moins de démarrages, de fourches, etc.).
La décision est prise selon plusieurs critères: fonctionnalité, nombre d'étoiles, support de projet, langage de développement.
Les décisions qui m'intéressaient étaient résumées dans un tableau où les champs indiqués ci-dessus étaient remplis, des notes appropriées étaient prises en fonction des résultats d'un test particulier.
L'inconvénient de cette vue, il me semble, est le manque de capacité de trier et de filtrer simultanément sur plusieurs champs.
En utilisant
api_github et python3, nous
décrivons un simple script simple qui forme pour nous un document csv avec les champs qui nous intéressent.
Exécutez le script
python3 git_repo_search.py osint
nous obtenons
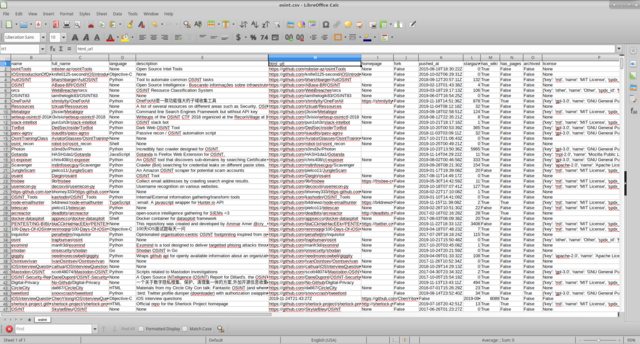
Il me semble que travailler avec des informations est plus pratique, après avoir caché des colonnes inutiles.
Code
iciJ'espère que quelqu'un vous sera utile.