À la veille du lancement du cours Backend PHP Developer, nous avons eu une leçon traditionnelle ouverte . Cette fois, nous nous sommes familiarisés avec le concept Serverless, avons parlé de son implémentation dans AWS, discuté des principes de fonctionnement, d'assemblage et de lancement, et avons également construit un simple TG-bot PHP basé sur AWS Lambda.
Conférencier - Alexander Pryakhin , CTO de Westwing Russie.

Une brève excursion dans l'histoire

Comment en est-on arrivé à une telle vie que l'informatique sans serveur est apparue? Bien sûr, ils sont apparus non seulement comme ça, mais sont devenus une continuation logique des technologies de virtualisation existantes.

Que virtualisons-nous habituellement? Par exemple, un processeur. Vous pouvez également virtualiser la mémoire en mettant en évidence certaines zones de mémoire et en les rendant accessibles à certains utilisateurs et inaccessibles à d'autres. Vous pouvez virtualiser un réseau VPN. Et ainsi de suite.

La virtualisation est bonne car nous utilisons mieux les ressources et augmentons la productivité. Mais il y a aussi des inconvénients, par exemple, à un moment donné, il y avait des problèmes de compatibilité. Cependant, il n'y a pratiquement aucune architecture qui serait incompatible avec les machines virtuelles modernes.
Le prochain inconvénient est que nous ajoutons une couche supplémentaire d'abstraction, ajoutons un hyperviseur, ajoutons une machine virtuelle par elle-même et, bien sûr, nous pouvons perdre un peu de vitesse. Un peu compliqué et l'utilisation du serveur.
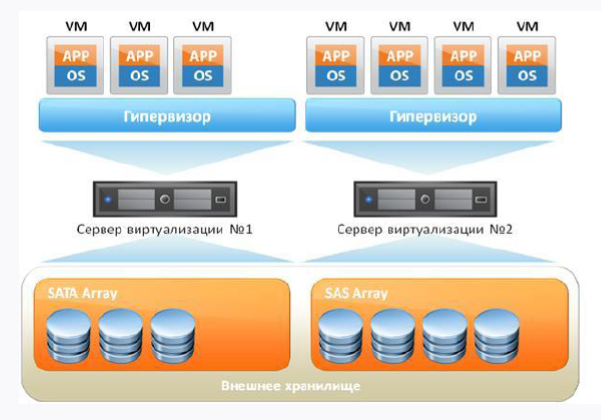
Si nous emportons une machine virtuelle standard avec vous, elle ressemblera à ceci:

Premièrement, nous avons un serveur de fer, et deuxièmement, le système d'exploitation sur lequel tournera notre hyperviseur. Et en plus de tout cela, nos machines virtuelles tournent, dans lesquelles il y a un OS invité, des bibliothèques et des applications. Si vous pensez logiquement, alors nous voyons des frais généraux en présence de l'OS invité, car en fait nous dépensons des ressources supplémentaires.
Comment puis-je résoudre le problème des frais généraux? Refuser les machines virtuelles et mettre un système de gestion de conteneurs au-dessus du système d'exploitation principal. Bien sûr, le système le plus populaire est désormais le Docker Engine. Ensuite, les bibliothèques à l'intérieur du conteneur utiliseront le noyau hôte du système d'exploitation.

De cette façon, nous supprimons les frais généraux, mais Docker n'est pas idéal non plus, et il a ses propres problèmes et fonctionnalités de travail que tout le monde n'aime pas.
La principale chose à comprendre est que Docker et la machine virtuelle sont des approches différentes, et il n'est pas nécessaire de les assimiler. Docker n'est pas un microvirtuel avec lequel vous pouvez travailler comme avec une machine virtuelle, car le conteneur est pour cela et le conteneur. Mais le conteneur nous permet d'offrir une flexibilité et une approche complètement différente de la livraison continue, lorsque nous livrons des choses à la production et comprenons qu'elles sont déjà testées et fonctionnent.
Technologie cloud
Avec le développement de la virtualisation, les technologies cloud ont également commencé à se développer. C'est une bonne solution, mais il convient de mentionner tout de suite que les nuages ne sont pas une solution miracle et pas une panacée pour tous les maux. Ici, on ne peut s'empêcher de rappeler une citation célèbre:
"Quand j'entends quelqu'un vanter le cloud comme une solution miracle pour tous les problèmes informatiques, je remplace silencieusement" cloud "par" clown "et continue avec un sourire zen."
Amy riche
Cependant, pour les moyennes entreprises qui souhaitent bénéficier d'un certain niveau de service et d'une tolérance aux pannes sans injections financières massives, le cloud est tout à fait une option. Et pour de nombreuses entreprises, conserver leur centre de données avec le même SLA sera beaucoup plus cher que d'être servi dans le cloud. De plus, nous pouvons utiliser les nuages pour nos besoins, car ils fournissent certaines choses en quelques clics de souris, ce qui est très pratique. Par exemple, la possibilité de lever une machine virtuelle ou un réseau en quelques clics.
Oui, il existe des restrictions, par exemple, la 152e loi fédérale interdisant le stockage de données personnelles à l'étranger, donc le même Amazon ne nous conviendra pas lors d'un audit. N'oubliez pas Vendor-lock. De nombreuses solutions cloud ne se portent pas entre elles, bien que le même stockage compatible S3 soit pris en charge par la plupart des fournisseurs.
Les nuages nous offrent la possibilité de recevoir différents niveaux de service sans connaissances étroitement ciblées. Moins vous aurez besoin de connaissances, plus nous paierons. Dans la figure ci-dessous, vous pouvez regarder la pyramide, où, de bas en haut, la diminution des connaissances techniques requises lors de l'utilisation du cloud est affichée:

Sans serveur et FaaS (Fonction en tant que service)
Sans serveur est une manière assez récente d'exécuter des scripts dans les nuages, par exemple, comme AWS (en termes d'AWS, le serveur est implémenté dans Lambda). * Les approches AaS répertoriées dans la pyramide ci-dessus sont déjà familières: IaaS (EC2, VDS), PaaS (hébergement partagé), SaaS (Office 365, Tilda). Ainsi, Serverless est une implémentation de l'approche FaaS. Et cette approche consiste à fournir à l'utilisateur une plate-forme prête à l'emploi pour le développement, le lancement et la gestion de certaines fonctionnalités sans nécessiter d'auto-préparation et de configuration.
Imaginez que vous ayez une machine qui est engagée dans le traitement de nuit des documents, effectuant des tâches de 00h00 à 6h00 et pendant le reste des heures, elle est inactive. La question est: pourquoi payer pour cela pendant la journée? Et pourquoi ne pas utiliser des ressources gratuites pour autre chose? Ce désir d'optimisation et le désir de dépenser de l'argent uniquement sur ce que vous utilisez réellement, ont conduit à l'émergence de FaaS.
Serverless est une ressource pour exécuter du code et rien de plus. Cela ne signifie pas qu'il n'y a pas de serveur derrière notre script - il l'est, mais nous n'avons en fait aucune ressource spécifiquement allouée sur laquelle notre Lambda sera lancée. Lorsque nous exécutons notre script, la micro-infrastructure se déroule immédiatement en dessous, et ce n'est pas votre problème en principe - vous pensez seulement que vous avez le code exécuté, et vous n'avez pas besoin de penser à autre chose.
Cela nécessite, bien sûr, une certaine approche du développement de votre code. Par exemple, vous ne pouvez rien stocker dans cet environnement, vous devez tout retirer. S'il s'agit de données, une base de données externe est nécessaire, s'il s'agit d'un journal, puis d'un service de journal externe, s'il s'agit d'un fichier, puis d'un stockage de fichiers externe. Heureusement, tout fournisseur sans serveur offre la possibilité de se connecter à des systèmes externes.
Vous n'avez que du code, vous travaillez dans le paradigme des apatrides, vous n'avez pas d'état. Pour le même monde de PHP, cela signifie, par exemple, que vous pouvez oublier le mécanisme de session standard. En principe, vous pouvez même construire votre Serverless, et récemment sur Habré il y avait un article à ce sujet .
L'idée principale de Serverless est que l'infrastructure ne nécessite pas le support de l'équipe. Tout tombe sur les épaules de la plateforme, pour laquelle vous payez en fait de l'argent. Parmi les inconvénients - vous ne contrôlez pas l'environnement d'exécution et ne savez pas où ce qui est effectué.
Sans serveur:
- ne signifie pas l'absence physique du serveur;
- pas un tueur de virtualoks et Docker;
- pas de battage médiatique ici et maintenant.
Sans serveur doit être poussé consciemment et délibérément. Par exemple, si vous devez tester rapidement une hypothèse sans impliquer la moitié de l'équipe. Vous obtenez donc la fonction en tant que service. La fonction répondra à certains événements, et comme il y a une réaction aux événements, ces événements doivent être appelés par quelque chose - pour cela, il existe de nombreux déclencheurs dans le même AWS.
Caractéristiques de FaaS:
- l'infrastructure ne nécessite pas de configuration;
- Modèle d'événement «prêt à l'emploi»;
- Apatride;
- la mise à l'échelle est très facile et s'effectue automatiquement en fonction des besoins de l'utilisateur.
AWS Lambda
La première implémentation FaaS accessible au public est AWS Lambda. S'il s'agit d'une thèse, elle présente les caractéristiques suivantes:
- disponible depuis 2014;
- prend en charge Java, Node.js, Python, Go et des runtimes personnalisés;
- nous payons pour:
nombre d'appels;
délai de livraison.
AWS Lambda: pourquoi est-il nécessaire:
Élimination Vous ne payez que pour la durée d'exécution du service.
La vitesse. Lambda elle-même se lève et fonctionne très rapidement.
Fonctionnel. Lambda possède de nombreuses fonctionnalités pour l'intégration avec les services AWS.
Performance. Mettre un lambda est assez difficile. En parallèle, elle peut être réalisée selon la région d'un maximum de 1000 à 3000 copies. Et si vous le souhaitez, cette limite peut être augmentée en écrivant à l'appui.
Nous avons un corps lambda, un éditeur en ligne, VPC comme une grille virtuelle de calculs, la journalisation, le code lui-même, les variables d'environnement et les déclencheurs qui provoquent lambda (en passant, le versioning fonctionne très bien). Une excellente anatomie Lambda est décrite dans cet article .
Le code est stocké soit dans le corps (s'il s'agit de langues prises en charge par défaut) soit dans des couches. Nous avons un déclencheur qui appelle le lambda, le lambda lit les environnements temporaires, les tire vers lui et exécute notre code:

Si nous avons un runtime personnalisé, nous devrons placer le code dans une couche. Si vous avez travaillé avec Docker, la couche Docker est très similaire à la couche de lambda - une sorte de quasi-référentiel dans lequel se trouve notre liaison nécessaire. Nous avons là le fichier exécutable de l'environnement (si nous parlons de PHP, vous devez placer le binaire PHP compilé à l'avance), le fichier d'amorçage lambda (situé par défaut) et les scripts directement appelés qui seront exécutés.

Avec la livraison, tout n'est pas si rose:

Autrement dit, il nous est proposé de prendre des fichiers avec le code, de les télécharger dans l'archive zip, de les télécharger sur la couche et d'exécuter notre code. C'est complètement cool que cela soit proposé dans la documentation officielle d'Amazon.

Bien sûr, cela ne correspond pas aux réalités modernes et à l'odeur de deux millièmes dans l'air. Heureusement, des gens gentils ont essayé et créé plusieurs frameworks, nous allons donc utiliser le framework Serverless développé sur Node.js et nous permettant de gérer les applications basées sur AWS Lambda. De plus, lorsque nous parlons de déploiement et de développement, bien sûr, je ne veux pas vraiment déployer manuellement, mais nous souhaitons faire quelque chose de flexible et d’automatisé.
Il nous faut donc:
- AWS CLI - interface de ligne de commande pour travailler avec les services AWS;
- le framework Serverless déjà mentionné ci-dessus (la version de développement est gratuite, et ses fonctionnalités suffisent aux yeux);
- La bibliothèque Bref, nécessaire à l'écriture de code. Cette bibliothèque est installée à l'aide de composer, donc le code sera compatible avec n'importe quel framework. Une excellente solution, d'autant plus qu'AWS Lambda ne prend pas en charge l'appel de scripts PHP hors de la boîte.

Personnalisez votre environnement et AWS
CLI AWS
Commençons par créer un compte et installer AWS CLI. Le shell de la console AWS est basé sur Python 2.7+ ou 3.4+. Étant donné qu'AWS recommande la version 3 de Python, nous ne discuterons pas.
Les exemples ci-dessous concernent Ubuntu.
sudo apt-get -y install python3-pip
Installez ensuite directement l'AWS CLI:
pip3 install awscli --upgrade --user
Vérifiez l'installation:
aws --version
Vous devez maintenant connecter AWS CLI à votre compte. Vous pouvez utiliser votre nom d'utilisateur et votre mot de passe existants, mais il serait préférable de créer un utilisateur distinct via AWS IAM, en lui définissant uniquement les droits d'accès nécessaires. L'appel de la configuration ne causera pas de problèmes:
aws configure
Ensuite, vous aurez besoin d'AWS Secret et d'AWS Access Key. Ils peuvent être obtenus dans ASW IAM dans l'onglet "Informations d'identification de sécurité" (situé sur la page de l'utilisateur souhaité). Le bouton «Créer une clé d'accès» vous aidera à générer des clés d'accès. Gardez-les avec vous.

Pour enregistrer un nouveau bot dans Telegram, utilisez @BotFather et la commande / newbot. En conséquence, le jeton nécessaire pour vous connecter à votre bot vous sera retourné. Verrouillez-le également.
Framework sans serveur
Pour installer Serverless Framework, vous aurez besoin d'un compte sur https://serverless.com/ .
Après avoir terminé l'enregistrement, nous procéderons à l'installation sur notre poste de travail. Node.js 6e et supérieur sera requis.
sudo apt-get -y install nodejs
Pour assurer le lancement correct dans notre environnement, nous suivons les étapes recommandées:
mkdir ~/.npm-global export PATH=~/.npm-global/bin:$PATH source ~/.profile npm config set prefix '~/.npm-global'
Ajoutez également:
~/.npm-global/bin:$PATH
dans le fichier / etc / environment.
Maintenant, mettez Serverless:
npm install -g serverless
Aws
Eh bien, il est temps de passer à l'interface AWS et d'ajouter un nom de domaine. Nous créons une zone AWS Route 53, un enregistrement DNS et un certificat SSL pour cela.
De plus, vous avez besoin de l'ELB, que nous créons dans le service EC2 -> Load Balancers. Soit dit en passant, lors de la création d'un ELB, vous devez suivre toutes les étapes de l'assistant, en indiquant le certificat créé.
Quant à l'équilibreur, vous pouvez le créer via l'AWS CLI à l'aide de la commande suivante:
aws elb create-load-balancer --load-balancer-name my-load-balancer --listeners "Protocol=HTTP,LoadBalancerPort=80,InstanceProtocol=HTTP,InstancePort=80" "Protocol=HTTPS,LoadBalancerPort=443,InstanceProtocol=HTTP,InstancePort=80,SSLCertificateId=arn:aws:iam::123456789012:server-certificate/my-server-cert" --subnets subnet-15aaab61 --security-groups sg-a61988c3
Un équilibreur sera nécessaire après le premier déploiement. Dans ce cas, vous devez lui envoyer des demandes à notre domaine. Pour l'implémenter, dans les paramètres de l'enregistrement DNS (champ "Alias target"), commencez à saisir le nom de l'ELB créé. En conséquence, vous verrez une liste déroulante, il reste donc à sélectionner l'entrée souhaitée et à l'enregistrer.

Maintenant, allez au code.
Écrire un code
Nous utiliserons Bref pour écrire le code. Comme mentionné précédemment, cette bibliothèque est installée à l'aide de composer, donc le code sera compatible avec n'importe quel framework. Soit dit en passant, les développeurs ont déjà décrit le processus d'utilisation de Bref avec Laravel et Symfony . Mais il est conseillé pour nous de travailler sur le PHP "nu" - cela aidera à mieux comprendre l'essence.
Nous commençons par les dépendances:
{ "require": { "php": ">=7.2", "bref/bref": "^0.5.9", "telegram-bot/api": "*" }, "autoload": { "psr-4": { "App\": "src/" } } }
Nous allons écrire en PHP 7.2 et supérieur, et pour travailler avec Telegram, ce shell pour l'API nous convient - https://github.com/TelegramBot/Api . Quant au code lui-même, il sera placé dans le répertoire src.
Ainsi, l'environnement sans serveur passe par une boîte de dialogue de console. Une application HTTP est requise, et du point de vue de Lambda, cela signifie que les appels de script seront exécutés de la même manière que Nginx. L'interprétation sera effectuée par PHP-FPM. En général, cela ressemble plus à un appel de script de console standard. C'est un point important, car sans prendre en compte cette fonctionnalité, nous ne pourrons pas appeler de scripts via HTTP.
Nous réalisons:
vendor/bin/bref init
Dans la boîte de dialogue, sélectionnez l'élément «Application HTTP» et n'oubliez pas de spécifier la région, car l'application doit fonctionner dans la même région dans laquelle fonctionne l'équilibreur.
Après l'initialisation, 2 nouveaux fichiers apparaîtront:
index.php - le fichier appelé;
serverless.yml - fichier de configuration de déploiement.
Le dossier .serverless devra être immédiatement ajouté au .gitignore (il apparaîtra après la 1ère tentative de déploiement).
Une fois que nous avons une application Web, nous déposons index.php dans le dossier public, basculant immédiatement vers serverless.yml. Voici à quoi cela pourrait ressembler dans notre implémentation:
# lambda- service: app # provider: name: aws # ! region: eu-central-1 # runtime: provided # , bref 1024. memoryLimit: 256 # stage: dev # environment: BOT_TOKEN: ${ssm:/app/bot-token} # bref plugins: - ./vendor/bref/bref # Lambda- functions: # php-api-dev # service-function-stage api: handler: public/index.php description: '' # in seconds (API Gateway has a timeout of 29 seconds) timeout: 28 layers: - ${bref:layer.php-73-fpm} # API Gateway events: - http: 'ANY /' - http: 'ANY /{proxy+}' # environment: MY_VARIABLE: ${ssm:/app/my_variable}
Analysons maintenant les lignes non évidentes. Nous avons surtout besoin de variables d'environnement. Nous ne voulons pas coder en dur les connexions aux bases de données, les API externes, etc. Si nous nous connectons à Telegram, nous aurons notre propre jeton, qui est reçu de BotFather. Et il n'est pas recommandé de stocker ce jeton dans serverless.yml, il est donc préférable de l'envoyer vers le stockage AWS ssm:
aws ssm put-parameter --region eu-central-1 --name '/app/my_variable' --type String --value '___BOTFATHER'
Soit dit en passant, nous en parlons dans la configuration.
Ces variables sont disponibles en tant que variables d'environnement, et vous pouvez y accéder en PHP en utilisant la fonction getenv. Si nous parlons de notre exemple, gardons le jeton de bot dans la portée globale pour plus de simplicité. Nous pouvons également transférer le jeton dans la portée d'une seule fonction, et l'appel lui-même ne changera pas de cela.
Continuons. Créons maintenant une classe BotApp simple - elle sera chargée de générer une réponse pour le bot et répondra aux commandes. Les développeurs de télégrammes recommandent d'ajouter la prise en charge des commandes / help et / start pour tous les bots. Ajoutons une autre commande pour le plaisir. La classe elle-même est assez simple et permet d'implémenter le contrôleur Front dans index.php sans charger le fichier d'appel lui-même. Pour obtenir une logique plus complexe, l'architecture doit être développée et compliquée.
<?php namespace App; use TelegramBot\Api\Client; use Telegram\Bot\Objects\Update; class BotApp { function run(): void{ $token = getenv('BOT_TOKEN'); $bot = new Client($token); // start $bot->command('start', function ($message) use ($bot) { $answer = ' !'; $bot->sendMessage($message->getChat()->getId(), $answer); }); // $bot->command('help', function ($message) use ($bot) { $answer = ': /help - '; $bot->sendMessage($message->getChat()->getId(), $answer); }); // $bot->command('hello', function ($message) use ($bot) { $answer = '-, - , Serverless '; $bot->sendMessage($message->getChat()->getId(), $answer); }); $bot->run(); } }
Et voici la liste de index.php:
<?php require_once('../vendor/autoload.php'); use App\BotApp; try{ $botApp = new BotApp(); $botApp->run(); } catch (Exception $e){ echo $e->getMessage(); print_r($e->getTrace(), 1); }
Cela peut sembler étrange, mais tout est prêt pour que nous partions en production. Faisons-le en exécutant la commande dans le dossier serverless.yml:
sls deploy
En mode normal, sans serveur emballera les fichiers dans des archives zip, créera un compartiment S3 où les placer, puis créera ou mettra à jour l'application AWS attachée à Lambda, et placera le code et le runtime dans une couche distincte.
Lors du 1er lancement, l'API Gateway sera créée (nous l'avons laissée pour faciliter le test des appels, mais il est alors conseillé de la supprimer). Vous devrez également configurer l'appel Lambda via ELB, pour lequel nous sélectionnons «Ajouter un déclencheur» dans la fenêtre de contrôle des fonctions et sélectionnez «Application Load Balancer» dans la liste déroulante. Vous devrez spécifier l'ELB créé précédemment, définir la connexion via HTTPS, laisser l'hôte vide et, dans Path, spécifier le chemin que Lambda appellera (par exemple, / lambda / mytgbot). Par conséquent, votre Lambda sera disponible à l'URL avec le chemin spécifié.
Vous pouvez maintenant enregistrer la partie réponse du bot dans Telegram afin que le messager comprenne où obtenir les messages. Pour ce faire, appelez l'URL suivante dans le navigateur, mais n'oubliez pas d'y substituer vos propres paramètres:
https://api.telegram.org/bot_/setWebhook?url=https://my-elb-host.com/lambda/mytgbot
En conséquence, l'API retournera «OK», après quoi le bot sera disponible.

Test du bot sur les locales
Le bot peut être testé avant le déploiement. Le fait est que le Serverless Framework prend en charge le lancement sur les locales en utilisant des conteneurs Docker pour cela. Commande d'appel:
sls invoke local --docker -f myFunction
N'oubliez pas que nous avons utilisé des variables d'environnement, donc lors de l'appel, elles doivent également être définies au format:
sls invoke local --docker -f myFunction --env VAR1=val1
Journaux
Par défaut, la sortie de l'appel sera enregistrée dans CloudWatch - elle est disponible dans le panneau de surveillance de la fonction Lambda correspondante. Ici vous pouvez lire les traces d'appels en cas de vidage côté PHP. De plus, vous pouvez connecter des services de surveillance avancés, mais ils coûteront quelques centimes de plus chaque mois.
Total
En conséquence, nous avons obtenu une solution assez rapide, flexible, évolutive et relativement peu coûteuse. Oui, Lambda ne gagne pas toujours par rapport aux VM et conteneurs standard, mais il y a des situations où l'application Serverless aide à «tirer» rapidement et efficacement. Et l'exemple du bot créé le démontre.
Documents utiles sur le sujet: