
Il y a quelques années, Kubernetes a
déjà été
discuté sur le blog officiel de GitHub. Depuis lors, il est devenu la technologie standard pour le déploiement de services. Kubernetes gère désormais une partie importante des services internes et publics. Au fur et à mesure que nos clusters se sont développés et que les exigences de performances sont devenues plus strictes, nous avons commencé à remarquer que certains services sur Kubernetes affichent sporadiquement des retards qui ne peuvent être expliqués par la charge de l'application elle-même.
En fait, dans les applications, un retard de réseau aléatoire allant jusqu'à 100 ms ou plus se produit, ce qui entraîne des délais d'attente ou des tentatives. Il était prévu que les services seraient en mesure de répondre aux demandes beaucoup plus rapidement que 100 ms. Mais cela n'est pas possible si la connexion elle-même prend autant de temps. Séparément, nous avons observé des requêtes MySQL très rapides, qui devaient prendre des millisecondes, et MySQL vraiment géré en millisecondes, mais du point de vue de l'application demandeuse, la réponse a pris 100 ms ou plus.
Il est immédiatement devenu clair que le problème se produit uniquement lors de la connexion à l'hôte Kubernetes, même si l'appel provenait de l'extérieur de Kubernetes. Le moyen le plus simple de reproduire le problème est le test
Vegeta , qui s'exécute à partir de n'importe quel hôte interne, teste le service Kubernetes sur un port spécifique et enregistre sporadiquement un délai important. Dans cet article, nous verrons comment nous avons réussi à rechercher la cause de ce problème.
Élimine la complexité inutile de la chaîne de défaillance
Après avoir reproduit le même exemple, nous avons voulu affiner le centre du problème et supprimer les couches supplémentaires de complexité. Au départ, il y avait trop d'éléments dans le ruisseau entre Vegeta et les gousses sur Kubernetes. Pour identifier un problème de réseau plus profond, vous devez en exclure certains.
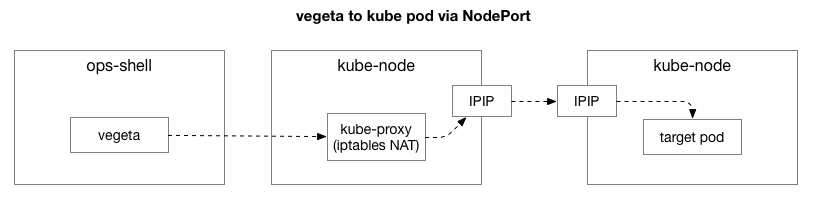
Le client (Vegeta) crée une connexion TCP avec n'importe quel nœud du cluster. Kubernetes agit comme un réseau de superposition (au-dessus du réseau de centre de données existant) qui utilise
IPIP , c'est-à-dire qui encapsule les paquets IP du réseau de superposition à l'intérieur des paquets IP du centre de données. Lorsqu'il est connecté au premier nœud, la
traduction d' adresse réseau NAT (
Network Address Translation ) est effectuée avec une surveillance d'état pour convertir l'adresse IP et le port de l'hôte Kubernetes en adresse IP et port sur le réseau de superposition (en particulier, le pod avec l'application). Pour les paquets reçus, la séquence inverse est effectuée. Il s'agit d'un système complexe avec de nombreux états et de nombreux éléments qui sont constamment mis à jour et modifiés au fur et à mesure du déploiement et du déplacement des services.
L'utilitaire
tcpdump dans le test Vegeta donne un délai pendant la négociation TCP (entre SYN et SYN-ACK). Pour supprimer cette complexité inutile, vous pouvez utiliser
hping3 pour de simples «pings» avec les packages SYN. Vérifiez s'il y a un retard dans le paquet de réponse, puis réinitialisez la connexion. Nous pouvons filtrer les données en n'incluant que les paquets de plus de 100 ms, et obtenir une option plus simple pour reproduire le problème que le test complet du réseau de niveau 7 dans Vegeta. Voici les «pings» de l'hôte Kubernetes utilisant TCP SYN / SYN-ACK sur le «port» hôte du service (30927) avec un intervalle de 10 ms, filtré par les réponses les plus lentes:
theojulienne@shell ~ $ sudo hping3 172.16.47.27 -S -p 30927 -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}\.'
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=1485 win=29200 rtt=127.1 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=1486 win=29200 rtt=117.0 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=1487 win=29200 rtt=106.2 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=1488 win=29200 rtt=104.1 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=5024 win=29200 rtt=109.2 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=5231 win=29200 rtt=109.2 msPeut immédiatement faire la première observation. Les numéros de série et les horaires montrent qu'il ne s'agit pas d'une congestion ponctuelle. Le retard s'accumule souvent et est finalement traité.
Ensuite, nous voulons savoir quels composants peuvent être impliqués dans l'apparition de congestion. Peut-être que ce sont quelques-unes des centaines de règles iptables en NAT? Ou quelques problèmes avec le tunnel IPIP sur le réseau? Une façon de le vérifier consiste à vérifier chaque étape du système en l'excluant. Que se passe-t-il si vous supprimez la logique NAT et pare-feu, ne laissant qu'une partie de IPIP:
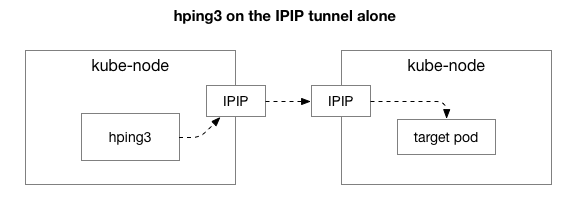
Heureusement, Linux facilite l'accès direct à la couche de superposition IP si la machine est sur le même réseau:
theojulienne@kube-node-client ~ $ sudo hping3 10.125.20.64 -S -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}\.'
len=40 ip=10.125.20.64 ttl=64 DF id=0 sport=0 flags=RA seq=7346 win=0 rtt=127.3 ms
len=40 ip=10.125.20.64 ttl=64 DF id=0 sport=0 flags=RA seq=7347 win=0 rtt=117.3 ms
len=40 ip=10.125.20.64 ttl=64 DF id=0 sport=0 flags=RA seq=7348 win=0 rtt=107.2 msA en juger par les résultats, le problème persiste! Cela exclut iptables et NAT. Le problème est donc dans TCP? Voyons comment va le ping ICMP:
theojulienne@kube-node-client ~ $ sudo hping3 10.125.20.64 --icmp -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}\.'
len=28 ip=10.125.20.64 ttl=64 id=42594 icmp_seq=104 rtt=110.0 ms
len=28 ip=10.125.20.64 ttl=64 id=49448 icmp_seq=4022 rtt=141.3 ms
len=28 ip=10.125.20.64 ttl=64 id=49449 icmp_seq=4023 rtt=131.3 ms
len=28 ip=10.125.20.64 ttl=64 id=49450 icmp_seq=4024 rtt=121.2 ms
len=28 ip=10.125.20.64 ttl=64 id=49451 icmp_seq=4025 rtt=111.2 ms
len=28 ip=10.125.20.64 ttl=64 id=49452 icmp_seq=4026 rtt=101.1 ms
len=28 ip=10.125.20.64 ttl=64 id=50023 icmp_seq=4343 rtt=126.8 ms
len=28 ip=10.125.20.64 ttl=64 id=50024 icmp_seq=4344 rtt=116.8 ms
len=28 ip=10.125.20.64 ttl=64 id=50025 icmp_seq=4345 rtt=106.8 ms
len=28 ip=10.125.20.64 ttl=64 id=59727 icmp_seq=9836 rtt=106.1 msLes résultats montrent que le problème n'a pas disparu. C'est peut-être un tunnel IPIP? Simplifions le test:
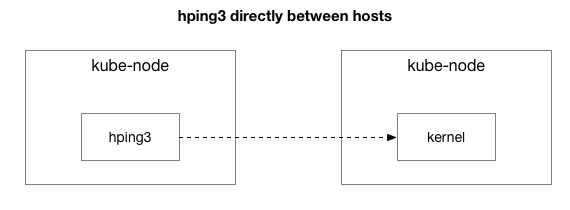
Tous les paquets sont-ils envoyés entre ces deux hôtes?
theojulienne@kube-node-client ~ $ sudo hping3 172.16.47.27 --icmp -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}\.'
len=46 ip=172.16.47.27 ttl=61 id=41127 icmp_seq=12564 rtt=140.9 ms
len=46 ip=172.16.47.27 ttl=61 id=41128 icmp_seq=12565 rtt=130.9 ms
len=46 ip=172.16.47.27 ttl=61 id=41129 icmp_seq=12566 rtt=120.8 ms
len=46 ip=172.16.47.27 ttl=61 id=41130 icmp_seq=12567 rtt=110.8 ms
len=46 ip=172.16.47.27 ttl=61 id=41131 icmp_seq=12568 rtt=100.7 ms
len=46 ip=172.16.47.27 ttl=61 id=9062 icmp_seq=31443 rtt=134.2 ms
len=46 ip=172.16.47.27 ttl=61 id=9063 icmp_seq=31444 rtt=124.2 ms
len=46 ip=172.16.47.27 ttl=61 id=9064 icmp_seq=31445 rtt=114.2 ms
len=46 ip=172.16.47.27 ttl=61 id=9065 icmp_seq=31446 rtt=104.2 msNous avons simplifié la situation pour que deux hôtes Kubernetes s'envoient n'importe quel paquet, même un ping ICMP. Ils voient toujours un retard si l'hôte cible est «mauvais» (certains pires que d'autres).
Maintenant, la dernière question: pourquoi le retard ne se produit-il que sur les serveurs de nœuds de kube? Et cela se produit-il lorsque le noeud kube est l'expéditeur ou le destinataire? Heureusement, cela est également assez facile à comprendre en envoyant un paquet à partir d'un hôte en dehors de Kubernetes, mais avec le même destinataire "mauvais connu". Comme vous pouvez le constater, le problème n'a pas disparu:
theojulienne@shell ~ $ sudo hping3 172.16.47.27 -p 9876 -S -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}\.'
len=46 ip=172.16.47.27 ttl=61 DF id=0 sport=9876 flags=RA seq=312 win=0 rtt=108.5 ms
len=46 ip=172.16.47.27 ttl=61 DF id=0 sport=9876 flags=RA seq=5903 win=0 rtt=119.4 ms
len=46 ip=172.16.47.27 ttl=61 DF id=0 sport=9876 flags=RA seq=6227 win=0 rtt=139.9 ms
len=46 ip=172.16.47.27 ttl=61 DF id=0 sport=9876 flags=RA seq=7929 win=0 rtt=131.2 msEnsuite, nous effectuons les mêmes requêtes depuis le nœud kube source précédent vers l'hôte externe (ce qui exclut l'hôte d'origine, car le ping inclut à la fois les composants RX et TX):
theojulienne@kube-node-client ~ $ sudo hping3 172.16.33.44 -p 9876 -S -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}\.'
^C
--- 172.16.33.44 hping statistic ---
22352 packets transmitted, 22350 packets received, 1% packet loss
round-trip min/avg/max = 0.2/7.6/1010.6 msAprès avoir examiné les captures de paquets retardées, nous avons obtenu des informations supplémentaires. En particulier, que l'expéditeur (ci-dessous) voit ce délai, mais le récepteur (ci-dessus) ne le voit pas - voir la colonne Delta (en secondes):

De plus, si vous regardez la différence dans l'ordre des paquets TCP et ICMP (par numéros de séquence) du côté destinataire, les paquets ICMP arrivent toujours dans la même séquence dans laquelle ils ont été envoyés, mais avec un timing différent. Dans le même temps, les paquets TCP alternent parfois et certains d'entre eux sont bloqués. En particulier, si nous examinons les ports des paquets SYN, du côté émetteur, ils vont dans l'ordre, mais pas du côté destinataire.
Il existe une différence subtile dans la façon dont
les cartes réseau des serveurs modernes (comme dans notre centre de données) traitent les paquets contenant TCP ou ICMP. Lorsqu'un paquet arrive, l'adaptateur réseau «le hache sur la connexion», c'est-à-dire qu'il essaie de rompre les connexions à tour de rôle et d'envoyer chaque file d'attente à un cœur de processeur distinct. Pour TCP, ce hachage comprend à la fois l'adresse IP source et de destination et le port. En d'autres termes, chaque connexion est hachée (potentiellement) différemment. Pour ICMP, seules les adresses IP sont hachées, car il n'y a pas de ports.
Autre nouvelle observation: pendant cette période, nous constatons des retards ICMP sur toutes les communications entre les deux hôtes, mais pas TCP. Cela nous indique que la raison est probablement due au hachage des files d'attente RX: il est presque certain que l'encombrement se produit dans le traitement des paquets RX, plutôt que dans l'envoi de réponses.
Cela exclut l'envoi de paquets de la liste des raisons possibles. Nous savons maintenant que le problème du traitement des paquets est du côté de la réception sur certains serveurs de nœuds de kube.
Comprendre le traitement des packages dans le noyau Linux
Pour comprendre pourquoi le problème se produit avec le destinataire sur certains serveurs de nœuds de cube, voyons comment le noyau Linux gère les packages.
Revenant à l'implémentation traditionnelle la plus simple, la carte réseau reçoit le paquet et envoie une
interruption au noyau Linux, qui est le paquet qui doit être traité. Le noyau arrête une autre opération, bascule le contexte vers le gestionnaire d'interruption, traite le package, puis revient aux tâches en cours.

Ce changement de contexte est lent: il n'était peut-être pas perceptible sur les cartes réseau de 10 mégaoctets dans les années 1990, mais sur les cartes 10G modernes avec un débit maximal de 15 millions de paquets par seconde, chaque cœur d'un petit serveur à huit cœurs peut être interrompu des millions de fois par seconde.
Afin de ne pas gérer constamment la gestion des interruptions, Linux a ajouté il y a de nombreuses années
NAPI : une API réseau que tous les pilotes modernes utilisent pour augmenter les performances à des vitesses élevées. À basse vitesse, le noyau accepte toujours les interruptions de la carte réseau à l'ancienne. Dès qu'un nombre suffisant de paquets arrive et dépasse le seuil, le noyau désactive les interruptions et commence à interroger la carte réseau et à prendre des paquets par lots. Le traitement est effectué dans softirq, c'est-à-dire dans le
contexte des interruptions logicielles après les appels système et des interruptions matérielles lorsque le noyau (contrairement à l'espace utilisateur) est déjà en cours d'exécution.
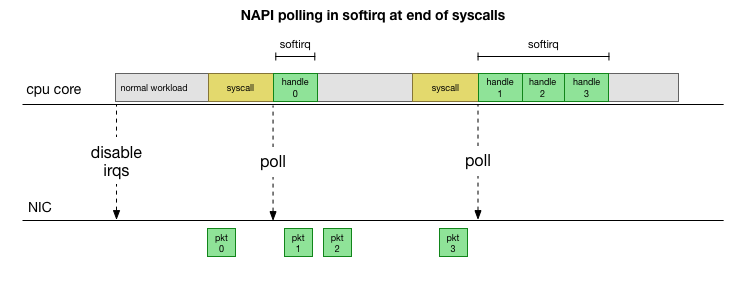
C'est beaucoup plus rapide, mais cause un problème différent. S'il y a trop de paquets, tout le temps qu'il faut pour traiter les paquets de la carte réseau et les processus de l'espace utilisateur n'ont pas le temps de vider réellement ces files d'attente (lecture à partir des connexions TCP, etc.). À la fin, les files d'attente se remplissent et nous commençons à abandonner les paquets. En essayant de trouver un équilibre, le noyau établit un budget pour le nombre maximum de paquets traités dans le contexte softirq. Une fois ce budget dépassé, un thread
ksoftirqd séparé
ksoftirqd (vous en verrez un en
ps pour chaque cœur), qui traite ces softirqs en dehors du chemin normal de syscall / interruption. Ce thread est planifié à l'aide d'un planificateur de processus standard qui tente de répartir équitablement les ressources.
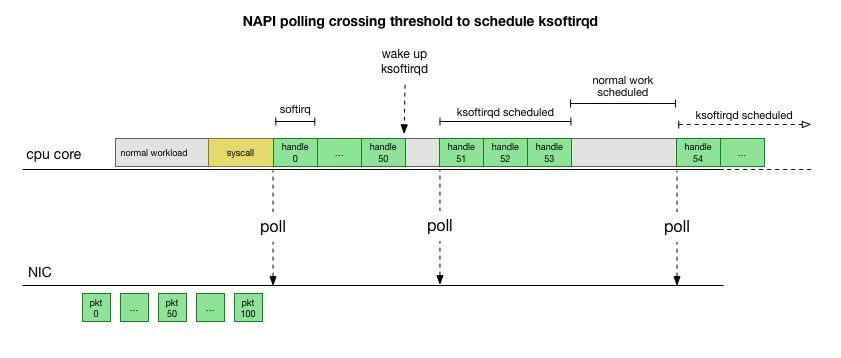
Après avoir examiné comment le noyau traite les paquets, vous pouvez voir qu'il existe une certaine probabilité de congestion. Si les appels softirq sont reçus moins fréquemment, les paquets devront attendre un certain temps avant d'être traités dans la file d'attente RX de la carte réseau. Cela est peut-être dû à une tâche bloquant le cœur du processeur, ou quelque chose d'autre empêche le noyau de démarrer softirq.
Nous limitons le traitement au noyau ou à la méthode
Les retards Softirq ne sont qu'une hypothèse. Mais cela a du sens et nous savons que nous voyons quelque chose de très similaire. Par conséquent, l'étape suivante consiste à confirmer cette théorie. Et si cela est confirmé, trouvez la raison des retards.
Retour à nos packages lents:
len=46 ip=172.16.53.32 ttl=61 id=29573 icmp_seq=1953 rtt=99.3 ms
len=46 ip=172.16.53.32 ttl=61 id=29574 icmp_seq=1954 rtt=89.3 ms
len=46 ip=172.16.53.32 ttl=61 id=29575 icmp_seq=1955 rtt=79.2 ms
len=46 ip=172.16.53.32 ttl=61 id=29576 icmp_seq=1956 rtt=69.1 ms
len=46 ip=172.16.53.32 ttl=61 id=29577 icmp_seq=1957 rtt=59.1 ms
len=46 ip=172.16.53.32 ttl=61 id=29790 icmp_seq=2070 rtt=75.7 ms
len=46 ip=172.16.53.32 ttl=61 id=29791 icmp_seq=2071 rtt=65.6 ms
len=46 ip=172.16.53.32 ttl=61 id=29792 icmp_seq=2072 rtt=55.5 msComme indiqué précédemment, ces paquets ICMP sont hachés dans une seule file d'attente NIC RX et traités par un seul cœur de processeur. Si nous voulons comprendre comment fonctionne Linux, il est utile de savoir où (sur quel cœur de processeur) et comment (softirq, ksoftirqd) ces packages sont traités pour suivre le processus.
Il est maintenant temps d'utiliser des outils qui permettent une surveillance en temps réel du noyau Linux. Ici, nous avons utilisé
bcc . Cette boîte à outils vous permet d'écrire de petits programmes C qui interceptent des fonctions arbitraires dans le noyau et les événements de tampon dans un programme Python de l'espace utilisateur qui peut les traiter et vous renvoyer le résultat. Les crochets pour les fonctions arbitraires dans le noyau sont complexes, mais l'utilitaire est conçu pour une sécurité maximale et est conçu pour suivre précisément ces problèmes de production qui ne sont pas faciles à reproduire dans un environnement de test ou de développement.
Le plan ici est simple: nous savons que le noyau traite ces pings ICMP, donc nous
accrochons la fonction de noyau
icmp_echo , qui reçoit le paquet ICMP de demande d'écho entrant et initie l'envoi de la réponse ICMP de réponse d'écho. Nous pouvons identifier le package en augmentant le nombre icmp_seq, qui montre
hping3 ci-dessus.
Le code du
script Cci semble compliqué, mais il n'est pas aussi effrayant qu'il n'y paraît. La fonction
icmp_echo passe la
struct sk_buff *skb : c'est le paquet avec la requête "echo request". Nous pouvons le suivre, extraire la séquence
echo.sequence (qui correspond à
icmp_seq partir de hping3
) et l'envoyer à l'espace utilisateur. Il est également pratique de capturer le nom / identificateur de processus actuel. Voici les résultats que nous voyons directement lors du traitement des paquets par le noyau:
NOM DU PROCESSUS TGID PID ICMP_SEQ
0 0 swapper / 11,770
0 0 swapper / 11,771
0 0 swapper / 11 772
0 0 swapper / 11 773
0 0 swapper / 11,774
20041 20086 prometheus 775
0 0 swapper / 11,776
0 0 swapper / 11,777
0 0 swapper / 11 778
4512 4542 rayons-rapport-s 779
Ici, il convient de noter que dans le contexte de
softirq processus qui ont effectué des appels système apparaîtront comme des «processus», bien qu'en fait ce noyau traite en toute sécurité les paquets dans le contexte du noyau.
Avec cet outil, nous pouvons établir la connexion de processus spécifiques avec des packages spécifiques qui montrent un retard dans
hping3 . Nous faisons un simple
grep sur cette capture pour des valeurs
icmp_seq spécifiques. Les paquets correspondant aux valeurs icmp_seq ci-dessus ont été marqués avec leur RTT, que nous avons observé ci-dessus (entre parenthèses sont les valeurs RTT attendues pour les paquets que nous avons filtrés en raison de valeurs RTT inférieures à 50 ms):
NOM DU PROCESSUS TGID PID ICMP_SEQ ** RTT
-
10137 10436 cadvisor 1951
10137 10436 cadvisor 1952
76 76 ksoftirqd / 11 1953 ** 99ms
76 76 ksoftirqd / 11 1954 ** 89ms
76 76 ksoftirqd / 11 1955 ** 79ms
76 76 ksoftirqd / 11 1956 ** 69ms
76 76 ksoftirqd / 11 1957 ** 59 ms
76 76 ksoftirqd / 11 1958 ** (49 ms)
76 76 ksoftirqd / 11 1959 ** (39 ms)
76 76 ksoftirqd / 11 1960 ** (29 ms)
76 76 ksoftirqd / 11 1961 ** (19 ms)
76 76 ksoftirqd / 11 1962 ** (9 ms)
-
10137 10436 cadvisor 2068
10137 10436 cadvisor 2069
76 76 ksoftirqd / 11 2070 ** 75 ms
76 76 ksoftirqd / 11 2071 ** 65ms
76 76 ksoftirqd / 11 2072 ** 55 ms
76 76 ksoftirqd / 11 2073 ** (45 ms)
76 76 ksoftirqd / 11 2074 ** (35 ms)
76 76 ksoftirqd / 11 2075 ** (25 ms)
76 76 ksoftirqd / 11 2076 ** (15 ms)
76 76 ksoftirqd / 11 2077 ** (5 ms)
Les résultats nous disent quelques choses. Tout d'abord, le contexte
ksoftirqd/11 gère tous ces packages. Cela signifie que pour cette paire particulière de machines, les paquets ICMP ont été hachés sur le cœur 11 à la réception. Nous constatons également qu'à chaque embouteillage, des paquets sont traités dans le cadre de l'
cadvisor système
cadvisor . Ensuite,
ksoftirqd prend la tâche et remplit la file d'attente accumulée: exactement le nombre de paquets qui se sont accumulés après
cadvisor .
Le fait qu'un
cadvisor travaille toujours juste avant cela implique son implication dans le problème. Ironiquement, l'objectif de
cadvisor est «d'analyser l'utilisation des ressources et les caractéristiques de performance des conteneurs en cours d'exécution», plutôt que de causer ce problème de performance.
Comme pour d'autres aspects de la manutention des conteneurs, ce sont tous des outils extrêmement avancés à partir desquels des problèmes de performances peuvent être attendus dans certaines circonstances imprévues.
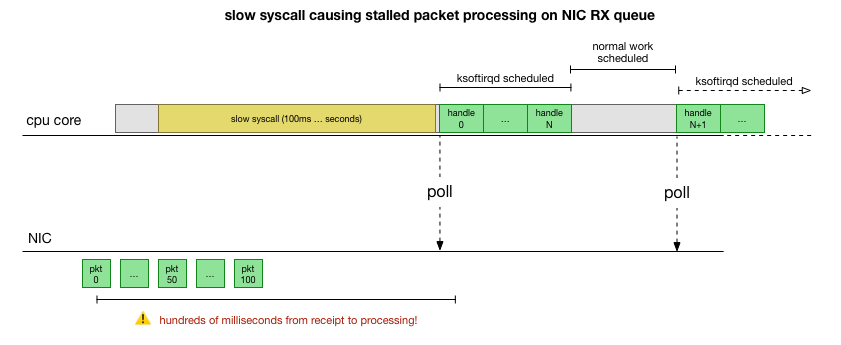
Que fait cadvisor pour ralentir la file d'attente des paquets?
Maintenant, nous avons une assez bonne compréhension de la façon dont la panne se produit, quel processus la cause et sur quel processeur. Nous voyons qu'en raison d'un verrouillage dur, le noyau Linux n'a pas le temps de planifier
ksoftirqd . Et nous voyons que les colis sont traités dans le cadre de
cadvisor . Il est logique de supposer que
cadvisor démarre un appel système lent, après quoi tous les paquets accumulés à ce moment sont traités:
C'est une théorie, mais comment la tester? Ce que nous pouvons faire, c'est suivre le fonctionnement du cœur de processeur tout au long de ce processus, trouver le point où le budget est dépassé par le nombre de paquets et ksoftirqd est appelé, puis regarder un peu plus tôt - ce qui fonctionnait exactement sur le cœur de processeur juste avant ce moment. C'est comme une radiographie d'un CPU toutes les quelques millisecondes. Cela ressemblera à ceci:
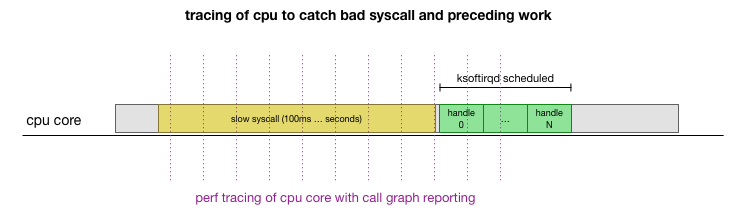
Idéalement, tout cela peut être fait avec les outils existants. Par exemple,
perf record vérifie le cœur de processeur spécifié avec la fréquence indiquée et peut générer un calendrier d'appels vers un système en cours d'exécution, y compris à la fois l'espace utilisateur et le noyau Linux. Vous pouvez prendre cet enregistrement et le traiter à l'aide d'un petit fork du programme
FlameGraph de Brendan Gregg, qui préserve l'ordre de trace de la pile. Nous pouvons enregistrer des traces de pile sur une ligne toutes les 1 ms, puis sélectionner et enregistrer l'échantillon pendant 100 millisecondes avant que
ksoftirqd dans la trace:
# record 999 times a second, or every 1ms with some offset so not to align exactly with timers
sudo perf record -C 11 -g -F 999
# take that recording and make a simpler stack trace.
sudo perf script 2>/dev/null | ./FlameGraph/stackcollapse-perf-ordered.pl | grep ksoftir -B 100Voici les résultats:
( , )
cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_iter cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages ksoftirqd/11;ret_from_fork;kthread;kthread;smpboot_thread_fn;smpboot_thread_fn;run_ksoftirqd;__do_softirq;net_rx_action;ixgbe_poll;ixgbe_clean_rx_irq;napi_gro_receive;netif_receive_skb_internal;inet_gro_receive;bond_handle_frame;__netif_receive_skb_core;ip_rcv_finish;ip_rcv;ip_forward_finish;ip_forward;ip_finish_output;nf_iterate;ip_output;ip_finish_output2;__dev_queue_xmit;dev_hard_start_xmit;ipip_tunnel_xmit;ip_tunnel_xmit;iptunnel_xmit;ip_local_out;dst_output;__ip_local_out;nf_hook_slow;nf_iterate;nf_conntrack_in;generic_packet;ipt_do_table;set_match_v4;ip_set_test;hash_net4_kadt;ixgbe_xmit_frame_ring;swiotlb_dma_mapping_error;hash_net4_test ksoftirqd/11;ret_from_fork;kthread;kthread;smpboot_thread_fn;smpboot_thread_fn;run_ksoftirqd;__do_softirq;net_rx_action;gro_cell_poll;napi_gro_receive;netif_receive_skb_internal;inet_gro_receive;__netif_receive_skb_core;ip_rcv_finish;ip_rcv;ip_forward_finish;ip_forward;ip_finish_output;nf_iterate;ip_output;ip_finish_output2;__dev_queue_xmit;dev_hard_start_xmit;dev_queue_xmit_nit;packet_rcv;tpacket_rcv;sch_direct_xmit;validate_xmit_skb_list;validate_xmit_skb;netif_skb_features;ixgbe_xmit_frame_ring;swiotlb_dma_mapping_error;__dev_queue_xmit;dev_hard_start_xmit;__bpf_prog_run;__bpf_prog_runIl y a beaucoup de choses ici, mais l'essentiel est que nous trouvions le modèle «cadvisor avant ksoftirqd» que nous avons vu plus tôt dans le traceur ICMP. Qu'est-ce que cela signifie?
Chaque ligne est une trace du CPU à un moment donné. Chaque appel sur la pile d'une ligne est séparé par un point-virgule. Au milieu des lignes, nous voyons syscall appelé:
read(): .... ;do_syscall_64;sys_read; ... read(): .... ;do_syscall_64;sys_read; ... Ainsi, cadvisor passe beaucoup de temps sur l'appel système
read() lié aux fonctions
mem_cgroup_* (haut de la pile d'appels / fin de ligne).
Dans la trace des appels, il n'est pas pratique de voir exactement ce qui est lu, alors exécutez
strace et voyez ce que fait cadvisor, et recherchez les appels système de plus de 100 ms:
theojulienne@kube-node-bad ~ $ sudo strace -p 10137 -T -ff 2>&1 | egrep '<0\.[1-9]'
[pid 10436] <... futex resumed> ) = 0 <0.156784>
[pid 10432] <... futex resumed> ) = 0 <0.258285>
[pid 10137] <... futex resumed> ) = 0 <0.678382>
[pid 10384] <... futex resumed> ) = 0 <0.762328>
[pid 10436] <... read resumed> "cache 154234880\nrss 507904\nrss_h"..., 4096) = 658 <0.179438>
[pid 10384] <... futex resumed> ) = 0 <0.104614>
[pid 10436] <... futex resumed> ) = 0 <0.175936>
[pid 10436] <... read resumed> "cache 0\nrss 0\nrss_huge 0\nmapped_"..., 4096) = 577 <0.228091>
[pid 10427] <... read resumed> "cache 0\nrss 0\nrss_huge 0\nmapped_"..., 4096) = 577 <0.207334>
[pid 10411] <... epoll_ctl resumed> ) = 0 <0.118113>
[pid 10382] <... pselect6 resumed> ) = 0 (Timeout) <0.117717>
[pid 10436] <... read resumed> "cache 154234880\nrss 507904\nrss_h"..., 4096) = 660 <0.159891>
[pid 10417] <... futex resumed> ) = 0 <0.917495>
[pid 10436] <... futex resumed> ) = 0 <0.208172>
[pid 10417] <... futex resumed> ) = 0 <0.190763>
[pid 10417] <... read resumed> "cache 0\nrss 0\nrss_huge 0\nmapped_"..., 4096) = 576 <0.154442>Comme vous pouvez vous y attendre, nous voyons ici des appels
read() . Du contenu des opérations de lecture et du contexte
mem_cgroup ,
mem_cgroup peut voir que ces appels
read() réfèrent au fichier
memory.stat , qui montre l'utilisation de la mémoire et les limitations de cgroup (technologie d'isolation des ressources Docker). L'outil cadvisor interroge ce fichier pour obtenir des informations sur l'utilisation des ressources pour les conteneurs. Vérifions si ce noyau ou ce conseiller fait quelque chose d'inattendu:
theojulienne@kube-node-bad ~ $ time cat /sys/fs/cgroup/memory/memory.stat >/dev/null
real 0m0.153s
user 0m0.000s
sys 0m0.152s
theojulienne@kube-node-bad ~ $Nous pouvons maintenant reproduire le bogue et comprendre que le noyau Linux est confronté à une pathologie.
Qu'est-ce qui rend la lecture si lente?
À ce stade, il est beaucoup plus facile de trouver des messages d'autres utilisateurs sur des problèmes similaires. Il s'est avéré que dans le tracker cadvisor, ce bogue a été signalé comme un
problème d'utilisation excessive du processeur , personne n'a remarqué que le retard était également reflété de manière aléatoire dans la pile du réseau. En effet, il a été remarqué que cadvisor consomme plus de temps processeur que prévu, mais cela n'a pas été accordé beaucoup d'importance, car nos serveurs ont beaucoup de ressources processeur, nous n'avons donc pas étudié attentivement le problème.
Le problème est que les groupes de contrôle (cgroups) prennent en compte l'utilisation de la mémoire à l'intérieur de l'espace de noms (conteneur). Lorsque tous les processus de ce groupe de contrôle se terminent, Docker libère un groupe de contrôle de mémoire. Cependant, la «mémoire» n'est pas seulement une mémoire de processus. Bien que la mémoire de processus elle-même ne soit plus utilisée, il s'avère que le noyau attribue également du contenu mis en cache, comme des denteries et des inodes (métadonnées de répertoire et de fichier), qui sont mis en cache dans le groupe de mémoire. D'après la description du problème:
cgroups zombies: groupes de contrôle dans lesquels il n'y a pas de processus et ils sont supprimés, mais pour lesquels la mémoire est toujours allouée (dans mon cas, à partir du cache dentry, mais elle peut également être allouée à partir du cache de page ou tmpfs).
Le noyau vérifiant toutes les pages du cache lorsque cgroup est libéré peut être très lent, donc le processus paresseux est choisi: attendez que ces pages soient à nouveau demandées, et même lorsque la mémoire est vraiment nécessaire, effacez finalement cgroup. Jusqu'à présent, cgroup est toujours pris en compte lors de la collecte des statistiques.
En termes de performances, ils ont sacrifié la mémoire pour les performances: accélérant le nettoyage initial en raison du fait qu'il reste un peu de mémoire en cache. C'est normal. Lorsque le noyau utilise la dernière partie de la mémoire cache, cgroup est finalement effacé, donc cela ne peut pas être appelé une «fuite». Malheureusement, l'implémentation spécifique du moteur de recherche
memory.stat dans cette version du noyau (4.9), combinée à l'énorme quantité de mémoire sur nos serveurs, conduit au fait qu'il faut beaucoup plus de temps pour restaurer les dernières données mises en cache et effacer les zombies de groupe de contrôle.
Il s'avère qu'il y avait tellement de zombies de groupes de contrôle sur certains de nos nœuds que la lecture et la latence ont dépassé une seconde.
Une solution de contournement pour le problème du conseiller consiste à effacer immédiatement les caches dentiers / inodes dans tout le système, ce qui élimine immédiatement la latence de lecture ainsi que la latence du réseau sur l'hôte, car la suppression du cache inclut les pages mises en cache par zombies cgroup, et elles sont également libérées. Ce n'est pas une solution, mais confirme la cause du problème.
Il s'est avéré que les versions plus récentes du noyau (4.19+) amélioraient les performances de l'appel
memory.stat , donc le passage à ce noyau a résolu le problème. Dans le même temps, nous avions des outils pour détecter les nœuds problématiques dans les clusters Kubernetes, les vidanger avec élégance et redémarrer. Nous avons parcouru tous les clusters, trouvé les nœuds avec un retard suffisamment élevé et les avons redémarrés. Cela nous a donné le temps de mettre à jour le système d'exploitation sur le reste des serveurs.
Pour résumer
Étant donné que ce bogue a arrêté le traitement des files d'attente NIC RX pendant des centaines de millisecondes, il a simultanément provoqué un retard important sur les connexions courtes et un retard au milieu de la connexion, par exemple, entre les requêtes MySQL et les paquets de réponse.
, Kubernetes, . Kubernetes .