
L'entreprise pour laquelle je travaille écrit son propre système de filtrage du trafic et protège l'entreprise avec elle contre les attaques DDoS, les bots, les analyseurs et bien plus encore. Le produit est basé sur un processus tel que le
proxy inverse , à l'aide duquel nous analysons de gros volumes de trafic en temps réel et, au final, n'autorisons que les demandes légitimes des utilisateurs, en filtrant toutes les malveillantes.
La principale caractéristique est que nos services fonctionnent avec un trafic entrant illimité, il est donc très important d'utiliser toutes les ressources des postes de travail aussi efficacement que possible. Une grande expérience du développement en C ++ moderne nous aide à cela, y compris les dernières normes et un ensemble de bibliothèques appelé Boost.
Proxy inverse
Revenons au proxy inverse et voyons comment l'implémenter en C ++ et boost.asio. Tout d'abord, nous avons besoin de deux objets appelés sessions serveur et client. La session serveur établit et maintient une connexion avec le navigateur; la session client établit et maintient une connexion avec le service. Vous aurez également besoin d'un tampon de flux qui encapsule le travail avec de la mémoire à l'intérieur, dans lequel la session serveur lit à partir du socket et à partir de laquelle la session client écrit dans le socket. Des exemples de sessions serveur et client peuvent être trouvés dans la documentation de boost.asio. Vous trouverez ici comment travailler avec le tampon de flux.
Après avoir collecté le prototype de proxy inverse à partir des exemples, il deviendra clair qu'une telle application ne servira probablement pas de trafic entrant illimité. Ensuite, nous commencerons à augmenter la complexité du code. Pensons au multithreading, aux wokers et aux pools pour les contextes io, et bien plus encore. En particulier, sur les optimisations prématurées liées à la copie de mémoire entre les sessions serveur et client.
De quel type de copie de mémoire parlons-nous? Le fait est que lors du filtrage, le trafic n'est pas toujours transmis inchangé. Regardez l'exemple ci-dessous: nous y supprimons un en-tête et en ajoutons deux à la place. Le nombre de requêtes utilisateur sur lesquelles des actions similaires sont effectuées augmente avec la complexité de la logique à l'intérieur du service. Vous ne pouvez en aucun cas copier des données sans réfléchir dans de tels cas! Si seulement 1% de la demande totale change et que 99% restent inchangés, vous devez allouer de la nouvelle mémoire uniquement pour ce 1%. Il vous aidera avec ces boost :: asio :: const_buffer et boost :: asio :: mutable_buffer, à l'aide desquels vous pouvez représenter plusieurs blocs de mémoire continus avec une seule entité.
Demande de l'utilisateur:
Browser -> Proxy: > POST / HTTP/1.1 > User-Agent: curl/7.29.0 > Host: 127.0.0.1:50080 > Accept: */* > Content-Length: 5888903 > Content-Type: application/x-www-form-urlencoded > ... Proxy -> Service: > POST / HTTP/1.1 > User-Agent: curl/7.29.0 > Host: 127.0.0.1:50080 > Accept: */* > Transfer-Encoding: chunked > Content-Type: application/x-www-form-urlencoded > Expect: 100-continue > ... Service -> Proxy: < HTTP/1.1 200 OK Proxy -> Browser < HTTP/1.1 200 OK
Le problème
En conséquence, nous avons obtenu une application prête à l'emploi qui peut bien évoluer et est dotée de toutes sortes d'optimisations. En le lançant en production, nous étions très satisfaits de la durée de son fonctionnement, stable et de qualité.
Au fil du temps, nous avons commencé à avoir de plus en plus de clients, avec l'avènement du trafic qui a également augmenté. À un moment donné, nous avons été confrontés au problème du manque de performances tout en repoussant les grandes attaques. Après avoir analysé le service à l'aide de l'utilitaire
perf , nous avons remarqué que toutes les opérations avec le tas sous charge sont en haut. Ensuite, nous avons recréé une situation similaire sur le circuit de test en utilisant
des réservoirs yandex et des cartouches générés en fonction du trafic réel. Accrochant un service via un
amplificateur, nous avons vu l'image suivante ...
Capture d'écran de l'amplificateur (woslab):
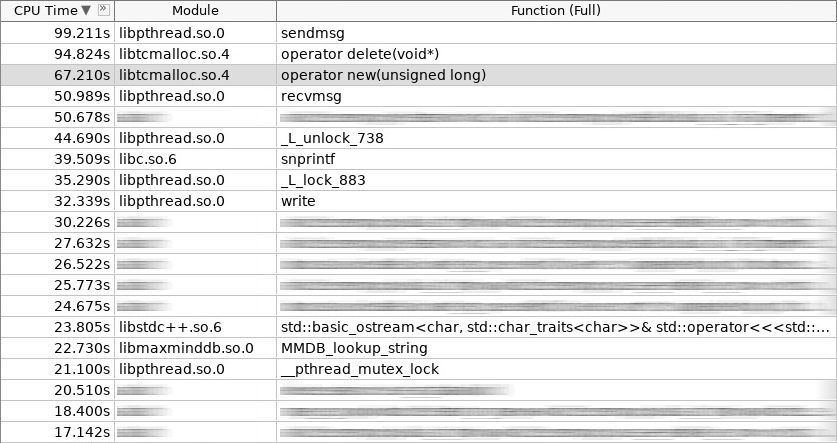
Dans la capture d'écran, l'opérateur nouveau a travaillé 67 secondes et l'opérateur supprime encore plus - 97 secondes.
Cette situation nous a bouleversés. Comment réduire le temps de séjour de l'application dans l'opérateur nouveau et supprimer l'opérateur? Il est logique que cela soit possible en abandonnant les allocations constantes d'objets fréquemment créés et supprimés sur le tas. Nous avons opté pour trois approches. Deux d'entre eux sont standard:
pool d'objets et
allocation de pile . Les sessions client organisées en pool au démarrage de l'application sont bien placées sur la première approche. La seconde approche est utilisée partout où une demande d'utilisateur est traitée du début à la fin dans la même pile, en d'autres termes, dans le même gestionnaire de contexte io. Nous n'y reviendrons pas plus en détail. Nous ferions mieux de parler de la troisième approche, la plus complexe et la plus intéressante. Il s'agit de l'
allocation ou de la distribution des dalles.
L'idée de la distribution des dalles n'est pas nouvelle. Il a été inventé et implémenté dans Solaris, puis migré vers le noyau Linux, et consiste dans le fait que les objets souvent utilisés du même type sont plus faciles à stocker dans le pool. Nous prenons simplement l'objet de la piscine lorsque nous en avons besoin, et une fois le travail terminé, nous le restituons. Aucun appel à l'opérateur nouveau et supprimer l'opérateur! De plus, un minimum d'initialisation. Dans le noyau de la dalle, la distribution est utilisée pour les sémaphores, les descripteurs de fichiers, les processus et les threads. Dans notre cas, cela tombait parfaitement sur les sessions serveur et client, ainsi que tout ce qui s'y trouve.
Graphique (distribution des dalles):

En plus du fait que les allocateurs de dalles sont dans le noyau, leurs implémentations existent également dans l'espace utilisateur. Ils sont peu nombreux et ceux qui se développent activement sont généralement peu nombreux. Nous nous sommes installés sur une bibliothèque appelée
libsmall , qui fait partie de
tarantool . Il a tout ce dont vous avez besoin.
- petit :: allocateur
- small :: slab_cache (thread local)
- petit :: dalle
- petit :: arène
- petit :: quota
La structure small :: slab est un pool avec un type d'objet spécifique. La structure small :: slab_cache est un cache qui contient diverses listes de pools avec un type spécifique d'objets. La structure small :: allocator est un code qui sélectionne le cache nécessaire, y recherche un pool approprié, dans lequel l'objet demandé est distribué. Ce que font les petits objets :: arena et petits :: quota ressortira clairement des exemples ci-dessous.
Envelopper
La bibliothèque libsmall est écrite en C, pas en C ++, nous avons donc dû développer plusieurs wrappers pour une intégration transparente dans la bibliothèque C ++ standard.
- variti :: slab_allocator
- variti :: dalle
- variti :: thread_local_slab
- variti :: slab_allocate_shared
La classe variti :: slab_allocator implémente les exigences minimales définies par la norme lors de l'écriture de son propre allocateur. Dans les classes variti :: slab, tout le travail avec la bibliothèque libsmall est encapsulé. Pourquoi variti :: thread_local_slab est-il nécessaire? Le fait est que les caches de dalles de distribution sont des objets locaux de thread. Cela signifie que chaque thread a son propre ensemble de caches. Ceci est fait afin de réduire à zéro le nombre d'opérations bloquées lors de la distribution d'un nouvel objet. Par conséquent, dans la mémoire de chaque thread, nous plaçons notre instance de la classe variti :: slab, et l'accès à celle-ci est réglementé à l'aide du wrapper variti :: thread_local_slab. Je vous parlerai plus tard de la fonction de modèle variti :: slab_allocate_shared.
Dans la classe variti :: slab_allocator, tout est assez simple. Il a la capacité de se relier d'un type à un autre, par exemple, du vide au caractère. Fait intéressant, vous pouvez faire attention à la prévalence de nullptr à l'exception std :: bad_alloc dans le cas où la mémoire s'épuise de la dalle de distribution. Le reste transfère des appels à l'intérieur du wrapper variti :: thread_local_slab.
Extrait (slab_allocator.hpp):
template <typename T> class slab_allocator { public: using value_type = T; using pointer = value_type*; using const_pointer = const value_type*; using reference = value_type&; using const_reference = const value_type&; template <typename U> struct rebind { using other = slab_allocator<U>; }; slab_allocator() {} template <typename U> slab_allocator(const slab_allocator<U>& other) {} T* allocate(size_t n, const void* = nullptr) { auto p = static_cast<T*>(thread_local_slab::allocate(sizeof(T) * n)); if (!p && n) throw std::bad_alloc(); return p; } void deallocate(T* p, size_t n) { thread_local_slab::deallocate(p, sizeof(T) * n); } }; template <> class slab_allocator<void> { public: using value_type = void; using pointer = void*; using const_pointer = const void*; template <typename U> struct rebind { typedef slab_allocator<U> other; }; };
Voyons comment le constructeur et le destructeur variti :: slab sont implémentés. Dans le constructeur, nous allouons un total de pas plus de 1 Gio de mémoire pour tous les objets. La taille de chaque piscine dans notre cas ne dépasse pas 1 Mio. L'objet minimum que nous pouvons distribuer est de 2 octets (en fait, libsmall l'augmentera au minimum requis - 8 octets). Les objets restants disponibles via notre distribution de dalles seront un multiple de deux (défini par la constante 2.f). Au total, vous pouvez distribuer des objets de taille 8, 16, 32, etc. Si la taille de l'objet demandé est de 24 octets, une surcharge se produira de la mémoire. La distribution vous renverra cet objet, mais il sera placé dans un pool qui correspond à un objet de 32 octets. Les 8 octets restants seront inactifs.
Extrait (slab.hpp):
inline void* phys_to_virt_p(void* p) { return reinterpret_cast<char*>(p) + sizeof(std::thread::id); } inline size_t phys_to_virt_n(size_t n) { return n - sizeof(std::thread::id); } inline void* virt_to_phys_p(void* p) { return reinterpret_cast<char*>(p) - sizeof(std::thread::id); } inline size_t virt_to_phys_n(size_t n) { return n + sizeof(std::thread::id); } inline std::thread::id& phys_thread_id(void* p) { return *reinterpret_cast<std::thread::id*>(p); } class slab : public noncopyable { public: slab() { small::quota_init(& quota_, 1024 * 1024 * 1024); small::slab_arena_create(&arena_, & quota_, 0, 1024 * 1024, MAP_PRIVATE); small::slab_cache_create(&cache_, &arena_); small::allocator_create(&allocator_, &cache_, 2, 2.f); } ~slab() { small::allocator_destroy(&allocator_); small::slab_cache_destroy(&cache_); small::slab_arena_destroy(&arena_); } void* allocate(size_t n) { auto phys_n = virt_to_phys_n(n); auto phys_p = small::malloc(&allocator_, phys_n); if (!phys_p) return nullptr; phys_thread_id(phys_p) = std::this_thread::get_id(); return phys_to_virt_p(phys_p); } void deallocate(const void* p, size_t n) { auto phys_p = virt_to_phys_p(const_cast<void*>(p)); auto phys_n = virt_to_phys_n(n); assert(phys_thread_id(phys_p) == std::this_thread::get_id()); small::free(&allocator_, phys_p, phys_n); } private: small::quota quota_; small::slab_arena arena_; small::slab_cache cache_; small::allocator allocator_; };
Toutes ces restrictions s'appliquent à une instance particulière de la classe variti :: slab. Étant donné que chaque thread a le sien (pensez au thread local), la limite totale du processus ne sera pas de 1 Gio, mais sera directement proportionnelle au nombre de threads qui utilisent la distribution de dalles.
Graphique (std :: thread :: id):
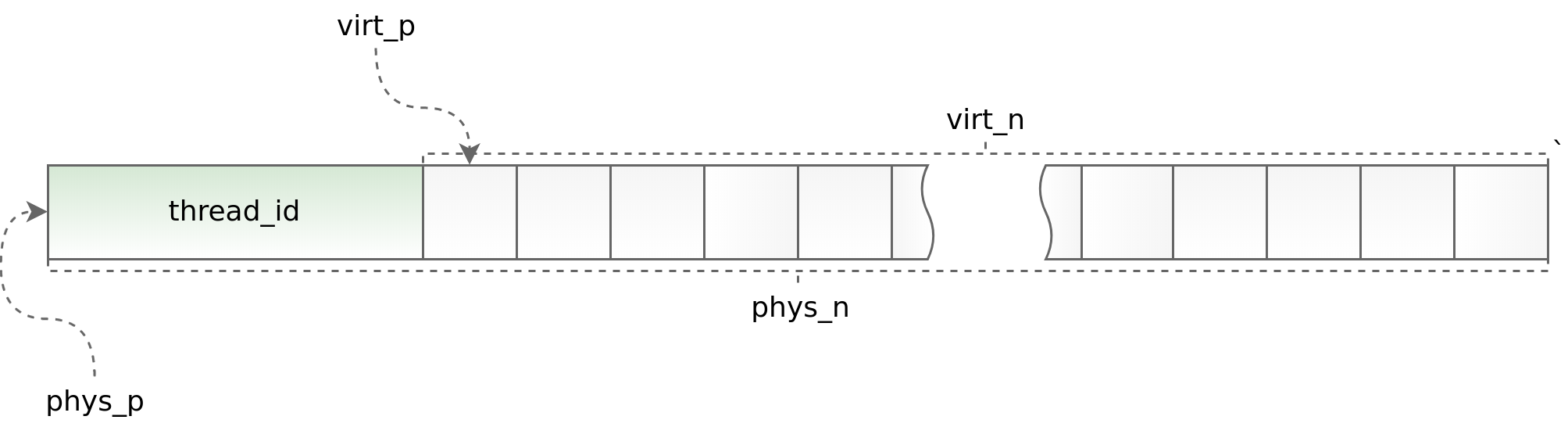
D'une part, l'utilisation de thread local permet d'accélérer le travail de distribution de dalles dans une application multi-thread, d'autre part, elle impose de sérieuses restrictions sur l'architecture de l'application asynchrone. Vous devez demander et renvoyer un objet dans le même flux. Faire cela dans le cadre de boost.asio est parfois très problématique. Pour suivre des situations manifestement erronées, au début de chaque objet, nous plaçons l'identifiant du flux dans lequel la méthode d'allocation est appelée. Cet identifiant est ensuite vérifié dans la méthode de désallocation. Les assistants phys_to_virt_p et virt_to_phys_p aident à cela.
Extrait (thread_local_slab.hpp):
class thread_local_slab : public noncopyable { public: static void initialize(); static void finalize(); static void* allocate(size_t n); static void deallocate(const void* p, size_t n); };
Extrait (thread_local_slab.cpp):
static thread_local slab* slab_; void thread_local_slab::initialize() { slab_ = new slab(slab_cfg_); } void thread_local_slab::finalize() { delete slab_; } void* thread_local_slab::malloc(size_t n) { return slab_->malloc(n); } void thread_local_slab::free(const void* p, size_t n) { slab_->free(p, n); }
Lorsque le contrôle du flux est perdu (lors du transfert d'un objet entre différents contextes io), un pointeur intelligent permet la libération correcte de l'objet. Tout ce qu'il fait est de distribuer l'objet, en se souvenant de son contexte io, puis de l'envelopper dans std :: shared_ptr avec un diviseur personnalisé qui ne renvoie pas immédiatement l'objet à la distribution, mais le fait dans le contexte io enregistré précédemment. Cela fonctionne bien lorsque chaque contexte io s'exécute sur un seul thread. Sinon, malheureusement, cette approche n'est pas applicable.
Extrait (slab_helper.hpp):
template <typename T, typename Allocator, typename... Args> std::shared_ptr<T> slab_allocate_shared(Allocator allocator, Args... args) { T* p = allocator.allocate(1); new ((void*)p) T(std::forward<Args>(args)...); std::shared_ptr<T> ptr(p, [allocator](T* p) { p->~T(); allocator.deallocate(p); }); return ptr; }; template <typename T, typename Allocator, typename... Args> std::shared_ptr<T> slab_allocate_shared(Allocator allocator, boost::asio::io_service* io, Args... args) { T* p = allocator.allocate(1); new ((void*)p) T(std::forward<Args>(args)...); std::shared_ptr<T> ptr(p, [allocator, io](T* p) { io->post([allocator, p]() { p->~T(); allocator.deallocate(p); }); }); return ptr; };
Solution
Une fois le travail de création de libsmall terminé, nous avons d'abord déplacé les allocateurs de blocs à l'intérieur du tampon de flux vers la dalle. C'était assez facile à faire. Après avoir obtenu un résultat positif, nous sommes allés de l'avant et avons appliqué les allocateurs de dalles d'abord au tampon de flux lui-même, puis à tous les objets à l'intérieur des sessions serveur et client.
- variti :: morceau
- variti :: streambuf
- variti :: server_session
- variti :: client_session
Dans le même temps, il était nécessaire de résoudre des problèmes supplémentaires, à savoir: transférer des objets simples, des objets composites et des collections vers des allocateurs de dalles. Et s'il n'y avait pas de difficultés sérieuses avec les deux premières classes d'objets (les objets composites sont réduits à des objets simples), alors lors de la traduction des collections, nous avons rencontré de sérieuses difficultés.
- std :: list
- std :: deque
- std :: vecteur
- std :: string
- std :: map
- std :: unordered_map
L'une des principales limitations lors de l'utilisation de la distribution de dalles est que le nombre d'objets de types différents ne doit pas être trop grand (plus il est petit, mieux c'est). Dans ce contexte, certaines collections peuvent bien tomber sur le concept d'allocateurs de dalles, tandis que d'autres ne le peuvent pas.
Pour la dalle std :: list, les allocateurs fonctionnent très bien. Cette collection est implémentée en interne à l'aide d'une liste chaînée, dont chaque élément a une taille fixe. Ainsi, avec l'ajout de nouvelles données à la liste std :: dans la distribution de dalles, de nouveaux types d'objets n'apparaissent pas. La condition indiquée ci-dessus est satisfaite! Le std :: map est organisé de la même manière. La seule différence est qu'à l'intérieur, ce n'est pas une liste chaînée, mais un arbre.
Dans le cas de std :: deque, les choses sont plus compliquées. Cette collection est implémentée via un bloc de mémoire contigu contenant des pointeurs vers des blocs. Bien que les morceaux soient assez précis, std :: deque se comporte de la même manière que std :: list, mais lorsqu'ils se terminent, ce même bloc de mémoire est redistribué. Du point de vue des allocateurs de dalles, chaque redistribution de mémoire est un objet avec un nouveau type. Le nombre d'objets ajoutés à la collection dépend directement de l'utilisateur et peut croître de manière incontrôlable. Cette situation n'est pas acceptable, nous avons donc soit limité au préalable la taille de std :: deque là où c'était possible, soit préféré std :: list.
Si nous prenons std :: vector et std :: string, alors ils sont encore plus compliqués. L'implémentation de ces collections est quelque peu similaire à std :: deque, sauf que leur bloc de mémoire continue croît beaucoup plus rapidement. Nous avons remplacé std :: vector et std :: string par std :: deque, et dans le pire des cas par std :: list. Oui, nous avons perdu en fonctionnalités et quelque part même en performances, mais cela a beaucoup moins affecté l'image finale que les optimisations pour lesquelles tout a été conçu.
Nous avons fait exactement la même chose avec std :: unordered_map, en l'abandonnant au profit du variti :: flat_map auto-écrit implémenté via std :: deque. Dans le même temps, nous avons simplement mis en cache les clés fréquemment utilisées dans des variables distinctes, par exemple, comme cela se fait avec les en-têtes de requête http dans nginx.
Conclusion
Après avoir terminé le transfert complet des sessions serveur et client vers les allocateurs de dalles, nous avons réduit le temps passé à travailler avec un groupe de plus d'une fois et demie.
Capture d'écran de l'amplificateur (coldslab):
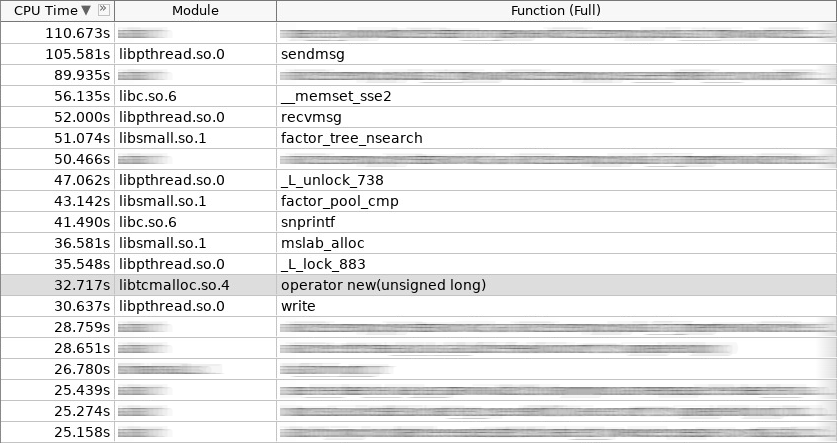
Dans la capture d'écran, l'opérateur new a travaillé 32 secondes et l'opérateur delete - 24 secondes. À ce moment, d'autres fonctions pour travailler avec le tas ont été ajoutées: smalloc - 21 secondes, mslab_alloc - 37 secondes, smfree - 8 secondes, mslab_free - 21 secondes. Total, 143 secondes contre 161 secondes.
Mais ces mesures ont été effectuées immédiatement après le démarrage du service sans initialiser les caches dans la distribution de la dalle. Après des tirs répétés à partir d'un char Yandex, l'image globale s'est améliorée.
Capture d'écran de l'amplificateur (hotslab):
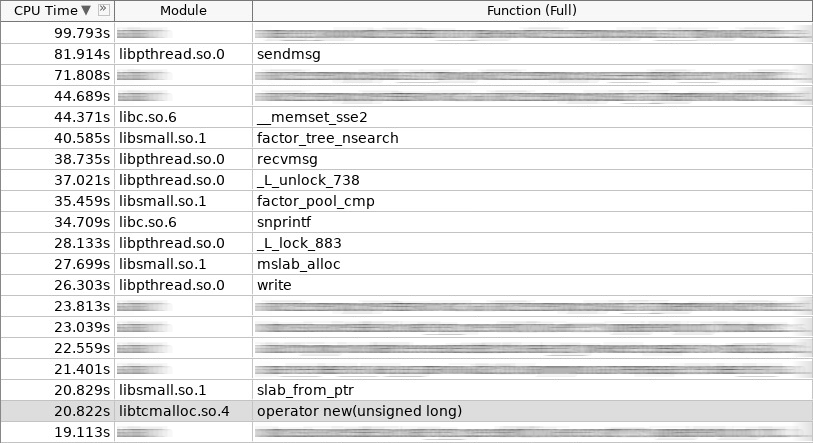
Dans la capture d'écran, l'opérateur new fonctionnait 20 secondes, smalloc - 16 secondes, mslab_alloc - 27 secondes, operator delete - 16 secondes, smfree - 7 secondes, mslab_free - 17 secondes. Total 103 secondes contre 161 secondes.
Tableau de mesure:
woslab coldslab hotslab operator new 67s 32s 20s smalloc - 21s 16s mslab_alloc - 37s 27s operator delete 94s 24s 16s smfree - 8s 7s mslab_free - 21s 17s summary 161s 143s 103s
Dans la vie réelle, le résultat devrait être encore meilleur, car les allocateurs de dalles résolvent non seulement le problème de l'allocation de mémoire longue et de la libération, mais réduisent également la fragmentation. Sans dalle, au fil du temps, le fonctionnement de l'opérateur new et de l'opérateur delete ne devrait que ralentir. Avec la dalle - elle restera toujours au même niveau.
Comme nous pouvons le voir, les allocateurs de dalles résolvent avec succès le problème d'allocation de mémoire des objets fréquemment utilisés. Faites attention à eux si la question de la création et de la suppression fréquentes d'objets vous intéresse. Mais n'oubliez pas les limitations qu'elles imposent à l'architecture de votre application! Tous les objets complexes ne peuvent pas simplement être placés dans la distribution de dalle. Il faut parfois abandonner beaucoup! Eh bien, plus l'architecture de votre application est complexe, plus vous devrez souvent vous occuper de remettre l'objet dans le cache correct en termes de multithreading. Cela peut être simple lorsque vous avez immédiatement élaboré l'architecture de l'application, en tenant compte de l'utilisation d'allocateurs de dalles, mais cela posera certainement des problèmes lorsque vous déciderez de les intégrer à un stade avancé.
App
Découvrez le code source
ici !