Dans un
article précédent, nous avons parlé de prévisions de séries chronologiques. Une suite logique sera un article sur l'identification des anomalies.
Candidature
La détection d'anomalies est utilisée dans des domaines tels que:
1) Prévision des pannes d'équipement
Ainsi, en 2010, les centrifugeuses iraniennes ont été attaquées par le virus Stuxnet, qui a placé l'équipement en mode optimal et a désactivé une partie de l'équipement en raison de l'usure accélérée.
Si des algorithmes de recherche d'anomalies étaient utilisés sur l'équipement, les situations de défaillance pourraient être évitées.

La recherche d'anomalies dans le fonctionnement des équipements est utilisée non seulement dans l'industrie nucléaire, mais aussi dans la métallurgie et l'exploitation des turbines d'aéronefs. Et dans d'autres domaines où l'utilisation de diagnostics prédictifs est moins chère que les pertes possibles en cas de panne imprévisible.
2) Prédire la fraude
Si la carte que vous utilisez à Podolsk est retirée en Albanie, il est possible que la transaction soit vérifiée davantage.
3) Identifier les habitudes de consommation anormales
Si certains clients présentent un comportement anormal, il peut y avoir un problème dont vous n'êtes pas au courant.
4) Identification de la demande et de la charge anormales
Si les ventes dans le magasin FMCG sont tombées sous la frontière de l'intervalle de confiance prévu, vous devriez trouver la raison de ce qui se passe.
Approches de détection des anomalies
1) La méthode des vecteurs de support avec une classe SVM à une classe
Convient lorsque les données de l'ensemble d'apprentissage obéissent à la distribution normale, tandis que l'ensemble de test contient des anomalies.
La méthode du vecteur de support à classe unique construit une surface non linéaire autour de l'origine. Il est possible de définir la frontière de coupure, dont les données sont considérées comme anormales.
Basé sur l'expérience de notre équipe DATA4, One-Class SVM est l'algorithme le plus fréquemment utilisé pour résoudre le problème de recherche d'anomalies.

2) Méthode d'isoler la forêt - isoler la forêt
Avec la méthode «aléatoire» de construction des arbres, les émissions tomberont dans les feuilles au début (à une faible profondeur de l'arbre), c'est-à-dire les émissions sont plus faciles à «isoler». Des valeurs anormales sont extraites aux premières itérations de l'algorithme.

3) Enveloppe elliptique et méthodes statistiques
Utilisé lorsque les données sont normalement distribuées. Plus la mesure est proche de la queue du mélange de distributions, plus la valeur est anormale.
D'autres méthodes statistiques peuvent être attribuées à cette classe.

 Image de dyakonov.org
Image de dyakonov.org4) Méthodes métriques
Les méthodes comprennent des algorithmes tels que k voisins les plus proches, k-ème voisin le plus proche, ABOD (détection des valeurs aberrantes en fonction de l'angle) ou LOF (facteur local des valeurs aberrantes).
Convient si la distance entre les valeurs des signes est équivalente ou normalisée (pour ne pas mesurer le boa chez les perroquets).
L'algorithme de k voisins les plus proches suggère que les valeurs normales sont situées dans une certaine région de l'espace multidimensionnel et que la distance aux anomalies sera plus grande qu'à l'hyperplan de séparation.
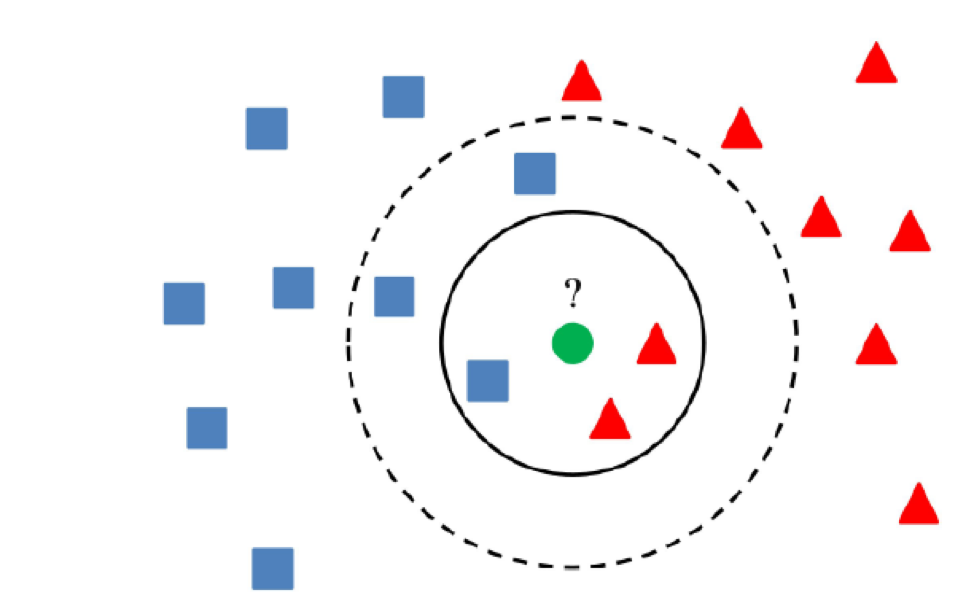
5) Méthodes de cluster
L'essence des méthodes de cluster est que si la valeur est supérieure à une certaine distance des centres des clusters, la valeur peut être considérée comme anormale.
L'essentiel est d'utiliser un algorithme qui regroupe correctement les données, qui dépend de la tâche spécifique.
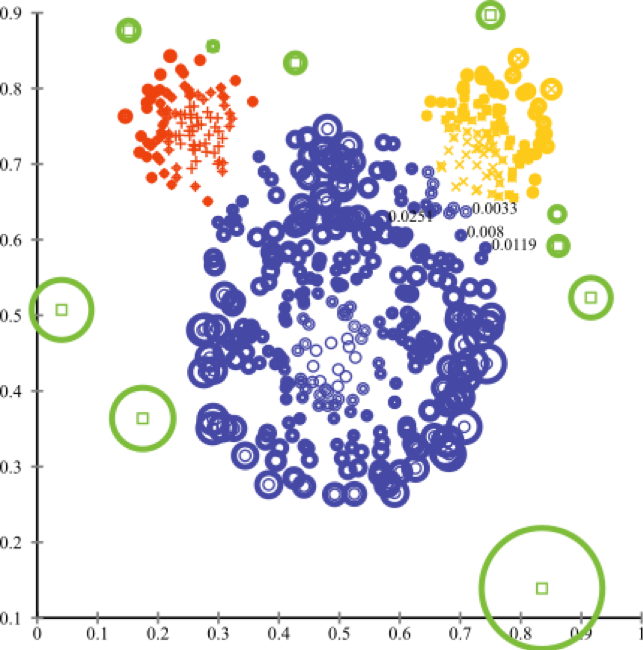
6) Méthode du composant principal
Convient lorsque les zones de plus grande variation de variance sont mises en évidence.
7) Algorithmes basés sur la prévision de séries chronologiques
L'idée est que si une valeur est éliminée d'un intervalle de confiance de prédiction, la valeur est considérée comme anormale. Des algorithmes tels que l'anti-crénelage triple, S (ARIMA), le boosting, etc. sont utilisés pour prédire la série temporelle.
Les algorithmes de prévision des séries chronologiques ont été discutés dans un article précédent.
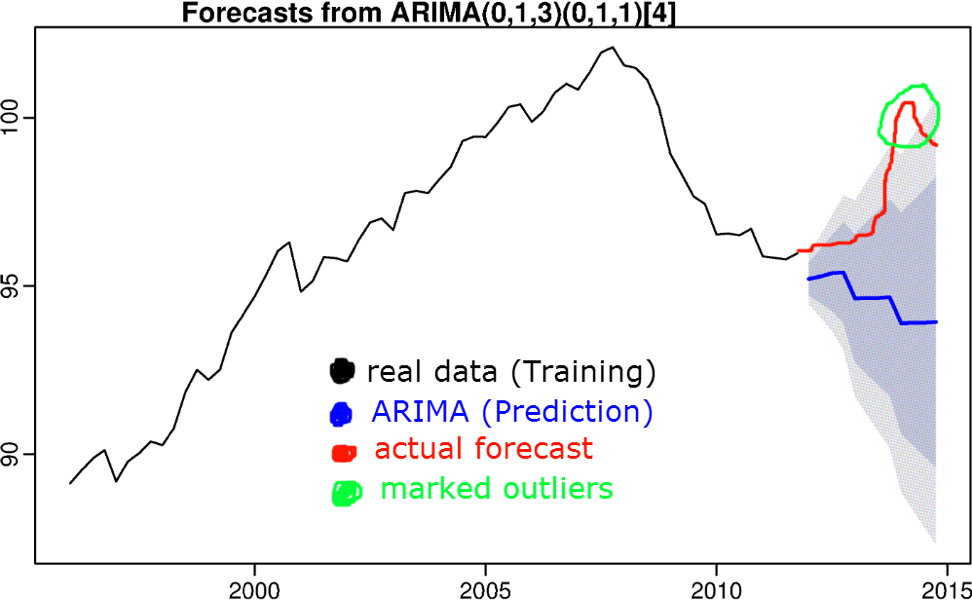
8) Formation avec un enseignant (régression, classification)
Si les données le permettent, nous utilisons des algorithmes de régression linéaire aux réseaux récurrents. Nous mesurons la différence entre la prédiction et la valeur réelle et concluons à quel point les données sont éliminées de la norme. Il est important que l'algorithme ait une capacité de généralisation suffisante et que l'échantillon d'apprentissage ne contienne pas de valeurs anormales.
9) Essais sur modèle
Nous abordons le problème de la recherche d'anomalies comme la tâche de rechercher des recommandations. Nous décomposons notre matrice de caractéristiques à l'aide de SVD ou de machines de factorisation, et les valeurs dans la nouvelle matrice, qui sont significativement différentes des originales, sont considérées comme anormales.
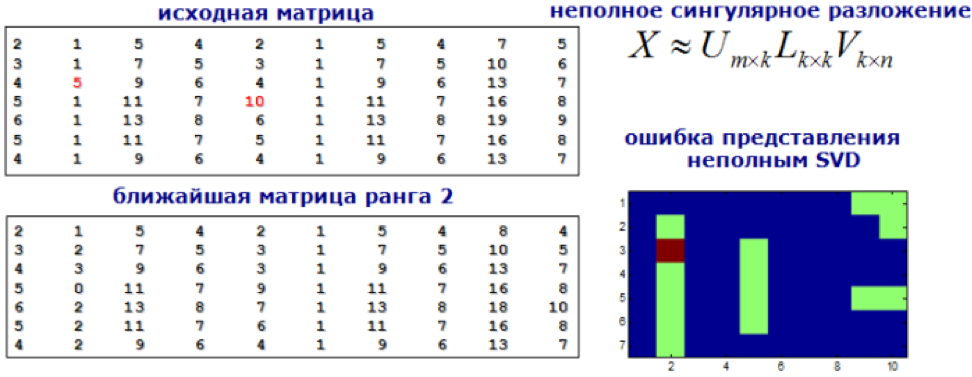 Image de dyakonov.org
Image de dyakonov.orgConclusion
Dans cet article, nous avons examiné les approches de base pour détecter les anomalies.
La recherche d'anomalies peut être qualifiée d'art de plusieurs manières. Il n'y a pas d'algorithme ou d'approche idéal dont l'application résout tous les problèmes. Le plus souvent, un ensemble de méthodes est utilisé pour résoudre un cas spécifique. Les anomalies sont recherchées en utilisant la méthode à classe unique des vecteurs de support, en isolant les forêts, les méthodes métriques et en grappes, ainsi qu'en utilisant les principaux composants et les séries chronologiques de prévision.
Si vous connaissez d'autres méthodes, écrivez à leur sujet dans la section commentaire de l'article.