Très souvent lors du développement d'applications mobiles (peut-être le même problème avec les applications web), les développeurs se retrouvent dans une situation où le backend ne fonctionne pas ou ne fournit pas les méthodes nécessaires.
Cette situation peut se produire pour diverses raisons. Cependant, le plus souvent au début du développement, le backend n'est tout simplement pas écrit et le client démarre sans lui. Dans ce cas, le début du développement est retardé de 2 à 4 mois
Parfois, le serveur s'arrête simplement (plante), parfois il n'a pas le temps de déployer les méthodes nécessaires, parfois il y a des problèmes de données, etc. Tous ces problèmes nous ont amenés à écrire un petit service Mocker qui vous permet de remplacer le vrai backend.

Comment en suis-je arrivé làComment en suis-je arrivé là? Ma première année dans l'entreprise se terminait et ils m'ont mis sur un tout nouveau projet de commerce électronique. Le gestionnaire a déclaré que le projet doit être achevé en 4 mois, mais l'équipe backend (côté client) ne commencera le développement qu'après 1,5 mois. Et pendant ce temps, nous devons déjà lancer de nombreuses fonctionnalités d'interface utilisateur.
J'ai suggéré d'écrire un backend moch (avant de devenir développeur iOS, j'ai joué avec .NET à l'uni). L'idée d'implémentation était simple: selon une spécification donnée, il était nécessaire d'écrire des méthodes de stub qui prendraient des données à partir de fichiers JSON pré-préparés. Ils ont décidé de cela.
Après 2 semaines, je suis parti en vacances et j'ai pensé: "Pourquoi ne génère-t-il pas automatiquement tout cela?" Donc, pendant 2 semaines de vacances, j'ai écrit un semblant d'interprète qui prend la spécification APIBlueprint et en génère l'application Web .NET (code C #).
En conséquence, la première version de cette chose est apparue et nous l'avons vécu pendant près de 2,5 mois. Je ne peux pas donner de vrais chiffres, combien cela nous a aidés, mais je me souviens comment ils ont dit rétrospectivement que sans ce système, il n'y aurait pas de version.
Maintenant, après plusieurs années, j'ai pris en compte les erreurs que j'ai commises (et il y en avait beaucoup) et j'ai complètement réécrit l'instrument.
Profitant de cette opportunité - merci beaucoup à des collègues qui nous ont aidés à nous faire part de leurs commentaires et de leurs conseils. Et aussi aux dirigeants qui ont enduré tout mon «arbitraire d'ingénierie».
Présentation
En règle générale, toute application client-serveur ressemble à ceci:
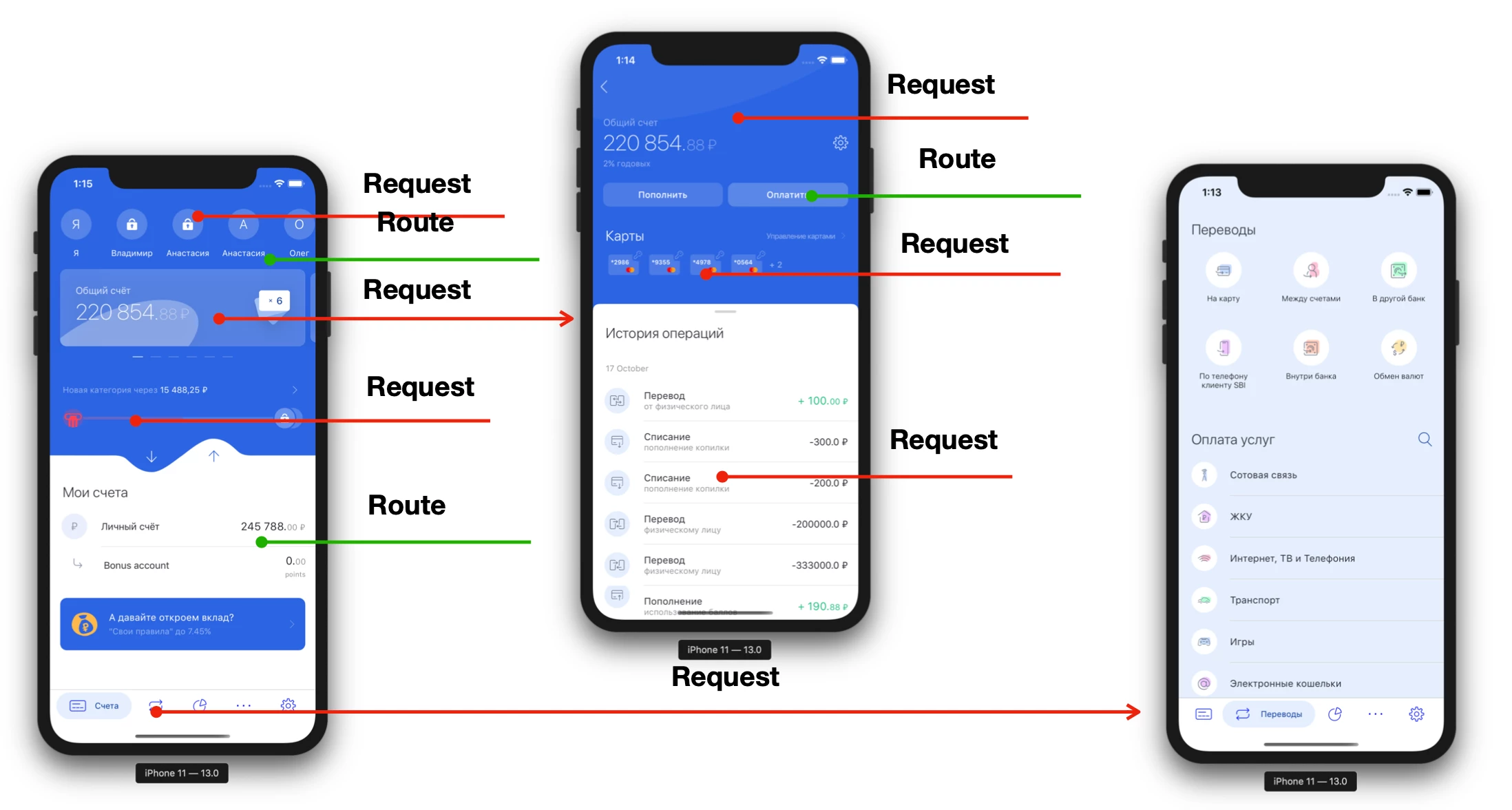
Chaque écran contient au moins 1 requête (et souvent plus). En pénétrant profondément dans les écrans, nous devons faire de plus en plus de demandes. Parfois, nous ne pouvons même pas effectuer la transition avant que le serveur ne nous dise "Afficher le bouton". Autrement dit, l'application mobile est très liée au serveur, non seulement pendant son travail immédiat, mais aussi au stade du développement. Considérez le cycle de développement de produit abstrait:

- Nous concevons d'abord. Nous décomposons, décrivons et discutons.
- Après avoir reçu les tâches et les exigences, nous commençons le développement. Nous écrivons le code, la composition, etc.
- Après avoir mis en œuvre quelque chose, un assemblage est en cours de préparation, qui passe en test manuel, où l'application est vérifiée pour différents cas.
- Si tout va bien pour nous, et que les testeurs testent le montage, cela revient au client qui effectue la réception.
Chacun de ces processus est très important. Surtout ce dernier, car le client doit comprendre à quel stade nous en sommes réellement, et parfois il doit rendre compte des résultats à la direction ou aux investisseurs. En règle générale, ces rapports se produisent, y compris sous la forme d'une démonstration d'une application mobile. Dans ma pratique, il y a eu un cas où un client a démontré seulement la moitié du MVP, qui ne fonctionnait que sur les mokas. L'application mok ressemble au présent et les charlatans au présent. C'est donc réel (:
Cependant, c'est un rêve rose. Voyons ce qui se passe vraiment si nous n'avons pas de serveur.

- Le processus de développement sera plus lent et plus pénible, car nous ne pouvons pas écrire de services normalement, nous ne pouvons pas non plus vérifier tous les cas, nous devons écrire des talons qui devront être supprimés plus tard.
- Après avoir fait le montage en deux avec chagrin, il arrive aux testeurs qui le regardent et ne comprennent pas quoi en faire. Vous ne pouvez rien vérifier, la moitié ne fonctionne pas du tout, car il n'y a pas de serveur. En conséquence, ils manquent de nombreux bugs: à la fois logiques et visuels.
- Eh bien, après "à quoi ils auraient pu ressembler", vous devez donner l'assemblage au client, puis le plus désagréable commence. Le client ne peut pas vraiment évaluer le travail, il voit 1-2 cas sur tous les possibles et ne peut certainement pas le montrer à ses investisseurs.
En général, tout va en descendant. Et malheureusement, de telles situations se produisent presque toujours: parfois il n'y a pas de serveur pendant quelques mois, parfois six mois, parfois juste dans le processus, le serveur est très en retard ou vous devez vérifier rapidement les cas limites qui peuvent être reproduits en utilisant des manipulations de données sur un vrai serveur.
Par exemple, nous voulons vérifier le comportement de l'application si le paiement de l'utilisateur est supérieur à la date d'échéance. Il est très difficile (et long) de reproduire une telle situation sur le serveur et nous devons le faire artificiellement.
Par conséquent, il existe les problèmes suivants:
- Le serveur est complètement manquant. Pour cette raison, il est impossible de concevoir, tester et présenter.
- Le serveur n'a pas le temps, ce qui interfère avec le développement et peut interférer avec les tests.
- Nous voulons tester les cas limites, et le serveur ne peut pas le permettre sans de longs gestes.
- Affectez les tests et les présentations menaçantes.
- Le serveur plante (une fois, pendant le développement stable, nous avons perdu le serveur pendant 3,5 jours).
Pour lutter contre ces problèmes, Mocker a été créé.
Principe de fonctionnement
Mocker est un petit service Web qui est hébergé quelque part, écoute le trafic sur un port spécifique et peut répondre avec des données prédéfinies à des demandes réseau spécifiques.
La séquence est la suivante:
1. Le client envoie une demande.
2. Mocker reçoit la demande.
3. Mocker trouve la maquette souhaitée.
4. Mocker renvoie la maquette souhaitée.
Si tout est clair avec les points 1, 2 et 4, alors 3 soulève des questions.
Afin de comprendre comment le service trouve la maquette nécessaire pour le client, nous considérons d'abord la structure de la maquette elle-même.
Mock est un fichier JSON au format suivant:
{ "url": "string", "method": "string", "statusCode": "number", "response": "object", "request": "object" }
Analysons chaque champ séparément.
url
Ce paramètre est utilisé pour spécifier l'URL de la demande à laquelle le client accède.
Par exemple, si une application mobile fait une demande d'url
host.dom/path/to/endpoint , alors dans le champ
url nous devons écrire
/path/to/endpoint .
Autrement dit, ce champ stocke le
chemin d'accès relatif au point de terminaison .
Ce champ doit être formaté au format de modèle d'URL, c'est-à-dire que les formats suivants sont autorisés:
/path/to/endpoint - adresse URL normale. Lorsque la demande est reçue, le service compare les lignes caractère par caractère./path/to/endpoint/{number} - url avec motif de chemin. Une maquette avec une telle URL répondra à toute demande qui correspond à ce modèle./path/to/endpoint/data?param={value} - url avec paramètre-modèle. Mock avec une telle URL déclenchera une requête contenant les paramètres donnés. De plus, si l'un des paramètres ne figure pas dans la demande, il ne correspondra pas au modèle.
Ainsi, en contrôlant les paramètres d'URL, vous pouvez clairement déterminer qu'un certain mock reviendra à une URL spécifique.
méthode
Il s'agit de la méthode http attendue. Par exemple,
POST ou
GET .
La chaîne doit contenir uniquement des majuscules.
statusCode
Il s'agit du code d'état http pour la réponse. Autrement dit, en demandant cette maquette, le client recevra une réponse avec le statut enregistré dans le champ statusCode.
réponse
Ce champ contient l'objet JSON qui sera envoyé au client dans le corps de la réponse à sa demande.
demande
Il s'agit du corps de la demande qui devrait être reçu du client. Il sera utilisé pour donner la réponse souhaitée en fonction du corps de la demande. Par exemple, si nous voulons changer les réponses en fonction des paramètres de la demande.
{ "url": "/auth", "method": "POST", "statusCode": 200, "response": { "token": "cbshbg52rebfzdghj123dsfsfasd" }, "request": { "login": "Tester", "password": "Valid" } }
{ "url": "/auth", "method": "POST", "statusCode": 400, "response": { "message": "Bad credentials" }, "request": { "login": "Tester", "password": "Invalid" } }
Si le client envoie une demande au corps:
{ "login": "Tester", "password": "Valid" }
Puis en réponse, il recevra:
{ "token": "cbshbg52rebfzdghj123dsfsfasd" }
Et dans le cas où nous voulons vérifier le fonctionnement de l'application si le mot de passe n'est pas entré correctement, une demande sera envoyée avec le corps:
{ "login": "Tester", "password": "Invalid" }
Puis en réponse, il recevra:
{ "message": "Bad credentials" }
Et nous pouvons vérifier le cas avec le mauvais mot de passe. Et donc pour tous les autres cas.
Et maintenant, nous allons voir comment le regroupement et la recherche du moq souhaité fonctionnent.

Afin de rechercher rapidement et facilement le mok souhaité, le serveur charge tous les mokas en mémoire et les regroupe de la bonne manière. L'image ci-dessus montre un exemple de regroupement.
Le serveur combine différents mokas par
URL et
méthode . Ceci est nécessaire, entre autres, pour que nous puissions créer de nombreux moks différents sur une seule URL.
Par exemple, nous voulons qu'en tirant constamment Pull-To-Refresh, différentes réponses arrivent et l'état de l'écran change tout le temps (pour vérifier tous les cas limites).
Ensuite, nous pouvons créer de nombreux moks différents avec les mêmes paramètres de
méthode et d'
URL , et le serveur nous les renverra de manière itérative (à son tour).
Par exemple, ayons de tels mokas:
{ "url": "/products", "method": "GET", "statusCode": 200, "response": { "name": "product", "currency": 1, "value": 20 } }
{ "url": "/products", "method": "GET", "statusCode": 200, "response": { "name": "gdshfjshhkfhsdgfhshdjgfhjkshdjkfsfgbjsfgskdf", "currency": 5, "value": 100000000000 } }
{ "url": "/products", "method": "GET", "statusCode": 200, "response": null }
{ "url": "/products", "method": "GET", "statusCode": 400, "response": null }
Ensuite, lorsque nous appellerons la méthode GET / products pour la première fois, nous obtiendrons d'abord la réponse:
{ "name": "product", "currency": 1, "value": 20 }
Lorsque nous appelons la deuxième fois, le pointeur de l'itérateur passera à l'élément suivant et nous reviendra:
{ "name": "gdshfjshhkfhsdgfhshdjgfhjkshdjkfsfgbjsfgskdf", "currency": 5, "value": 100000000000 }
Et nous pouvons vérifier le comportement de l'application si nous obtenons de grandes valeurs. Et ainsi de suite.
Eh bien, et lorsque nous arrivons au dernier élément et appelons à nouveau la méthode, le premier élément nous reviendra, car l'itérateur reviendra au premier élément.
Proxy de mise en cache
Mocker peut fonctionner en mode cache de proxy. Cela signifie que lorsqu'un service reçoit une demande d'un client, il supprime l'adresse de l'hôte sur lequel se trouve le serveur réel et le schéma (pour déterminer le protocole). Ensuite, il prend la demande reçue (avec tous ses en-têtes, donc si la méthode nécessite une authentification, alors tout va bien, votre
Authorization: Bearer ... transférée) et supprime les informations de service (le même
host et le même
scheme ) et envoie la demande au vrai serveur.
Après avoir reçu la réponse avec le 200e code, Mocker enregistre la réponse dans le fichier Mock (oui, vous pouvez ensuite le copier ou le modifier) et retourne au client ce qu'il a reçu du vrai serveur. De plus, il n'enregistre pas seulement le fichier à un endroit aléatoire, mais organise les fichiers de sorte que vous puissiez ensuite les utiliser manuellement. Par exemple, Mocker envoie une demande à l'URL suivante:
hostname.dom/main/products/loans/info . Ensuite, il créera un dossier
hostname.dom , puis à l'intérieur il créera un dossier
main , à l'intérieur un dossier
products ...
Afin d'éviter les doublons, le nom est formé sur la base de la
méthode http (GET, PUT ...) et d'un
hachage du corps de réponse du serveur réel . Dans ce cas, s'il existe déjà une maquette sur une réponse spécifique, elle sera simplement remplacée.
Cette fonction peut être activée individuellement pour chaque demande. Pour ce faire, ajoutez trois en-têtes à la demande:
X-Mocker-Redirect-Is-On: "true", X-Mocker-Redirect-Host: "hostaname.ex:1234", X-Mocker-Redirect-Scheme: "http"
Indication explicite du chemin vers les simulacres
Parfois, vous voulez que Mocker ne retourne que les mokas que nous voulons, et pas tous ceux qui sont dans le projet.
Particulièrement pertinent pour les testeurs. Il serait pratique pour eux d'avoir une sorte de jeu de mokas préparé pour chacun des cas de test. Et puis, pendant les tests, QA sélectionne simplement le dossier dont il a besoin et fonctionne silencieusement, car il n'y a plus de bruit provenant de simulations tierces.
Maintenant c'est possible. Pour activer cette fonction, vous devez utiliser un en-tête spécial:
X-Mocker-Specific-Path: path
Par exemple, laissez Mocker avoir une telle structure de dossiers à la racine
root/ block_card_test_case/ mocks.... main_test_case/ blocked_test_case/ mocks...
Si vous devez exécuter un scénario de test sur les cartes bloquées,
X-Mocker-Specific-Path: block_card_test_caseSi vous devez exécuter un scénario de test associé au verrouillage de l'écran principal,
X-Mocker-Specific-Path: main_test_case/blocked_test_caseInterface
Au début, nous avons travaillé avec les mokas directement via ssh, mais avec une augmentation du nombre de mokas et d'utilisateurs, nous sommes passés à une option plus pratique. Maintenant, nous utilisons CloudCommander.
Dans l'exemple docker-compose, il se lie au conteneur Mocker.
Cela ressemble à ceci:
Eh bien, le bonus est un éditeur Web, qui vous permet d'ajouter / modifier des moki directement depuis le navigateur.

Il s'agit également d'une solution temporaire. Dans les plans pour sortir du travail avec les moks via le système de fichiers vers une base de données. Et en conséquence, il sera possible de contrôler les mokas eux-mêmes depuis l'interface graphique vers cette base de données.
Déploiement
La façon la plus simple de déployer Mocker est d'utiliser Docker. De plus, le déploiement du service à partir du docker déploiera automatiquement une interface Web à travers laquelle il est plus pratique de travailler avec des mokas. Les fichiers nécessaires au déploiement via Docker se trouvent dans le référentiel.
Cependant, si cette option ne vous convient pas, vous pouvez assembler indépendamment le service à partir de la source. Assez pour cela:
git clone https://github.com/LastSprint/mocker.git cd mocker go build .
Ensuite, vous devez écrire un fichier de configuration (
exemple ) et démarrer le service:
mocker config.json
Problèmes connus
- Après chaque nouveau fichier, vous devez effectuer
curl mockerhost.dom/update_models pour que le service curl mockerhost.dom/update_models les fichiers. Je n'ai pas trouvé de moyen rapide et élégant de le mettre à jour sinon - Parfois, des bugs CloudCommander (ou j'ai fait quelque chose de mal) et cela ne permet pas de modifier les moki qui ont été créés via l'interface Web. Il est traité en effaçant le cache du navigateur.
- Le service fonctionne uniquement avec
application/json . Les plans prennent en charge le form-url-encoding .
Résumé
Mocker est un service Web qui résout les problèmes de développement d'applications client-serveur lorsque le serveur n'est pas prêt pour une raison quelconque.
Le service vous permet de créer de nombreuses simulations différentes sur une seule URL, vous permet de connecter la demande et la réponse entre elles en spécifiant explicitement les paramètres dans l'URL, ou directement en définissant le corps de la demande attendu. Le service possède une interface Web qui simplifie considérablement la vie des utilisateurs.
Chaque utilisateur du service peut ajouter indépendamment le point de terminaison nécessaire et la demande dont il a besoin. Dans ce cas, sur le client, pour passer à un vrai serveur, il suffit de remplacer simplement la constante par l'adresse de l'hôte.
J'espère que cet article aidera les personnes qui souffrent de problèmes similaires et, peut-être, nous travaillerons ensemble pour développer cet outil.
Dépôt GitHub .