La question classique qu'un développeur pose à son
administrateur de base de données ou à un propriétaire d'entreprise, un consultant PostgreSQL, sonne presque toujours la même:
«Pourquoi les requêtes s'exécutent-elles si longtemps sur la base de données?»L'ensemble des raisons traditionnelles:
- algorithme inefficace
lorsque vous avez décidé de faire un JOIN de plusieurs CTE pour quelques dizaines de milliers d'enregistrements - statistiques non pertinentes
si la distribution réelle des données dans le tableau est déjà très différente de la dernière fois que ANALYZE les a collectées - "Gag" par ressources
et il n'y a déjà pas assez de puissance de calcul dédiée du CPU, des gigaoctets de mémoire sont constamment pompés ou le disque ne suit pas toute la base de données "Wishlist" - blocage des processus concurrents
Et si les verrous sont assez difficiles à capturer et à analyser, alors pour tout le reste, nous avons besoin d'
un plan de requête qui peut être obtenu en utilisant
l'opérateur EXPLAIN (
mieux, bien sûr, immédiatement EXPLAIN (ANALYZE, BUFFERS) ... ) ou
le module auto_explain .
Mais, comme indiqué dans la même documentation,
"Comprendre le plan est un art, et pour le maîtriser, il faut de l'expérience, ..."
Mais vous pouvez vous en passer si vous utilisez le bon outil!
À quoi ressemble généralement un plan de requête? Quelque chose comme ça:
Index Scan using pg_class_relname_nsp_index on pg_class (actual time=0.049..0.050 rows=1 loops=1) Index Cond: (relname = $1) Filter: (oid = $0) Buffers: shared hit=4 InitPlan 1 (returns $0,$1) -> Limit (actual time=0.019..0.020 rows=1 loops=1) Buffers: shared hit=1 -> Seq Scan on pg_class pg_class_1 (actual time=0.015..0.015 rows=1 loops=1) Filter: (relkind = 'r'::"char") Rows Removed by Filter: 5 Buffers: shared hit=1
ou comme ça:
"Append (cost=868.60..878.95 rows=2 width=233) (actual time=0.024..0.144 rows=2 loops=1)" " Buffers: shared hit=3" " CTE cl" " -> Seq Scan on pg_class (cost=0.00..868.60 rows=9972 width=537) (actual time=0.016..0.042 rows=101 loops=1)" " Buffers: shared hit=3" " -> Limit (cost=0.00..0.10 rows=1 width=233) (actual time=0.023..0.024 rows=1 loops=1)" " Buffers: shared hit=1" " -> CTE Scan on cl (cost=0.00..997.20 rows=9972 width=233) (actual time=0.021..0.021 rows=1 loops=1)" " Buffers: shared hit=1" " -> Limit (cost=10.00..10.10 rows=1 width=233) (actual time=0.117..0.118 rows=1 loops=1)" " Buffers: shared hit=2" " -> CTE Scan on cl cl_1 (cost=0.00..997.20 rows=9972 width=233) (actual time=0.001..0.104 rows=101 loops=1)" " Buffers: shared hit=2" "Planning Time: 0.634 ms" "Execution Time: 0.248 ms"
Mais lire le plan avec le texte «de la feuille» est très difficile et bien-aimé:
- le nœud affiche la somme des ressources du sous-arbre
c'est-à-dire, pour comprendre combien de temps il a fallu pour exécuter un nœud particulier, ou exactement combien cette lecture de la table a généré des données du disque - vous devez en quelque sorte soustraire l'un de l'autre - le temps du nœud doit être multiplié par des boucles
oui, la soustraction n'est pas l'opération la plus difficile à faire «dans l'esprit» - après tout, le temps d'exécution est indiqué en moyenne sur une exécution du nœud, et il peut y en avoir des centaines - eh bien, et tout cela ensemble, il est difficile de répondre à la question principale - alors qui est le «maillon le plus faible» ?
Lorsque nous avons essayé d'expliquer tout cela à plusieurs centaines de nos développeurs, nous avons réalisé que de l'extérieur, cela ressemble à ceci:

Et cela signifie que nous avons besoin de ...
Instrument
Dans ce document, nous avons essayé de rassembler toutes les mécaniques clés qui aident selon le plan et de demander à comprendre "qui est à blâmer et quoi faire." Eh bien, partagez une partie de votre expérience avec la communauté.
Rencontrer et utiliser -
expliquer.tensor.ruPlans clairs
Est-il facile de comprendre un plan à quoi il ressemble?
Seq Scan on pg_class (actual time=0.009..1.304 rows=6609 loops=1) Buffers: shared hit=263 Planning Time: 0.108 ms Execution Time: 1.800 ms
Pas vraiment.
Mais comme ça,
sous une forme abrégée , lorsque les indicateurs clés sont séparés - c'est déjà beaucoup plus clair:
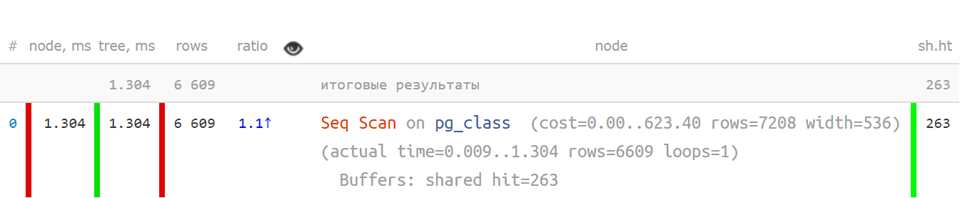
Mais si le plan est plus compliqué, la
distribution du temps par
diagramme par nœuds viendra à la
rescousse :
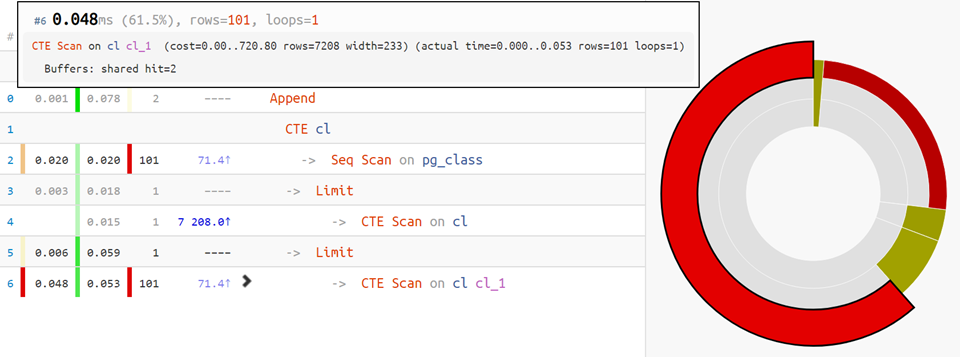
Eh bien, pour les options les plus difficiles,
le diagramme d'exécution se dépêche d'aider:
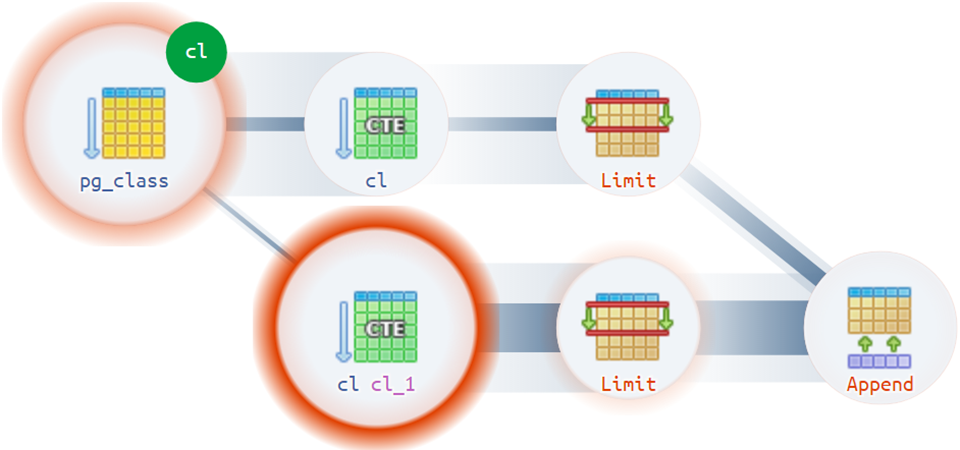
Par exemple, il existe des situations assez banales lorsqu'un plan peut avoir plusieurs racines réelles:
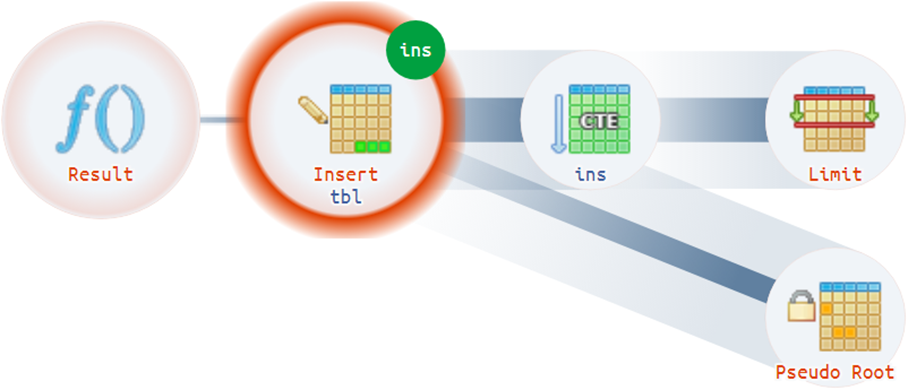
Conseils structurels
Eh bien, et si toute la structure du plan et ses points sensibles sont déjà présentés et visibles - pourquoi ne pas les mettre en évidence avec le développeur et les expliquer avec la «langue russe»?

Nous avons déjà collecté une douzaine de modèles de recommandations de ce type.
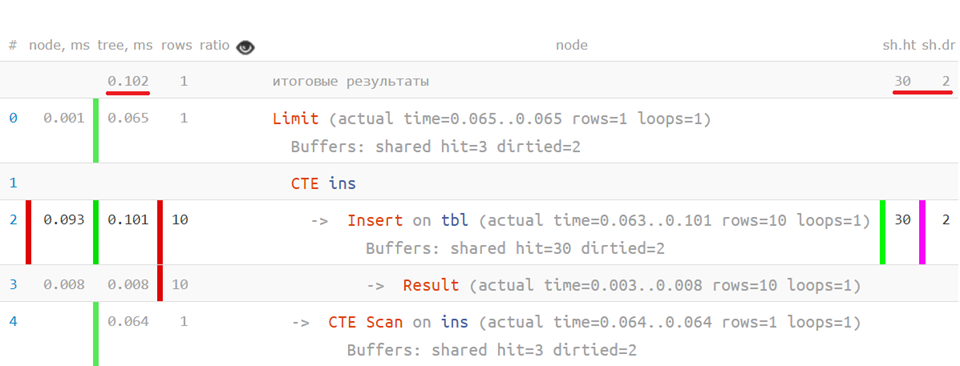
Profileur de requête
Maintenant, si vous placez la requête d'origine sur le plan analysé, vous pouvez voir combien de temps cela a pris pour chaque opérateur individuel - quelque chose comme ceci:
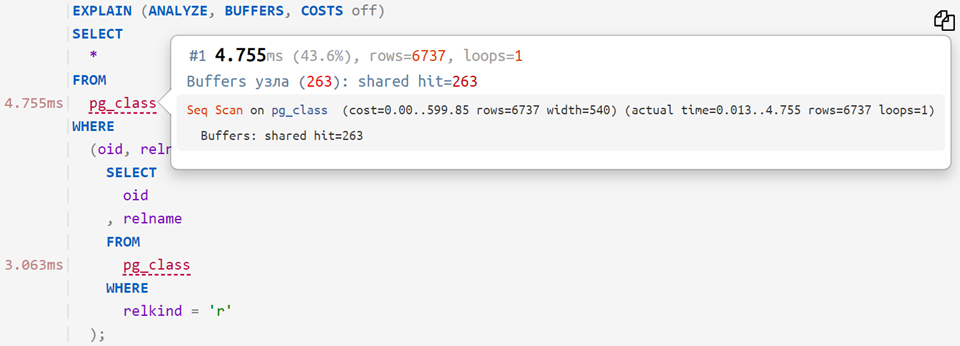
... ou même ainsi:

Substitution de paramètres dans la demande
Si vous avez "attaché" non seulement la demande au plan, mais aussi ses paramètres à partir de la ligne DETAIL du journal, vous pouvez le copier en plus dans l'une des options:
- avec substitution de valeurs dans la demande
pour une exécution directe sur sa base et un profilage supplémentaire
SELECT 'const', 'param'::text;
- avec substitution de valeur via PREPARE / EXECUTE
pour émuler le travail du planificateur lorsque la partie paramétrique peut être ignorée - par exemple, lorsque vous travaillez sur des tables partitionnées
DEALLOCATE ALL; PREPARE q(text) AS SELECT 'const', $1::text; EXECUTE q('param'::text);
Archive des plans
Insérez, analysez, partagez avec vos collègues! Les plans resteront dans les archives, et vous pourrez y revenir plus tard:
expliquez.tensor.ru/archiveMais si vous ne voulez pas que d'autres voient votre plan, n'oubliez pas de cocher la case "ne pas publier dans l'archive".
Dans les articles suivants, je parlerai des difficultés et des solutions qui surgissent dans l'analyse du plan.