Salut
Il arrive que vous regardiez un film, et dans votre tête il n'y a qu'une seule question - "Suis-je de nouveau en train de recevoir des appâts?" Nous allons résoudre ce problème et nous ne regarderons que des films appropriés. Je suggère d'expérimenter un peu les données et d'écrire un réseau neuronal simple pour évaluer le film.
Notre expérience est basée sur la technologie d'analyse des sentiments pour déterminer l'humeur du public pour un produit. En tant que données, nous prenons un ensemble de données d'avis d'utilisateurs sur les films IMDb. L'environnement de développement de Google Colab vous permettra de former rapidement votre réseau de neurones grâce à un accès gratuit au GPU (NVidia Tesla K80).
J'utilise la bibliothèque Keras, à l'aide de laquelle je vais construire un modèle universel pour résoudre des problèmes similaires d'apprentissage automatique. J'aurai besoin du backend TensorFlow, la version par défaut de Colab 1.15.0, il suffit donc de passer à 2.0.0.
from __future__ import absolute_import, division, print_function, unicode_literals import tensorflow as tf !tf_upgrade_v2 -h
Ensuite, nous importons tous les modules nécessaires pour le prétraitement des données et la construction de modèles. Dans les articles précédents, l'accent est mis sur les bibliothèques, vous pouvez y regarder.
%matplotlib inline import matplotlib import matplotlib.pyplot as plt
import numpy as np from keras.utils import to_categorical from keras import models from keras import layers from keras.datasets import imdb
Analyse des données IMDb
L'ensemble de données IMDb comprend 50 000 critiques de films d'utilisateurs notés positif (1) et négatif (0).
- Les avis sont prétraités et chacun d'eux est codé par une séquence d'indices de mots sous forme d'entiers
- Les mots dans les revues sont indexés par leur fréquence totale dans l'ensemble de données. Par exemple, l'entier «2» code le deuxième mot le plus utilisé
- 50 000 avis sont divisés en deux ensembles: 25 000 pour la formation et 25 000 pour les tests.
Téléchargez l'ensemble de données intégré à Keras. Étant donné que les données sont divisées en formation et test dans un rapport de 50-50, je les combinerai pour que plus tard je puisse les diviser par 80-20.
from keras.datasets import imdb (training_data, training_targets), (testing_data, testing_targets) = imdb.load_data(num_words=10000) data = np.concatenate((training_data, testing_data), axis=0) targets = np.concatenate((training_targets, testing_targets), axis=0)
Exploration des données
Voyons ce avec quoi nous travaillons.
print("Categories:", np.unique(targets)) print("Number of unique words:", len(np.unique(np.hstack(data))))

length = [len(i) for i in data] print("Average Review length:", np.mean(length)) print("Standard Deviation:", round(np.std(length)))

Vous pouvez voir que toutes les données appartiennent à deux catégories: 0 ou 1, ce qui représente l'ambiance de la revue. L'ensemble de données contient 9998 mots uniques, la taille moyenne des avis est de 234 mots avec un écart-type de 173.
Regardons le premier examen de cet ensemble de données, qui est marqué comme positif.
print("Label:", targets[0]) print(data[0])

index = imdb.get_word_index() reverse_index = dict([(value, key) for (key, value) in index.items()]) decoded = " ".join( [reverse_index.get(i - 3, "#") for i in data[0]] ) print(decoded)

Préparation des données
Il est temps de préparer les données. Nous devons vectoriser chaque enquête et la remplir de zéros pour que le vecteur contienne exactement 10 000 nombres. Cela signifie que chaque avis de moins de 10 000 mots est rempli de zéros. Je le fais parce que la plus grande vue d'ensemble est presque de la même taille, et chaque élément d'entrée de notre réseau neuronal devrait avoir la même taille. Vous devez également convertir les variables en type flottant.
def vectorize(sequences, dimension = 10000): results = np.zeros((len(sequences), dimension)) for i, sequence in enumerate(sequences): results[i, sequence] = 1 return results data = vectorize(data) targets = np.array(targets).astype("float32")
Ensuite, je divise l'ensemble de données en données de formation et de test comme convenu 4: 1.
test_x = data[:10000] test_y = targets[:10000] train_x = data[10000:] train_y = targets[10000:]
Créer et former un modèle
La chose est petite, il ne reste plus qu'à écrire un modèle et à le former. Commencez par choisir un type. Deux types de modèles sont disponibles dans Keras: séquentiels et avec une API fonctionnelle. Ensuite, vous devez ajouter des couches d'entrée, cachées et de sortie.
Pour éviter le sur-ajustement, nous utiliserons un "dropout" entre eux. Sur chaque couche, la fonction "dense" est utilisée pour relier complètement les couches entre elles. Dans les couches cachées, nous utiliserons la fonction d'activation «relu», ce qui conduit presque toujours à des résultats satisfaisants. Sur la couche de sortie, nous utilisons une fonction sigmoïde qui renormalise les valeurs dans la plage de 0 à 1.
J'utilise l'optimiseur adam, il changera de poids pendant la formation.
Nous utilisons l'entropie croisée binaire comme fonction de perte et la précision comme mesure métrique.
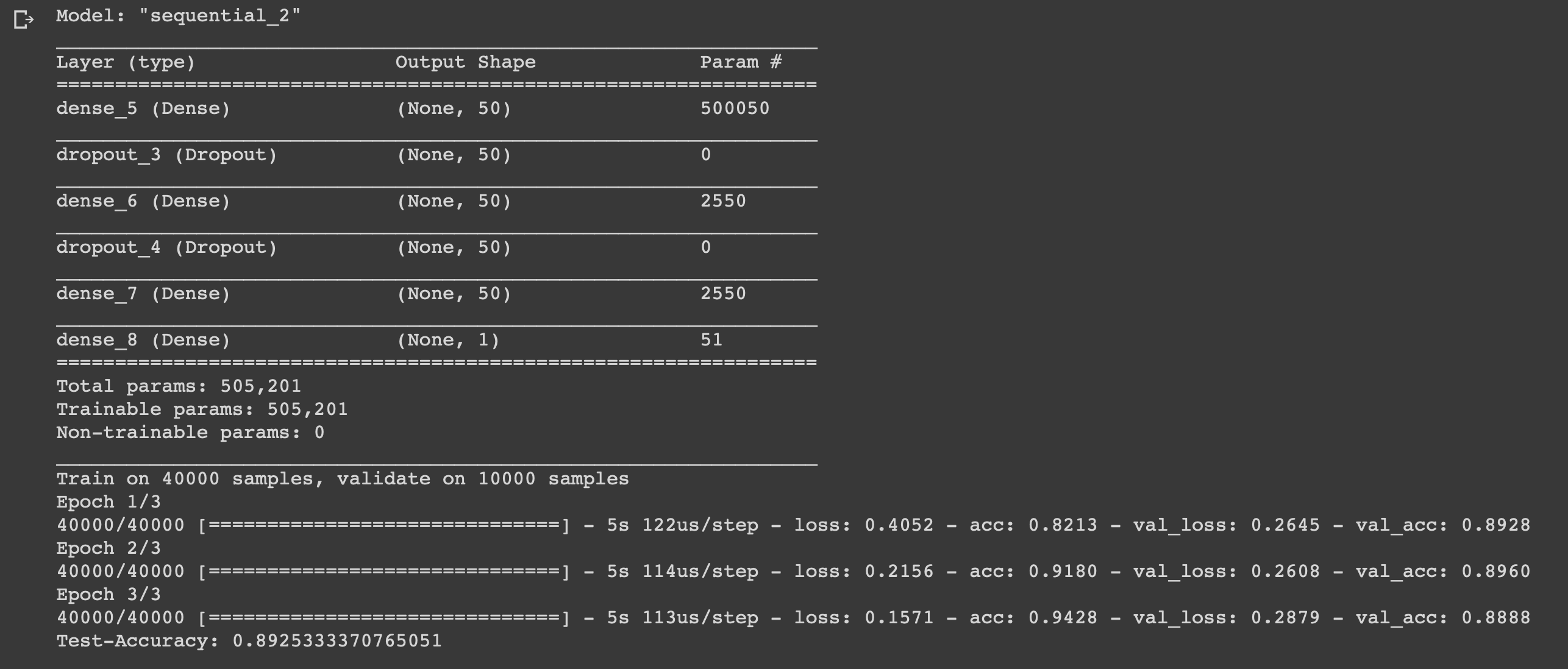
Vous pouvez maintenant former notre modèle. Nous le ferons avec une taille de lot de 500 et seulement trois époques, car il a été révélé que le modèle commence à se recycler s'il est entraîné plus longtemps.
model = models.Sequential()
Conclusion
Nous avons créé un réseau neuronal simple à six couches qui peut calculer l'humeur des cinéastes avec une précision de 0,89. Bien sûr, pour regarder des films sympas, il n'est pas du tout nécessaire d'écrire un réseau de neurones, mais ce n'était qu'un autre exemple de la façon dont vous pouvez utiliser les données, en bénéficier, car vous en avez besoin pour cela. Le réseau de neurones est universel en raison de la simplicité de sa structure, en modifiant certains paramètres, vous pouvez l'adapter à des tâches complètement différentes.
N'hésitez pas à écrire vos idées dans les commentaires.