
La conception de systèmes d'analyse en continu et de traitement de données en continu a ses propres nuances, ses propres problèmes et sa propre pile technologique. Nous en avons parlé dans la prochaine
leçon ouverte , tenue à la veille du lancement du cours
Data Engineer .
Lors du webinaire discuté:
- lorsque le traitement en streaming est nécessaire;
- quels éléments sont dans SPOD, quels outils pouvons-nous utiliser pour implémenter ces éléments;
- comment construire votre propre système d'analyse clickstream.
Conférencier -
Yegor Mateshuk , ingénieur principal des données chez MaximaTelecom.
Quand le streaming est-il nécessaire? Stream vs Batch
Tout d'abord, nous devons déterminer quand nous avons besoin de streaming et lors du traitement par lots. Expliquons les forces et les faiblesses de ces approches.
Ainsi, les inconvénients du traitement par lots:- les données sont livrées avec un retard. Puisque nous avons une certaine période de calculs, alors pour cette période, nous sommes toujours en retard sur le temps réel. Et plus il y a d'itérations, plus nous prenons de retard. Ainsi, nous obtenons un délai, qui dans certains cas est critique;
- une charge de pointe sur le fer est créée. Si nous calculons beaucoup en mode batch, à la fin de la période (jour, semaine, mois) nous avons une charge de pointe, car vous devez calculer beaucoup de choses. À quoi cela mène-t-il? Premièrement, nous commençons à nous appuyer sur des limites qui, comme vous le savez, ne sont pas infinies. Par conséquent, le système fonctionne régulièrement jusqu'à la limite, ce qui entraîne souvent des échecs. Deuxièmement, comme tous ces emplois démarrent en même temps, ils se font concurrence et sont calculés assez lentement, c'est-à-dire que vous ne pouvez pas compter sur un résultat rapide.
Mais le traitement par lots a ses avantages:- haute efficacité. Nous n'irons pas plus loin, car l'efficacité est associée à la compression, aux frameworks et à l'utilisation de formats de colonnes, etc. Le fait est que le traitement par lots, si vous prenez le nombre d'enregistrements traités par unité de temps, sera plus efficace;
- facilité de développement et de support. Vous pouvez traiter n'importe quelle partie des données en testant et en recomptant si nécessaire.
Avantages du streaming de traitement de données (streaming):- résultat en temps réel. Nous n'attendons la fin d'aucune période: dès que les données (même très petites) nous parviennent, nous pouvons immédiatement les traiter et les transmettre. C'est-à-dire que le résultat, par définition, tend vers le temps réel;
- charge uniforme sur le fer. Il est clair qu'il existe des cycles quotidiens, etc., cependant, la charge est toujours répartie tout au long de la journée et elle s'avère plus uniforme et prévisible.
Le principal inconvénient du traitement en streaming:- complexité du développement et du support. Tout d'abord, les tests, la gestion et la récupération des données sont un peu plus difficiles par rapport au lot. La deuxième difficulté (en fait, c'est le problème le plus fondamental) est associée aux annulations. Si les emplois n'ont pas fonctionné et qu'il y a eu un échec, il est très difficile de saisir exactement le moment où tout s'est cassé. Et résoudre le problème vous demandera plus d'efforts et de ressources que le traitement par lots.
Donc, si vous pensez
que vous avez besoin de flux , répondez vous-même aux questions suivantes:
- Avez-vous vraiment besoin de temps réel?
- Existe-t-il de nombreuses sources de streaming?
- La perte d'un enregistrement est-elle critique?
Regardons
deux exemples :
Exemple 1. Analyse des stocks pour la vente au détail:- l'affichage des marchandises ne change pas en temps réel;
- les données sont le plus souvent livrées en mode batch;
- la perte d'informations est critique.
Dans cet exemple, il est préférable d'utiliser le lot.
Exemple 2. Analytique pour un portail Web:- la vitesse d'analyse détermine le temps de réaction à un problème;
- les données arrivent en temps réel;
- Les pertes d'une petite quantité d'informations sur les activités des utilisateurs sont acceptables.
Imaginez que l'analyse reflète la façon dont les visiteurs d'un portail Web se sentent en utilisant votre produit. Par exemple, vous avez déployé une nouvelle version et vous devez comprendre dans un délai de 10 à 30 minutes si tout est en ordre, si des fonctionnalités personnalisées se sont cassées. Disons que le texte du bouton "Commander" a disparu - les analyses vous permettront de réagir rapidement à une forte baisse du nombre de commandes, et vous comprendrez immédiatement que vous devez revenir en arrière.
Ainsi, dans le deuxième exemple, il est préférable d'utiliser des flux.
Éléments SPOD
Les ingénieurs en traitement de données capturent, déplacent, livrent, convertissent et stockent ces mêmes données (oui, le stockage de données est également un processus actif!).
Par conséquent, afin de construire un système de traitement de données en continu (SPOD), nous aurons besoin des éléments suivants:
- chargeur de données (moyen de livraison des données au stockage);
- bus d'échange de données (ce n'est pas toujours nécessaire, mais il n'y a aucun moyen dans les flux sans lui, car vous avez besoin d'un système à travers lequel vous échangerez des données en temps réel);
- stockage de données (comme sans);
- Moteur ETL (nécessaire pour effectuer diverses opérations de filtrage, de tri et autres);
- BI (pour afficher les résultats);
- orchestrateur (relie l'ensemble du processus, organise le traitement des données en plusieurs étapes).
Dans notre cas, nous considérerons la situation la plus simple et nous concentrerons uniquement sur les trois premiers éléments.
Outils de traitement de flux de données
Nous avons plusieurs «candidats» pour le rôle de
chargeur de
données :
- Canal Apache
- Apache nifi
- Streamset
Canal Apache
Le premier dont nous parlerons est
Apache Flume , un outil pour transporter des données entre différentes sources et référentiels.

Avantages:
- il y a presque partout
- longtemps utilisé
- suffisamment flexible et extensible
Inconvénients:
- configuration peu pratique
- difficile à surveiller
Quant à sa configuration, elle ressemble à ceci:

Ci-dessus, nous créons un canal simple qui se trouve sur le port, en prend les données et les enregistre simplement. En principe, pour décrire un processus, c'est toujours normal, mais lorsque vous en avez des dizaines, le fichier de configuration se transforme en enfer. Quelqu'un ajoute des configurateurs visuels, mais pourquoi s'embêter s'il existe des outils qui le rendent prêt à l'emploi? Par exemple, les mêmes NiFi et StreamSets.
Apache nifi
En fait, il joue le même rôle que Flume, mais avec une interface visuelle, ce qui est un gros plus, surtout quand il y a beaucoup de processus.
Quelques faits sur NiFi
- développé à l'origine à la NSA;
- Hortonworks est maintenant pris en charge et développé;
- une partie de HDF de Hortonworks;
- dispose d'une version spéciale de MiNiFi pour la collecte de données à partir d'appareils.
Le système ressemble à ceci:
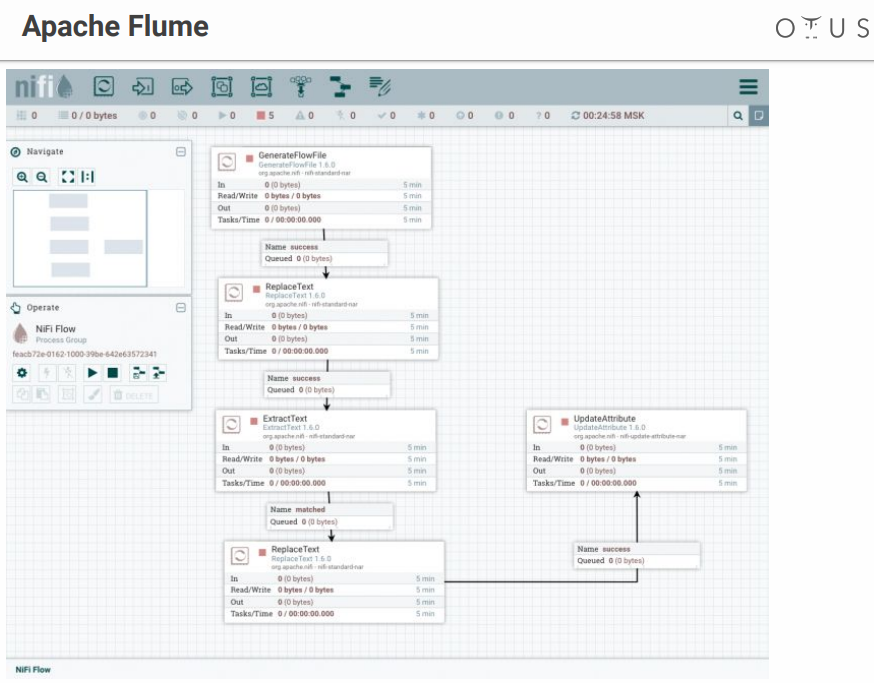
Nous avons un champ de créativité et d'étapes de traitement des données que nous y jetons. Il existe de nombreux connecteurs pour tous les systèmes possibles, etc.
Streamset
C'est également un système de contrôle de flux de données avec une interface visuelle. Il a été développé par des gens de Cloudera, il est facilement installé comme Parcel sur CDH, il a une version spéciale de SDC Edge pour collecter des données à partir d'appareils.
Se compose de deux éléments:
- SDC - un système qui effectue un traitement direct des données (gratuit);
- StreamSets Control Hub - un centre de contrôle pour plusieurs SDC avec des fonctionnalités supplémentaires pour le développement de lignes de paiement (payantes).
Cela ressemble à ceci:

Moment désagréable - StreamSets ont des pièces gratuites et payantes.
Bus de données
Voyons maintenant où nous allons télécharger ces données. Candidats:
Apache Kafka est la meilleure option, mais si vous avez RabbitMQ ou NATS dans votre entreprise et que vous devez ajouter un peu d'analyse, le déploiement de Kafka à partir de zéro ne sera pas très rentable.
Dans tous les autres cas, Kafka est un excellent choix. En fait, c'est un courtier de messages avec une mise à l'échelle horizontale et une bande passante énorme. Il est parfaitement intégré à l'ensemble de l'écosystème d'outils pour travailler avec les données et peut supporter de lourdes charges. Il a une interface universelle et est le système circulatoire de notre traitement des données.
À l'intérieur, Kafka est divisé en sujet - un certain flux de données distinct des messages avec le même schéma ou, au moins, avec le même objectif.
Pour discuter de la nuance suivante, vous devez vous rappeler que les sources de données peuvent varier légèrement. Le format des données est très important:

Le format de sérialisation des données Apache Avro mérite une mention spéciale. Le système utilise JSON pour déterminer la structure de données (schéma) qui est sérialisée en un
format binaire compact . Par conséquent, nous économisons une énorme quantité de données et la sérialisation / désérialisation est moins chère.
Tout semble aller bien, mais la présence de fichiers séparés avec des circuits pose un problème, car nous devons échanger des fichiers entre différents systèmes. Il semblerait que c'est simple, mais lorsque vous travaillez dans différents départements, les gars de l'autre côté peuvent changer quelque chose et se calmer, et tout va tomber en panne pour vous.
Afin de ne pas transférer tous ces fichiers sur des lecteurs flash, des disquettes et des peintures rupestres, il existe un service spécial - Registre de schéma. Il s'agit d'un service de synchronisation d'avro-schémas entre des services qui écrivent et lisent à partir de Kafka.

Pour Kafka, le producteur est celui qui écrit, le consommateur est celui qui consomme (lit) les données.
Entrepôt de données
Challengers (en fait, il y a beaucoup plus d'options, mais n'en prenez que quelques-unes):
- HDFS + Hive
- Kudu + Impala
- Clickhouse
Avant de choisir un référentiel, rappelez-vous ce qu'est l'
idempotence . Wikipédia dit que l'idempotence (idem latin - le même + potens - capable) - la propriété d'un objet ou d'une opération lors de la nouvelle application de l'opération à l'objet, donne le même résultat que le premier. Dans notre cas, le processus de traitement en continu doit être construit de sorte que lors du remplissage des données source, le résultat reste correct.
Comment y parvenir dans les systèmes de streaming:
- identifier un identifiant unique (peut être composite)
- utilisez cet identifiant pour dédupliquer les données
Le stockage HDFS + Hive
ne fournit pas l'idempotence pour l'enregistrement en streaming «prêt à l'emploi», nous avons donc:
Kudu est un référentiel adapté aux requêtes analytiques, mais avec une clé primaire, pour la déduplication.
Impala est l'interface SQL de ce référentiel (et de plusieurs autres).
Quant à ClickHouse, il s'agit d'une base de données analytique de Yandex. Son objectif principal est l'analyse sur une table remplie d'un grand flux de données brutes. Parmi les avantages - il existe un moteur ReplacingMergeTree pour la déduplication des clés (la déduplication est conçue pour économiser de l'espace et peut laisser des doublons dans certains cas, vous devez prendre en compte les
nuances ).
Reste à ajouter quelques mots sur
Divolte . Si vous vous en souvenez, nous avons parlé du fait que certaines données doivent être saisies. Si vous avez besoin d'organiser rapidement et facilement des analyses pour un portail, Divolte est un excellent service pour capturer les événements des utilisateurs sur une page Web via JavaScript.
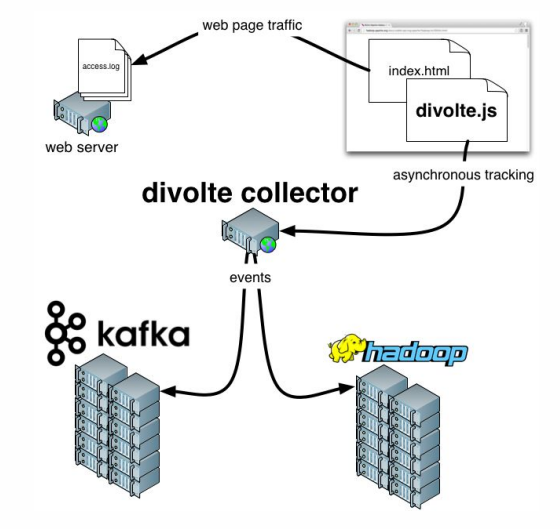
Exemple pratique
Qu'essayons-nous de faire?
Essayons de construire un pipeline pour collecter les données Clickstream en temps réel.
Clickstream est une empreinte virtuelle qu'un utilisateur laisse lorsqu'il est sur votre site. Nous allons capturer des données à l'aide de Divolte et les écrire dans Kafka.

Vous avez besoin de Docker pour fonctionner, et vous devez cloner le
référentiel suivant . Tout ce qui se passera sera lancé dans des conteneurs. Pour exécuter régulièrement plusieurs conteneurs à la fois,
docker-compose.yml sera utilisé. De plus, il existe un
Dockerfile compilant nos StreamSets avec certaines dépendances.
Il existe également trois dossiers:
- les données clickhouse seront écrites dans clickhouse-data
- exactement le même papa ( sdc-data ) que nous aurons pour StreamSets, où le système peut stocker des configurations
- le troisième dossier ( exemples ) comprend un fichier de demande et un fichier de configuration de canal pour StreamSets

Pour commencer, entrez la commande suivante:
docker-compose up
Et nous apprécions la façon dont les conteneurs démarrent lentement mais sûrement. Après le démarrage, nous pouvons aller à l'adresse
http: // localhost: 18630 / et toucher immédiatement Divolte:

Nous avons donc Divolte, qui a déjà reçu des événements et les a enregistrés à Kafka. Essayons de les calculer en utilisant StreamSets:
http: // localhost: 18630 / (mot de passe / login - admin / admin).

Afin de ne pas souffrir, il est préférable d'
importer Pipeline , en le nommant, par exemple,
clickstream_pipeline . Et à partir du dossier d'exemples, nous importons
clickstream.json . Si tout va bien,
nous verrons l'image suivante :

Nous avons donc créé une connexion à Kafka, enregistré quel Kafka nous avons besoin, enregistré quel sujet nous intéresse, puis sélectionné les champs qui nous intéressent, puis mis un drain dans Kafka, enregistrant quel Kafka et quel sujet. Les différences sont que dans un cas, le format de données est Avro et dans le second, il s'agit simplement de JSON.
Continuons. Nous pouvons, par exemple,
faire un aperçu qui capture certains enregistrements en temps réel à partir de Kafka. Ensuite, nous écrivons tout.
Après le lancement, nous verrons qu'un flux d'événements vole vers Kafka, et cela se produit en temps réel:

Vous pouvez maintenant créer un référentiel pour ces données dans ClickHouse. Pour travailler avec ClickHouse, vous pouvez utiliser un client natif simple en exécutant la commande suivante:
docker run -it --rm --network divolte-ss-ch_default yandex/clickhouse-client --host clickhouse
Veuillez noter que cette ligne indique le réseau auquel vous souhaitez vous connecter. Et selon la façon dont vous nommez le dossier avec le référentiel, le nom de votre réseau peut différer. En général, la commande sera la suivante:
docker run -it --rm --network {your_network_name} yandex/clickhouse-client --host clickhouse
La liste des réseaux peut être consultée avec la commande:
docker network ls
Eh bien, il ne reste plus rien:
1.
Tout d'abord, «signez» notre ClickHouse à Kafka , «lui expliquant» le format des données dont nous avons besoin:
CREATE TABLE IF NOT EXISTS clickstream_topic ( firstInSession UInt8, timestamp UInt64, location String, partyId String, sessionId String, pageViewId String, eventType String, userAgentString String ) ENGINE = Kafka SETTINGS kafka_broker_list = 'kafka:9092', kafka_topic_list = 'clickstream', kafka_group_name = 'clickhouse', kafka_format = 'JSONEachRow';
2.
Nous allons maintenant créer un vrai tableau où nous mettrons les données finales:
CREATE TABLE clickstream ( firstInSession UInt8, timestamp UInt64, location String, partyId String, sessionId String, pageViewId String, eventType String, userAgentString String ) ENGINE = ReplacingMergeTree() ORDER BY (timestamp, pageViewId);
3.
Et puis nous fournirons une relation entre ces deux tables :
CREATE MATERIALIZED VIEW clickstream_consumer TO clickstream AS SELECT * FROM clickstream_topic;
4.
Et maintenant, nous allons sélectionner les champs nécessaires :
SELECT * FROM clickstream;
Par conséquent, le choix dans la table cible nous donnera le résultat dont nous avons besoin.
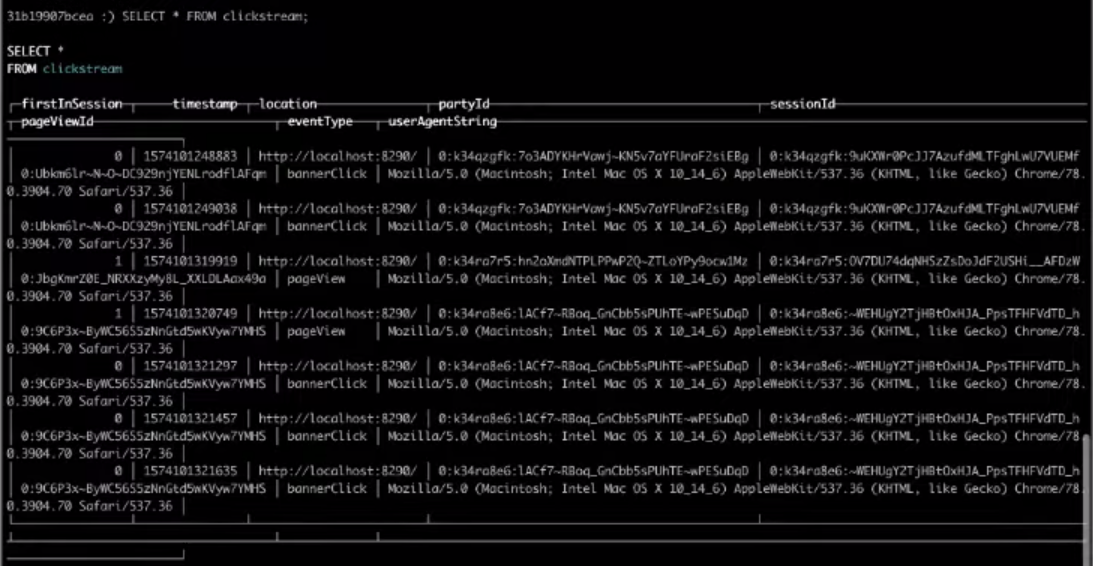
C'est tout, c'était le Clickstream le plus simple que vous puissiez créer. Si vous souhaitez effectuer vous-même les étapes ci-dessus,
regardez l' intégralité de la
vidéo .