
L'histoire de l'apprentissage automatique a commencé au milieu du siècle dernier. À cette époque, cette technologie était davantage un domaine de recherche et d'expériences scientifiques, et de puissants ordinateurs ont donné une impulsion à l'application pratique du ML.
Aujourd'hui, l'apprentissage automatique est une tendance indéniable sur le marché informatique. De plus en plus d'entreprises de différents secteurs créent des divisions de science des données afin d'utiliser l'apprentissage automatique pour trouver de nouvelles opportunités dans les données accumulées pour la croissance et l'amélioration de l'efficacité des entreprises. Cependant, alors que ces initiatives ne donnent pas le rendement voulu. Selon les statistiques, 8 cas confirmés sur 10 ne sont pas commercialisés.
Très probablement, la plupart d'entre vous ont entendu la blague "la diapositive PowerPoint est le moyen le plus efficace de rendre l'apprentissage automatique plus productif". Malheureusement, ce n'est pas une blague. Souvent, l'ensemble du processus ressemble à ceci: une entreprise transmet des données et une analyse de rentabilité téléchargée à partir de systèmes d'entreprise. Les scientifiques des données développent un modèle d'apprentissage automatique dans le bloc-notes Jupiter, une capture d'écran des graphiques est placée sur une diapositive PowerPoint et envoyée au client professionnel. Est-il possible d'utiliser la diapositive résultante pour prendre des décisions de gestion? Probablement pas, car les données de prévision deviennent rapidement obsolètes et la situation dans l'entreprise pendant cette période peut sérieusement changer.
En essayant de surmonter tous les obstacles et de mettre l'apprentissage automatique en marche, la plupart des entreprises investissent dans l'infrastructure de collecte, de stockage et de traitement de grandes quantités de données - Data Lake. Bien sûr, c'est une étape nécessaire. Mais qu'est-ce que cela change d'un point de vue commercial? Est-il possible de prendre des décisions basées sur l'apprentissage automatique? Non, car il existe un écart entre Data Lake et l'entreprise. De toute évidence, pourquoi 86% des entreprises interrogées pensent que les applications métier de nouvelle génération devraient être équipées du machine learning.
Chez SAP, nous avons décidé d'écrire une série d'articles sur la façon de surmonter les difficultés existantes avec la nouvelle plateforme SAP Data Intelligence et de mettre un outil aussi puissant que l'apprentissage automatique au service des entreprises. Et, si vous êtes intéressé par ce sujet, lisez la suite :)
Pour commencer, je vais vous parler de la première et très importante étape du développement de toute analyse de rentabilisation «Recherche et préparation de données». Dans les articles suivants, nous examinerons les étapes «Développement et formation des modèles», «Intégration détaillée avec les sources de données SAP et non SAP sur site et dans le cloud», «Création de services pour l'utilisation de modèles», «Transférer des analyses de rentabilisation vers des modèles productifs», «Surveillance et le fonctionnement des analyses de rentabilisation »et bien plus encore.
Développement d'un business case basé sur le machine learning. Recherche et préparation des données.Examinons le processus de création d'une analyse de rentabilisation (figure 1).
Au départ, une idée est généralement formulée par une entreprise. Souvent, il le fait volontiers, car il a un objectif précis de numérisation des fonctions au sein de la transformation numérique de l'ensemble de l'entreprise. Pour collecter, évaluer et hiérarchiser les idées, vous pouvez utiliser, par exemple, SAP Innovation Management.
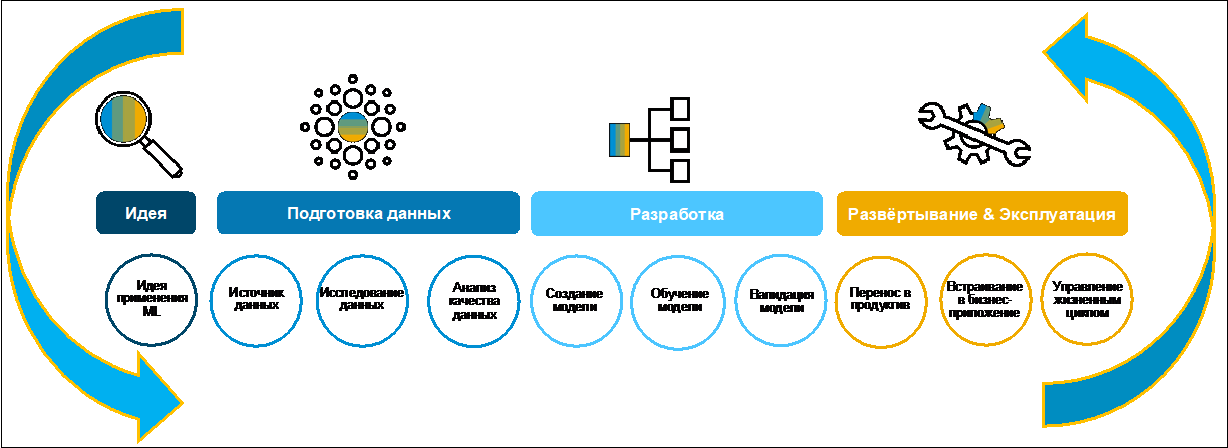 Figure 1
Figure 1Au premier stade de la recherche et de la préparation des données, il est nécessaire de comprendre si elles existent pour l'élaboration d'une analyse de rentabilisation, où elles sont stockées, dans quels formats et de quelle qualité elles sont. Le paysage typique moderne comprend de nombreux systèmes hétérogènes. Les données peuvent être dupliquées dans différentes applications. Trouver les bonnes informations peut prendre beaucoup de temps. À cet effet, dans SAP Data Intelligence, cette tâche a été considérablement simplifiée à l'aide du catalogue de métadonnées. Voyons ce que c'est et comment l'utiliser.
Catalogue de métadonnéesPour utiliser le catalogue de métadonnées, vous devez connecter le système source à Data Intelligence. Les sources de données pour Data Intelligence peuvent être des systèmes sur site SAP ERP, BW, Marketing ... et non SAP MES, Oracle, MS SQL, DB2, Hadoop et bien d'autres, ainsi que des services cloud Amazon, Azzure, Google SCP. Pour vous connecter aux sources de données, vous avez besoin d'informations sur l'emplacement des systèmes et des utilisateurs techniques créés dans ces systèmes spécifiquement pour l'intégration avec SAP Data Intelligence. La figure 2 montre un exemple d'un paysage de données personnalisé dans SAP Data Intelligence.
 Figure 2
Figure 2
Une fois configuré dans le catalogue de métadonnées SAP Data Intelligence, il est possible de voir les informations stockées sur les systèmes connectés. La figure 3 montre la liste des fichiers qui se trouvent dans le dossier DAT263 dans Hadoop connecté à SAP Data Intelligence.
 Figure 3
Figure 3Si vous trouvez les données nécessaires pour implémenter une analyse de rentabilisation, ajoutons des objets de données au catalogue à l'aide de la fonction de publication. J'utiliserai le fichier autos_history.csv, qui contient les statistiques de ventes de voitures d'occasion. Dans la figure 4, vous voyez comment vous pouvez publier un objet de données et ses métadonnées dans le catalogue pour un accès rapide à l'avenir.
 Figure 4
Figure 4Vous pouvez personnaliser la structure du répertoire et les niveaux de hiérarchie en fonction des exigences de votre analyse de rentabilisation. Par exemple, dans mon dossier Habr_demo, toutes les métadonnées sur les objets dont j'ai besoin pour cet article seront collectées.
Le catalogue de métadonnées généré est un accès rapide aux données de l'analyse de rentabilisation. Je procéderai au profilage et à l'analyse de leur qualité sur les objets de mon dossier dans le catalogue de métadonnées SAP Data Intelligence. L'écran initial du catalogue de métadonnées est illustré à la Fig. 5.
 Figure 5
Figure 5Et voici l'objet même de données que j'ai publié dans le dossier Habr_demo (Fig.6)
 Figure 6
Figure 6De plus, pour améliorer et accélérer la recherche, nous pouvons attribuer des balises ou des étiquettes dans le catalogue des objets de données, comme le montre la Fig. 7.
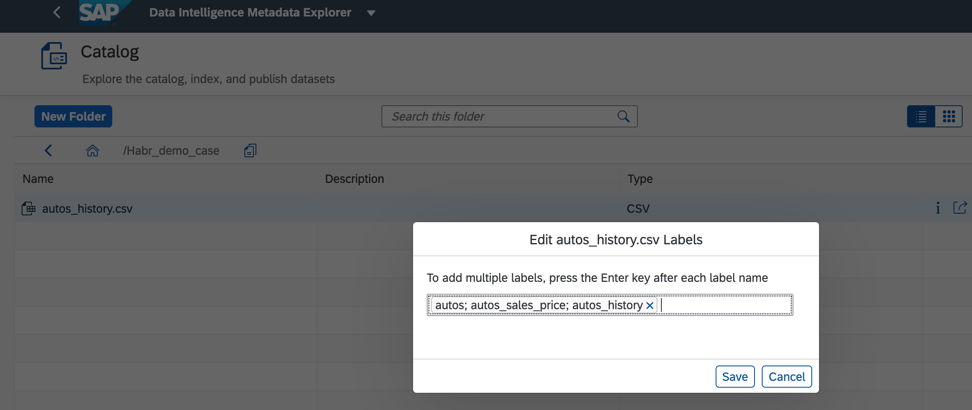 Figure 7
Figure 7Le catalogue de métadonnées vous permet de rechercher des objets par leurs noms, champs, ainsi que par étiquette. Un seul objet de données peut avoir plusieurs étiquettes. C'est pratique si plusieurs développeurs travaillent avec, tout le monde peut attribuer une étiquette à leur analyse de rentabilisation et trouver rapidement tout ce dont vous avez besoin. De plus, les balises peuvent mettre en évidence des données personnelles et confidentielles, dont l'accès doit être strictement limité.
Dans l'ensemble de données considéré, une recherche par étiquette et par nom de champ donne un résultat rapide (Fig. 8). D'accord, c'est très pratique!
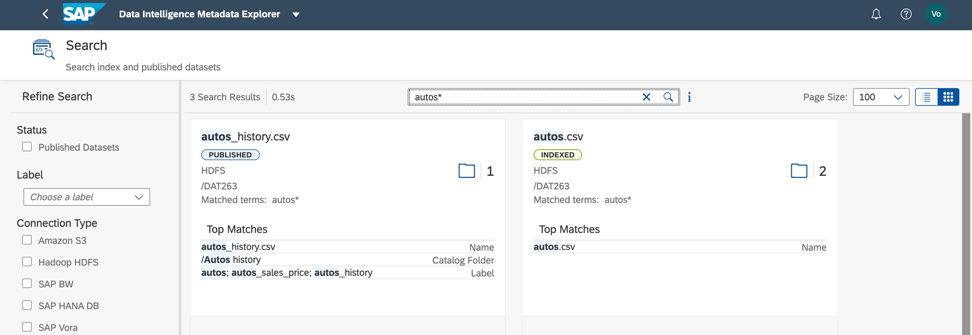 Figure 8
Figure 8Ensuite, nous devons comprendre comment notre dossier est rempli. Pour ce faire, nous pouvons profiler les données. Nous démarrons également le processus à partir du catalogue de métadonnées et du menu contextuel des objets de données (Fig. 9).
 Figure 9
Figure 9Lors du profilage, le catalogue de métadonnées lira le contenu du fichier, analysera sa structure et son remplissage. Le résultat peut être trouvé dans la fiche d'information (Fig. 10).
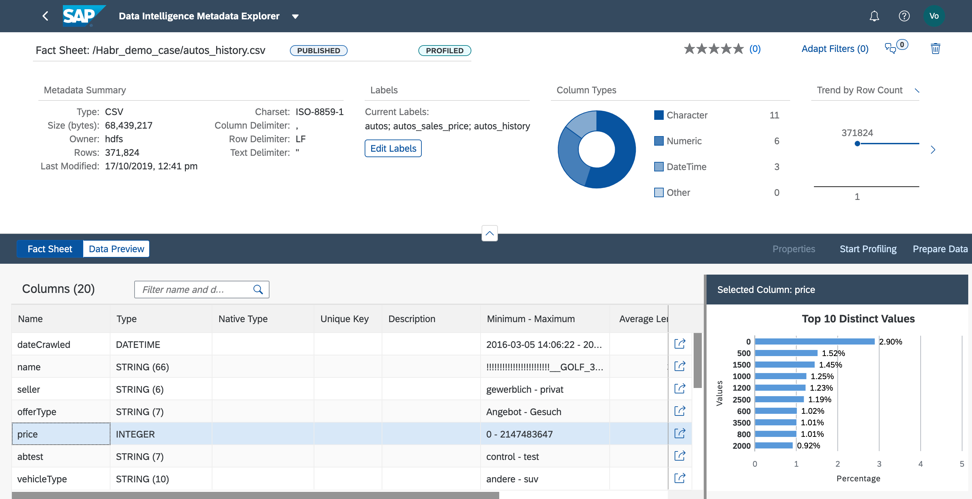 Figure 10
Figure 10
Dans la fiche d'information, nous voyons la structure du fichier et des informations sur le remplissage des champs.
1. Dans le fichier sélectionné, à la suite du profilage, nous avons révélé: le champ vendeur a une valeur I dans toutes les lignes. Cela signifie que nous pouvons supprimer ce champ de l'ensemble de données afin de ne pas utiliser l'apprentissage automatique lors de la construction du modèle, car cela n'affectera pas le résultat de la prévision (Fig. 11).
 Figure 11.2.
Figure 11.2. En analysant la colonne des prix, nous comprenons que près de 3% des données que nous avons contiennent un prix nul. Afin d'utiliser ce fichier dans notre analyse de rentabilisation, nous devons remplir le prix avec les valeurs réelles ou la moyenne de ce produit, ou nous devons supprimer les lignes avec un prix nul du fichier (Fig.12).
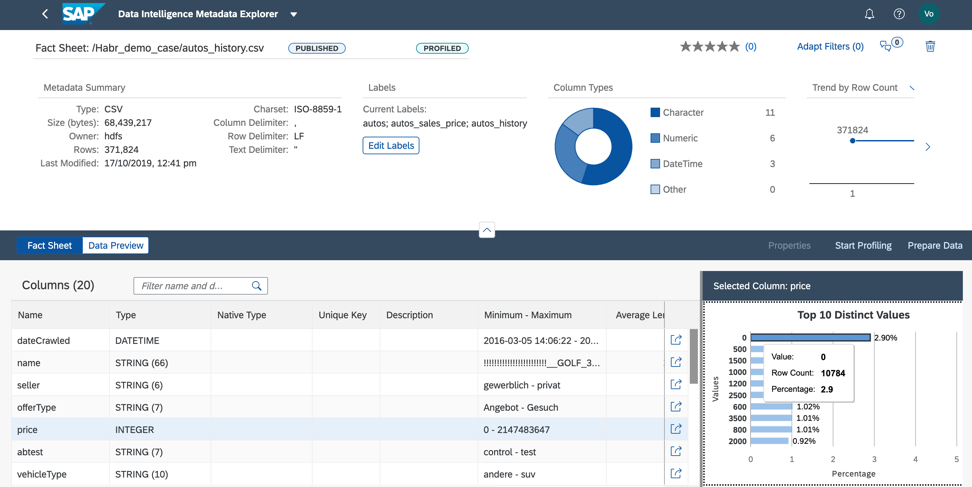 Figure 12.
Figure 12.Nous pouvons effectuer le prétraitement des données de deux manières: dans le catalogue de métadonnées ou directement dans le bloc-notes Jupiter. Le choix de l'outil dépend de la personne responsable du prétraitement des données pour l'analyse de rentabilisation. Si vous êtes analyste, je vous recommande d'utiliser l'interface de préparation des données visuelles, qui est disponible dans le catalogue de métadonnées. Si un scientifique des données est engagé dans la préparation des données, alors le choix devrait certainement être en faveur du Jupiter Notebook, qui est également intégré à Data Intelligence.
3. La valeur du champ du modèle est bien répartie, ce qui nous permettra de former qualitativement le modèle, comme dans la figure 13.
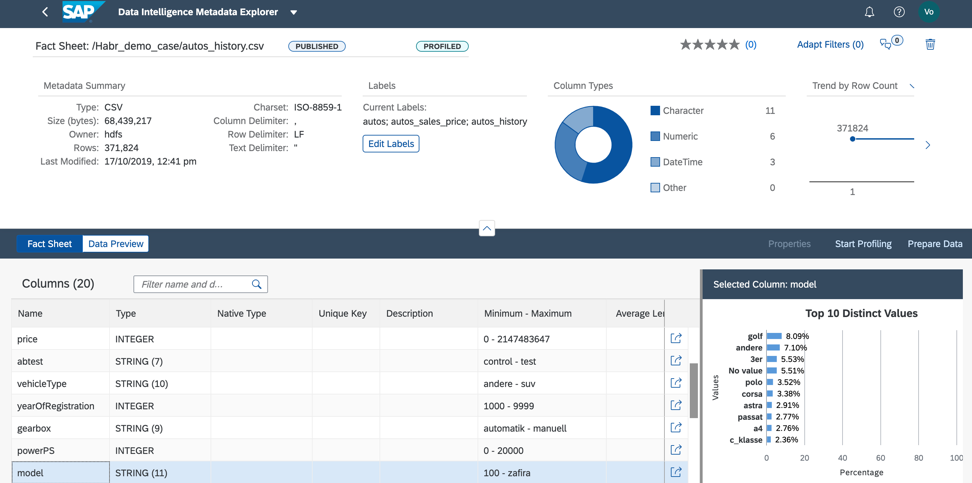 Figure 13.
Figure 13.
Nous comprenons maintenant quels objets de données sont nécessaires pour implémenter une analyse de rentabilisation, quels objets de données sont remplis, quel prétraitement nous devons faire pour utiliser ces données pour implémenter, former et tester le modèle. Mais avant de commencer le prétraitement, vous devez vérifier la qualité des données. Pour ce faire, des règles métier sont disponibles dans le catalogue de métadonnées. Je constate tout de suite qu’actuellement la fonctionnalité des règles d’affaires présente un certain nombre de limitations importantes. Par conséquent, je recommande un prétraitement des données plus ou moins compliqué dans le Jupiter Notebook, qui est intégré à SAP Data Intelligence.
Revenons donc à notre ensemble de données et vérifions la conformité avec les seuils minimum et maximum dans le champ de prix, afin que nous puissions approximativement estimer si les données ont des anomalies ou des valeurs incorrectes. Comme vous l'avez déjà compris, les règles métier sont également configurées dans le catalogue de métadonnées, comme dans la Fig. 14a, c. La relation entre les règles et les données est configurée dans le livre de règles (Rulebook). Cela vous permet d'utiliser les mêmes règles pour vérifier des données différentes.
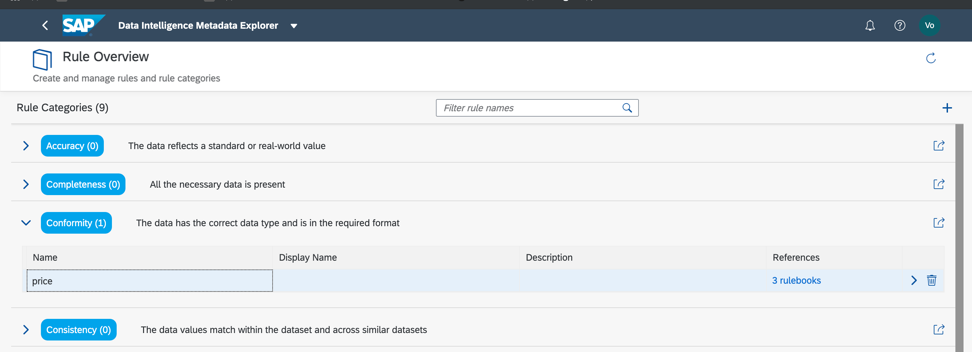 Figure 14 a.
Figure 14 a.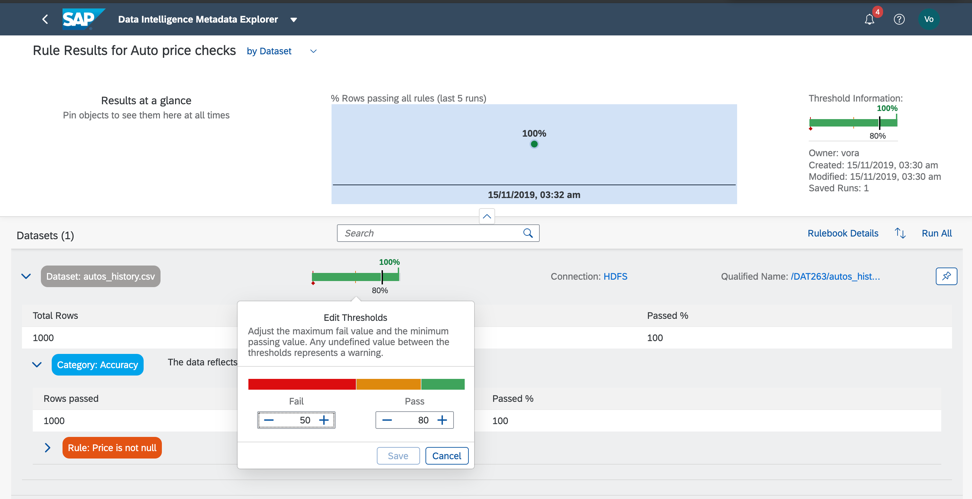 Figure 14 c.
Figure 14 c.Donc, comme nous le voyons, nos données sont 100% correctes.
Mais cela ne se produit pas toujours. Les données peuvent être considérées comme correctes si 75% des enregistrements remplissent les conditions spécifiées dans les règles.
Il est possible d'améliorer la qualité des données, et surtout cela se fait dans les systèmes comptables. Pour ce faire, les entreprises organisent le processus de gestion des données. Une autre raison possible est des critères de qualité des données mal définis.
En résumé, je veux dire sur les avantages et les inconvénients du catalogue de métadonnées.
À mon avis, il présente 3 avantages principaux:
- Simplifiez l'accès aux données.
- Accélérer la récupération des données.
- Interface pratique et intuitive, qui est destinée non seulement aux spécialistes avancés en informatique ou en science des données, mais également aux entreprises impliquées dans la mise en œuvre et la prise en charge de l'analyse de rentabilisation.
Et, bien sûr, sur les défauts. Ils sont évidents. Actuellement, la fonctionnalité du catalogue de métadonnées dans SAP Data Intelligence est au niveau de base. Il peut être suffisant de commencer à utiliser, mais la fonctionnalité ne couvre pas exactement toutes les exigences d'une solution de gestion de données.
Et cela est une conséquence de la nouveauté et de la complexité de SAP Data Intelligence. SAP investit beaucoup de ressources pour améliorer cette solution. Et cela donne confiance que dans un avenir proche, le catalogue de métadonnées deviendra un puissant outil de gestion des données. Il sera possible de créer des règles commerciales complexes sans programmation. Il sera également possible d'intégrer SAP Information Steward et SAP Data Hub dans le but de couvrir pleinement le sujet de la gestion des données.
Dans le prochain article, nous parlerons de la phase «Développement et formation d'un modèle dans SAP Data Intelligence». Tous les plus intéressants à venir!
Publié par Elena Ganchenko, expert SAP CIS