Lorsque vous faites confiance à quelqu'un, la chose la plus précieuse que vous avez - les données de votre application ou service - vous voulez imaginer comment cette personne va gérer votre plus grande valeur.
Je m'appelle Vladimir Borodin, je suis le chef de la plateforme de données Yandex.Cloud. Aujourd'hui, je veux vous dire comment tout est organisé et fonctionne au sein des services de bases de données gérées Yandex, pourquoi tout est fait comme ça et quels sont les avantages - du point de vue des utilisateurs - de nos solutions. Et bien sûr, vous découvrirez certainement ce que nous prévoyons de finaliser dans un proche avenir afin que le service devienne meilleur et plus pratique pour tous ceux qui en ont besoin.
Eh bien, allons-y!

Bases de données gérées (bases de données gérées Yandex) est l'un des services Yandex.Cloud les plus populaires. Plus précisément, il s'agit de tout un groupe de services, qui est désormais le deuxième derrière les machines virtuelles Yandex Compute Cloud en popularité.
Les bases de données gérées Yandex permettent d'obtenir rapidement une base de données fonctionnelle et assument de telles tâches:
- Évolutivité - de la capacité élémentaire d'ajouter des ressources informatiques ou de l'espace disque à une augmentation du nombre de répliques et de fragments.
- Installez les mises à jour, mineures et majeures.
- Sauvegarde et restauration.
- Offrir une tolérance aux pannes.
- Suivi
- Fournir des outils de configuration et de gestion pratiques.
Organisation des services de base de données gérés: vue de dessus
Le service comprend deux parties principales: le plan de contrôle et le plan de données. Control Plane est, tout simplement, une API de gestion de base de données qui vous permet de créer, modifier ou supprimer des bases de données. Le plan de données est le niveau de stockage direct des données.
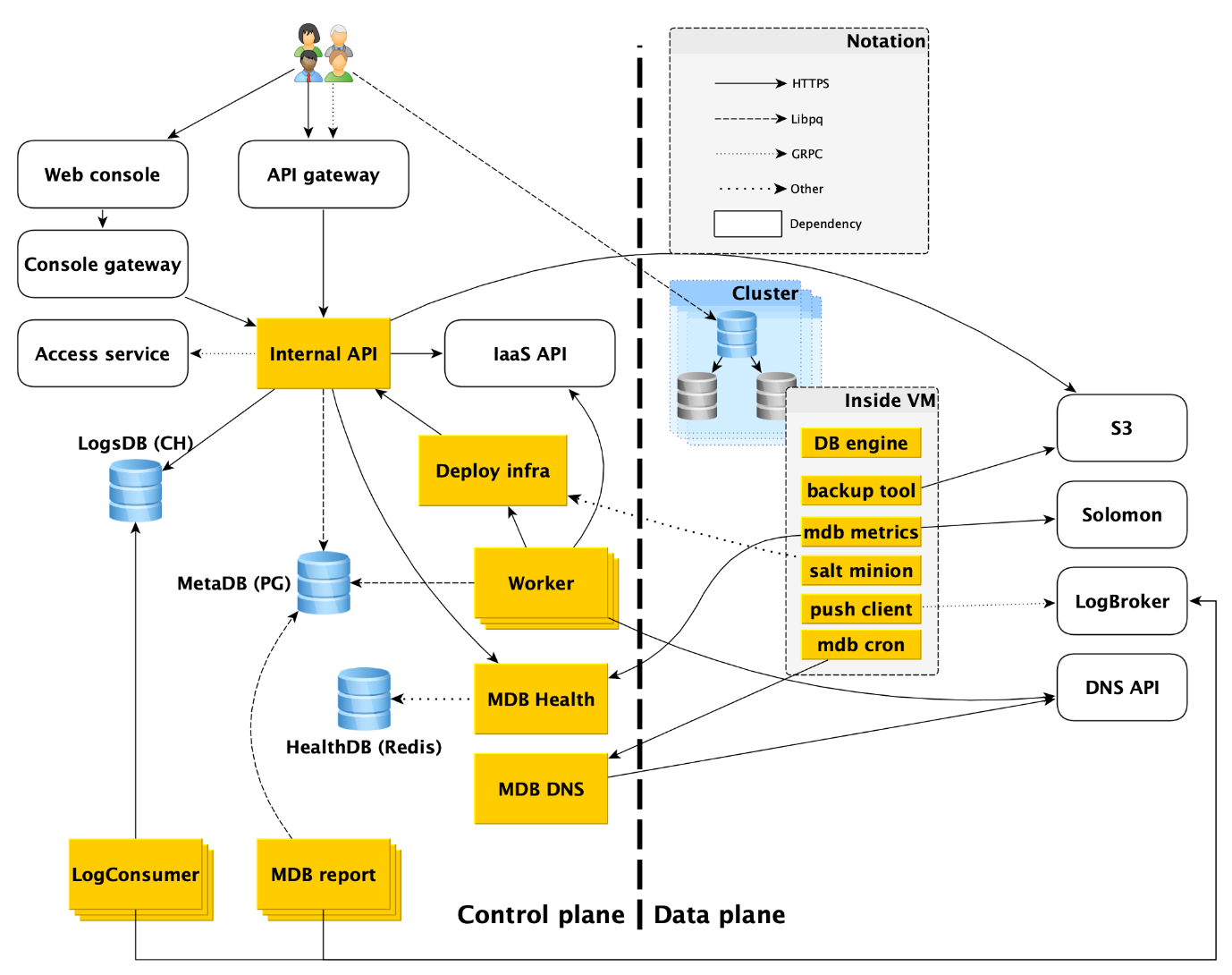
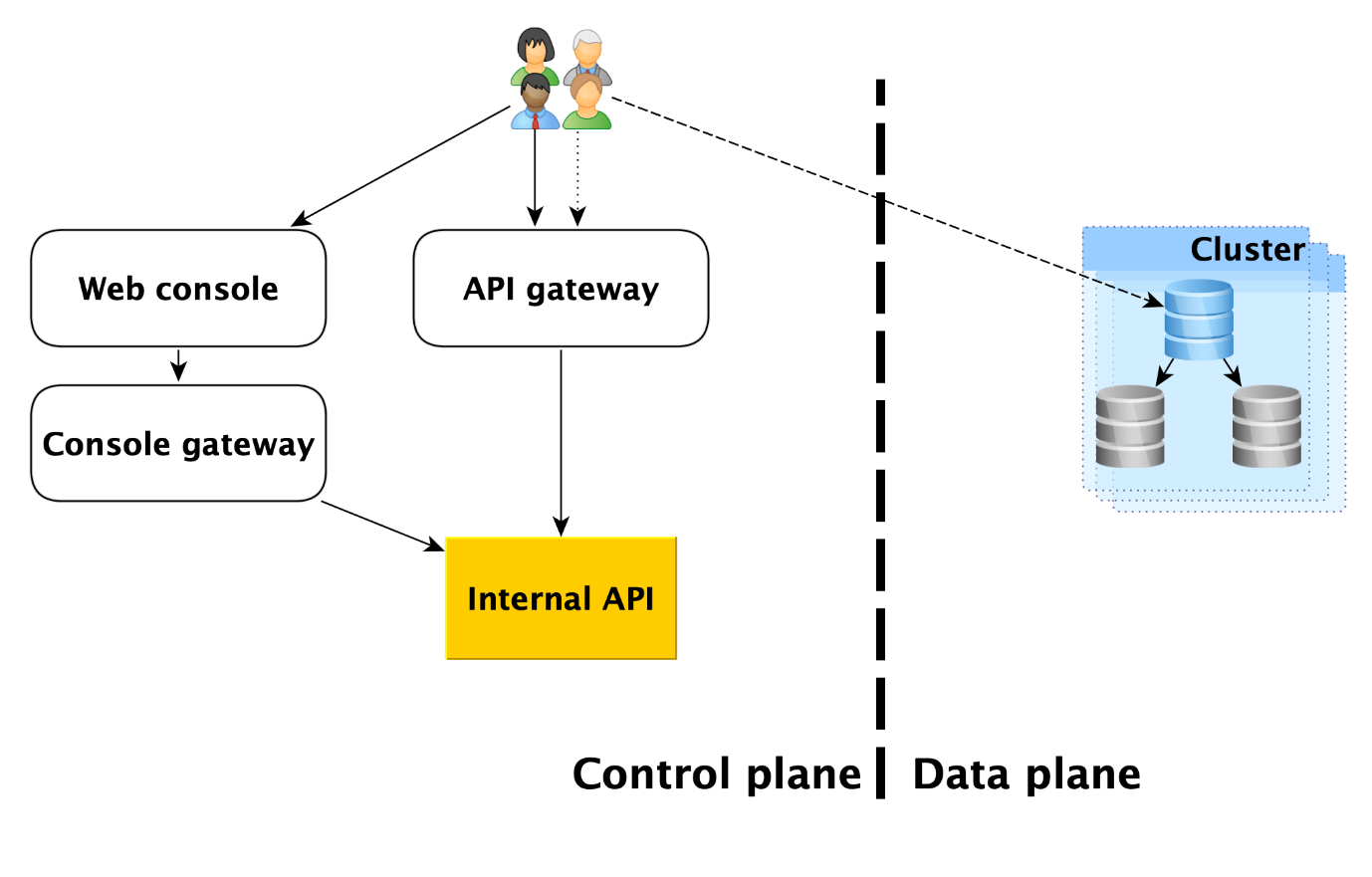
Les utilisateurs du service disposent en effet de deux points d'entrée:
- Dans le plan de contrôle. En fait, il existe de nombreuses entrées - la console Web, l'utilitaire CLI et l'API de passerelle qui fournit l'API publique (gRPC et REST). Mais tous vont finalement à ce que nous appelons l'API interne, et donc nous considérerons ce point d'entrée dans le plan de contrôle. En fait, c'est le point de départ du domaine de responsabilité du service Bases de données gérées (MDB).
- Dans le plan de données. Il s'agit d'une connexion directe à une base de données en cours d'exécution via des protocoles d'accès au SGBD. Si c'est, par exemple, PostgreSQL, alors ce sera l'interface libpq .
Ci-dessous, nous décrirons plus en détail tout ce qui se passe dans le plan de données, et nous analyserons chacun des composants du plan de contrôle.
Plan de données
Avant d'examiner les composants du plan de contrôle, examinons ce qui se passe dans le plan de données.
À l'intérieur d'une machine virtuelle
MDB exécute des bases de données dans les mêmes machines virtuelles que celles fournies dans
Yandex Compute Cloud .
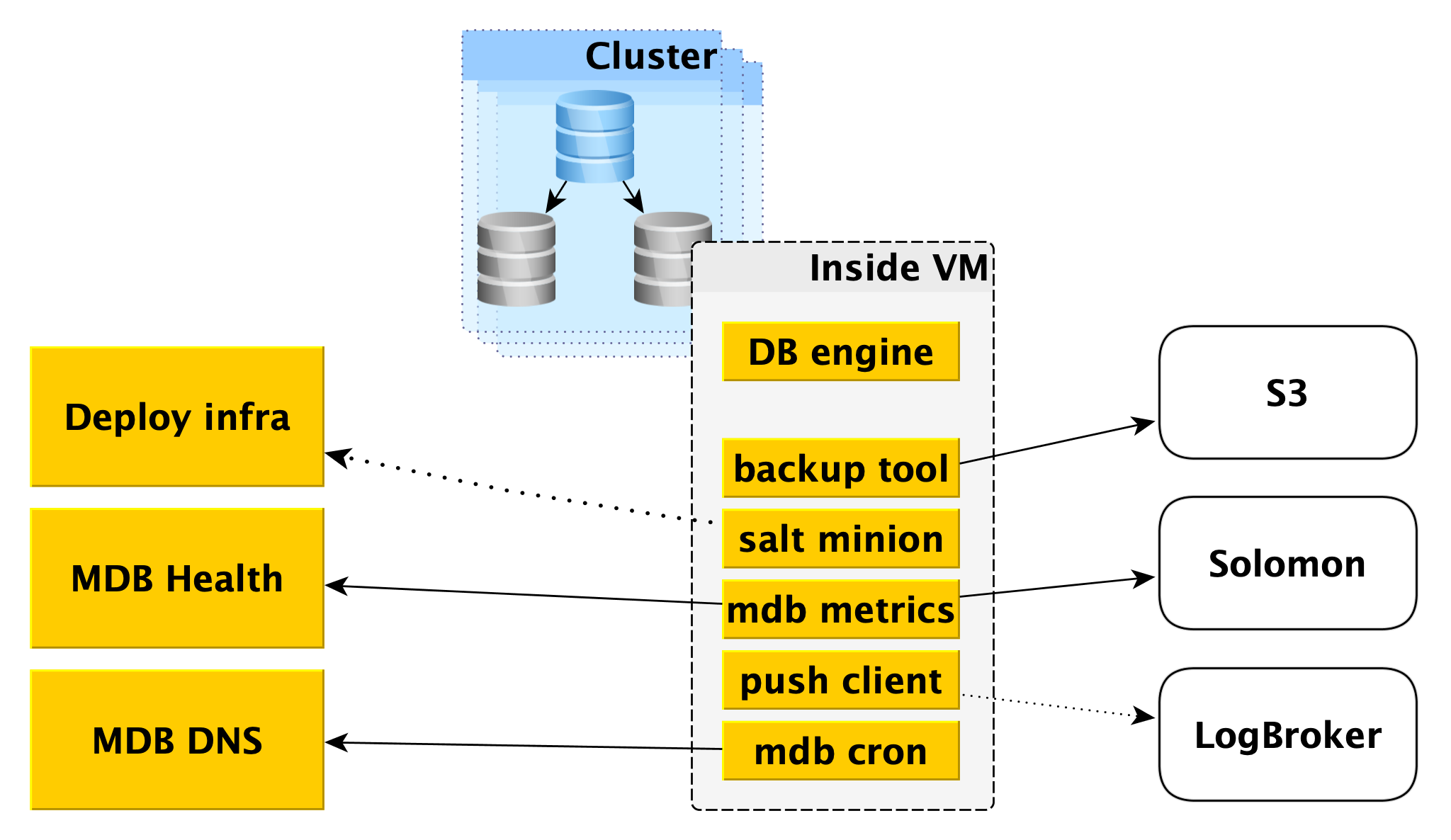
Tout d'abord, un moteur de base de données, par exemple PostgreSQL, y est déployé. En parallèle, différents programmes auxiliaires peuvent être lancés. Pour PostgreSQL, ce sera
Odyssey , l'extracteur de connexion à la base de données.
Toujours à l'intérieur de la machine virtuelle, un certain ensemble de services standard est lancé, le sien pour chaque SGBD:
- Service de création de sauvegardes. Pour PostgreSQL, il s'agit d'un outil WAL-G open source . Il crée des sauvegardes et les stocke dans Yandex Object Storage .
- Salt Minion est un composant du système SaltStack pour les opérations et la gestion de la configuration. Plus d'informations à ce sujet sont fournies ci-dessous dans la description de l'infrastructure de déploiement.
- Métriques MDB, qui est responsable de la transmission des mesures de base de données à Yandex Monitoring et à notre microservice pour surveiller l'état des clusters et hôtes MDB Health.
- Le client Push, qui envoie des journaux SGBD et des journaux de facturation au service Logbroker, est une solution spéciale pour la collecte et la livraison de données.
- MDB cron - notre vélo, qui diffère du cron habituel par la capacité d'effectuer des tâches périodiques avec une précision d'une seconde.
Topologie du réseau
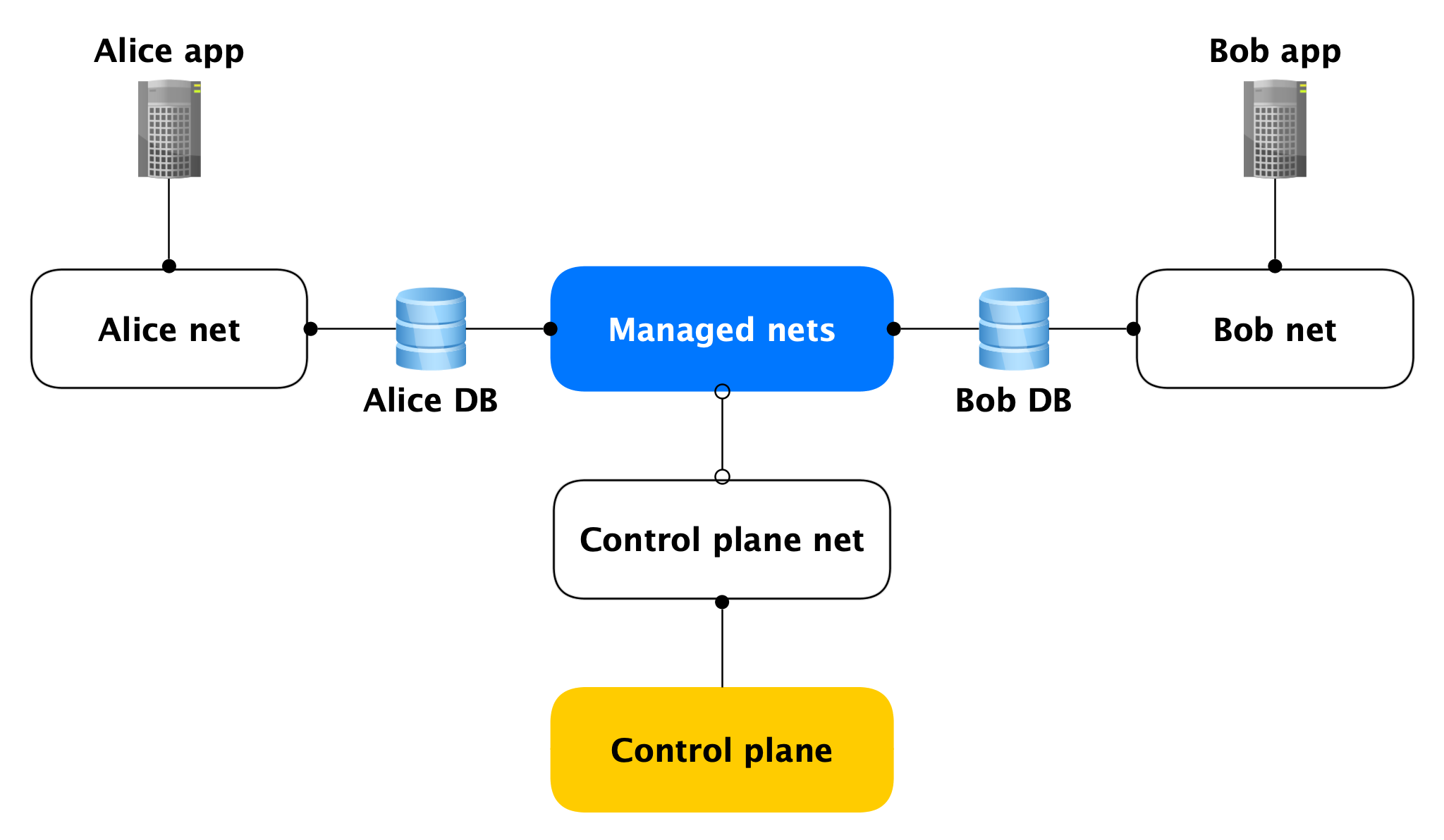
Chaque hôte du plan de données possède deux interfaces réseau:
- L'un d'eux se connecte au réseau de l'utilisateur. En général, il est nécessaire de gérer la charge du produit. Grâce à elle, la réplication est à la poursuite.
- Le second reste dans l'un de nos réseaux gérés via lesquels les hôtes accèdent au Control Plane.
Oui, les hôtes de différents clients sont coincés dans un tel réseau géré, mais ce n'est pas effrayant, car sur l'interface gérée (presque) rien n'écoute, les connexions réseau sortantes dans Control Plane ne sont ouvertes que depuis celui-ci. Presque personne, car il existe des ports ouverts (par exemple, SSH), mais ils sont fermés par un pare-feu local qui autorise uniquement les connexions à partir d'hôtes spécifiques. Par conséquent, si un attaquant accède à une machine virtuelle avec une base de données, il ne peut pas accéder aux bases de données d'autres personnes.
Sécurité du plan de données
Puisque nous parlons de sécurité, il faut dire que nous avons initialement conçu le service en fonction de l'attaquant se rootant sur la machine virtuelle du cluster.
En fin de compte, nous avons mis beaucoup d'efforts pour faire ce qui suit:
- Pare-feu local et grand;
- Cryptage de toutes les connexions et sauvegardes;
- Tous avec authentification et autorisation;
- AppArmor
- IDS auto-écrit.
Considérez maintenant les composants du plan de contrôle.
Avion de contrôle
API interne
L'API interne est le premier point d'entrée dans le plan de contrôle. Voyons comment tout fonctionne ici.
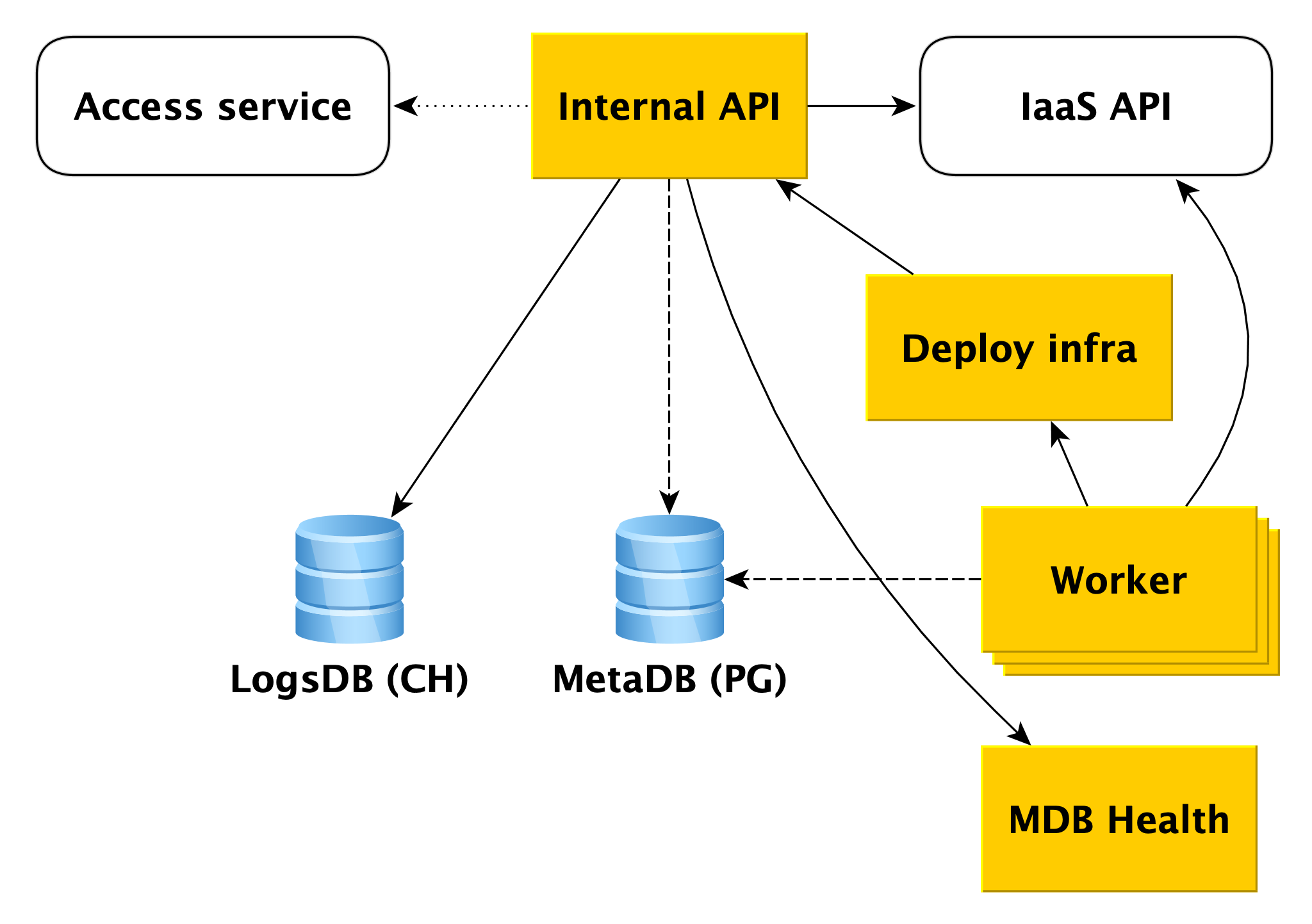
Supposons que l'API interne reçoive une demande de création d'un cluster de base de données.
Tout d'abord, l'API interne accède au service d'accès au service cloud, qui est chargé de vérifier l'authentification et l'autorisation de l'utilisateur. Si l'utilisateur réussit la vérification, l'API interne vérifie la validité de la demande elle-même. Par exemple, une demande de création d'un cluster sans spécifier son nom ou avec un nom déjà pris échouera au test.
Et l'API interne peut envoyer des demandes à l'API d'autres services. Si vous souhaitez créer un cluster dans un certain réseau A et un hôte spécifique dans un sous-réseau B spécifique, l'API interne doit s'assurer que vous avez des droits à la fois sur le réseau A et le sous-réseau spécifié B. En même temps, il vérifiera que le sous-réseau B appartient au réseau A Cela nécessite un accès à l'API d'infrastructure.
Si la demande est valide, les informations sur le cluster créé seront enregistrées dans la métabase. Nous l'appelons MetaDB, il est déployé sur PostgreSQL. MetaDB a une table avec une file d'attente d'opérations. L'API interne enregistre des informations sur l'opération et définit la tâche de manière transactionnelle. Après cela, des informations sur l'opération sont renvoyées à l'utilisateur.
En général, pour traiter la plupart des demandes de l'API interne, il suffit d'utiliser MetaDB et l'API des services associés. Mais il existe deux autres composants vers lesquels l'API interne répond pour répondre à certaines requêtes: LogsDB, où se trouvent les journaux du cluster d'utilisateurs, et MDB Health. À propos de chacun d'eux sera décrit plus en détail ci-dessous.
Ouvrier
Les travailleurs sont simplement un ensemble de processus qui interrogent la file d'attente des opérations dans MetaDB, les récupèrent et les exécutent.
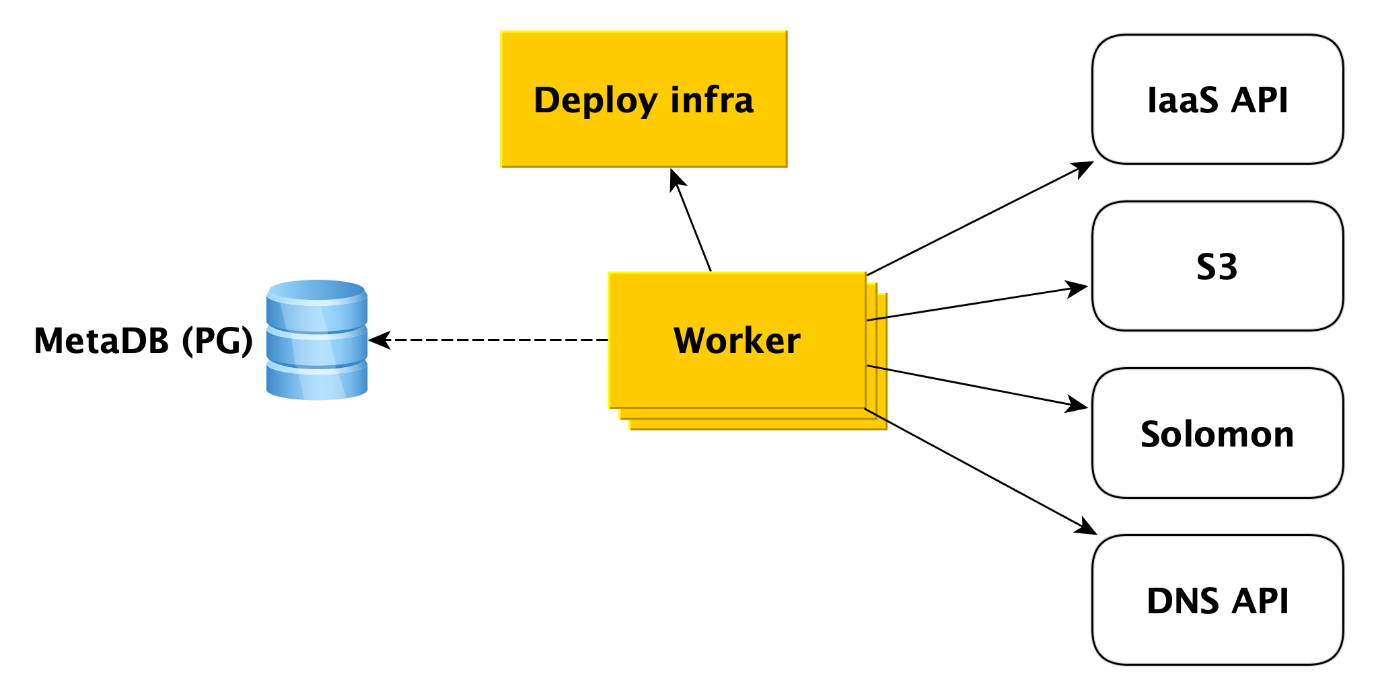
Que fait exactement un travailleur lors de la création d'un cluster? Il se tourne d'abord vers l'API d'infrastructure pour créer des machines virtuelles à partir de nos images (ils ont déjà tous les packages nécessaires installés et la plupart des choses sont configurées, les images sont mises à jour une fois par jour). Lorsque les machines virtuelles sont créées et que le réseau y décolle, le travailleur se tourne vers l'infrastructure de déploiement (nous vous en dirons plus à ce sujet plus tard) pour déployer ce dont l'utilisateur a besoin sur les machines virtuelles.
De plus, le travailleur accède à d'autres services Cloud. Par exemple, dans
Yandex Object Storage pour créer un compartiment dans lequel les sauvegardes de cluster seront enregistrées. Au service de
surveillance Yandex , qui collectera et visualisera les métriques de la base de données. Le travailleur doit y créer des méta-informations de cluster. À l'API DNS, si l'utilisateur souhaite attribuer des adresses IP publiques aux hôtes du cluster.
En général, le travailleur travaille très simplement. Il reçoit la tâche de la file d'attente de la métabase et accède au service souhaité. Après avoir terminé chaque étape, le travailleur stocke des informations sur la progression de l'opération dans la métabase. En cas d'échec, la tâche redémarre simplement et s'exécute à l'endroit où elle s'était arrêtée. Mais même le redémarrer depuis le début n'est pas un problème, car presque tous les types de tâches pour les travailleurs sont écrits de manière idempotante. En effet, le travailleur peut effectuer l'une ou l'autre étape de l'opération, mais il n'y a aucune information à ce sujet dans MetaDB.
Déployer l'infrastructure
Tout en bas se trouve
SaltStack , un système de gestion de configuration open source assez courant écrit en Python. Le système est très
extensible , pour lequel nous l'aimons.
Les principaux composants de Salt sont Salt Master, qui stocke des informations sur ce qui doit être appliqué et où, et Salt Minion - un agent installé sur chaque hôte, interagit avec le maître et peut appliquer directement le sel du Salt Master sur l'hôte. Pour les besoins de cet article, nous avons suffisamment de connaissances et vous pouvez en lire plus dans la
documentation SaltStack .
Un maître du sel n'est pas tolérant aux pannes et ne s'étend pas à des milliers de serviteurs, plusieurs maîtres sont nécessaires. Interagir avec cela directement à partir du travailleur n'est pas pratique, et nous avons écrit nos liaisons sur Salt, que nous appelons le cadre de déploiement.
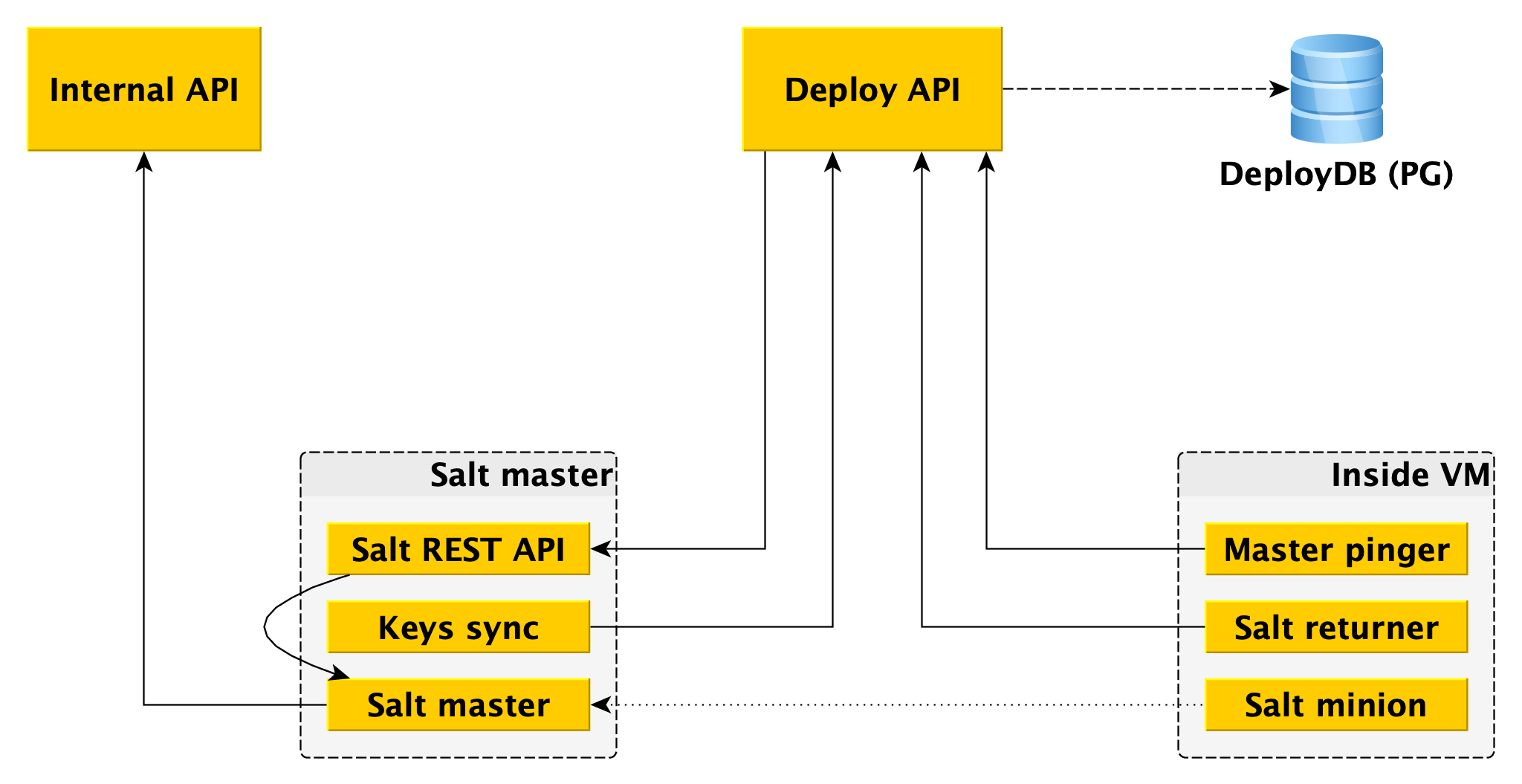
Pour le travailleur, le seul point d'entrée est l'API Deploy, qui implémente des méthodes telles que «Appliquer l'état entier ou ses éléments individuels à de tels serviteurs» et «Dire le statut de tel ou tel déploiement». L'API de déploiement stocke des informations sur tous les déploiements et ses étapes spécifiques dans DeployDB, où nous utilisons également PostgreSQL. Des informations sur tous les serviteurs et maîtres et sur l'appartenance du premier au second y sont également stockées.
Deux composants supplémentaires sont installés sur les maîtres de sel:
- API Salt REST , avec laquelle l'API Deploy interagit pour lancer des déploiements. L'API REST va au maître du sel local, et il communique déjà avec les sbires en utilisant ZeroMQ.
- L'essentiel est qu'il va à l'API Deploy et reçoive les clés publiques de tous les serviteurs qui doivent être connectés à ce salt-master. Sans clé publique sur le maître, le serviteur ne peut tout simplement pas se connecter au maître.
En plus du sébaste, deux composants sont également installés dans le plan de données:
- Returner - un module (l'une des parties extensibles de salt), qui apporte le résultat du déploiement non seulement au salt-master, mais aussi dans l'API Deploy. L'API de déploiement lance le déploiement en accédant à l'API REST sur l'assistant et reçoit le résultat via le retourneur du serviteur.
- Master pinger, qui interroge périodiquement l'API Deploy à laquelle les serviteurs principaux doivent être connectés. Si l'API Deploy renvoie une nouvelle adresse d'assistant (par exemple, car l'ancienne est morte ou surchargée), pinger reconfigure le serviteur.
Un autre endroit où nous utilisons l'extensibilité SaltStack est
ext_pillar - la possibilité d'obtenir un
pilier de quelque part à l'extérieur (certaines informations statiques, par exemple, la configuration de PostgreSQL, les utilisateurs, les bases de données, les extensions, etc.). Nous allons à l'API interne de notre module pour obtenir des paramètres spécifiques au cluster, car ils sont stockés dans MetaDB.
Séparément, nous notons que le pilier contient également des informations confidentielles (mots de passe utilisateur, certificats TLS, clés GPG pour le chiffrement des sauvegardes), et donc, premièrement, toutes les interactions entre tous les composants sont chiffrées (pas dans nos bases de données venir sans TLS, HTTPS partout, le serviteur et le maître chiffrent également tout le trafic). Et deuxièmement, tous ces secrets sont cryptés dans MetaDB, et nous utilisons la séparation des secrets - sur les machines API internes, il y a une clé publique qui crypte tous les secrets avant d'être stockés dans MetaDB, et la partie privée est sur des maîtres de sel et seuls ils peuvent obtenir secrets ouverts pour le transfert en tant que pilier à un serviteur (à nouveau via un canal crypté).
MDB Health
Lorsque vous travaillez avec des bases de données, il est utile de connaître leur statut. Pour cela, nous avons le microservice MDB Health. Il reçoit des informations sur l'état de l'hôte du composant interne des MDB de la machine virtuelle MDB et les stocke dans sa propre base de données (dans ce cas, Redis). Et lorsqu'une demande concernant le statut d'un cluster particulier arrive dans l'API interne, l'API interne utilise les données de MetaDB et MDB Health.
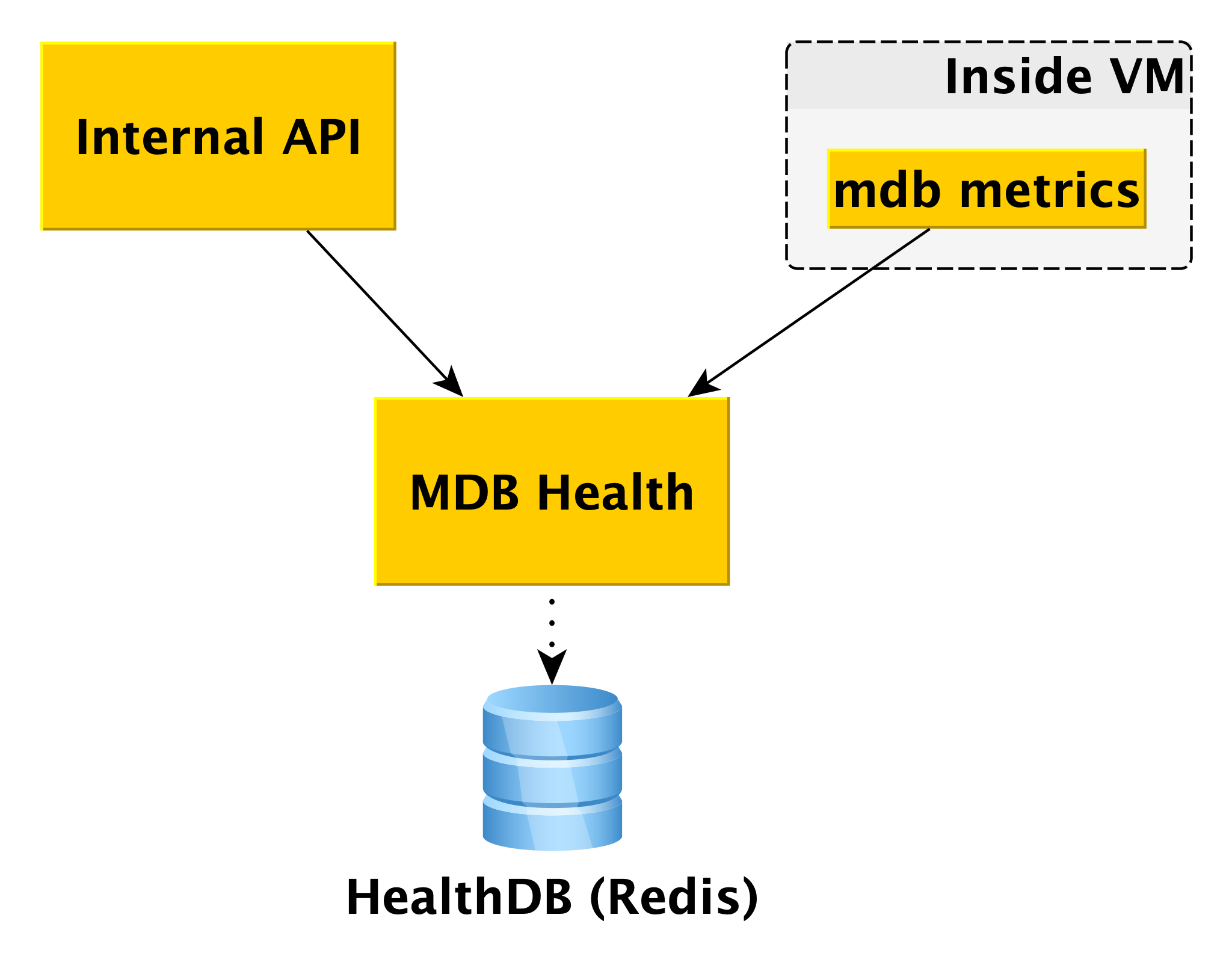
Les informations sur tous les hôtes sont traitées et présentées sous une forme compréhensible dans l'API. Outre l'état des hôtes et des clusters pour certains SGBD, MDB Health indique également si un hôte particulier est un maître ou une réplique.
DNS MDB
Le microservice DNS MDB est nécessaire pour gérer les enregistrements CNAME. Si le pilote de connexion à la base de données ne permet pas de transférer plusieurs hôtes dans la chaîne de connexion, vous pouvez vous connecter à un
CNAME spécial, qui indique toujours le maître actuel dans le cluster. Si le maître change, le CNAME change.
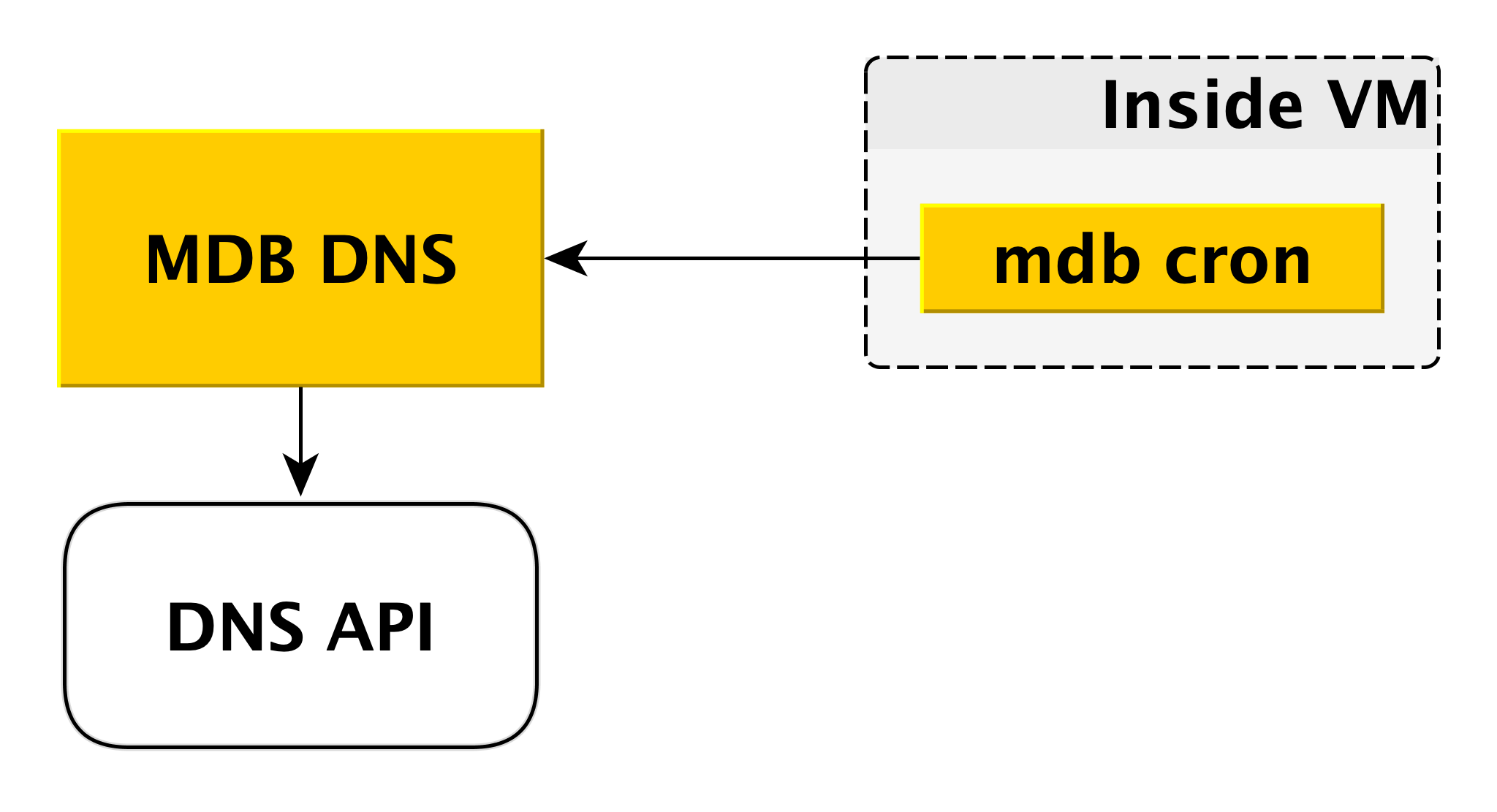
Comment ça se passe? Comme nous l'avons dit ci-dessus, à l'intérieur de la machine virtuelle, il y a un cron MDB, qui envoie périodiquement une pulsation du contenu suivant au DNS MDB: "Dans ce cluster, l'enregistrement CNAME doit pointer vers moi." MDB DNS accepte ces messages de toutes les machines virtuelles et décide de modifier les enregistrements CNAME. Si nécessaire, il modifie l'enregistrement via l'API DNS.
Pourquoi avons-nous créé un service distinct pour cela? Parce que l'API DNS n'a le contrôle d'accès qu'au niveau de la zone. Un attaquant potentiel, accédant à une machine virtuelle distincte, pourrait modifier les enregistrements CNAME des autres utilisateurs. MDB DNS exclut ce scénario car il vérifie l'autorisation.
Livraison et affichage des journaux de base de données
Lorsque la base de données de la machine virtuelle écrit dans le journal, le composant client push spécial lit cet enregistrement et envoie la ligne qui vient d'apparaître à Logbroker (
ils l'ont déjà écrit sur Habré). L'interaction du client push avec LogBroker est construite avec une sémantique exacte: nous l'enverrons certainement et nous en assurerons strictement une fois.
Un pool distinct de machines - LogConsumers - prend les journaux de la file d'attente LogBroker et les stocke dans la base de données LogsDB. Le SGBD ClickHouse est utilisé pour la base de données des journaux.
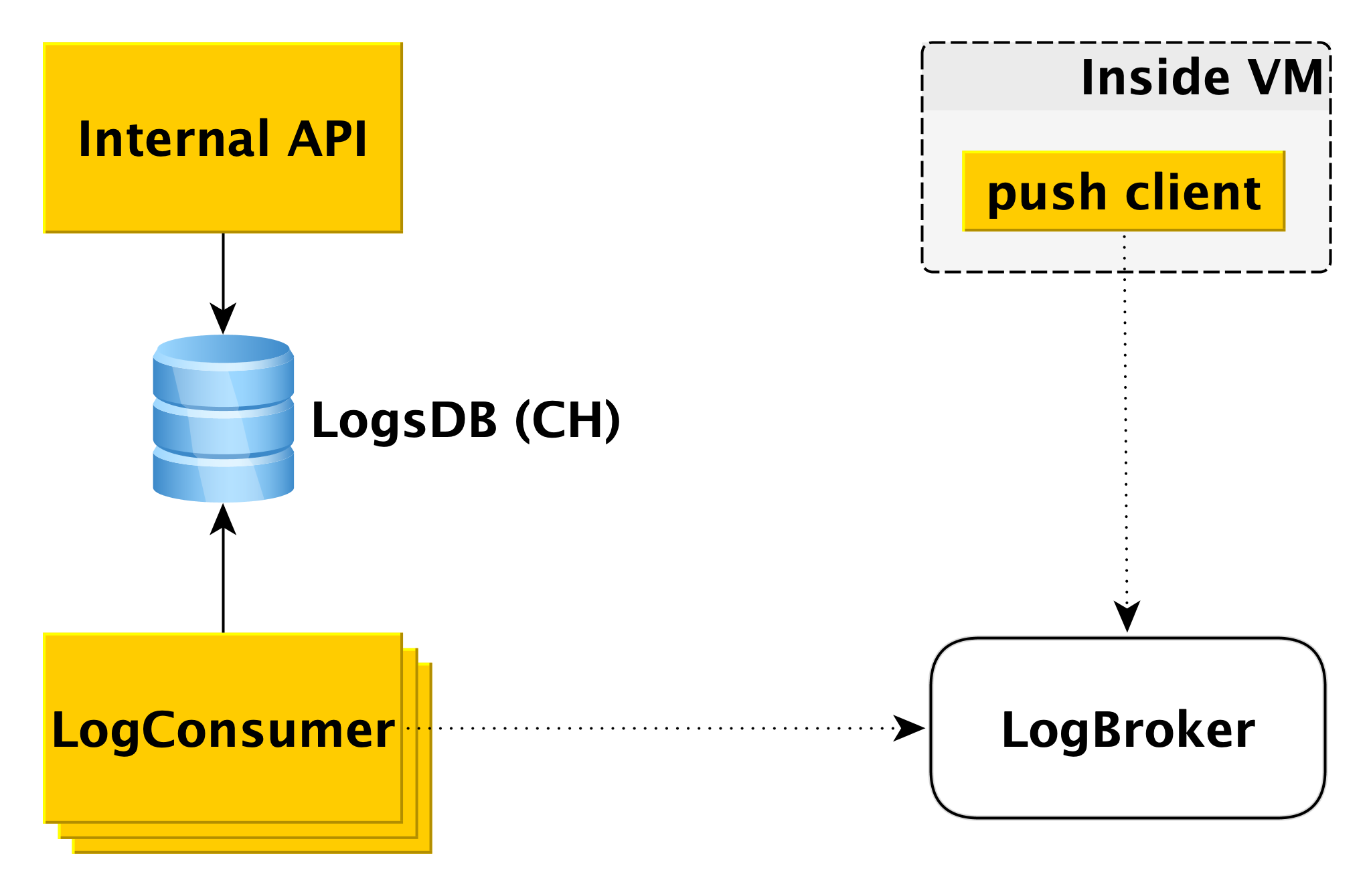
Lorsqu'une demande est envoyée à l'API interne pour afficher les journaux pendant un intervalle de temps spécifique pour un cluster particulier, l'API interne vérifie l'autorisation et envoie la demande à LogsDB. Ainsi, la boucle de remise des journaux est complètement indépendante de la boucle d'affichage des journaux.
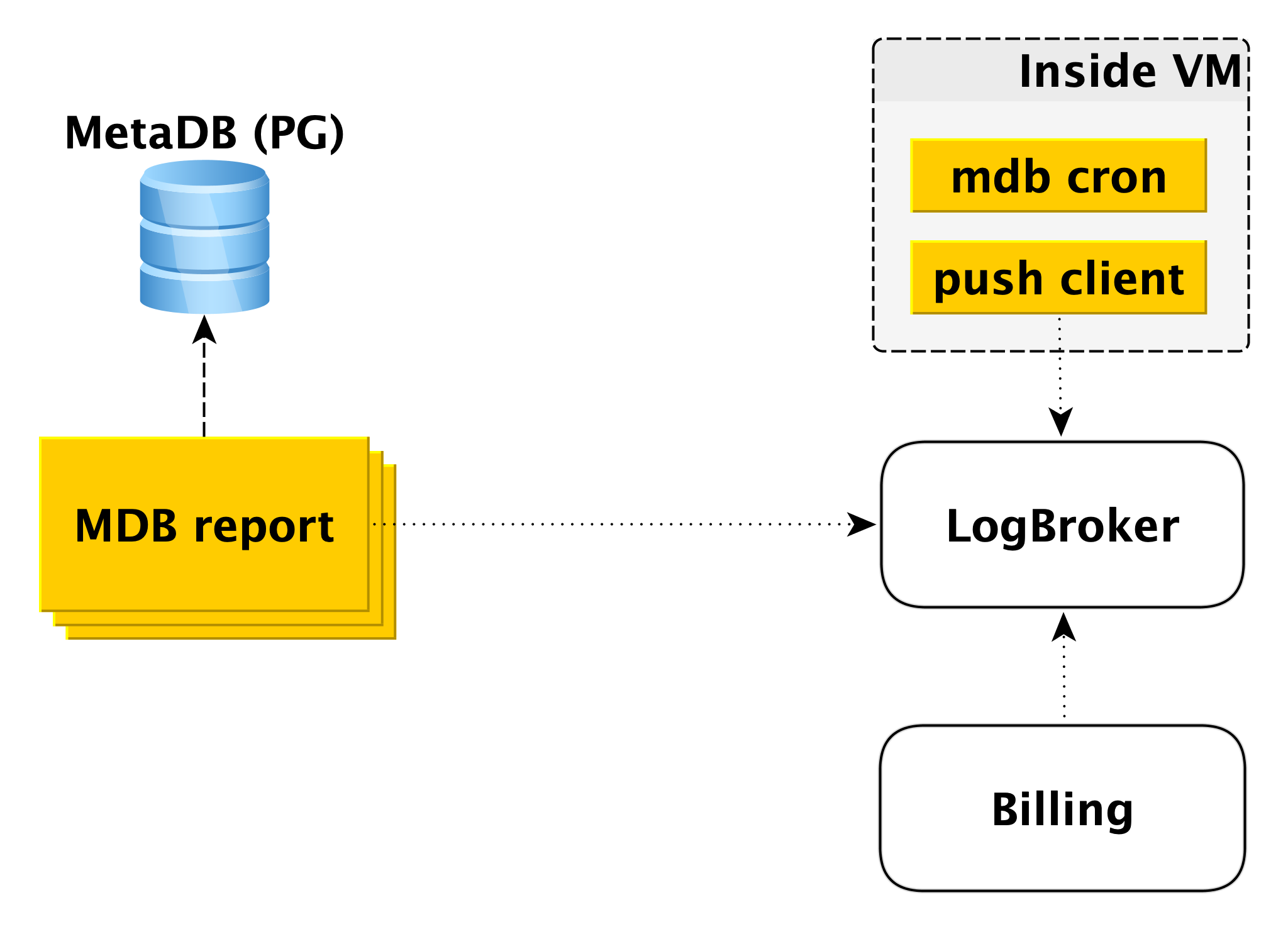
Facturation
Le schéma de facturation est construit de manière similaire. À l'intérieur de la machine virtuelle, il y a un composant qui vérifie avec une certaine périodicité que tout est en ordre avec la base de données. Si tout va bien, vous pouvez effectuer la facturation pour cet intervalle de temps dès le dernier lancement. Dans ce cas, un enregistrement est effectué dans le journal de facturation, puis le client push envoie l'enregistrement à LogBroker. Les données de Logbroker sont transférées vers le système de facturation et les calculs y sont effectués. Il s'agit d'un schéma de facturation pour l'exécution de clusters.
Si le cluster est désactivé, l'utilisation des ressources informatiques cesse d'être facturée, cependant, l'espace disque est facturé. Dans ce cas, la facturation à partir de la machine virtuelle est impossible et le deuxième circuit est impliqué - le circuit de facturation hors ligne. Il existe un pool distinct de machines qui ratissent la liste des clusters d'arrêt de MetaDB et écrivent un journal au même format dans Logbroker.
La facturation hors ligne peut également être utilisée pour la facturation et les clusters inclus, mais nous facturerons les hôtes, même s'ils sont en cours d'exécution, mais ils ne fonctionnent pas. Par exemple, lorsque vous ajoutez un hôte à un cluster, il se déploie à partir de la sauvegarde et est rattrapé par la réplication. Il est faux de facturer l'utilisateur pour cela, car l'hôte est inactif pendant cette période.
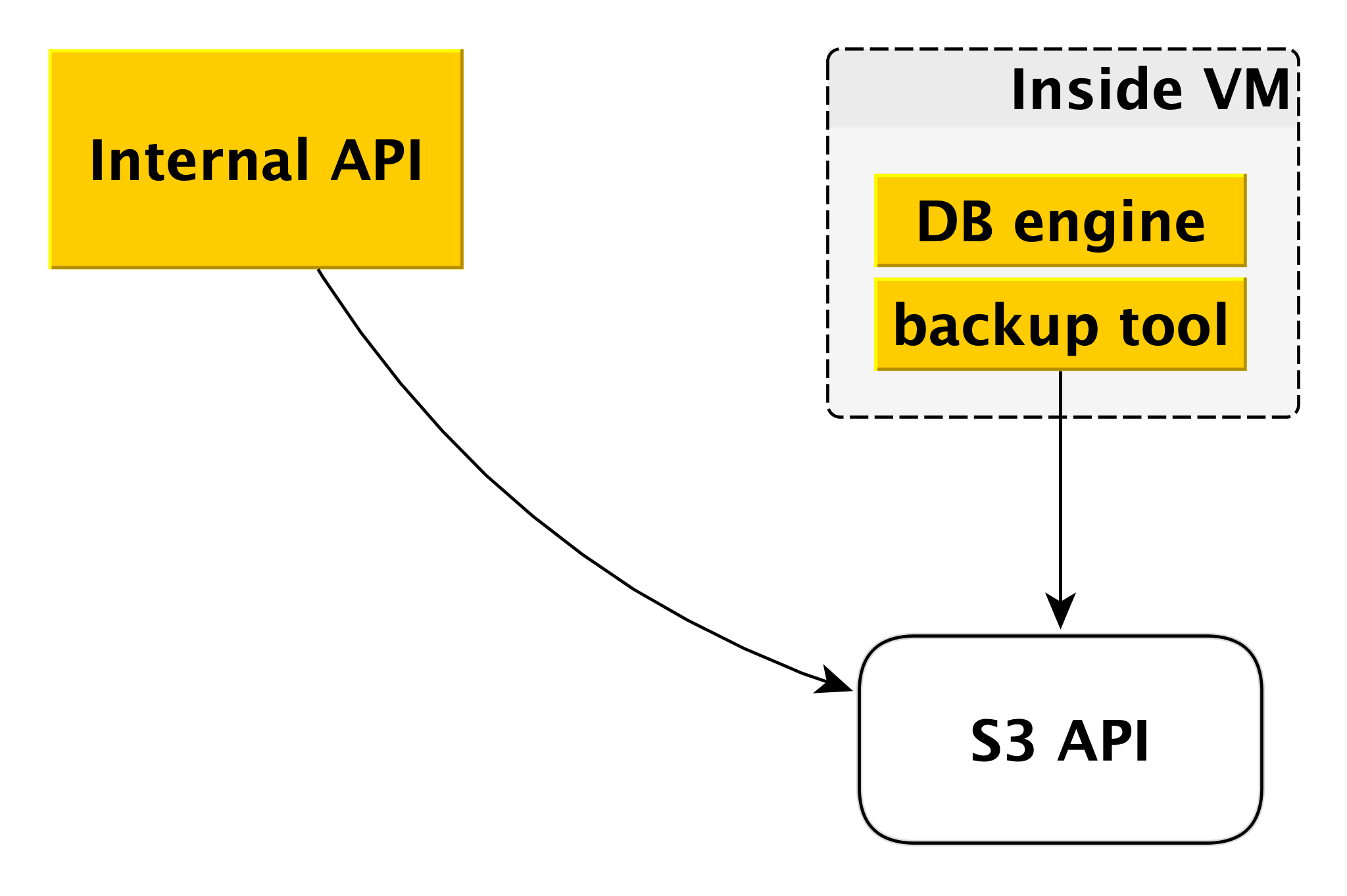
Sauvegarde
Le schéma de sauvegarde peut différer légèrement pour différents SGBD, mais le principe général est toujours le même.
Chaque moteur de base de données utilise son propre outil de sauvegarde. Pour PostgreSQL et MySQL, il s'agit de
WAL-G . Il crée des sauvegardes, les compresse, les chiffre et les place dans
Yandex Object Storage . Dans le même temps, chaque cluster est placé dans un compartiment séparé (d'une part, pour l'isolement, et d'autre part, pour faciliter la sauvegarde de l'espace pour les sauvegardes) et est chiffré avec sa propre clé de chiffrement.
Voici comment fonctionnent le plan de contrôle et le plan de données. De tout cela, le service de base de données gérée Yandex.Cloud est formé.
Pourquoi tout est arrangé de cette façon
Bien sûr, au niveau mondial, quelque chose pourrait être mis en œuvre selon des schémas plus simples. Mais nous avions nos propres raisons de ne pas suivre la voie de la moindre résistance.
Tout d'abord, nous voulions avoir un plan de contrôle commun pour tous les types de SGBD. Peu importe celui que vous choisissez, au final, votre demande parvient à la même API interne et tous les composants qui en font partie sont également communs à tous les SGBD. Cela rend notre vie un peu plus compliquée en termes de technologie. D'un autre côté, il est beaucoup plus facile d'introduire de nouvelles fonctionnalités et capacités qui affectent tous les SGBD. Cela se fait une fois, pas six.
Deuxième moment important pour nous - nous voulions garantir autant que possible l'indépendance du plan de données par rapport au plan de contrôle. Et aujourd'hui, même si Control Plane est complètement indisponible, toutes les bases de données continueront de fonctionner. Le service assurera leur fiabilité et leur disponibilité.
Troisièmement, le développement de presque tous les services est toujours un compromis. D'une manière générale, grosso modo, la vitesse de publication des versions et la fiabilité supplémentaire sont quelque part plus importantes. En même temps, personne ne peut désormais se permettre de faire une ou deux sorties par an, c'est évident. Si vous regardez Control Plane, nous nous concentrons ici sur la vitesse de développement, sur l'introduction rapide de nouvelles fonctionnalités, en déployant des mises à jour plusieurs fois par semaine. Et Data Plane est responsable de la sécurité de vos bases de données, de la tolérance aux pannes, voici donc un cycle de version complètement différent, mesuré en semaines. Et cette flexibilité en termes de développement nous assure également leur indépendance mutuelle.
Autre exemple: les services de base de données généralement gérés ne fournissent aux utilisateurs que des lecteurs réseau. Yandex.Cloud propose également des disques locaux. La raison est simple: leur vitesse est beaucoup plus élevée. Avec les lecteurs réseau, par exemple, il est plus facile de faire évoluer la machine virtuelle de haut en bas. Il est plus facile de faire des sauvegardes sous forme d'instantanés de stockage réseau. Mais de nombreux utilisateurs ont besoin d'une vitesse élevée, nous augmentons donc les outils de sauvegarde.
Plans futurs
Et quelques mots sur les plans d'amélioration du service à moyen terme. Il s'agit de plans qui affectent l'ensemble des bases de données gérées Yandex dans leur ensemble, plutôt que les SGBD individuels.
Tout d'abord, nous voulons donner plus de flexibilité dans le réglage de la fréquence de création de sauvegarde. Il existe des scénarios où il est nécessaire que pendant la journée les sauvegardes soient effectuées toutes les quelques heures, pendant la semaine - une fois par jour, pendant le mois - une fois par semaine, pendant l'année - une fois par mois. Pour ce faire, nous développons un composant distinct entre l'API interne et
Yandex Object Storage .
Un autre point important, important pour les utilisateurs et pour nous, est la vitesse des opérations. Nous avons récemment apporté des modifications majeures à l'infrastructure de déploiement et réduit le temps d'exécution de presque toutes les opérations à quelques secondes. Les opérations de création d'un cluster et d'ajout d'un hôte au cluster n'étaient pas couvertes. Le temps d'exécution de la deuxième opération dépend de la quantité de données. Mais nous allons accélérer le premier dans un avenir proche, car les utilisateurs souhaitent souvent créer et supprimer des clusters dans leurs pipelines CI / CD.
Notre liste de cas importants comprend l'ajout de la fonction d'augmentation automatique de la taille du disque. Maintenant, cela se fait manuellement, ce qui n'est pas très pratique et pas très bon.
Enfin, nous proposons aux utilisateurs un grand nombre de graphiques montrant ce qui se passe avec la base de données. Nous donnons accès aux journaux. Dans le même temps, nous constatons que les données sont parfois insuffisantes. Besoin d'autres graphiques, d'autres tranches. Ici, nous prévoyons également des améliorations.
Notre histoire sur le service de base de données gérée s'est avérée longue et probablement assez fastidieuse. Mieux que tous les mots et descriptions, seulement une vraie pratique. Par conséquent, si vous le souhaitez, vous pouvez évaluer indépendamment les capacités de nos services: