Probablement, dans chaque ville du Bélarus où il y a des trolleybus, il y a des groupes VK ou des chats sur Telegram dans lesquels les gens suivent l'emplacement des contrôleurs. Ceci est principalement fait afin de ne pas payer les voyages et les voyages gratuits, bien que la description des groupes contienne presque toujours le post-scriptum «Payer pour les voyages».
Dans VC, cela ressemble généralement à ceci:
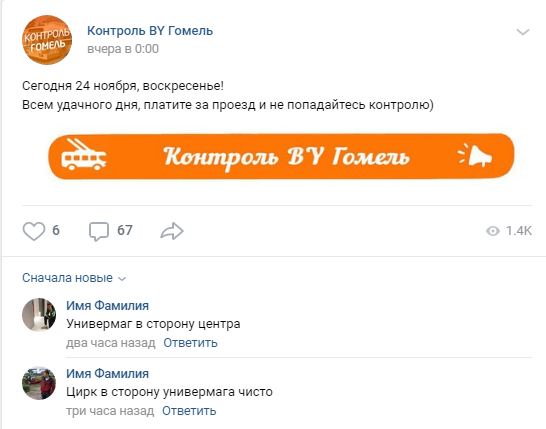
Un commentaire typique ressemble à ceci:
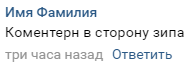
La structure est extrêmement simple. Dans le commentaire, il y a des noms de l'arrêt où les contrôleurs étaient actuellement remarqués, il y a aussi la direction dans laquelle ils se trouvent:
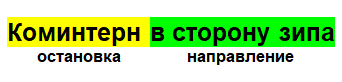
En conséquence, le commentaire est un objet avec un arrêt, une heure et une date, ainsi qu'un identifiant unique permettant de l'identifier. Avec cela, vous pouvez calculer l'emplacement le plus probable de l'emplacement actuel des contrôleurs.
La préparation
Vous devez d'abord déterminer le public cible, à partir duquel nous analyserons les données. Le groupe devrait avoir beaucoup d'activité dans les commentaires, sinon nous risquons d'obtenir trop peu de données
Dans mon cas, c'est le groupe «Control Gomel».
Nous analyserons les commentaires à l'aide de l'API VKontakte officielle pour Python
Nous nous authentifions avec la clé d'accès de l'utilisateur, car certains groupes peuvent être fermés et l'accès à leurs commentaires ne peut être obtenu que si vous avez été accepté dans le groupe.
Après cela, vous pouvez commencer à extraire des commentaires:
Recevoir des commentaires
Pour commencer, nous obtenons le dernier message disponible dans le groupe pour extraire les commentaires via vk.wall.getComments et initialiser le DataFrame, dans lequel nous enregistrerons les données.
Chaque article de commentaire a l'inscription «Passez une bonne journée, payez le prix et ne tombez pas sous le contrôle», alors téléchargez les commentaires, vérifiez le contenu de l'article et obtenez un tableau de commentaires à partir duquel vous pouvez prendre des données.
J'ai pris les commentaires des articles au cours des 3 derniers mois, étant donné qu'un article est publié chaque jour (maintenant fin novembre, l'année scolaire commence en septembre, et les contrôleurs en tiennent probablement compte et changent de place). En principe, d'autres signes peuvent être pris en compte, comme par exemple la période de l'année.
Certains des commentaires sont bouchés par des messages comme «Y a-t-il quelqu'un sur Barykin?» Si vous regardez ces commentaires (inutiles), vous pouvez mettre en évidence certains signes:
- Le texte contient les mots «propre», «gauche», «personne» et similaires
- Les mots «dites-moi», «qui», «quoi», «comment»
- Des symboles, comme des émoticônes, par exemple
Après cela, nous passons en revue un tableau de commentaires et en retirons un identifiant, un texte, une heure, une date et un jour de la semaine uniques, que nous mettons dans le DataFrame déjà créé.
Recevoir des commentairesimport re import time import pandas as pd import lp import vk_api import check_correctness def auth(): vk_session = vk_api.VkApi(lp.login, lp.password) vk_session.auth() vk = vk_session.get_api() return vk def getDataFromComments(vk, groupID):
Ainsi, nous avons reçu un DataFrame avec le texte des commentaires, leur identifiant, le jour de la semaine, l'heure et la minute dans laquelle le commentaire a été écrit. Nous n'avons besoin que du jour de la semaine, de l'heure d'écriture et du texte. Cela ressemble à ceci:
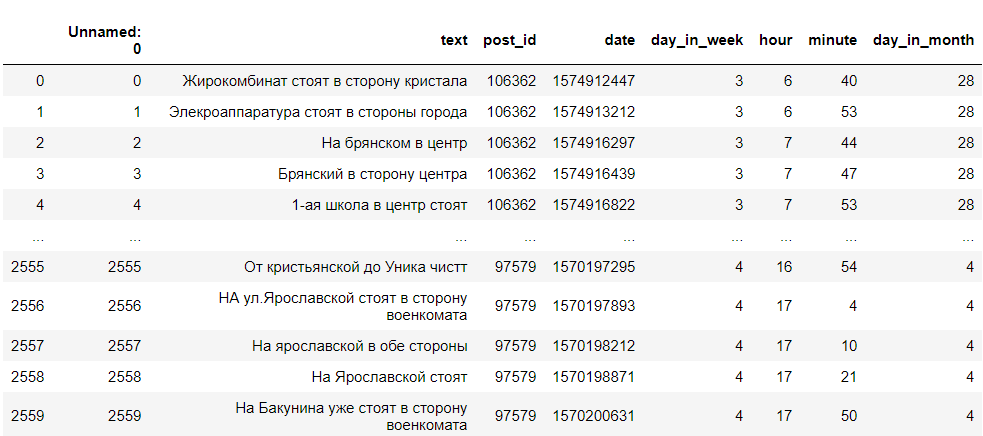
Nettoyage des données
Maintenant, nous devons effacer les données. Il est nécessaire de supprimer la direction du commentaire afin de faire moins d'erreurs lors de la recherche de la distance Levenshtein. Nous trouvons les expressions «sur le côté», «aller», «comment», «près», car elles sont généralement suivies du nom du deuxième arrêt, et nous les supprimons avec ce qui vient après, ainsi que remplacer certains noms de jargon des arrêts par l'habituel .
Effacer les données from fuzzywuzzy import process def clear_commentary(text): """ - """ index = 0 splitted = text.split(" ") for i, s in enumerate(splitted): if len(splitted) == 1: return np.NaN if ((("" in s) or ("" in s) or ( "" in s) or ( "" in s)) and s is not ""): index = i if index is not 0 and index < len(splitted) - 2: for i in range(1, 4): splitted.remove(splitted[index]) string = " ".join(splitted) text = (string.lower()) elif index is not 0: splitted = splitted[:index] string = " ".join(splitted) text = string.lower() else: text = " ".join(splitted).lower() return text def clean_data(data): data.dropna(inplace=True) data["text"] = data["text"].map(lambda s: clear_commentary(s)) data.dropna(inplace=True) print("cleaned") return data
Conversion à l'aide de la distance de Levenshtein
Nous allons directement à la distance Levenshane. Un peu d'aide: distance Levenshtein - le nombre minimum d'opérations pour insérer un caractère, supprimer un caractère et remplacer un caractère par un autre, nécessaire pour transformer une ligne en une autre.
Nous le trouverons en utilisant la bibliothèque
fuzzywuzzy . Il vous aide à calculer rapidement et facilement la distance Levenshtein. Pour accélérer le travail, les auteurs de la bibliothèque recommandent également d'installer la bibliothèque python-Levenshtein.
Afin d'obtenir des arrêts à partir des commentaires, nous avons besoin d'une liste d'arrêts. Il m'a été gracieusement fourni par le développeur de l'application GoTrans, Alexander Kozlov.
La liste a dû être élargie, en y ajoutant des arrêts qui n'étaient pas là, et en changeant une partie des noms afin qu'ils soient mieux localisés.
Arrêtestops = ['supermarché', 'prairie', 'remybtekhnika', 'Leningrad', 'Yaroslavl', 'Polesskaya',
«Yaroslavl», «timofeenko», «8 mars»,
«Rechitsky trading house», «Rechitsky avenue», «circus», «department store», «Chongarskaya»,
«chongarka», «ggu», «skorina», «université», «appareil», «1000 petites choses», «maya», «station»,
«parc des diplômés», «commerce et économie», «anniversaire», «microdistrict 18», «aéroport», «venant en sens inverse»,
«gomelgeodezcentr», «cristal», «lac lyubenskoye», «marché davydovsky», «davydovka»,
«rivière sozh», «gomeldrev»,
«Sevruki», «gmu n ° 1», «etc. Rechitsky», «costume», «hôpital des maladies infectieuses», «camp de goélands»,
Volotova, Coral, Gomeltorgmash, Gomelproekt, Vneshgomelstroy, Journal,
«Kalenikova», «Eremino», «distillerie», «spécialisation industrielle», «2nd School», «Barykina»,
«unités de machine», «jeunesse», «corps de coulée», «chimistes», «golovatsky», «budenny»,
'spu67', '35th', 'gagarin', '50 years to the Gomselmash plant ',' hill ',' radio factory ',
«grand-mère», «verrerie», «châtaignier», «démarrage des moteurs», «astronautes»,
«rtsrm initial», «bykhovskaya», «institut du ministère des situations d'urgence», «dk gomselmash», «magasin», «rechitsky»,
'Sevruks', 'Osovtsy', 'tourist', 'meat factory', 'Holy Trinity', 'medical town', 'octobre',
«dépôt d'huile», «gomelloblavtotrans», «milkavita», «bakunin», «zip», «oma», «résine»,
«construction market ksk», «road builder», «field», «kamenetskaya», «bolchevik», «jakubovka»,
«Borodina», «hypermarché hippopotame», «héros souterrains», «9 mai», «châtaignier», «prothésiste»,
'iput station', 'communist international', 'music pedagogical college', 'farm firm', 'bypass road', 'victoire',
«western», «pearl», «Vladimir», «dry», «dispensary», «Ivanova»,
«construction de machines», «bouleaux», «60 ans», «ingénieur électricien», «centrolite»,
«clinique oncologique», «champ de tir», «golovintsy», «corail», «sud», «printemps»,
Efremova, Border, Belgut, Gomelstroy, Borisenko, Athletics Palace,
«Michurinsky», «solaire», «gastello», «militaire», «centre automobile», «plomberie», «uza»,
«collège médical», «maternelle 11», «bolchevik», «chiots», «Davydovsky», «océan», «progrès»,
«Dobrushskaya», «blanc», «GSK», «davydovka», «équipement électrique», «amitié»,
«70 ans», «réparation automobile», «colline suédoise», «circuit», «canal d'eau», «machine gomel»,
Volotova, Pioneer, RCM, Khimtorg, 2nd Meadow Lane, Bochkina, Baths,
«clinique oncologique», «carré», «Lénine», «1ère école», «magasin sud»,
«gomelagrotrans», «meuniers», «lyubensky», «bureau d'enrôlement militaire», «hôpital», «uza», «rtsrm»,
«lysyukovyh», «shop iput», «raton», «gas station», «randovsky», «farmhouse», «châtaignier», «ropovsky»,
«Romanovichi», «Ilyich», «aviron», «entreprise de construction», «infectieux»,
«fat factory», «car service», «agroservice», «sticky», «Nikolskaya»,
«abatteuses automotrices», «maçons», «matériaux de construction», «machines de réparation», «administration»,
«Octobre», «conte de fées forestier», «Tatiana», «Boris Tsarikov», «Zharkovsky», «Zaitseva»,
«délocalisation», «Karpovich», «usine de construction de maisons», «transports électriques urbains», «zlin»,
«stade gomselmash», «ap 6», «entraînement hydraulique», «dépôt de locomotives», «marché automobile osovtsy»,
«nouvelle vie», «Zhukova», «unité militaire», «3e école», «forêt», «phare rouge»,
«régional», «Davydovskaya», «Karbysheva», «satellite du monde», «jeunesse», «locomotive du stade»,
«solaire», «Ladaservice», «μR 21», «Aresa», «internationalistes», «Kosareva»,
«Bogdanova», «Gomel iron-concrete», «μr 20a», «μr Rechitsky», «medical equipment», «Juraeva»,
«collège d'artisanat d'art», «glace», «festival dk», «centre commercial»,
'Kuibyshevsky', 'festival', 'garage koop 27', 'génie sismique', 'milcha', 'tube hospital',
«ptu179», «produits chimiques», «pompiers», «hôpital», «dépôt de bus»,
«complexe de journaux», «victoire», «klenkovsky», «diamant», «réparation de moteur», «mkr 19»]
En utilisant .map et fuzzywuzzy.process.extractOne, nous trouvons l'arrêt avec la distance Levenshtein minimale dans la liste, après quoi nous remplaçons le texte du commentaire par le nom de l'arrêt, ce qui nous permet d'obtenir un ensemble de données avec les noms des arrêts.
L'ensemble de données résultant ressemble à ceci:
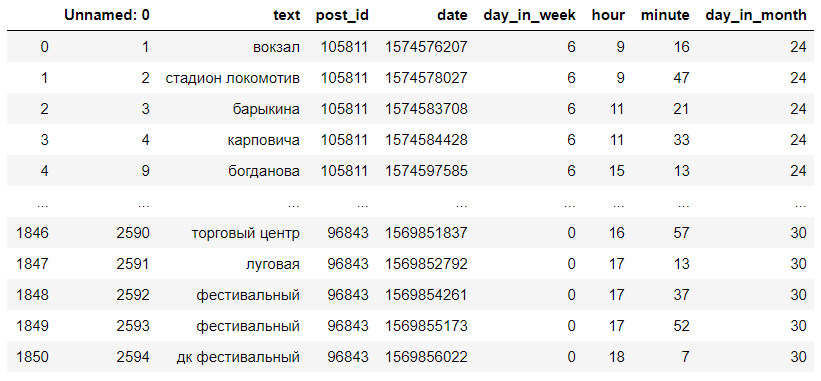
Les commentaires se transforment en arrêts def get_category_from_comment(text): """ """ dict = process.extractOne(text.lower(), stops) if dict[1] > 75: text = dict[0] else: text = np.nan print("wait") return text def get_category_dataset(data): """ """ print("remap started. wait") data.text = data.text.map(lambda comment: get_category_from_comment(str(comment))) print("remap ends") data.dropna(inplace=True) data["text"] = data.text.map(lambda s: "" if s=="" else s) data["text"] = data.text.map(lambda s: "" if s=="" else s) data["text"] = data.text.map(lambda s: " " if s=="" else s) data["text"] = data.text.map(lambda s: " " if s=="" else s) return data
Sortie de données
Nous pouvons maintenant supposer où les contrôleurs seront le plus probablement à l'heure donnée.
Nous recherchons dans les enregistrements de données résultants pour une heure et un jour spécifiques de la semaine. Par exemple, le mardi à 9 h:
<code>data[(data["day_in_week"] == day) & (data["hour"] == hour)]</code>
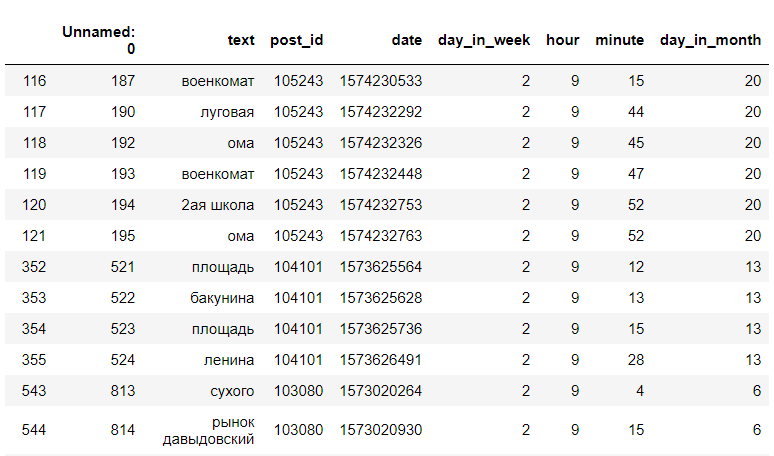 (ce ne sont pas toutes les données)
(ce ne sont pas toutes les données)Après cela, nous trouvons le nombre d'arrêts uniques et affichons uniquement les arrêts et leur nombre:
df[(df["day_in_week"] == 2) & (df["hour"] == 9)]["text"].value_counts()

Maintenant, nous pouvons dire qu'à 9 heures du matin, le mardi, les contrôleurs seront très probablement repérés aux arrêts Myasokombinat, ul. Lugovaya, BelGUT, TD «Oma».
Le principal défaut de cette méthode est le manque de données. Pas pour tous les jours et heures, il y a des entrées dans les commentaires donnés aux heures de pointe, lorsque les gens utilisent plus les transports publics que les données aux heures moins populaires, mais si vous ajoutez des données, par exemple, non seulement à partir des commentaires d'un groupe, mais aussi à partir de groupes alternatifs ou de chats télégrammes, avec le nombre d'entrées, tout deviendra plus facile.
Bot avec VK LongPoll API
Pour donner la possibilité de recevoir des données sur l'emplacement des contrôleurs, selon l'heure, et sans être lié à un ordinateur, j'ai créé un bot pour un groupe sur VKontakte qui répond à n'importe quel message en envoyant le nombre d'arrêts dans les enregistrements, compte tenu de l'heure et du jour de la semaine.
Code Bot from random import randint import vk_api from requests import * from get_stops_from_data import get_stops_by_time def start_bot(data, token): vk_session = vk_api.VkApi(token=token) vk = vk_session.get_api() print("bot started") longPoll = vk.groups.getLongPollServer(group_id=183524419) server, key, ts = longPoll['server'], longPoll['key'], longPoll['ts'] while True:
Conclusion
La qualité de telles hypothèses a été testée par moi plus d'une fois dans la pratique, et tout fonctionne bien. Il s'est avéré que les contrôleurs, au fond, sont aux mêmes arrêts, bien que des prévisions absolument correctes ne puissent pas être données, et la probabilité de succès n'est pas de 100%. La distance de Levenshtein a des dizaines d'applications différentes, de la correction d'erreurs en un mot, à la comparaison de gènes, de chromosomes et de protéines, mais elle a également un potentiel dans de tels problèmes appliqués.
Passez une bonne journée et payez le prix.
Toutes les manipulations de code bot et de données sont publiées
ici .