Bonjour à tous! Je m'appelle Alexey Skorobogaty, je suis architecte système chez Lamoda. En février 2019, j'ai pris la parole lors de Go Meetup tout en restant dans la position de chef d'équipe de l'équipe principale. Aujourd'hui, je veux présenter une transcription de mon rapport, que vous pouvez également voir.
Notre équipe s'appelle Core pour une raison: le domaine de responsabilité comprend tout ce qui concerne les commandes dans la plateforme de commerce électronique. L'équipe était formée de développeurs PHP et de spécialistes de notre traitement des commandes, qui à l'époque était un monolithe unique. Nous étions engagés et continuons à gérer sa décomposition en microservices.

Une commande dans notre système se compose de composants associés: il y a une unité de livraison et un panier, des unités de remise et de paiement, et à la fin il y a un bouton qui envoie la commande à retirer à l'entrepôt. C'est à ce moment que commence le travail du système de traitement des commandes, où toutes les données de commande seront validées et les informations agrégées.
À l'intérieur de tout cela, il y a une logique multicritère complexe. Les blocs interagissent les uns avec les autres et s'influencent mutuellement. Les changements continus et constants de l'entreprise ajoutent à la complexité des critères. De plus, nous avons différentes plateformes à travers lesquelles les clients peuvent créer des commandes: site web, applications, centre d'appels, plateforme B2B. Ainsi que des critères SLA / MTTI / MTTR rigoureux (mesures d'enregistrement et résolution des incidents). Tout cela nécessite une grande flexibilité et stabilité du service.
Patrimoine architectural
Comme je l'ai déjà dit, au moment de la formation de notre équipe, le système de traitement des commandes était un monolithe - près de 100 000 lignes de code qui décrivaient directement la logique métier. La partie principale a été écrite en 2011 en utilisant l'architecture MVC multicouche classique. Il était basé sur PHP (le framework ZF1), qui a été progressivement envahi par des adaptateurs et des composants symfony pour interagir avec divers services. Au cours de son existence, le système comptait plus de 50 contributeurs, et bien que nous ayons réussi à maintenir un style unifié d'écriture de code, cela a également imposé ses limites. En outre, un grand nombre de contextes mixtes sont apparus - pour diverses raisons, certains mécanismes ont été mis en œuvre dans le système qui n'étaient pas directement liés au traitement des commandes. Tout cela a conduit au fait que nous avons actuellement une base de données MySQL supérieure à 1 téraoctet.
Schématiquement, l'architecture initiale peut être représentée comme suit:
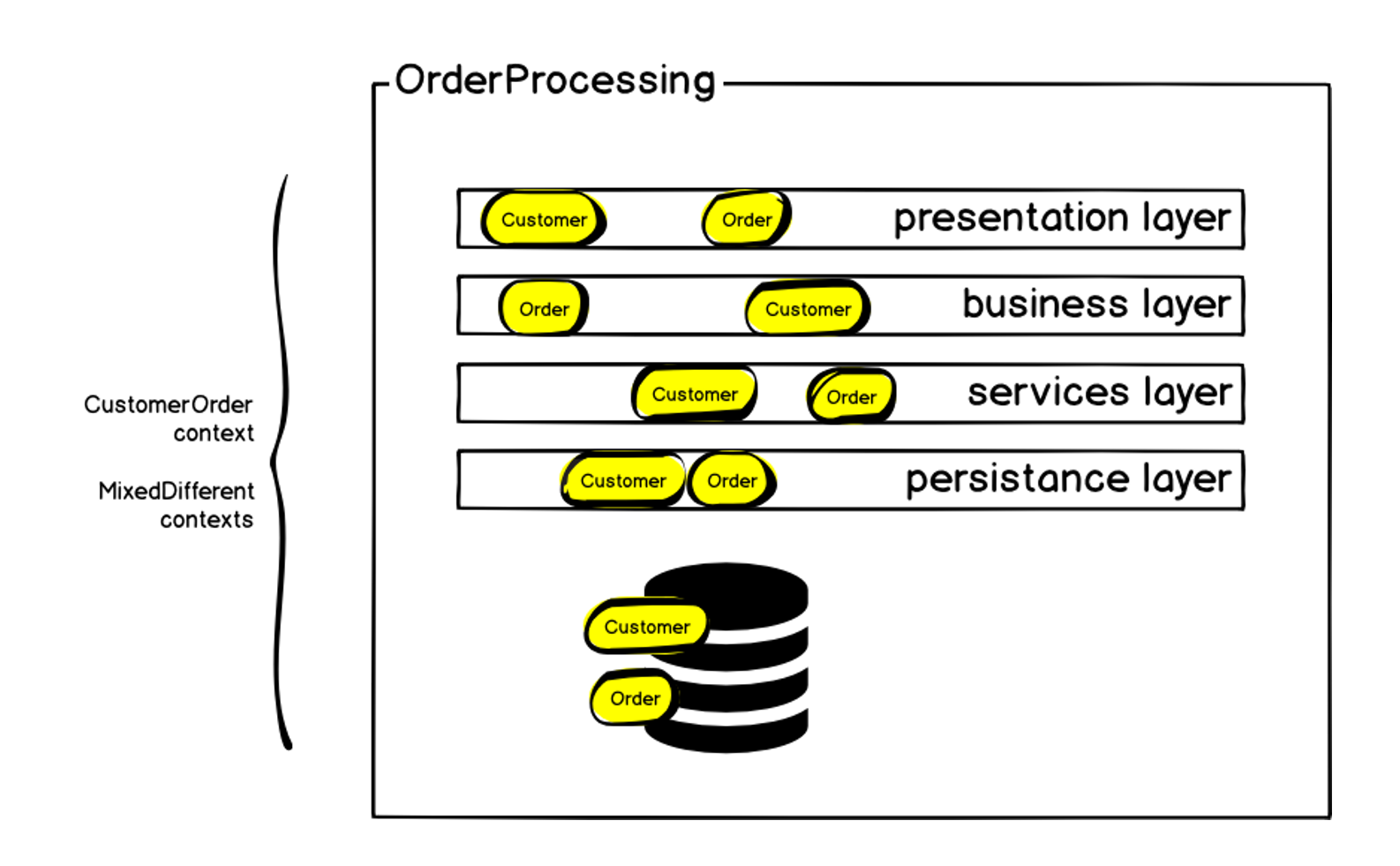
L'ordre, bien sûr, était sur chacune des couches - mais en plus de l'ordre, il y avait d'autres contextes. Nous avons commencé par définir le contexte délimité de la commande et l'appeler la Commande Client, car en plus de la commande elle-même, il y a les mêmes blocs que j'ai mentionnés au début: livraison, paiement, etc. À l'intérieur du monolithe, tout cela était difficile à gérer: tout changement entraînait une augmentation des dépendances, le code était livré au prod depuis très longtemps, et la probabilité d'erreurs et de défaillances du système augmentait tout le temps. Mais nous parlons de créer une commande, la métrique principale d'une boutique en ligne - si les commandes ne sont pas créées, le reste n'est pas si important. Une défaillance du système entraîne une baisse immédiate des ventes.
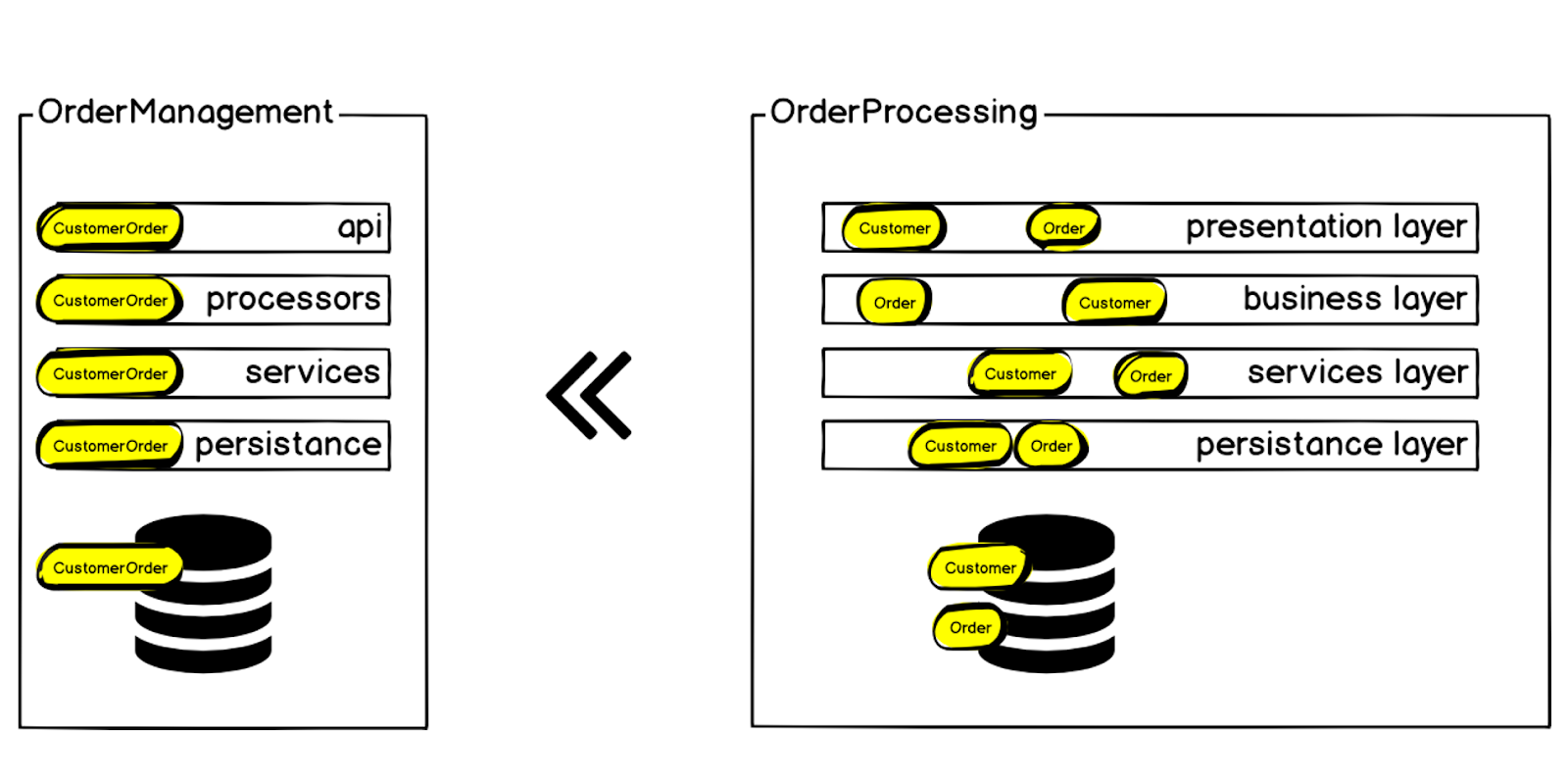
Par conséquent, nous avons décidé de transférer le contexte de commande client du système de traitement des commandes vers un microservice distinct, appelé Gestion des commandes.
Exigences et outils
Après avoir déterminé le contexte que nous avons décidé de retirer du monolithe en premier lieu, nous avons formé les exigences pour notre futur service:
- Performances
- Cohérence des données
- Durabilité
- Prévisibilité
- La transparence
- Incrément de changement
Nous voulions que le code soit aussi clair et facile à modifier que possible, afin que la prochaine génération de développeurs puisse rapidement apporter les modifications nécessaires à l'entreprise.
En conséquence, nous sommes arrivés à une certaine structure que nous utilisons dans tous les nouveaux microservices:
Contexte délimité . Chaque nouveau microservice, à commencer par la gestion des commandes, nous créons en fonction des besoins de l'entreprise. Il doit y avoir des explications spécifiques sur quelle partie du système et pourquoi il est nécessaire de le placer dans un microservice séparé.
Infrastructure et outils existants. Nous ne sommes pas la première équipe de Lamoda à commencer à implémenter Go; avant nous, il y avait des pionniers - l'équipe Go elle-même, qui a préparé l'infrastructure et les outils:
- Gogi (swagger) est un générateur de spécification de swagger.
- Gonkey (testing) - pour les tests fonctionnels.
- Nous utilisons Json-rpc et générons une liaison client / serveur par swagger. Nous déployons également tout cela sur Kubernetes, collectons des métriques dans Prometheus, utilisons ELK / Jaeger pour le traçage - tout cela est inclus dans le bundle que Gogi crée pour chaque nouveau microservice par spécification.
Voici à quoi ressemble notre nouveau microservice de gestion des commandes:
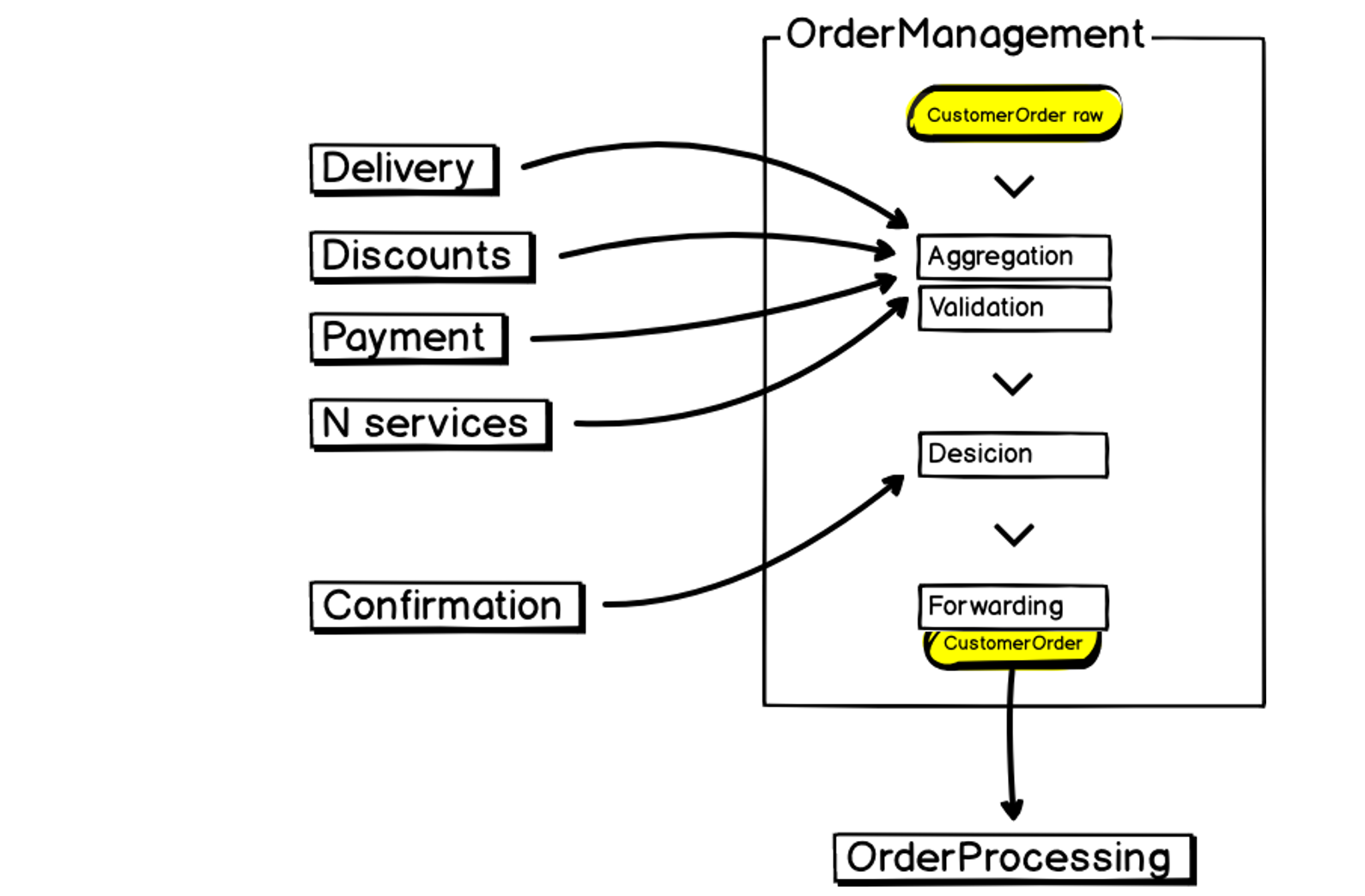
En entrée, nous avons des données, nous les agrégons, les validons, interagissons avec des services tiers, prenons des décisions et transférons les résultats au traitement des commandes - le même monolithe qui est grand, instable et gourmand en ressources. Cela doit également être pris en compte lors de la création d'un microservice.
Changement de paradigme
En choisissant Go, nous avons immédiatement obtenu plusieurs avantages:
- Le typage fort statique coupe immédiatement une certaine gamme de bogues possibles.
- Le modèle de concurrence correspond bien à nos tâches, car nous devons nous déplacer et interroger simultanément plusieurs services.
- La composition et les interfaces nous aident également dans les tests.
- La «simplicité» de l'étude - c'est ici que non seulement des avantages évidents ont été découverts, mais aussi des problèmes.
La langue de Go limite l'imagination du développeur. Cela est devenu une pierre d'achoppement pour notre équipe, habituée à PHP lorsque nous sommes passés au développement sur Go. Nous sommes confrontés à un véritable changement de paradigme. Nous avons dû passer par plusieurs étapes et comprendre certaines choses:
- Il est difficile de construire des abstractions.
- On peut dire que go est basé sur un objet, mais pas un langage orienté objet, car il n'y a pas d'héritage direct et d'autres choses.
- Go aide à écrire explicitement, plutôt que de cacher des objets derrière des abstractions.
- Allez a pipelining. Cela nous a inspiré pour construire des chaînes de processeurs de données.
En conséquence, nous avons compris que Go est un langage de programmation procédural.

Les données d'abord
Je pensais comment visualiser le problème auquel nous étions confrontés et suis tombé sur cette image:
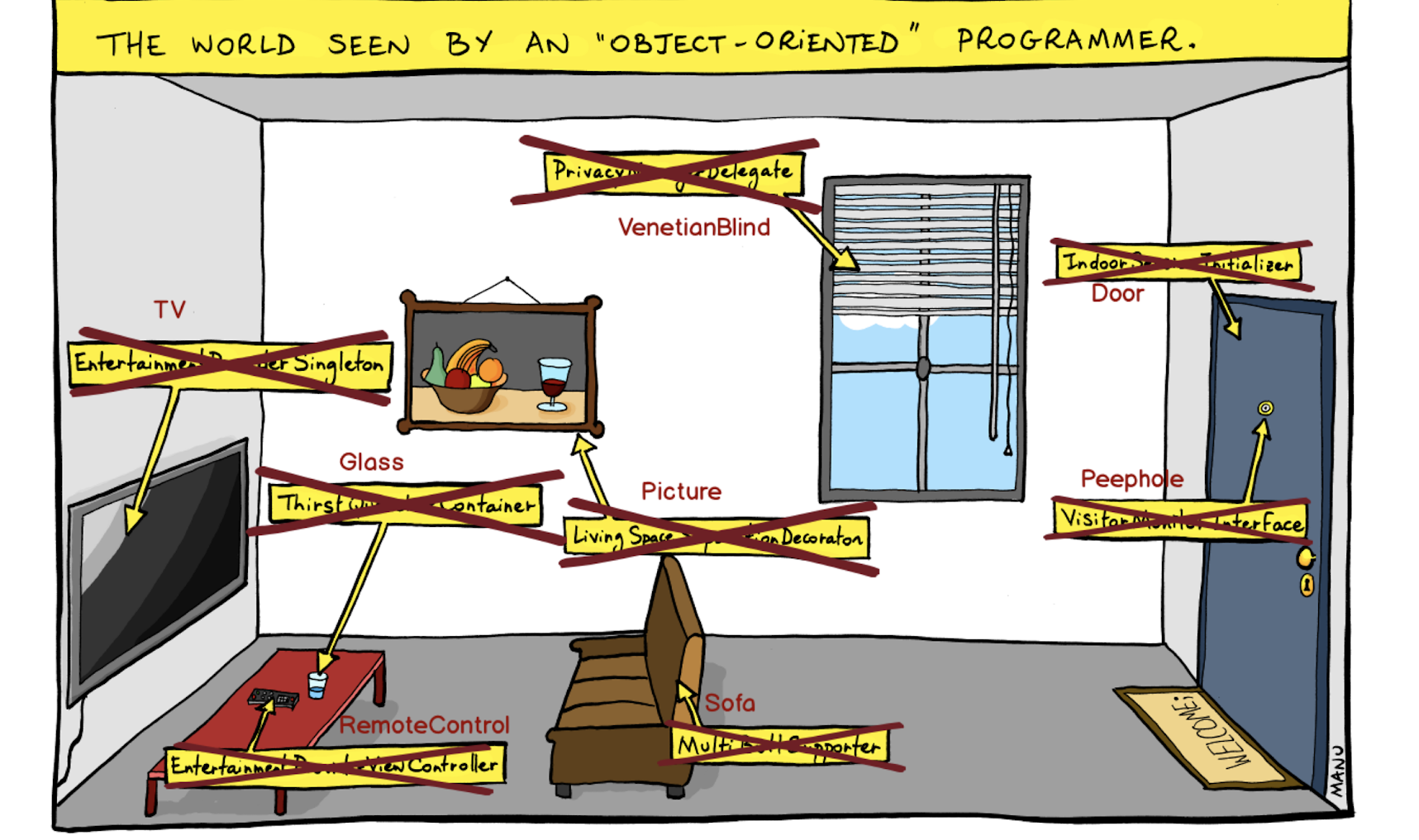
Il s'agit d'une vision «orientée objet» du monde où nous construisons des abstractions et fermons des objets derrière elles. Par exemple, voici non seulement une porte, mais un initialiseur de session intérieure. Pas l'élève, mais l'interface du moniteur de visiteurs - et ainsi de suite.
Nous avons abandonné cette approche et mis les entités en premier lieu, sans devenir obscurcis par les abstractions.
En raisonnant de cette façon, nous avons mis les données en premier lieu et avons mis un tel Pipelining dans le service:

Initialement, nous définissons un modèle de données qui entre dans le pipeline du gestionnaire. Les données sont modifiables et les modifications peuvent se produire de manière séquentielle et simultanée. Avec cela, nous gagnons en vitesse.
Retour vers le futur
Du coup, en développant des microservices, nous sommes arrivés au modèle de programmation des années 70. Après les années 70, de grands monolithes d'entreprise sont apparus, où la programmation orientée objet est apparue, et la programmation fonctionnelle - de grandes abstractions qui ont permis de conserver le code dans ces monolithes. Dans les microservices, nous n'avons pas besoin de tout cela, et nous pouvons utiliser l'excellent modèle de CSP ( communicating sequential process ), dont l'idée a été avancée juste dans les années 70 par Charles Choir.
Nous utilisons également Sequence / Selection / Interation - un paradigme de programmation structurelle selon lequel tout le code de programme peut être composé des structures de contrôle correspondantes.
Eh bien, la programmation procédurale, qui était le courant dominant dans les années 70 :)
Structure du projet

Comme je l'ai dit, en premier lieu, nous avons mis les données. De plus, nous avons remplacé la construction du projet «à partir de l'infrastructure» par une construction à vocation commerciale. Pour que le développeur, en entrant le code du projet, voit immédiatement ce que fait le service - c'est la transparence même que nous avons identifiée comme l'une des exigences de base pour la structure de nos microservices.
En conséquence, nous avons une architecture plate: une petite couche API et des modèles de données. Et toute la logique (qui est limitée dans notre contexte par les exigences métier d'un microservice) est stockée dans des processeurs (gestionnaires).
Nous essayons de ne pas créer de nouveaux microservices séparés sans une demande claire de l'entreprise - c'est ainsi que nous contrôlons la granularité de l'ensemble du système. S'il existe une logique étroitement liée au microservice existant, mais se référant essentiellement à un contexte différent, nous la concluons d'abord dans les soi-disant services. Et seulement lorsque survient un besoin commercial constant, nous le retirons dans un microservice distinct, auquel nous nous tournons ensuite en utilisant un appel rpc.
Afin de contrôler la granularité et de ne pas produire de microservices sans réfléchir, nous concluons une logique qui n'est pas directement liée à ce contexte, mais qui est étroitement liée à ce microservice, dans la couche services. Et puis, s'il y a un besoin commercial, nous le prenons dans un microservice distinct - puis nous l'utilisons avec l'appel rpc pour y accéder.
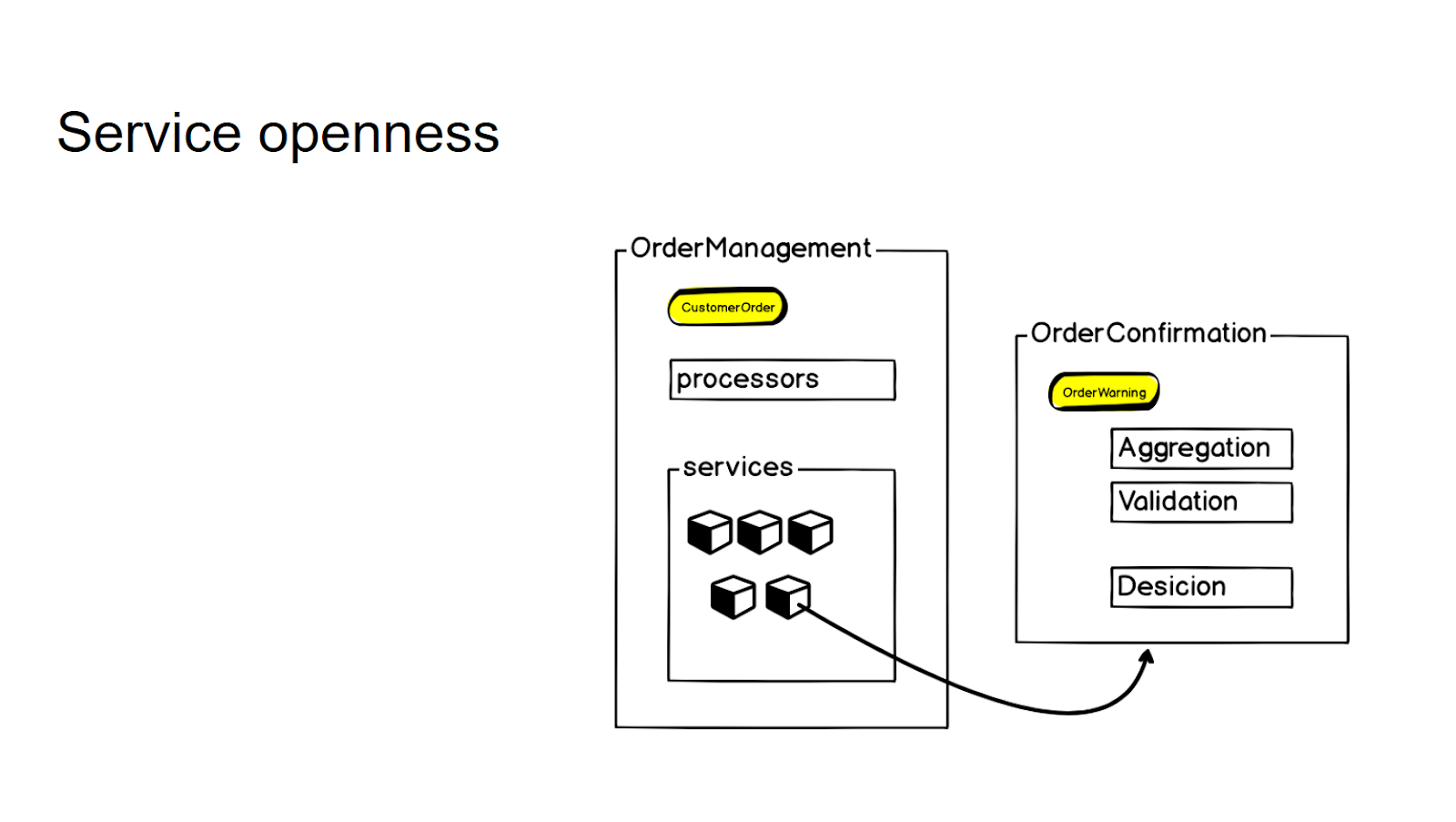
Ainsi, pour l'API interne dans les processeurs du service, l'interaction ne change en rien.
Durabilité
Nous avons décidé de ne pas prendre de bibliothèques tierces à l'avance, car les données avec lesquelles nous travaillons sont assez sensibles. Nous avons donc fait un peu de vélo :) Par exemple, nous avons nous-mêmes implémenté des mécanismes classiques - pour Idempotency, Queue-worker, Fault Tolerance, Compensating transactions. Notre prochaine étape consiste à essayer de le réutiliser. Enveloppez-vous dans des bibliothèques, peut-être des conteneurs latéraux dans des pods Kubernetes. Mais maintenant, nous pouvons appliquer ces modèles.
Nous mettons en œuvre dans nos systèmes un schéma appelé dégradation gracieuse: le service doit continuer à fonctionner, quels que soient les appels externes dans lesquels nous agrégons les informations. Sur l'exemple de la création d'une commande: si la demande est entrée dans le service, nous créerons une commande dans tous les cas. Même si le service voisin tombe, qui est responsable d'une partie des informations que nous devons agréger ou valider. De plus - nous ne perdrons pas la commande, même si nous ne pouvons pas à court terme refuser le traitement de la commande, où nous devons transférer. C'est également l'un des critères par lesquels nous décidons de mettre la logique dans un service séparé. Si un service ne peut pas fournir son travail lorsque les services suivants ne sont pas disponibles sur le réseau, vous devez soit le reconcevoir, soit vous demander s'il doit être retiré du monolithe.
Allez à Go!
Lorsque vous venez d'écrire des microservices de produits orientés métier à partir d'une architecture classique orientée services, en particulier PHP, vous rencontrez un changement de paradigme. Et il doit être adopté, sinon vous pouvez monter sur le râteau sans fin. La structure commerciale du projet nous permet de ne pas compliquer à nouveau le code et de contrôler la granularité du service.
L'une de nos tâches principales était d'augmenter la stabilité du service. Bien sûr, Go n'offre pas une stabilité accrue juste à la sortie de la boîte. Mais, à mon avis, dans l'écosystème Go, il s'est avéré plus facile de créer tout le kit de fiabilité nécessaire, même de vos propres mains, sans avoir recours à des bibliothèques tierces.
Une autre tâche importante consistait à accroître la flexibilité du système. Et ici, je peux certainement dire que le taux d'introduction des changements requis par l'entreprise a considérablement augmenté. Grâce à l'architecture des nouveaux microservices, le développeur se retrouve seul avec des fonctionnalités métier; il n'a pas besoin de penser à la construction de clients, à l'envoi de surveillance, à l'envoi de suivi et à la configuration de la journalisation. Nous laissons au développeur exactement la couche d'écriture de la logique métier, lui permettant de ne pas penser à l'ensemble du bundle d'infrastructure.
Allons-nous tout réécrire sur Go et abandonner PHP?
Non, puisque nous nous éloignons des besoins des entreprises, et il existe certains contextes dans lesquels PHP s'intègre très bien - il n'a pas besoin d'une telle vitesse et de la boîte à outils Go-go entière. Toute automatisation des opérations pour la livraison des commandes et la gestion du studio photo se fait en PHP. Mais, par exemple, dans la plateforme e-commerce côté client, on réécrit presque tout sur Go, car là c'est justifié.