Spring est un puissant framework Java open source. J'ai décidé de vous dire pour quelles tâches le backend Spring est utile et quels sont ses avantages et ses inconvénients par rapport aux autres bibliothèques: Guice et Dagger 2. Envisagez l'injection de dépendances et l'inversion de contrôle - vous apprendrez comment commencer à étudier ces principes.
- Bonjour à tous, je m'appelle Cyril. Aujourd'hui, je vais parler de l'injection de dépendance.
Nous allons commencer par le nom de mon rapport. "Dans un certain royaume, pas dans un état" naissant "." Nous parlerons, bien sûr, du printemps, mais je veux aussi regarder tout ce qui est en dehors de lui. De quoi parlerons-nous précisément?

Je vais faire une petite digression - vous dire sur quoi je travaille, quel est mon projet, pourquoi nous utilisons l'injection de dépendance. Ensuite, je vais vous dire de quoi il s'agit, comparer l'inversion de contrôle et l'injection de dépendances, et parler de son implémentation dans les trois bibliothèques les plus célèbres.
Je travaille dans l'équipe Yandex.Tracker. Nous fabriquons un analogue d'épicerie de Jira ou Trello. [...] Nous avons décidé de fabriquer notre propre produit, qui était d'abord interne. Maintenant, nous le vendons. Chacun de vous peut entrer, créer son propre tracker et effectuer des tâches, par exemple pédagogiques ou professionnelles.
Regardons l'interface. Dans les exemples, j'utiliserai certains termes de ma région. Nous allons essayer de créer un ticket et regarder les commentaires que d'autres collègues me laisseront dedans.
Pour commencer, qu'est-ce que l'injection de dépendance en général? C'est un modèle de programmation qui répond au vieil adage américain, au principe hollywoodien: "Ne nous appelez pas, nous vous appellerons nous-mêmes." Les dépendances elles-mêmes viennent à nous. Il s'agit principalement d'un modèle, pas d'une bibliothèque. Par conséquent, en principe, un tel modèle est commun presque partout. Vous pourriez même dire que toutes les applications utilisent l'injection de dépendance d'une manière ou d'une autre.

Voyons comment vous pouvez proposer vous-même l'injection de dépendance si nous partons de zéro. Supposons que j'ai décidé de développer une classe si petite dans laquelle je vais créer un ticket via notre API. Par exemple, créez une instance de la classe TrackerApi. Il a une méthode createTicket dans laquelle nous enverrons mon e-mail. Nous créerons un ticket sous mon compte avec le nom: "Préparer un rapport pour Java Meetup".

Voyons l'implémentation de TrackerApi. Ici, par exemple, nous pouvons le faire: créer une instance httpClient. En termes simples, nous allons créer un objet à travers lequel nous irons à l'API. A travers cet objet, nous appellerons la méthode execute dessus.

Par exemple, un personnalisé. J'ai écrit du code externe de ces classes, et il l'utilisera quelque chose comme ça. Je crée un nouveau TicketCreator et j'appelle la méthode createTicket dessus.

Il y a un problème ici - chaque fois que nous créons un ticket, nous recréerons et recréerons httpClient, bien qu'en général, cela ne soit pas nécessaire. httpClients est très sérieux à créer.

Essayons de le faire. Ici vous pouvez voir le tout premier exemple d'Injection de dépendances dans notre code. Faites attention à ce que nous avons fait. Nous avons retiré notre variable dans le champ et l'avons remplie dans le constructeur. Le fait que nous le remplissions dans le constructeur signifie que les dépendances nous viennent. Il s'agit de la première injection de dépendance.

Nous avons transféré la responsabilité aux utilisateurs du code, nous devons donc maintenant créer un httpClient, en le transmettant, par exemple, à TicketCreator.
Ce n'est pas non plus très bon ici, car maintenant, en appelant cette méthode, nous allons à nouveau créer httpClient à chaque fois.

Par conséquent, nous l'emportons à nouveau sur le terrain. Et ici, en passant, il y a un exemple non évident d'injection de dépendance. Nous pouvons dire que nous créons toujours des billets sous moi (ou sous quelqu'un d'autre). Nous créerons chaque objet TicketCreator distinct sous différents utilisateurs.
Par exemple, celui-ci créera sous moi lorsque nous le créerons. Et la ligne que nous passons au constructeur est également l'injection de dépendance.

Comment allons-nous faire maintenant? Créez une nouvelle instance de TrackerTicketCreator et appelez la méthode. Maintenant, nous pouvons même créer une sorte de méthode personnalisée qui créera un ticket avec du texte personnalisé pour nous. Par exemple, créez un ticket "Embaucher un nouveau stagiaire".

Essayons maintenant de voir à quoi ressemblerait notre code si nous voulions lire les commentaires dans ce ticket de la même manière, sous moi. Il s'agit du même code. Nous appellerions la méthode getComments sur ce ticket.
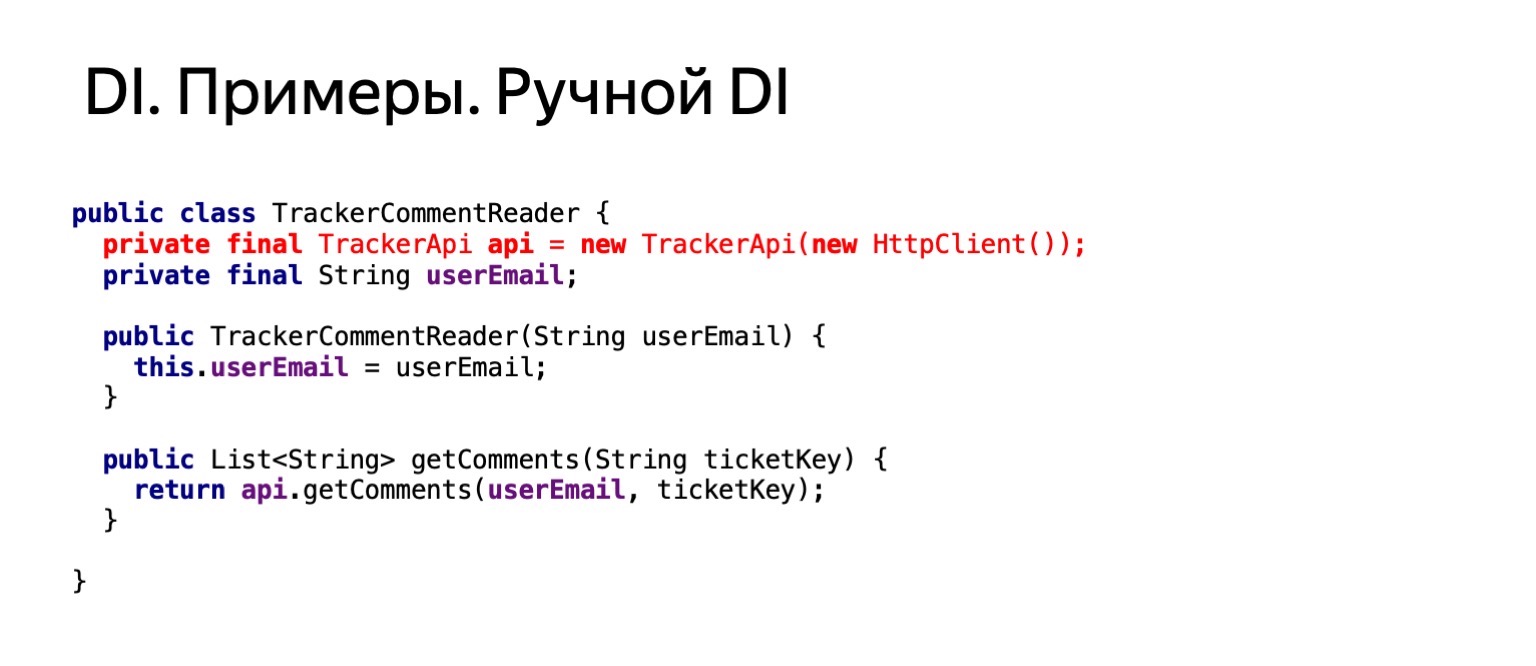
À quoi ressemblerait-il? Si nous prenons et dupliquons cette fonctionnalité dans un lecteur de commentaires, nous dupliquons la création de httpClient. Cela ne nous convient pas. Nous voulons nous en débarrasser.

Bon. Passons maintenant tous ces paramètres en injection de dépendance, en tant que paramètres de constructeur.

Quel est le problème ici? Nous avons tout ignoré, mais dans le code utilisateur, nous écrivons maintenant «passe-partout». Il s'agit d'une sorte de code inutile qu'un utilisateur doit généralement écrire pour effectuer une action relativement petite en termes de logique. Ici, nous devrons constamment créer httpClient, une API pour celui-ci et sélectionner les e-mails des utilisateurs. Chaque utilisateur de TicketCreator devra le faire lui-même. Ce n'est pas ok. Nous allons maintenant essayer de voir à quoi il ressemblera dans les bibliothèques lorsque nous essaierons de l'éviter.
Maintenant, dévions un peu et regardons ce qu'est l'inversion de contrôle, car beaucoup y associent l'injection de dépendance.

Inversion of Control est un principe de programmation dans lequel les objets que nous utilisons ne sont pas créés par nous. Nous n'affectons pas du tout leur cycle de vie. En règle générale, l'entité qui crée ces objets est appelée conteneur IoC. Beaucoup d'entre vous ont entendu parler du printemps ici. La documentation de Spring indique que les IoC sont également appelées injection de dépendance. Ils croient que c'est la même chose.

Quels sont les principes de base? Les objets sont créés non pas par le code d'application, mais par un conteneur IoC. En tant qu'utilisateurs de la bibliothèque, nous ne faisons rien, tout nous vient tout seul. Bien sûr, l'IoC est relative. Le conteneur IoC lui-même crée ces objets, ce qui ne lui est plus applicable. Vous pourriez penser que l'IoC implémente non seulement les bibliothèques DI. Les bibliothèques Java bien connues Servlets et Akka Actors, qui sont maintenant utilisées dans Scala et dans le code Java.

Parlons des bibliothèques. De manière générale, de nombreuses bibliothèques ont déjà été écrites pour Java et Kotlin. Je vais énumérer les principaux:
- Spring, un super cadre. Sa partie principale est l'injection de dépendance ou, comme on dit, l'inversion de contrôle.
- Guice est une bibliothèque qui a été écrite approximativement entre le deuxième et le troisième printemps lorsque Spring est passé du XML à la description du code. Autrement dit, quand le printemps n'était pas encore si beau.
- Dagger est ce que les gens utilisent généralement sur Android.
Essayons de réécrire notre exemple sur Spring.

Nous avions notre TrackerApi. Je n'ai pas inclus l'utilisateur ici pour faire court. Supposons que nous essayions dans l'injection de dépendances de faire pour httpClient. Pour ce faire, nous devons le déclarer avec une annotation.
Le composant , la classe entière, et en particulier le constructeur, sont déclarés avec l'annotation
Autowired . Qu'est-ce que cela signifie pour le printemps?

Nous avons une telle configuration dans le code, elle est indiquée par l'annotation
Component Scan. Cela signifie que nous allons essayer de parcourir l'arborescence entière de nos classes dans le package dans lequel il est contenu. Et plus à l'intérieur des terres, nous essaierons de trouver toutes les classes marquées dans l'annotation
Component .
Ces composants tomberont dans le conteneur IoC. Il est important pour nous que tout tombe pour nous. Nous ne marquons que ce que nous voulons annoncer. Pour que quelque chose nous arrive, nous devons le déclarer en utilisant l'annotation
Autowired dans le constructeur.

TicketCreator nous marquons exactement de la même manière.

Et CommentReader aussi.
Revenons maintenant à la configuration. Comme nous l'avons dit, Component Scan mettra tout dans un conteneur IoC. Mais il y a un point, la méthode dite d'usine. Nous avons la méthode httpClient, que nous ne créons pas en tant que classe, car httpClient nous vient de la bibliothèque. Il ne comprend pas ce qu'est Spring, etc. Nous allons le créer directement dans la configuration. Pour ce faire, nous écrivons une méthode qui le construit généralement une fois et la marquons avec l'annotation Bean.

Quels sont les avantages et les inconvénients? Le principal avantage - le printemps est très commun dans le monde. Le prochain plus et moins est la numérisation automatique. Nous ne devons pas déclarer explicitement nulle part que nous voulons ajouter un conteneur à IoC en plus des annotations sur les classes elles-mêmes. Assez d'annotations. Et le moins est exactement le même: si, au contraire, nous voulons contrôler cela, alors Spring ne nous le fournit pas. À moins que nous ne puissions dire dans notre équipe: «Non, nous ne le ferons pas. Nous devons clairement prescrire quelque chose quelque part. Seulement dans la configuration, comme nous l'avons fait avec les haricots.
De plus, à cause de cela, un démarrage lent se produit. Lorsque l'application démarre, Spring doit parcourir toutes ces classes et déterminer ce qu'il faut mettre dans le conteneur IoC. Cela le ralentit. Le plus gros inconvénient du printemps, il me semble, est l'arbre de dépendance. Il n'est pas vérifié au stade de la compilation. Lorsque Spring démarre à un moment donné, il doit comprendre si j'ai une telle dépendance à l'intérieur. S'il s'avère plus tard qu'il ne se trouve pas dans l'arborescence des dépendances, vous obtiendrez une erreur lors de l'exécution. Et nous, en Java, ne voulons pas d'erreur d'exécution. Nous voulons que le code soit compilé pour nous. Cela signifie que cela fonctionne.

Jetons un coup d'œil à Guice. Il s'agit d'une bibliothèque qui, comme je l'ai dit, a été créée entre le deuxième et le troisième printemps. La beauté que nous avons vue ne l'était pas. Il y avait XML. Pour résoudre ce problème, et a été écrit par Guice. Et ici, vous pouvez voir que, contrairement à la configuration, nous écrivons un module. Dans ce document, nous déclarons explicitement quelles classes nous voulons mettre dans ce module: TrackerAPI, TrackerTicketCreator et tous les autres bacs. Un analogue de l'annotation Bean ici est Provides, qui crée httpClient de la même manière.

Nous devons déclarer chacun de ces beans. Nous citerons un exemple de
Singleton . Mais spécifiquement,
Singleton dira qu'un tel bean sera créé exactement une fois. Nous ne le recréerons pas constamment. Et
Inject , respectivement, est un analogue d'
Autowired .

Une petite tablette avec ce qui appartient.

Quels sont les avantages et les inconvénients? Pour: c'est plus simple, il me semble, et compréhensible que la version XML de Spring. Démarrage plus rapide. Et voici le contre: il nécessite une déclaration explicite des beans utilisés. Nous aurions dû écrire Bean. Mais d'un autre côté, c'est un plus, comme nous l'avons déjà dit. Ceci est une image miroir de ce que Spring a. Bien sûr, c'est moins courant que le printemps. C'est son inconvénient naturel. Et il y a exactement le même problème - l'arbre de dépendance n'est pas vérifié au stade de la compilation.
Lorsque les gars ont commencé à utiliser Guice pour Android, ils ont réalisé qu'ils manquaient toujours de vitesse de lancement. Par conséquent, ils ont décidé d'écrire un cadre d'injection de dépendances plus simple et plus primitif qui leur permettra de démarrer rapidement l'application, car pour Android, c'est très important.

Ici, la terminologie est la même. Dagger a exactement les mêmes modules que Guice. Mais ils sont déjà marqués d'annotations, pas comme dans le cas de l'héritage de la classe. Par conséquent, le principe est maintenu.
Le seul inconvénient est que nous devons toujours indiquer explicitement dans le module comment les beans sont créés. Dans Guice, nous pourrions donner la création de beans à l'intérieur du bean lui-même. Nous n’avions pas à dire à quel type de dépendances nous devions nous adresser. Et ici, nous devons le dire explicitement.

Dans Dagger, parce que vous ne voulez pas faire de saisie trop manuelle, il y a le concept de composant. Un composant est quelque chose qui lie des modules lorsque nous voulons déclarer un bac d'un module afin qu'il puisse être pris dans un autre module. C'est un concept différent. Un bean d'un module peut «injecter» un bean d'un autre module à l'aide d'un composant.

Voici à peu près la même plaque récapitulative - ce qui a changé ou n'a pas changé dans le cas d'Inject ou de modules.

Quels en sont les avantages? C'est encore plus simple que Guice. Le lancement est encore plus rapide que Guice. Et cela ne deviendra probablement plus plus rapide, car Dagger a complètement abandonné la réflexion. C'est exactement la partie de la bibliothèque en Java qui est chargée de regarder l'état d'un objet, sa classe et ses méthodes. Autrement dit, obtenez l'état en cours d'exécution. Par conséquent, il n'utilise pas de réflexion. Il ne va pas et n'analyse pas les dépendances de qui que ce soit. Mais à cause de cela, il commence très rapidement.
Comment le fait-il? Utilisation de la génération de code.
Si nous regardons en arrière, nous verrons le composant d'interface. Nous n'avons implémenté aucune implémentation de cette interface, Dagger le fait pour nous. Et il sera possible d'utiliser davantage l'interface dans l'application.
Naturellement, il est très courant dans le monde Android en raison de cette vitesse. L'arbre des dépendances est vérifié immédiatement lors de la compilation, car il n'y a rien que nous vérifierons différemment lors de l'exécution.
Quels sont les inconvénients? Il a moins d'opportunités. Il est plus verbeux que Guice et Spring.

Au sein de ces bibliothèques, une initiative a vu le jour en Java - le soi-disant JSR-330. JSR est une demande de modification de la spécification de langue ou de la compléter avec quelques bibliothèques supplémentaires. Une telle norme a été proposée sur la base de Guice, et des annotations d'
injection ont été ajoutées à cette bibliothèque. En conséquence, Spring et Guice l'appuient.
Quelles conclusions peut-on en tirer? Java a beaucoup de bibliothèques différentes pour DI. Et vous devez comprendre pourquoi nous en prenons un spécifique. Si nous prenons Android, alors il n'y a déjà pas le choix, nous utilisons Dagger. Si nous allons dans le monde du backend, nous cherchons déjà ce qui nous convient le mieux. Et pour la première étude de Dependency Injection, il me semble que Guice est meilleur que Spring. Il n'y a rien de superflu là-dedans. Vous pouvez voir comment cela fonctionne, sentir.
Pour une étude plus approfondie, je vous suggère de vous familiariser avec la documentation de toutes ces bibliothèques et la composition de JSR:
-
Printemps-
Guice-
Dague 2-
JSR-330Je vous remercie!