Depuis la dernière publication dans le monde de la langue Julia, beaucoup de choses intéressantes se sont produites:
Dans le même temps, il y a une augmentation notable de l'intérêt des développeurs, qui se traduit par une abondante analyse comparative:
Nous nous réjouissons simplement des outils nouveaux et pratiques et continuons à les étudier. Ce soir sera consacré à l'analyse de texte, à la recherche de sens caché dans les discours des présidents et à la génération de texte dans l'esprit du programmeur Shakespeare et Julia, et pour le dessert, nous alimentons un réseau récurrent de 40000 tartes.
Récemment ici sur Habré la revue des packages pour Julia a été réalisée permettant d'effectuer des recherches dans le domaine de la PNL - Julia PNL. Nous traitons les textes . Commençons donc immédiatement et commençons par le package TextAnalysis .
TextAnalisys
Soit un texte donné, que nous représentons comme un document de chaîne:
using TextAnalysis str = """ Ich mag die Sonne, die Palmen und das Meer, Ich mag den Himmel schauen, den Wolken hinterher. Ich mag den kalten Mond, wenn der Vollmond rund, Und ich mag dich mit einem Knebel in dem Mund. """; sd = StringDocument(str)
StringDocument{String}("Ich mag die ... dem Mund.\n", TextAnalysis.DocumentMetadata(Languages.Default(), "Untitled Document", "Unknown Author", "Unknown Time"))
Pour un travail pratique avec un grand nombre de documents, il est possible de changer les champs, par exemple les titres, et aussi, pour simplifier le traitement, on peut supprimer la ponctuation et les majuscules:
title!(sd, "Knebel") prepare!(sd, strip_punctuation) remove_case!(sd) text(sd)
"ich mag die sonne die palmen und das meer \nich mag den himmel schauen den wolken hinterher \nich mag den kalten mond wenn der vollmond rund \nund ich mag dich mit einem knebel in dem mund \n"
qui vous permet de construire des n-grammes épurés pour les mots:
dict1 = ngrams(sd) Dict{String,Int64} with 26 entries: "dem" => 1 "himmel" => 1 "knebel" => 1 "der" => 1 "schauen" => 1 "mund" => 1 "rund" => 1 "in" => 1 "mond" => 1 "dich" => 1 "einem" => 1 "ich" => 4 "hinterher" => 1 "wolken" => 1 "den" => 3 "das" => 1 "palmen" => 1 "kalten" => 1 "mag" => 4 "sonne" => 1 "vollmond" => 1 "die" => 2 "mit" => 1 "meer" => 1 "wenn" => 1 "und" => 2
Il est clair que les signes de ponctuation et les mots avec des majuscules seront des unités distinctes dans le dictionnaire, ce qui interférera avec une évaluation qualitative des occurrences de fréquence des termes spécifiques de notre texte, nous nous en sommes donc débarrassés. Pour les n-grammes, il est facile de trouver de nombreuses applications intéressantes, par exemple, elles peuvent être utilisées pour une recherche floue dans le texte , mais comme nous ne sommes que des touristes, nous nous en sortirons avec des exemples de jouets, à savoir la génération de texte à l'aide de chaînes de Markov
Procházení modelového grafu
Une chaîne de Markov est un modèle discret d'un processus de Markov consistant en un changement dans un système qui ne prend en compte que son (modèle) état précédent. Au sens figuré, on peut percevoir cette construction comme un automate cellulaire probabiliste. Les N-grammes coexistent assez bien avec ce concept: tout mot du lexique est associé à chaque autre connexion d'épaisseurs différentes, qui est déterminée par la fréquence d'occurrence de paires de mots spécifiques (grammes) dans le texte.

Chaîne de Markov pour chaîne "ABABD"
La mise en œuvre de l'algorithme lui-même est déjà une excellente activité pour la soirée, mais Julia a déjà un merveilleux package Markovify , qui a été créé juste à ces fins. En parcourant soigneusement le manuel en tchèque , nous procédons à nos exécutions linguistiques.
Diviser le texte en jetons (par exemple, des mots)
using Markovify, Markovify.Tokenizer tokens = tokenize(str, on = words) 2-element Array{Array{String,1},1}: ["Ich", "mag", "die", "Sonne,", "die", "Palmen", "und", "das", "Meer,", "Ich", "mag", "den", "Himmel", "schauen,", "den", "Wolken", "hinterher."] ["Ich", "mag", "den", "kalten", "Mond,", "wenn", "der", "Vollmond", "rund,", "Und", "ich", "mag", "dich", "mit", "einem", "Knebel", "in", "dem", "Mund."]
Nous composons un modèle de premier ordre (seuls les voisins les plus proches sont pris en compte):
mdl = Model(tokens; order=1) Model{String}(1, Dict(["dich"] => Dict("mit" => 1),["den"] => Dict("Himmel" => 1,"kalten" => 1,"Wolken" => 1),["in"] => Dict("dem" => 1),["Palmen"] => Dict("und" => 1),["wenn"] => Dict("der" => 1),["rund,"] => Dict("Und" => 1),[:begin] => Dict("Ich" => 2),["Vollmond"] => Dict("rund," => 1),["die"] => Dict("Sonne," => 1,"Palmen" => 1),["kalten"] => Dict("Mond," => 1)…))
Ensuite, nous procédons à l'implémentation de la fonction de la phrase génératrice basée sur le modèle fourni. Il faut, en fait, un modèle, une solution de contournement et le nombre de phrases que vous souhaitez obtenir:
Code function gensentences(model, fun, n) sentences = []
Le développeur du package a fourni deux fonctions de contournement: walk et walk2 (la seconde fonctionne plus longtemps, mais donne des conceptions plus uniques), et vous pouvez toujours déterminer votre option. Essayons-le:
gensentences(mdl, walk, 4) 4-element Array{Any,1}: "Ich mag den Wolken hinterher." "Ich mag die Palmen und das Meer, Ich mag den Himmel schauen, den Wolken hinterher." "Ich mag den Wolken hinterher." "Ich mag die Palmen und das Meer, Ich mag dich mit einem Knebel in dem Mund." gensentences(mdl, walk2, 4) 4-element Array{Any,1}: "Ich mag den Wolken hinterher." "Ich mag dich mit einem Knebel in dem Mund." "Ich mag den Himmel schauen, den kalten Mond, wenn der Vollmond rund, Und ich mag den Wolken hinterher." "Ich mag die Sonne, die Palmen und das Meer, Ich mag dich mit einem Knebel in dem Mund."
Bien sûr, la tentation est grande d'essayer des textes russes, en particulier des vers blancs. Pour la langue russe, en raison de sa complexité, la plupart des phrases sont illisibles. De plus, comme déjà mentionné , les caractères spéciaux nécessitent un soin particulier, par conséquent, soit nous enregistrons les documents à partir desquels le texte encodé en UTF-8 est collecté, soit nous utilisons des outils supplémentaires .
Sur les conseils de sa sœur, après avoir nettoyé quelques livres d'Oster des caractères spéciaux et des séparateurs et avoir défini un deuxième ordre pour les n-grammes, j'ai obtenu l'ensemble suivant d'unités phraséologiques:
", !" ". , : !" ", , , , ?" " !" ". , !" ". , ?" " , !" " ?" " , , ?" " ?" ", . ?"
Elle a assuré que c'était par une telle technique que les pensées étaient construites dans le cerveau féminin ... ahem, et qui suis-je pour argumenter ...
Analysez-le
Dans le répertoire du package TextAnalysis, vous pouvez trouver des exemples de données textuelles, dont une collection de discours de présidents américains avant le congrès

Code using TextAnalysis, Clustering, Plots
29-element Array{String,1}: "Bush_1989.txt" "Bush_1990.txt" "Bush_1991.txt" "Bush_1992.txt" "Bush_2001.txt" "Bush_2002.txt" "Bush_2003.txt" "Bush_2004.txt" "Bush_2005.txt" "Bush_2006.txt" "Bush_2007.txt" "Bush_2008.txt" "Clinton_1993.txt" ⋮ "Clinton_1998.txt" "Clinton_1999.txt" "Clinton_2000.txt" "Obama_2009.txt" "Obama_2010.txt" "Obama_2011.txt" "Obama_2012.txt" "Obama_2013.txt" "Obama_2014.txt" "Obama_2015.txt" "Obama_2016.txt" "Trump_2017.txt"
Après avoir lu ces fichiers et en avoir formé un corps, ainsi que le nettoyage de la ponctuation, nous passerons en revue le vocabulaire général de tous les discours:
Code crps = DirectoryCorpus(pth) standardize!(crps, StringDocument) crps = Corpus(crps[1:29]);
remove_case!(crps) prepare!(crps, strip_punctuation) update_lexicon!(crps) update_inverse_index!(crps) lexicon(crps)
Dict{String,Int64} with 9078 entries: "enriching" => 1 "ferret" => 1 "offend" => 1 "enjoy" => 4 "limousines" => 1 "shouldn" => 21 "fight" => 85 "everywhere" => 17 "vigilance" => 4 "helping" => 62 "whose" => 22 "'" => 725 "manufacture" => 3 "sleepless" => 2 "favor" => 6 "incoherent" => 1 "parenting" => 2 "wrongful" => 1 "poised" => 3 "henry" => 3 "borders" => 30 "worship" => 3 "star" => 10 "strand" => 1 "rejoin" => 3 ⋮ => ⋮
Il peut être intéressant de voir quels documents contiennent des mots spécifiques, par exemple, regardez comment nous traitons les promesses:
crps["promise"]' 1×24 LinearAlgebra.Adjoint{Int64,Array{Int64,1}}: 1 2 3 4 6 7 9 10 11 12 15 … 21 22 23 24 25 26 27 28 29 crps["reached"]' 1×7 LinearAlgebra.Adjoint{Int64,Array{Int64,1}}: 12 14 15 17 19 20 22
ou avec des fréquences de pronom:
lexical_frequency(crps, "i"), lexical_frequency(crps, "you") (0.010942182388035081, 0.005905479339070189)
Alors probablement scientifiques et journalistes de viol et il existe une attitude perverse envers les données étudiées.
Matrices
La sémantique véritablement distributionnelle commence lorsque les textes, les grammes et les jetons se transforment en vecteurs et matrices .
Un terme document matrice ( DTM ) est une matrice qui a une taille où - le nombre de documents dans l'affaire, et - Taille du dictionnaire de corpus, c'est-à-dire le nombre de mots (uniques) que l'on retrouve dans notre corpus. Dans la i- ème ligne, la j-ème colonne de la matrice est un nombre - combien de fois dans le i- ème texte le j-ème mot a été trouvé.
Code dtm1 = DocumentTermMatrix(crps)
D = dtm(dtm1, :dense) 29×9078 Array{Int64,2}: 0 0 1 4 0 0 0 0 0 0 0 0 0 … 1 0 0 16 0 0 0 0 0 0 0 1 4 0 0 0 0 0 0 0 0 0 1 0 0 4 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 3 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 6 5 8 0 0 0 0 0 0 0 0 0 0 0 0 10 38 0 0 0 0 0 3 0 0 0 0 0 0 0 0 5 0 … 0 0 0 22 0 0 0 0 0 0 0 12 4 2 0 0 0 0 0 1 3 0 0 0 0 41 0 0 0 0 0 0 0 1 1 2 1 0 0 0 0 0 5 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 1 0 0 0 0 44 0 0 0 0 0 0 0 2 1 1 0 0 0 0 0 0 2 0 0 0 67 0 0 14 1 1 31 2 0 8 2 1 1 0 0 0 0 0 4 0 … 0 0 0 50 0 0 0 0 0 2 0 3 3 0 2 0 0 0 0 0 2 1 0 0 0 11 0 0 0 0 0 0 0 8 3 6 3 0 0 0 0 0 0 0 1 0 0 4 0 0 0 0 0 ⋮ ⋮ ⋮ ⋱ ⋮ ⋮ 0 1 11 5 3 3 0 0 0 1 0 1 0 1 0 0 44 0 0 0 0 0 0 0 11 5 4 5 0 0 0 0 0 1 0 1 0 0 48 0 0 0 0 0 0 0 18 6 8 4 0 0 0 0 0 0 1 1 0 0 80 0 0 0 0 0 0 0 1 2 0 0 0 0 0 0 0 0 0 … 0 0 0 26 0 0 0 0 0 1 0 4 5 5 1 0 0 0 0 0 1 0 0 0 45 0 0 0 0 0 1 1 0 8 2 1 3 0 0 0 0 0 2 0 0 0 47 0 0 170 11 11 1 0 0 7 1 1 1 0 0 0 0 0 0 0 0 0 3 2 0 208 2 2 0 1 0 5 2 0 1 1 0 0 0 0 1 0 0 0 41 0 0 122 7 7 1 0 0 4 3 4 1 0 0 0 0 0 0 0 … 0 0 62 0 0 173 11 11 7 2 0 6 0 0 0 0 0 0 0 0 3 0 0 0 0 0 0 0 0 0 0 0 0 3 0 3 0 0 0 0 0 0 0 0 0 0 0 35 0 0 0 0 0 1 0 2 2 0 2 0 0 0 0 0 1 0 0 0 0 30 0 0 0 0 0
Ici, les unités d'origine sont des termes
m.terms[3450:3465] 16-element Array{String,1}: "franklin" "frankly" "frankness" "fraud" "frayed" "fraying" "fre" "freak" "freddie" "free" "freed" "freedom" "freedoms" "freely" "freer" "frees"
Attends un instant ...
crps["freak"] 1-element Array{Int64,1}: 25 files[25] "Obama_2013.txt"
Il faudra lire plus en détail ...
Vous pouvez également extraire toutes sortes de données intéressantes des termes matrices. Dire la fréquence d'apparition de mots spécifiques dans les documents
w1, w2 = dtm1.column_indices["freedom"], dtm1.column_indices["terror"] (3452, 8101)
D[:, w1] |> bar
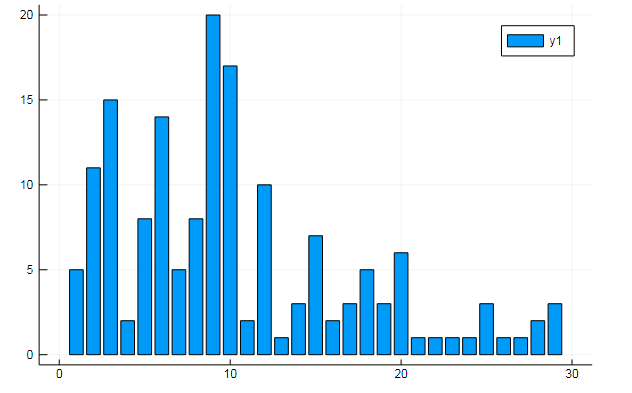
D[:, w1] |> bar
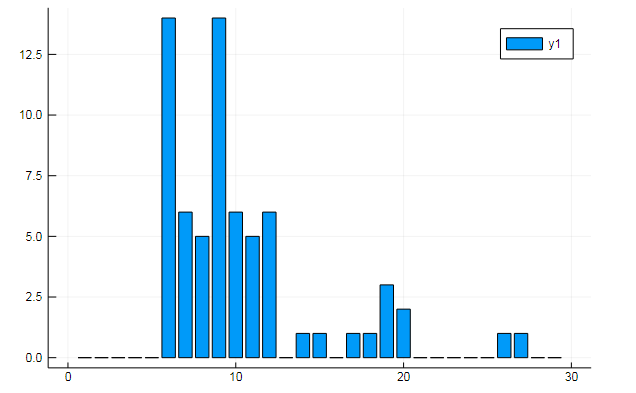
ou similitude de documents sur certains sujets cachés:
k = 3

Les graphiques montrent comment chacun des trois sujets est divulgué dans les discours
ou regrouper les mots par sujet, ou, par exemple, la similitude du vocabulaire et la préférence de certains sujets dans différents documents
T = tf_idf(D) cl = kmeans(T, 5)
s1 = scatter(T[10, 1:10:end], assign, yaxis = "Bush 2006") s2 = scatter(T[29, 1:10:end], assign, yaxis = "Obama 2016") s3 = scatter(T[30, 1:10:end], assign, yaxis = "Trump 2017") plot(s1, s2, s3, layout = (3,1), legend=false )
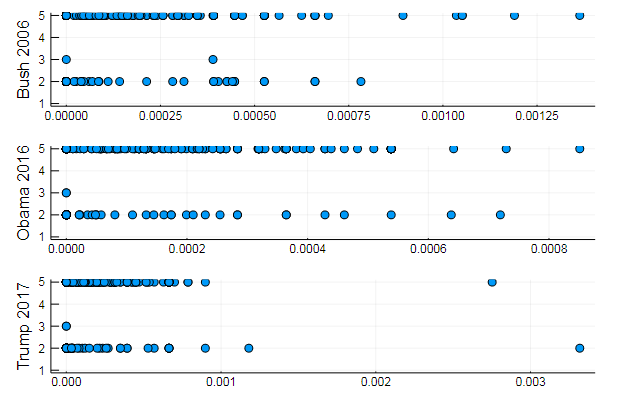
Des résultats tout à fait naturels, des performances du même type. En fait, la PNL est une science assez intéressante, et vous pouvez extraire beaucoup d'informations utiles à partir de données correctement préparées: vous pouvez trouver de nombreux exemples sur cette ressource ( Reconnaissance de l'auteur dans les commentaires , application de LDA , etc.)
Eh bien, pour ne pas aller loin, nous allons générer des phrases pour le président idéal:
Code function loadfiles(filenames) return ( open(filename) do file text = read(file, String)
7-element Array{Any,1}: "I want harmony and fathers, sons and we mark the jobkilling TransPacific Partnership." "I am asking all across our partners must be one very happy, indeed." "At the health insurance and terrorismrelated offenses since my Inauguration, and the future and pay their jobs, their community." "Millions lifted from this Nation, and Jessica Davis." "It will expand choice, increase access, lower the Director of our aspirations, not working." "We will defend our freedom." "The challenges we will celebrate the audience tonight, has come for a record."
Mémoire à court terme
Eh bien, comment cela peut-il être sans réseaux de neurones! Ils ramassent des lauriers dans ce domaine avec une vitesse croissante, et l'environnement de la langue Julia y contribue de toutes les manières. Pour les curieux, vous pouvez conseiller le package Knet , qui, contrairement au Flux que nous avons examiné précédemment , ne fonctionne pas avec les architectures de réseaux neuronaux en tant que constructeur de modules, mais fonctionne pour la plupart avec des itérateurs et des flux. Cela peut être d'un intérêt académique et contribuer à une compréhension plus profonde du processus d'apprentissage, et donne également un calcul haute performance. En cliquant sur le lien fourni ci-dessus, vous trouverez des conseils, des exemples et du matériel pour l'auto-apprentissage (par exemple, il montre comment créer un générateur de texte shakespearien ou un code juliac sur des réseaux récurrents). Cependant, certaines fonctions du package Knet sont implémentées uniquement pour le GPU, donc pour l'instant, continuons à tourner autour de Flux.
Un des exemples typiques du fonctionnement des réseaux de récurrence est souvent le modèle selon lequel les sonnets de Shakespeare sont alimentés symboliquement:
QUEN: Chiet? The buswievest by his seld me not report. Good eurronish too in me will lide upon the name; Nor pain eat, comes, like my nature is night. GRUMIO: What for the Patrople: While Antony ere the madable sut killing! I think, bull call. I have what is that from the mock of France: Then, let me? CAMILLE: Who! we break be what you known, shade well? PRINCE HOTHEM: If I kiss my go reas, if he will leave; which my king myself. BENEDICH: The aunest hathing rouman can as? Come, my arms and haste. This weal the humens? Come sifen, shall as some best smine? You would hain to all make on, That that herself: whom will you come, lords and lafe to overwark the could king to me, My shall it foul thou art not from her. A time he must seep ablies in the genely sunsition. BEATIAR: When hitherdin: so like it be vannen-brother; straight Edwolk, Wholimus'd you ainly. DUVERT: And do, still ene holy break the what, govy. Servant: I fearesed, Anto joy? Is it do this sweet lord Caesar: The dece
Si vous plissez les yeux et ne connaissez pas l'anglais, le jeu semble bien réel .

C'est plus facile à comprendre en russe
Mais il est beaucoup plus intéressant d'essayer les grands et les puissants, et bien que ce soit très difficile lexicalement, vous pouvez utiliser la littérature plus primitive comme données, à savoir, plus récemment connue comme le courant d'avant-garde de la poésie moderne - les rimes-tartes.
Collecte de données
Tartes et poudres - quatrains rythmiques, souvent sans rime, tapés en minuscules et sans signes de ponctuation.
Le choix s'est porté sur le site poetory.ru sur lequel l'administrateur camarade hior . Le long manque de réponse à la demande de données a été la raison pour commencer à analyser le site d'analyse. Un rapide coup d'œil au didacticiel HTML vous donne une compréhension rudimentaire de la conception des pages Web. Ensuite, nous trouvons les moyens de la langue Julia pour travailler dans ces domaines:

Ensuite, nous implémentons un script qui transforme les pages de la poésie et enregistre les tartes dans un document texte:
Code using HTTP, Gumbo, Cascadia function grabit(npages) str = "" for i = 1:npages url = "https://poetory.ru/por/rating/$i"
Plus en détail, il est démonté dans un cahier Jupiter . Collectons les tartes et la poudre à canon en une seule ligne:
str = read("pies.txt", String) * read("poroh.txt", String); length(str)
Et regardez l'alphabet utilisé:
prod(sort([unique(str)..., '_']) )

Vérifiez les données téléchargées avant de démarrer le processus.
Ay-ah-ah, quelle honte! Certains utilisateurs enfreignent les règles (parfois les gens s'expriment simplement en faisant du bruit dans ces données). Nous allons donc nettoyer notre cas de symbole des ordures
str = lowercase(str)
Comme conseillé par rssdev10, le code est modifié à l'aide d' expressions régulières
Vous avez un jeu de caractères plus acceptable. La plus grande révélation d'aujourd'hui est que, du point de vue du code machine, il y a au moins trois espaces différents - il est difficile pour les chasseurs de données de vivre.

Vous pouvez maintenant connecter Flux à la présentation ultérieure des données sous forme de vecteurs onehot:
Flux entre en jeu using Flux using Flux: onehot, chunk, batchseq, throttle, crossentropy using StatsBase: wsample using Base.Iterators: partition texta = collect(str) println(length(texta))
Nous avons défini le modèle à partir de quelques couches LSTM, d'un perceptron et d'un softmax entièrement connectés, ainsi que de petites choses de tous les jours, et pour la fonction de perte et l'optimiseur:
Code m = Chain( LSTM(N, 256), LSTM(256, 128), Dense(128, N), softmax)
Le modèle est prêt pour la formation, donc en exécutant la ligne ci-dessous, vous pouvez vaquer à vos occupations, dont le coût est sélectionné en fonction de la puissance de votre ordinateur. Dans mon cas, ce sont deux conférences de philosophie qui, pour une putain de chose, nous ont été livrées tard le soir ...
@time Flux.train!(loss, params(m), zip(Xs, Ys), opt, cb = throttle(evalcb, 30))
Après avoir assemblé un générateur d'échantillons, vous pouvez commencer à récolter les fruits de vos travaux.
générateur barmaglot function sample(m, alphabet, len)
Légère déception due à des attentes un peu élevées. Bien que le réseau n'ait qu'une séquence de caractères à l'entrée et ne puisse fonctionner qu'avec les fréquences de leur réunion les unes après les autres, il a complètement saisi la structure de l'ensemble de données, a distingué un semblant de mots et, dans certains cas, a même montré la capacité de maintenir le rythme. Peut-être, l' identification de l'affinité sémantique contribuera à l'amélioration.

Les poids d'un réseau formé peuvent être enregistrés sur le disque, puis lus facilement
weights = Tracker.data.(params(model)); using BSON: @save
Avec la prose aussi, seule la cyber psychédélie abstraite sort. Il y a eu des tentatives pour améliorer la qualité de la largeur et de la profondeur du réseau, ainsi que la diversité et l'abondance des données. Pour le corps de texte donné, merci au plus grand vulgarisateur de la langue russe

! . ? , , , , , , , , . , , , , . , . ? , , , , , ,
Mais si vous entraînez un réseau de neurones sur le code source du langage Julia, cela se révèle plutôt cool:
Ajouté à cela la possibilité de métaprogrammation , nous obtenons un programme qui écrit et s'exécute, peut-être même notre propre code! Eh bien, ou ce sera une aubaine pour les concepteurs de films sur les pirates .
En général, le début a été fait, puis déjà comme l'indique le fantasme. Tout d'abord, vous devez vous procurer un équipement de haute qualité afin que de longs calculs ne répriment pas le désir d'expérimenter. Deuxièmement, nous devons approfondir les méthodes et l'heuristique, ce qui nous permettra de concevoir des modèles meilleurs et plus optimisés. Sur cette ressource, il suffit de trouver tout ce qui concerne le traitement du langage naturel, après quoi il est tout à fait possible d'enseigner à votre réseau de neurones comment générer de la poésie ou aller à un hackathon pour l'analyse de texte .
Sur ce point, permettez-moi de prendre congé. Données pour l'entraînement dans le cloud , listes sur le github , feu dans les yeux, un œuf dans un canard, et bonne nuit à tous!