X5 gère 43 centres de distribution et 4 029 propres camions, ils fournissent un approvisionnement ininterrompu de produits dans 15 752 magasins. Dans l'article, je partagerai l'expérience de la création à partir de zéro d'un système interactif pour surveiller les événements de l'entrepôt. Les informations seront utiles à la logistique des sociétés commerciales avec des dizaines de centres de distribution gérant une large gamme de produits.

En règle générale, la construction de systèmes de surveillance et de gestion des processus métier commence par le traitement des messages et des incidents. Dans le même temps, un moment technologique important est manqué, lié à la possibilité d'automatiser le fait même de la survenance d'événements commerciaux et d'enregistrer des incidents. La plupart des systèmes d'entreprise de la classe WMS, TMS, etc., ont des outils intégrés pour surveiller leurs propres processus. Mais, s'il s'agit d'un système de différents fabricants ou si la fonctionnalité de surveillance n'est pas suffisamment développée, vous devez commander des améliorations coûteuses ou faire appel à des consultants spécialisés pour des paramètres supplémentaires.
Considérons une approche dans laquelle nous n'avons besoin que d'une petite partie de la consultation liée à la détermination des sources (tableaux) pour obtenir des indicateurs du système.
La spécificité de nos entrepôts réside dans le fait que plusieurs systèmes de gestion d'entrepôt (WMS Exceed) opèrent sur le même complexe logistique. Les entrepôts sont répartis en fonction des catégories de stockage des marchandises (sec, alcool, congélation, etc.) non seulement de manière logique. Au sein d'un même complexe logistique se trouvent plusieurs bâtiments d'entrepôt distincts, les opérations sur chacun d'entre eux sont gérées par leur propre WMS.

Pour se faire une idée générale des processus se déroulant dans l'entrepôt, les responsables analysent les rapports de chaque WMS plusieurs fois par jour, traitent les messages des exploitants de l'entrepôt (récepteurs, cueilleurs, gerbeurs) et résument les indicateurs de fonctionnement réels à afficher sur le panneau d'information.
Pour gagner du temps aux managers, nous avons décidé de développer un système peu coûteux de contrôle opérationnel des événements de l'entrepôt. Le nouveau système, en plus d'afficher des indicateurs «à chaud» du travail opérationnel des processus de l'entrepôt, devrait également aider les gestionnaires à corriger les incidents et à surveiller les tâches pour éliminer les causes qui affectent les indicateurs donnés. Après avoir effectué un audit général de l'architecture informatique de l'entreprise, nous avons réalisé que les différentes parties du système requis existent déjà d'une manière ou d'une autre dans notre paysage et pour elles, il y a à la fois un examen des paramètres et des services de support nécessaires. Il ne reste plus qu'à réduire l'ensemble du concept en une seule solution architecturale et à évaluer la portée du développement.
Après avoir évalué la quantité de travail qui doit être fait pour construire un nouveau système, il a été décidé de diviser le projet en plusieurs étapes:
- Collecte d'indicateurs sur les processus de stockage, visualisation et contrôle des indicateurs et écarts
- Automatisation des normes de processus et enregistrement des applications dans le service des services aux entreprises pour les écarts
- Suivi proactif avec prévision de charge et recommandations aux managers.
À la première étape, le système devrait recueillir des tranches préparées de données opérationnelles de tous les complexes WMS. La lecture a lieu presque en temps réel (intervalles inférieurs à 5 minutes). L'astuce est que les données doivent être obtenues à partir du SGBD de plusieurs dizaines d'entrepôts lors du déploiement du système sur l'ensemble du réseau. Les données opérationnelles reçues sont traitées par la logique centrale du système pour calculer les écarts par rapport aux indicateurs prévus et calculer les statistiques. Les données ainsi traitées doivent être affichées sur la tablette du responsable ou sur le panneau d'information de l'entrepôt sous forme de graphiques et de diagrammes clairs.

Lors du choix d'un système approprié pour la mise en œuvre pilote de la première étape, nous avons opté pour Zabbix. Ce système est déjà utilisé pour surveiller les performances informatiques des systèmes d'entrepôt. En ajoutant une installation distincte pour la collecte des mesures commerciales pour les opérations de l'entrepôt, vous pouvez obtenir une image globale de l'intégrité de l'entrepôt.
L'architecture générale du système est illustrée sur la figure.
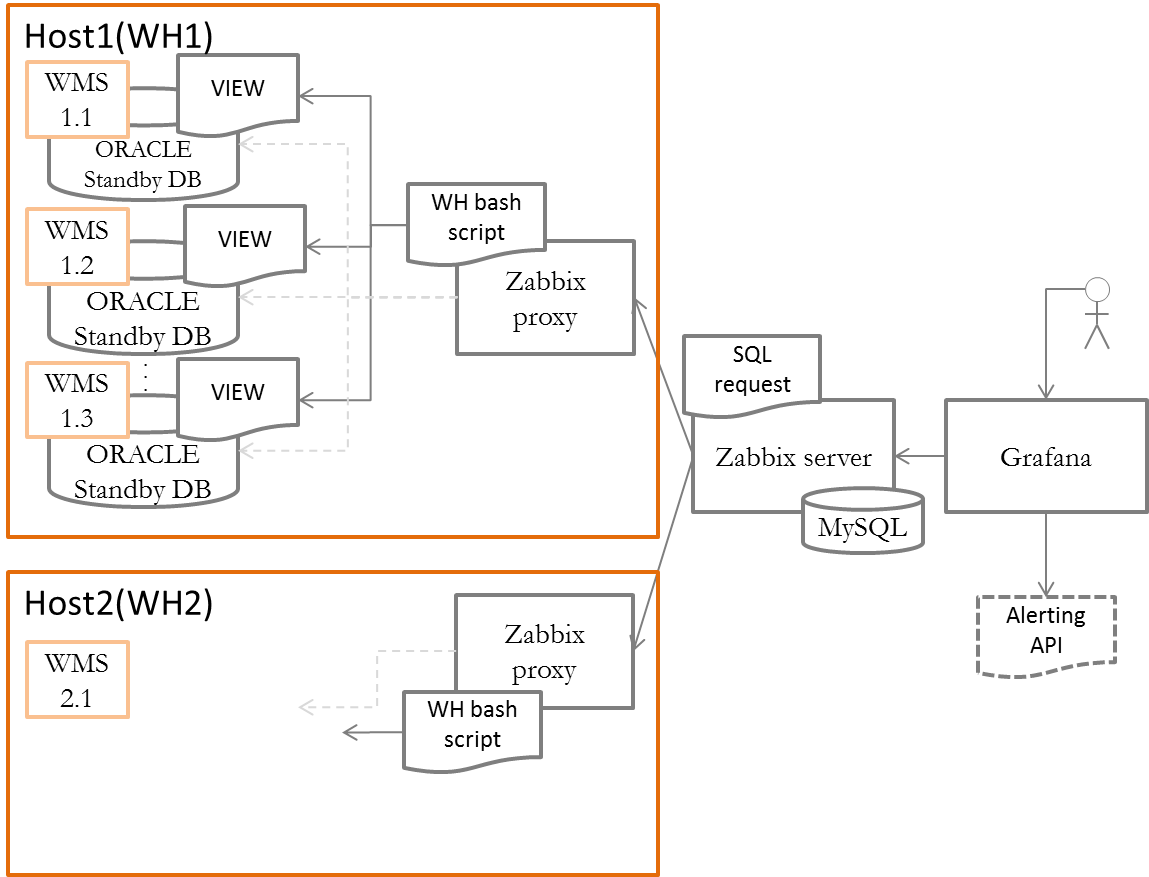
Chaque instance WMS est définie comme un hôte pour le système de surveillance. Les métriques sont collectées par un serveur central dans le réseau du centre de données en exécutant un script avec une requête SQL préparée. Si vous devez surveiller un système qui ne recommande pas un accès direct à la base de données (par exemple, SAP EWM), vous pouvez utiliser des appels de script à des fonctions API documentées pour écrire des indicateurs ou écrire un simple programme python / vbascript.
Le proxy Zabbix est déployé sur le réseau d'entrepôt pour répartir la charge à partir du serveur principal. Grâce au proxy, le travail avec toutes les instances WMS locales est fourni. À la prochaine demande de paramètres par le serveur Zabbix sur l'hôte avec proxy Zabbix, un script est exécuté pour demander des métriques à la base de données WMS.
Pour afficher les graphiques et les indicateurs de l'entrepôt sur le serveur central Zabbix, déployez Grafana. En plus de produire des tableaux de bord préparés avec des infographies d'entrepôt, Grafana sera utilisé pour contrôler les écarts d'indicateurs et transférer des alertes automatiques au système de service d'entrepôt pour traiter les incidents commerciaux.
A titre d'exemple, considérons la mise en œuvre du contrôle du chargement de la zone d'acceptation de l'entrepôt. Comme principaux indicateurs des processus dans cette section de l'entrepôt sélectionnés:
- le nombre de véhicules dans la zone d'accueil, en tenant compte des statuts (prévu, arrivé, documents, déchargement, départ;
- congestion des zones de placement et de réapprovisionnement (selon les conditions de stockage).
Paramètres
L'installation et la configuration des principaux composants du système (SQLcl, Zabbix, Grafana) sont décrites dans différentes sources et nous ne répéterons pas ici. L'utilisation de SQLcl au lieu de SQLplus est due au fait que SQLcl (l'interface de ligne de commande Oracle DBMS écrite en java) ne nécessite pas d'installation supplémentaire d'Oracle Client et fonctionne par défaut.
Je décrirai les principaux points auxquels il convient de prêter attention lors de l'utilisation de Zabbix pour surveiller les performances des processus commerciaux de l'entrepôt, et l'un des moyens possibles de les mettre en œuvre. En outre, ce message n'est pas sur la sécurité. La sécurité des connexions et l'utilisation des méthodes présentées nécessitent une étude supplémentaire dans le processus de transfert de la solution pilote en fonctionnement productif.
L'essentiel est que lors de la mise en œuvre d'un tel système, il soit possible de se passer de programmation, en utilisant les paramètres fournis par le système.
Le système de surveillance Zabbix offre plusieurs options pour collecter des métriques à partir d'un système surveillé. Cela peut être fait à la fois par interrogation directe des hôtes contrôlés et par une méthode plus avancée d'envoi de données au serveur via le zabbix_sender de l'hôte, y compris des méthodes pour définir des paramètres de découverte de bas niveau. Pour résoudre notre problème, la méthode d'interrogation directe des hôtes par un serveur central est tout à fait appropriée. cela vous permet d'avoir un contrôle total sur la séquence d'obtention des métriques et garantit l'utilisation d'un package de paramètres / scripts sans avoir à les distribuer à chaque hôte contrôlé.
Comme «expérimental» pour le débogage et le réglage du système, nous utilisons les feuilles de calcul WMS pour contrôler la réception:
- TS à l'acceptation, tout ce qui est arrivé: Tous les TS avec des statuts pour la période "- 72 heures à partir de l'heure actuelle" - Identificateur de requête SQL: getCars .
- Historique de tous les statuts des véhicules: Statuts de tous les véhicules avec 72 heures d'arrivée - Identificateur de requête SQL: carsHistory .
- Véhicules planifiés pour acceptation: Le statut de tous les véhicules avec le statut "Planifié", l'intervalle de temps est "24 heures" et "+24 heures" à partir de l'heure actuelle - Identificateur de requête SQL: carsIn .
Ainsi, après avoir décidé d'un ensemble de métriques d'entrepôt, nous préparerons des requêtes SQL pour la base de données WMS. Pour exécuter des requêtes, il est conseillé d'utiliser non pas la base de données principale, mais sa copie «à chaud» - veille.
Nous sommes connectés à Oracle DBMS de secours pour l'acquisition de données. Adresse IP pour la connexion à la base de test
192.168.1.106 . Les paramètres de connexion sont enregistrés sur le serveur Zabbix dans TNSNames.ORA du dossier SQLcl de travail:
# cat /opt/sqlcl/bin/TNSNames.ORA WH1_1= (DESCRIPTION = (ADDRESS = (PROTOCOL = TCP)(HOST = 192.168.1.106)(PORT = 1521)) (CONNECT_DATA = (SERVER = DEDICATED) (SERVICE_NAME = WH1_1) ) )
Cela nous permettra d'exécuter des requêtes SQL sur chaque hôte via EZconnect, en spécifiant uniquement le nom d'utilisateur / mot de passe et le nom de la base de données:
# sql znew/Zabmon1@WH1_1
Les requêtes SQL préparées sont enregistrées dans le dossier de travail sur le serveur Zabbix:
/etc/zabbix/sql
et autoriser l'accès à l'utilisateur zabbix de notre serveur:
# chown zabbix:zabbix -R /etc/zabbix/sql
Les fichiers de demande reçoivent un nom d'identification unique pour l'accès du serveur Zabbix. Chaque requête de base de données via SQLcl nous renvoie plusieurs paramètres. Étant donné les spécificités de Zabbix, qui ne peut traiter qu'une seule métrique dans une requête, nous utiliserons des scripts supplémentaires pour analyser les résultats de la requête en métriques individuelles.
Nous préparons le script principal, appelons-le wh_Metrics.sh, pour appeler la requête SQL dans la base de données, enregistrer les résultats et renvoyer la métrique technique avec des indicateurs de réussite des données:
#!/bin/sh ## </i> export ORACLE_HOME=/usr/lib/oracle/11.2/client64 export PATH=$PATH:$ORACLE_HOME/bin export LD_LIBRARY_PATH=$ORACLE_HOME/lib:/usr/lib64:/usr/lib:$ORACLE_HOME/bin export TNS_ADMIN=$ORACLE_HOME/network/admin export JAVA_HOME=/ alias sql="opt/sqlcl/bin/sql" ## sql- scriptLocation=/etc/zabbix/sql sqlFile=$scriptLocation/sqlScript_"$2".sql ## resultFile=/etc/zabbix/sql/mon_"$1"_main.log ## username="$3" password="$4" tnsname="$1" ## var=$(sql -s $username/$password@$tnsname < $sqlFile) ## echo $var | cut -f5-18 -d " " > $resultFile ## if grep -q ora "$resultFile"; then echo null > $resultFile echo 0 else echo 1 fi
Nous plaçons le fichier fini avec le script dans le dossier pour l'hébergement des scripts externes conformément aux paramètres de configuration du proxy Zabbix (par défaut -
/ usr / local / share / zabbix / externalscripts ).
L'identification de la base de données à partir de laquelle le script recevra les résultats sera transmise par le paramètre de script. L'identifiant de la base de données doit correspondre à la ligne de paramètres du fichier TNSNames.ORA.
Le résultat de l'appel de la requête SQL est enregistré dans un fichier de la forme
mon_base_id_main.log, où base_id = identifiant DB obtenu comme paramètre de script. La séparation du fichier de résultats par des identifiants de base de données est prévue en cas de requêtes du serveur simultanément vers plusieurs bases de données. La requête renvoie un tableau de valeurs bidimensionnel trié.
Le script suivant, appelons-le getMetrica.sh, est nécessaire pour obtenir la métrique spécifiée du fichier avec le résultat de la demande:
#!/bin/sh ## resultFile=/etc/zabbix/sql/mon_”$1”_main.log ## : ## , (RSLT) ## {1 1 2 2…} ( IFS) ## IFS=' ' str=$(cat $resultFile) status_id=null read –ra RSLT <<< “$str” for i in “${RSLT[@]}”; do if [[ “$status_id” == null ]]; then status_id=”$I" elif [[ “$status_id” == “$2” ]]; then echo “$i” break else status_id=null fi done
Nous sommes maintenant prêts à configurer Zabbix et à commencer à surveiller les performances des processus d'acceptation d'entrepôt.
Sur chaque nœud de base de données, un agent Zabbix est installé et configuré.
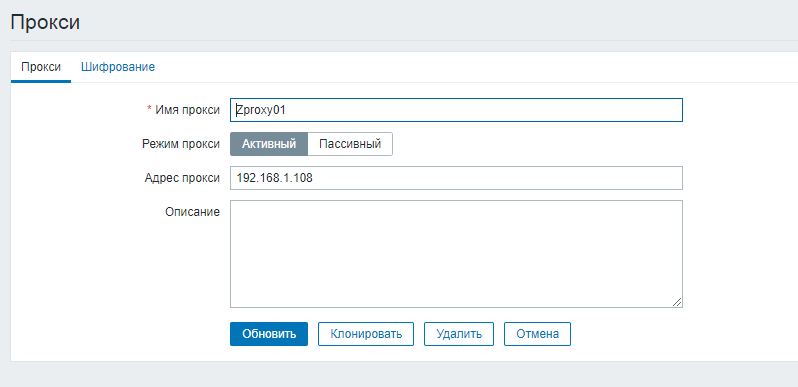
Sur le serveur principal, nous définissons tous les serveurs avec des proxys Zabbix. Pour les paramètres, accédez au chemin suivant:
Administration → Proxy → Créer un proxy
Définissez les hôtes contrôlés:
Paramètres → Hôtes → Créer un hôte
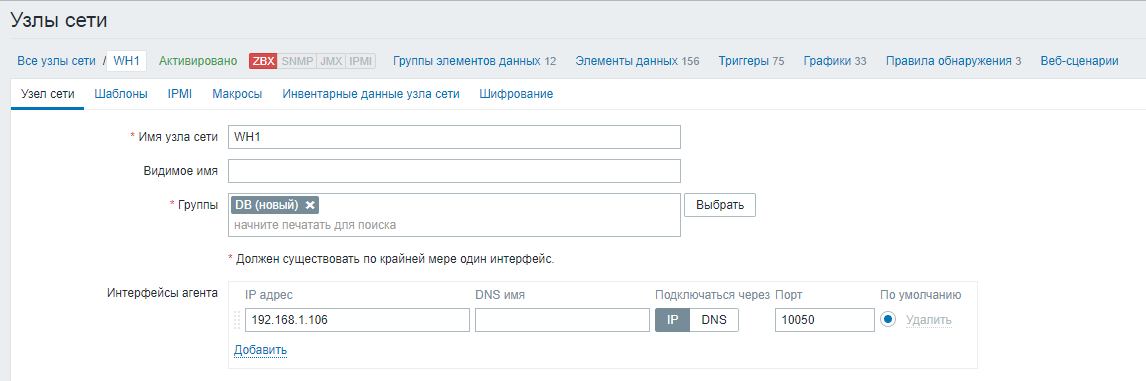
Le nom d'hôte doit correspondre au nom d'hôte spécifié dans le fichier de configuration de l'agent.
Nous indiquons le groupe pour le nœud, ainsi que l'adresse IP ou le nom DNS du nœud de la base de données.
Nous créons des métriques et spécifions leurs propriétés:
Paramètres → Noeuds →
'nom du noeud' → Éléments de données> Créer un élément de données
1) Créez une métrique de base pour interroger tous les paramètres de la base de données
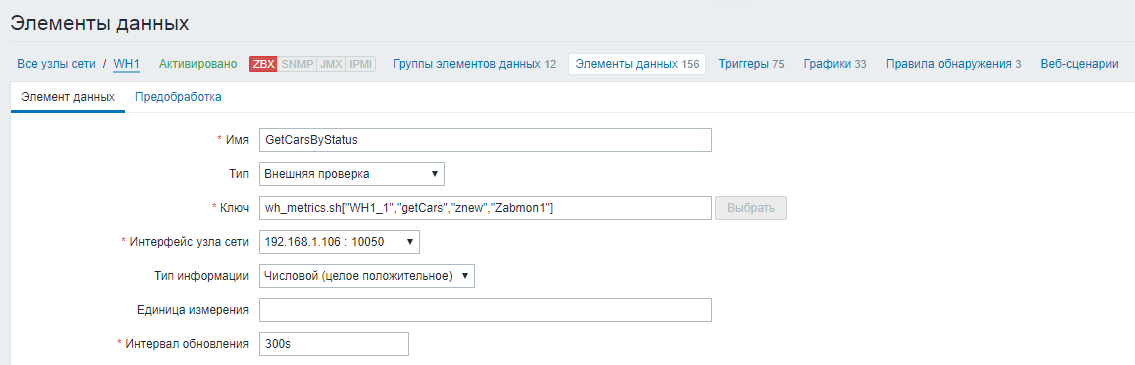
Nous définissons le nom de l'élément de données, indiquons le type de «Vérification externe». Dans le champ «Clé», nous définissons un script auquel nous transférons le nom de la base de données Oracle, le nom de la requête sql, le login et le mot de passe pour se connecter à la base de données en tant que paramètres. Définissez l'intervalle de mise à jour de la demande sur 5 minutes (300 secondes).
2) Créez les métriques restantes pour chaque état du véhicule. Les valeurs de ces métriques seront formées en fonction du résultat de la vérification de la métrique principale.
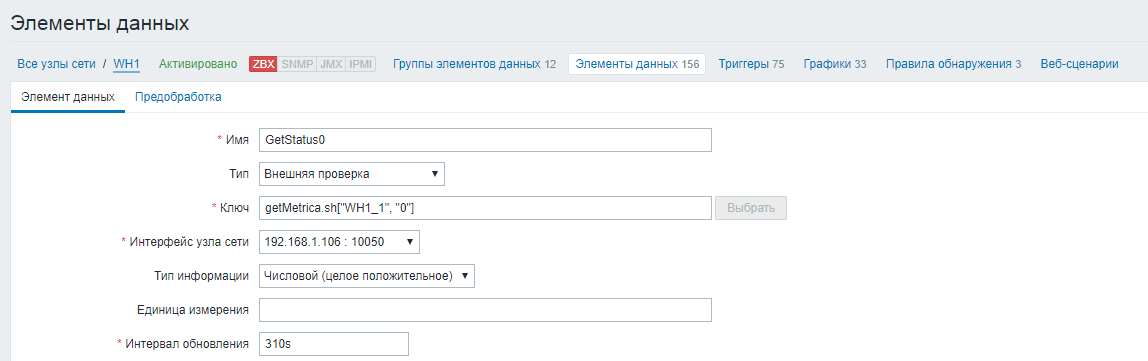
Nous définissons le nom de l'élément de données, indiquons le type de «Vérification externe». Dans le champ «Clé», nous définissons un script auquel nous transférons le nom de la base de données Oracle et le code d'état, dont nous voulons suivre la valeur en tant que paramètres. Nous définissons l'intervalle de mise à jour de la demande 10 secondes de plus que la métrique principale (310 secondes) afin que les résultats puissent être écrits dans le fichier.
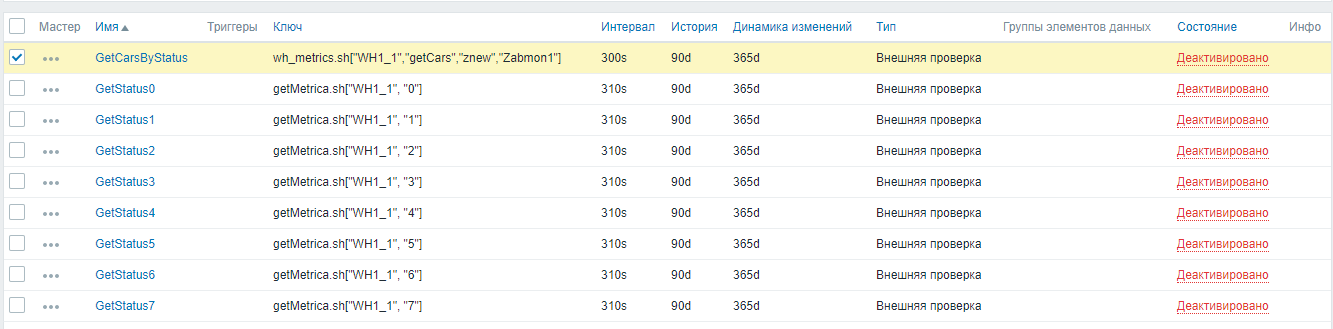
Pour obtenir correctement les métriques, l'ordre dans lequel les contrôles sont activés est important. Afin d'éviter les conflits lors de la réception de données, tout d'abord, activez la métrique principale GetCarsByStatus avec un appel de script - wh_Metrics.sh.
Paramètres → Noeuds → «nom de noeud» → Éléments de données → Sous-filtre «Vérifications externes». Nous marquons la coche nécessaire et cliquons sur «Activer».
Ensuite, activez les métriques restantes en une seule opération, en les sélectionnant toutes ensemble:
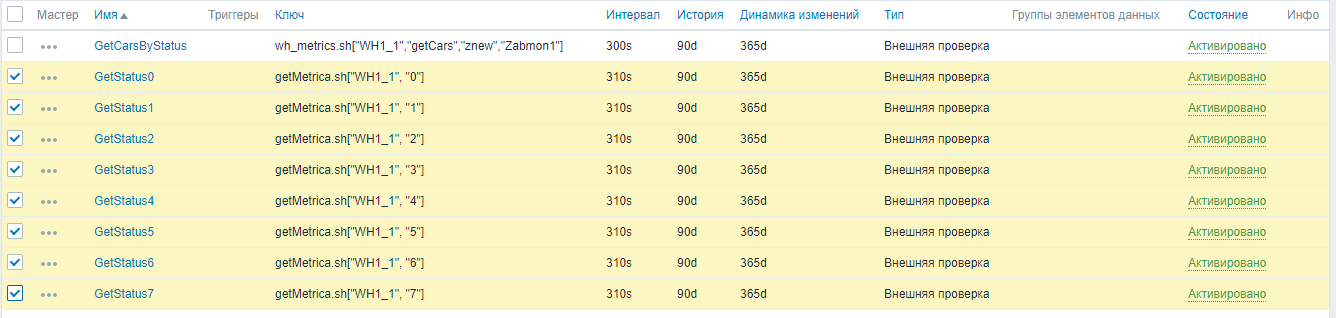
Zabbix a maintenant commencé à collecter des métriques commerciales d'entrepôt.
Dans les articles suivants, nous examinerons plus en détail la connexion de Grafana et la formation de tableaux de bord d'information pour les opérations d'entrepôt pour différentes catégories d'utilisateurs. Grafana surveille également les écarts dans l'entrepôt et, en fonction des limites et de la fréquence des écarts, enregistre les incidents dans le système du centre de service de gestion d'entrepôt via l'API ou envoie simplement des notifications au responsable par e-mail.
