Une étude récente,
«Utilisation et attribution d'extraits de code Stack Overflow dans les projets GitHub», a soudainement révélé que la plupart du temps dans les projets open source, ma
réponse a été écrite il y a près de dix ans. Ironiquement, il y a un bug.
Il était une fois ...
En 2010, j'étais assis dans mon bureau et je faisais des bêtises:
j'aimais le golf à code et j'ai
ajouté une note à Stack Overflow.
La question suivante a attiré mon attention: comment afficher le nombre d'octets dans un format lisible? Autrement dit, comment convertir quelque chose comme 123456789 octets en «123,5 Mo».
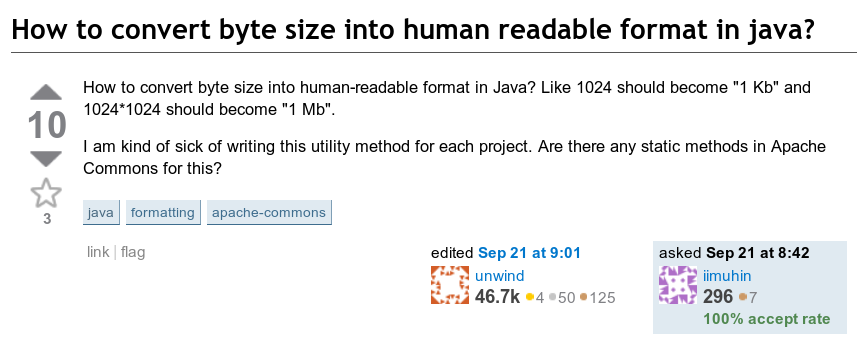 Bonne vieille interface 2010, merci The Wayback Machine
Bonne vieille interface 2010, merci The Wayback MachineImplicitement, le résultat serait un nombre compris entre 1 et 999,9 avec l'unité appropriée.
Il y avait déjà une réponse avec une boucle. L'idée est simple: vérifier tous les degrés de la plus grande unité (EB = 10
18 octets) à la plus petite (B = 1 octet) et appliquer le premier, qui est inférieur au nombre d'octets. En pseudo code, cela ressemble à ceci:
suffixes = [ "EB", "PB", "TB", "GB", "MB", "kB", "B" ] magnitudes = [ 10^18, 10^15, 10^12, 10^9, 10^6, 10^3, 10^0 ] i = 0 while (i < magnitudes.length && magnitudes[i] > byteCount) i++ printf("%.1f %s", byteCount / magnitudes[i], suffixes[i])
Habituellement, avec la bonne réponse avec une note positive, il est difficile de la rattraper. Dans le jargon Stack Overflow, cela s'appelle le
problème du tireur le plus rapide de l'Ouest . Mais ici, la réponse avait plusieurs défauts, alors j'espérais toujours la dépasser. Au moins le code avec une boucle peut être considérablement réduit.
Et bien c'est de l'algèbre, tout est simple!
Puis cela m'est apparu. Les préfixes sont kilo-, méga-, giga-, ... - rien de plus que des degrés 1000 (ou 1024 dans la norme CEI), donc le préfixe correct peut être déterminé en utilisant le logarithme, et non le cycle.
Sur la base de cette idée, j'ai publié ce qui suit:
public static String humanReadableByteCount(long bytes, boolean si) { int unit = si ? 1000 : 1024; if (bytes < unit) return bytes + " B"; int exp = (int) (Math.log(bytes) / Math.log(unit)); String pre = (si ? "kMGTPE" : "KMGTPE").charAt(exp-1) + (si ? "" : "i"); return String.format("%.1f %sB", bytes / Math.pow(unit, exp), pre); }
Bien sûr, ce n'est pas très lisible, et log / pow est inférieur en efficacité à d'autres options. Mais il n'y a pas de boucle et presque pas de branchement, donc le résultat est assez beau, à mon avis.
Les mathématiques sont simples . Le nombre d'octets est exprimé par byteCount = 1000 s , où s représente le degré (en notation binaire, la base est 1024.) La solution s donne s = log 1000 (byteCount).
Il n'y a pas de simple expression log 1000 dans l'API, mais nous pouvons l'exprimer en termes de logarithme naturel comme suit s = log (byteCount) / log (1000). Ensuite, nous convertissons s en int, donc si, par exemple, nous avons plus d'un mégaoctet (mais pas un gigaoctet complet), alors MB sera utilisé comme unité de mesure.
Il s'avère que si s = 1, alors la dimension est en kilo-octets, si s = 2 - mégaoctets et ainsi de suite. Divisez byteCount par 1000 s et giflez la lettre correspondante dans le préfixe.
Il ne restait plus qu'à attendre et à voir comment la communauté percevait la réponse. Je ne pouvais pas penser que ce morceau de code deviendrait le plus largement diffusé dans l'histoire de Stack Overflow.
Étude d'attribution
Avance rapide jusqu'en 2018. Sebastian Baltes, étudiant diplômé, publie un article dans la revue scientifique
Empirical Software Engineering intitulé
«Utilisation et attribution d'extraits de code de débordement de pile dans les projets GitHub» . Le sujet de sa recherche est de savoir dans quelle mesure la licence Stack Overflow CC BY-SA 3.0 est respectée, c'est-à-dire que les auteurs indiquent les liens Stack Overflow comme source de code.
Pour l'analyse, des extraits de code ont été extraits du
vidage de débordement de pile et mis en correspondance avec le code dans les référentiels publics GitHub. Citation du résumé:
Nous présentons les résultats d'une étude empirique à grande échelle analysant l'utilisation et l'attribution de fragments non triviaux de code Java à partir de réponses SO dans des projets publics GitHub (GH).
(Spoiler: non, la plupart des programmeurs ne respectent pas les exigences de licence).
L'article a un tel tableau:
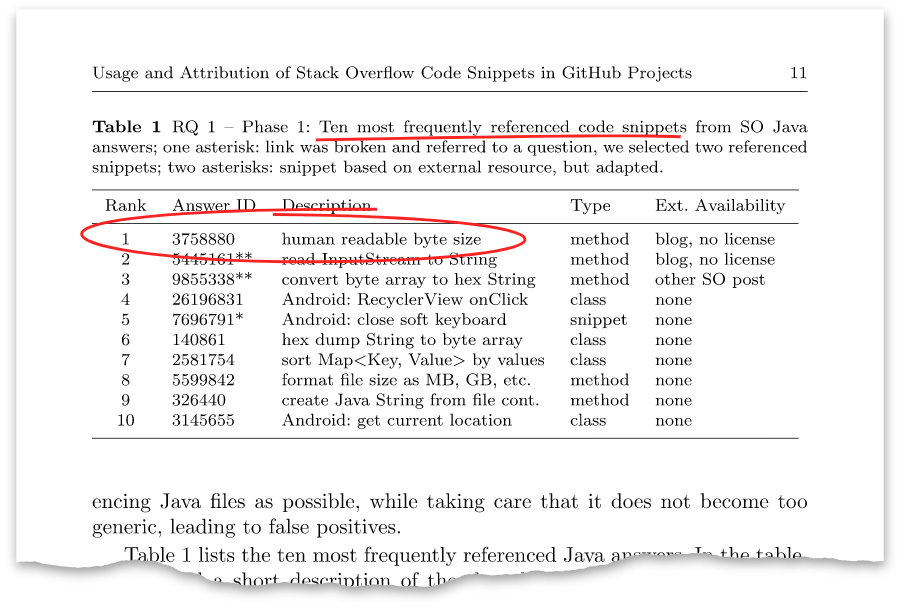
Cette réponse ci-dessus avec l'identifiant
3758880 s'est avérée être la réponse même que j'ai postée il y a huit ans. À l'heure actuelle, il a plus de cent mille vues et plus de mille avantages.
Une recherche rapide sur GitHub produit vraiment des milliers de référentiels avec le code
humanReadableByteCount .
Recherchez ce fragment dans votre référentiel:
$ git grep humanReadableByteCount
Une histoire drôle , comme j'ai découvert cette étude.
Sebastian a trouvé une correspondance dans le référentiel OpenJDK sans aucune attribution, et la licence OpenJDK n'est pas compatible avec CC BY-SA 3.0. Sur la liste de diffusion jdk9-dev, il a demandé: le code Stack Overflow est-il copié depuis OpenJDK ou vice versa?
Le plus drôle, c'est que je viens de travailler dans Oracle, dans le projet OpenJDK, donc mon ancien collègue et ami a écrit ce qui suit:
Salut
Pourquoi ne pas demander directement à l'auteur de ce post sur SO (aioobe)? Il est membre d'OpenJDK et a travaillé chez Oracle lorsque ce code est apparu dans les référentiels source d'OpenJDK.
Oracle prend ces problèmes très au sérieux. Je sais que certains managers ont été soulagés en lisant cette réponse et en trouvant le «coupable».
Puis Sebastian m'a écrit pour clarifier la situation, ce que j'ai fait: ce code a été ajouté avant de rejoindre Oracle et je n'ai rien à voir avec le commit. Il vaut mieux ne pas plaisanter avec Oracle. Quelques jours après l' ouverture du ticket, ce code a été supprimé .
Bug
Je parie que vous y avez déjà pensé. Quel genre d'erreur dans le code?
Encore une fois:
public static String humanReadableByteCount(long bytes, boolean si) { int unit = si ? 1000 : 1024; if (bytes < unit) return bytes + " B"; int exp = (int) (Math.log(bytes) / Math.log(unit)); String pre = (si ? "kMGTPE" : "KMGTPE").charAt(exp-1) + (si ? "" : "i"); return String.format("%.1f %sB", bytes / Math.pow(unit, exp), pre); }
Quelles sont les options?
Après les exaoctets (10
18 ) sont des zettaoctets (10
21 ). Peut-être qu'un très grand nombre ira au-delà de kMGTPE? Non. La valeur maximale est de 2
63 -1 ≈ 9,2 × 10
18 , donc aucune valeur ne dépassera jamais les exaoctets.
Peut-être la confusion entre les unités SI et le système binaire? Non. Il y avait de la confusion dans la première version de la réponse, mais elle a été corrigée assez rapidement.
Peut-être que exp finit par mettre à zéro, provoquant le blocage de charAt (exp-1)? Non non plus. La première instruction if couvre ce cas. La valeur exp sera toujours au moins 1.
Peut-être une étrange erreur d'arrondi dans l'extradition? Enfin, enfin ...
Beaucoup de neuf
La solution fonctionne jusqu'à ce qu'elle approche 1 Mo. Lorsque
"1000,0 kB" octets sont spécifiés en entrée, le résultat (en mode SI) est
"1000,0 kB" . Bien que 999,999 soit plus proche de 1000 × 1000
1 que de 999,9 × 1000
1 , le signifiant 1000 est interdit par la spécification. Le résultat correct est
"1.0 MB" .
Pour ma défense, je peux dire qu'au moment de la rédaction de ce document, une telle erreur figurait dans les 22 réponses publiées, y compris les bibliothèques Apache Commons et Android.
Comment y remédier? Tout d'abord, notez que l'exposant (exp) doit passer de «k» à «M» dès que le nombre d'octets est plus proche de 1 × 1000
2 (1 Mo) que de 999,9 × 1000
1 (999,9 k ) Cela se produit à 999 950. De même, nous devons passer de «M» à «G» lorsque nous passons par 999 950 000 et ainsi de suite.
Nous calculons ce seuil et
exp si les
bytes supérieurs:
if (bytes >= Math.pow(unit, exp) * (unit - 0.05)) exp++;
Avec ce changement, le code fonctionne bien jusqu'à ce que le nombre d'octets approche 1 EB.
Plus de neuf
Lors du calcul de 999 949 999 999 999 999 999, le code donne
1000.0 PB et le résultat correct est
999.9 PB . Mathématiquement, le code est précis, alors que se passe-t-il ici?
Nous sommes maintenant confrontés à une
double contrainte.
Introduction à l'arithmétique en virgule flottante
Selon la spécification IEEE 754, les valeurs en virgule flottante proches de zéro ont une représentation très dense, tandis que les grandes valeurs ont une représentation très clairsemée. En fait, la moitié de toutes les valeurs sont comprises entre -1 et 1, et lorsqu'il s'agit de grands nombres, une valeur de taille Long.MAX_VALUE ne signifie rien. Au sens littéral.
double l1 = Double.MAX_VALUE; double l2 = l1 - Long.MAX_VALUE; System.err.println(l1 == l2); // prints true
Voir "Bits à virgule flottante" pour plus de détails.
Le problème est représenté par deux calculs:
- Division en
String.format et
- Seuil d'expansion
exp
Nous pouvons passer à
BigDecimal , mais c'est ennuyeux. De plus, des problèmes se posent également ici, car l'API standard n'a pas de logarithme pour
BigDecimal .
Réduire les valeurs intermédiaires
Pour résoudre le premier problème, nous pouvons réduire la valeur des
bytes à la plage souhaitée, où la précision est meilleure, et ajuster
exp conséquence. Dans tous les cas, le résultat final est arrondi, donc peu importe que nous jetions les chiffres les moins significatifs.
if (exp > 4) { bytes /= unit; exp--; }
Réglage des bits les moins significatifs
Pour résoudre le deuxième problème
, les bits
les moins significatifs
sont importants pour nous (99994999 ... 9 et 99995000 ... 0 doivent avoir des degrés différents), nous devons donc trouver une solution différente.
Tout d'abord, notez qu'il existe 12 valeurs de seuil différentes (6 pour chaque mode) et qu'une seule d'entre elles entraîne une erreur. Un résultat incorrect peut être identifié de manière unique car il se termine par D00
16 . Vous pouvez donc le réparer directement.
long th = (long) (Math.pow(unit, exp) * (unit - 0.05)); if (exp < 6 && bytes >= th - ((th & 0xFFF) == 0xD00 ? 52 : 0)) exp++;
Étant donné que nous nous appuyons sur certains modèles de bits dans les résultats en virgule flottante, nous utilisons le modificateur strictfp pour garantir que le code fonctionne indépendamment du matériel.
Valeurs d'entrée négatives
Il n'est pas clair dans quelles circonstances un nombre négatif d'octets peut avoir un sens, mais comme Java n'a pas de
long non signé, il est préférable de gérer cette option. À l'heure actuelle, des entrées comme
-10000 B produisent
-10000 BabsBytes :
long absBytes = bytes == Long.MIN_VALUE ? Long.MAX_VALUE : Math.abs(bytes);
L'expression est tellement verbeuse car
-Long.MIN_VALUE == Long.MIN_VALUE . Maintenant, nous faisons tous les calculs
exp utilisant
absBytes au lieu d'
bytes .
Version finale
Voici la version finale du code, raccourcie et condensée dans l'esprit de la version originale:
Notez que cela a commencé comme une tentative d'éviter les boucles et les branchements excessifs. Mais après lissage de toutes les situations frontalières, le code est devenu encore moins lisible que la version originale. Personnellement, je ne copierais pas ce fragment en production.
Pour une version mise à jour de la qualité de production, consultez un article séparé:
«Formatage de la taille des octets dans un format lisible» .
Constatations clés
- Il peut y avoir des erreurs dans les réponses à Stack Overflow, même si elles contiennent des milliers d'avantages.
- Vérifiez tous les cas limites, en particulier dans le code avec Stack Overflow.
- L'arithmétique en virgule flottante est compliquée.
- Assurez-vous d'inclure l'attribution correcte lors de la copie du code. Quelqu'un peut vous emmener pour nettoyer l'eau.