Dans mon
article précédent, j'ai parlé de l'expérience d'utilisation du moteur
Gemini pour développer des tests visuels, ou plutôt des tests de régression visuelle. Ces tests vérifient si quelque chose a «bougé» dans l'interface utilisateur après les prochains changements en comparant les captures d'écran actuelles avec celles de référence précédemment fixées. Depuis lors, beaucoup de choses ont changé dans nos approches d'écriture des tests visuels, y compris le moteur utilisé. Maintenant, nous utilisons
Hermione , mais dans cet article, je vais parler non seulement et pas tellement d'Hermione, mais des problèmes qui se sont accumulés depuis et comment les résoudre, qui, entre autres, ont conduit à la transition vers un nouveau moteur.
Premièrement, bien que les tests aient fonctionné et avec succès, nous ne comprenions pas clairement ce qui était couvert par les tests et ce qui ne l’était pas. Il y avait bien sûr une certaine idée du degré de couverture, mais nous ne l'avons pas mesuré quantitativement. Deuxièmement, la composition des tests a augmenté au fil du temps et différents tests ont souvent testé la même chose, car dans différentes captures d'écran, une partie coïncidait avec la même partie, mais dans une capture d'écran différente. Par conséquent, même des modifications mineures de CSS pourraient submerger de nombreux tests à la fois et nécessiter la mise à jour d'un grand nombre de normes. Troisièmement, un thème sombre est apparu dans notre produit, et afin de le couvrir en quelque sorte avec des tests, certains tests ont été sélectivement passés à l'utilisation d'un thème sombre, ce qui n'a pas non plus clarifié le problème de la détermination du degré de couverture.
Optimisation des performances
Nous avons commencé, curieusement, avec des performances optimisées. Je vais vous expliquer pourquoi. Nos tests visuels sont basés sur le
livre d'histoires . Chaque histoire du livre d'histoires n'est pas un composant unique, mais un «bloc» entier (par exemple, une grille avec une liste d'entités, une carte d'entité, un dialogue ou même l'application dans son ensemble). Pour afficher ce bloc, vous devez «pomper» l'histoire avec des données, non seulement les données affichées pour l'utilisateur, mais aussi l'état des composants utilisés à l'intérieur du bloc. Ces informations sont stockées avec le code source sous forme de fichiers json contenant une représentation sérialisée de l'état de l'application (redux store). Oui, ces données sont, pour le moins, redondantes, mais elles simplifient considérablement la création de tests. Pour créer un nouveau test, nous ouvrons simplement la carte, la liste ou la boîte de dialogue souhaitée dans l'application, prenons un instantané de l'état actuel de l'application et le sérialisons dans un fichier. Ensuite, nous ajoutons une nouvelle histoire et des tests qui prennent des captures d'écran de cette histoire (le tout en quelques lignes de code).
Cette approche augmente inévitablement la taille du paquet. Le degré de duplication des données en elle ne fait que «rouler». Lors de l'exécution de tests, le moteur gemini exécute chaque suite de tests dans une session de navigateur distincte. Chaque session charge à nouveau le bundle et la taille du bundle dans un tel schéma est loin de la dernière valeur.
Pour réduire le temps d'exécution des tests, nous avons réduit le nombre de suites de tests en augmentant le nombre de tests qu'elles contiennent. Ainsi, une suite de tests pourrait affecter plusieurs histoires à la fois. Dans ce schéma, nous avons pratiquement perdu la possibilité de «filtrer» uniquement une certaine zone de l'écran en raison du fait que Gemini vous permet de définir la zone de capture d'écran uniquement pour la suite de tests dans son ensemble (bien que l'API vous permette de le faire avant chaque capture d'écran, mais en pratique cela ne fonctionne pas).
L'incapacité à limiter la zone de la capture d'écran dans les tests a conduit à la duplication des informations visuelles dans les images de référence. Bien qu'il n'y ait pas eu beaucoup de tests, ce problème ne semblait pas significatif. Oui, et l'interface utilisateur n'a pas changé très souvent. Mais cela ne pouvait pas durer éternellement - une refonte se profilait à l'horizon.
Pour l'avenir, je dirai que dans Hermione, une zone de capture d'écran peut être définie pour chaque prise de vue et, à première vue, le passage à un nouveau moteur résoudrait tous les problèmes. Mais il nous faudrait encore «écraser» les grandes suites de tests. Le fait est que les tests visuels ne sont pas intrinsèquement stables (cela peut être dû à diverses raisons, par exemple, avec des retards de réseau, à l'aide d'animations ou avec la «météo sur Mars») et il est très difficile de se passer de tentatives automatiques. Gemini et Hermione effectuent des tentatives pour la suite de tests dans son ensemble, et plus la suite de tests est «épaisse», moins elle aura de chances de se terminer avec succès pendant les nouvelles tentatives, car lors de la prochaine exécution, il se peut que les tests qui ont été réussis précédemment tombent. Pour les suites de tests épaisses, nous avons dû implémenter un schéma de nouvelle tentative intégré au moteur Gemini et nous ne voulions vraiment pas recommencer lors du passage à un nouveau moteur.
Par conséquent, afin d'accélérer le chargement de la suite de tests, nous avons divisé le paquet monolithique en parties, en allouant chaque instantané de l'état de l'application en une «pièce» distincte, chargée «à la demande» pour chaque histoire séparément. Le code de création d'histoire ressemble maintenant à ceci:
Pour créer une histoire, le composant StoryProvider est utilisé (son code sera donné ci-dessous). Les instantanés sont chargés à l'aide de la fonction d'
importation dynamique . Différentes histoires ne diffèrent les unes des autres que par des images d'états. Pour un thème sombre, sa propre histoire est générée, en utilisant le même instantané que l'histoire pour un thème clair. Dans le contexte d'un livre de contes, cela ressemble à ceci:
Histoire de thème par défaut Le composant StoryProvider accepte un rappel pour charger un instantané dans lequel la fonction import () est appelée. La fonction import () fonctionne de manière asynchrone, vous ne pouvez donc pas prendre de capture d'écran immédiatement après le chargement de l'histoire - nous risquons de supprimer le vide. Afin de saisir l'instant de la fin du téléchargement, le fournisseur rend l'élément marqueur DOM signalant le moteur de test pour la durée du téléchargement, qui doit être retardé avec la capture d'écran:
De plus, pour réduire la taille du bundle, désactivez l'ajout de mappages source au bundle. Mais pour ne pas perdre la possibilité de déboguer l'histoire (on ne sait jamais quoi), on le fait à la condition:
.storybook / webpack.config.js Le
script npm run build-storybook compile un storybook statique sans sourcemap dans le dossier storybook-static. Il est utilisé lors des tests. Et le
script npm run storybook est utilisé pour développer et déboguer des histoires de test.
Élimination de la duplication des informations visuelles
Comme je l'ai dit ci-dessus, Gemini vous permet de définir des sélecteurs de zone de capture d'écran pour la suite de tests dans son ensemble, ce qui signifie que pour résoudre complètement le problème de duplication des informations visuelles dans les captures d'écran, nous devons créer notre propre suite de tests pour chaque capture d'écran. Même en tenant compte de l'optimisation du chargement de l'histoire, cela n'avait pas l'air trop optimiste en termes de vitesse et nous avons pensé à changer le moteur de test.
En fait, pourquoi Hermione? Actuellement, le référentiel Gemini est marqué comme obsolète et, tôt ou tard, nous avons dû «déplacer» quelque part. La structure du fichier de configuration Hermione est identique à la structure du fichier de configuration Gemini et nous avons pu réutiliser cette config. Les plugins Gemini et Hermione sont également courants. De plus, nous avons pu réutiliser l'infrastructure de test - machines virtuelles et grille de sélénium déployée.
Contrairement à Gemini, Hermione n'est pas positionnée comme un outil uniquement pour les tests de régression de la mise en page. Ses capacités de manipulation du navigateur sont beaucoup plus larges et limitées uniquement par les capacités de
Webdriver IO . En combinaison avec
mocha, ce moteur est plus pratique à utiliser pour les tests fonctionnels (simulation des actions de l'utilisateur) que pour les tests de mise en page. Pour les tests de régression de la mise en page, Hermione fournit uniquement la méthode assertView (), qui compare une capture d'écran d'une page de navigateur avec une référence. La capture d'écran peut être limitée à la zone spécifiée à l'aide des sélecteurs css.
Pour notre cas, le test pour chaque histoire individuelle ressemblerait à ceci:
La méthode waitForVisible (), malgré son nom, vous permet de vous attendre non seulement à l'apparence, mais également au masquage de l'élément, si vous définissez le deuxième paramètre sur true. Ici, nous l'utilisons pour attendre qu'un élément marqueur soit masqué, indiquant que l'instantané de données n'est pas encore chargé et que l'histoire n'est pas encore prête pour une capture d'écran.
Si vous essayez de trouver la méthode waitForVisible () dans la documentation Hermione, vous ne trouverez rien. Le fait est que la
méthode waitForVisible ()
est la méthode API Webdriver IO . La méthode url (), respectivement, aussi. Dans la méthode url (), nous transmettons l'adresse de trame d'une histoire particulière, pas le livre d'histoires entier. Tout d'abord, cela est nécessaire pour que la liste des histoires ne s'affiche pas dans la fenêtre du navigateur - nous n'avons pas besoin de la tester. Deuxièmement, si nécessaire, nous pouvons avoir accès aux éléments DOM à l'intérieur du cadre (les méthodes webdriverIO vous permettent d'exécuter du code JavaScript dans un contexte de navigateur).
Pour simplifier l'écriture des tests, nous avons fait notre wrapper sur les tests mocha. Le fait est qu'il n'y a pas de sens particulier dans l'élaboration détaillée des cas de test pour les tests de régression. Tous les cas de test sont identiques - «devrait être égal à étalon». Eh bien, je ne veux pas non plus dupliquer le code pour attendre le chargement des données dans chaque test. Par conséquent, le même travail pour tous les tests «singe» est délégué à la fonction wrapper, et les tests eux-mêmes sont écrits de manière déclarative (enfin, presque). Voici le texte de cette fonction:
create-test-suite.js const themes = [ 'default', 'dark' ]; const rootClassName = '.explorer'; const loadingStubClassName = '.loading-stub'; const timeout = 2000; function createTestSuite(testSuite) { const { name, storyName, browsers, testCases, selector } = testSuite;
Un objet décrivant la suite de tests est passé à l'entrée de la fonction. Chaque suite de tests est construite selon le scénario suivant: prendre une capture d'écran de la mise en page principale (par exemple, une zone d'une carte d'entité ou une zone d'une liste d'entités), puis appuyer sur des boutons par programmation pouvant entraîner l'apparition d'autres éléments (par exemple, des panneaux contextuels ou des menus contextuels) et «prendre une capture d'écran »Chacun de ces éléments séparément. Ainsi, nous simulons les actions des utilisateurs dans le navigateur, mais pas dans le but de tester une sorte de scénario d'entreprise, mais simplement pour «capturer» le nombre maximal possible de composants visuels. De plus, la duplication des informations visuelles dans les captures d'écran est minime, car les captures d'écran sont prises "ponctuellement" à l'aide de sélecteurs. Exemple de suite de tests:
Détermination de la couverture
Donc, nous avons compris la vitesse et la redondance, il reste à déterminer l'efficacité de nos tests, c'est-à-dire déterminer le degré de couverture du code avec des tests (ici par code, j'entends les feuilles de style CSS).
Pour les histoires de test, nous avons empiriquement sélectionné les cartes, listes et autres éléments les plus compliqués à remplir afin de couvrir autant de styles que possible avec une capture d'écran. Par exemple, pour tester une carte d'entité, des cartes avec un grand nombre de types de contrôles différents (texte, nombre, transferts, dates, grilles, etc.) ont été sélectionnées. Les cartes pour différents types d'entités ont leurs propres spécificités, par exemple, à partir d'une carte de document, vous pouvez afficher un panneau avec une liste des versions de document, et la carte de tâche affiche la correspondance pour cette tâche. En conséquence, pour chaque type d'entité, sa propre histoire et un ensemble de tests spécifiques à ce type, etc., ont été créés. Au final, nous avons pensé que tout semblait être couvert de tests, mais nous voulions un peu plus de confiance que «j'aime».
Pour évaluer la couverture dans Chrome DevTools, il existe un outil avec le nom Couverture très adapté à ce cas:
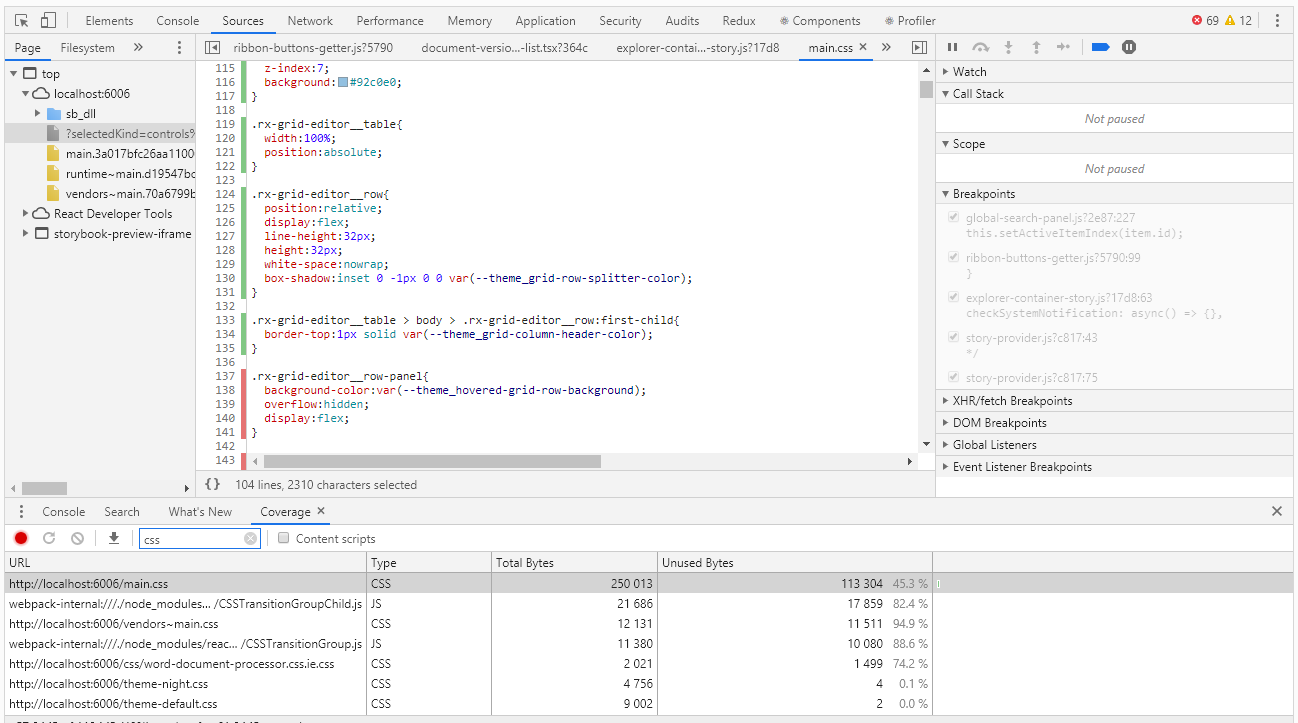
La couverture vous permet de déterminer quels styles ou quel code js a été utilisé lors de l'utilisation de la page du navigateur. Le rapport sur l'utilisation des rayures vertes indique le code utilisé, rouge - non utilisé. Et tout irait bien si nous avions une application du niveau «bonjour, monde», mais que faire quand nous avons des milliers de lignes de code? Les développeurs de couverture l'ont bien compris et ont fourni la possibilité d'exporter le rapport dans un fichier qui peut déjà être élaboré par programme.
Je dois dire tout de suite que jusqu'à présent, nous n'avons pas trouvé de moyen de collecter automatiquement le degré de couverture. Théoriquement, cela peut être fait en utilisant le navigateur sans tête pupeteer, mais pupeteer ne fonctionne pas sous le contrôle du sélénium, ce qui signifie que nous ne pourrons pas réutiliser le code de nos tests. Donc pour l'instant, sautons ce sujet extrêmement intéressant et travaillons avec des stylos.
Après avoir exécuté les tests en mode manuel, nous obtenons un rapport de couverture, qui est un fichier json. Dans le rapport pour chaque css, js, ts, etc. le fichier indique son texte (sur une ligne) et les intervalles du code utilisé dans ce texte (sous forme d'indices de caractères de cette ligne). Voici un extrait du rapport:
coverage.json [ { "url": "http://localhost:6006/theme-default.css", "ranges": [ { "start": 0, "end": 8127 } ], "text": "... --theme_primary-accent: #5b9bd5;\r\n --theme_primary-light: #ffffff;\r\n --theme_primary: #f4f4f4;\r\n ..." }, { "url": "http://localhost:6006/main.css", "ranges": [ { "start": 0, "end": 610 }, { "start": 728, "end": 754 } ] "text": "... \r\n line-height:1;\r\n}\r\n\r\nol, ul{\r\n list-style:none;\r\n}\r\n\r\nblockquote, q..." ]
À première vue, il n'y a rien de difficile à trouver des sélecteurs CSS inutilisés. Mais alors que faire de ces informations? En effet, en dernière analyse, nous devons trouver non pas des sélecteurs spécifiques, mais des composants que nous avons oublié de couvrir avec des tests. Les styles d'un composant peuvent être définis par plus d'une douzaine de sélecteurs. En conséquence, sur la base des résultats de l'analyse du rapport, nous obtenons des centaines de sélecteurs inutilisés, et si vous traitez avec chacun d'eux, vous pouvez tuer beaucoup de temps.
Ici, les expressions régulières nous aident. Bien sûr, ils ne fonctionneront que si les conventions de dénomination des classes css sont respectées (dans notre code, les classes css sont nommées selon la méthodologie BEM - block_name_name_name_modifier). À l'aide d'expressions régulières, nous calculons les valeurs uniques des noms de blocs, qui ne sont plus difficiles à associer aux composants. Bien sûr, nous nous intéressons également aux éléments et aux modificateurs, mais pas en premier lieu, nous devons d'abord faire face à un «poisson» plus gros. Vous trouverez ci-dessous un script pour le traitement d'un rapport de couverture
couverture.js const modules = require('./coverage.json').filter(e => e.url.endsWith('.css')); function processRange(module, rangeStart, rangeEnd, isUsed) { const rules = module.text.slice(rangeStart, rangeEnd); if (rules) { const regex = /^\.([^\d{:,)_ ]+-?)+/gm; const classNames = rules.match(regex); classNames && classNames.forEach(name => selectors[name] = selectors[name] || isUsed); } } let previousEnd, selectors = {}; modules.forEach(module => { previousEnd = 0; for (const range of module.ranges) { processRange(module, previousEnd, range.start, false); processRange(module, range.start, range.end, true); previousEnd = range.end; } processRange(module, previousEnd, module.length, false); }); console.log('className;isUsed'); Object.keys(selectors).sort().forEach(s => { console.log(`${s};${selectors[s]}`); });
Nous exécutons le script en plaçant d'abord le fichier coverage.json exporté de Chrome DevTools et en écrivant l'échappement dans un fichier .csv:
node coverage.js> coverage.csvVous pouvez ouvrir ce fichier à l'aide d'Excel et analyser les données, notamment en déterminant le pourcentage de couverture de code par des tests.

Au lieu d'un CV
L'utilisation du livre d'histoires comme base pour des tests visuels se justifie pleinement - nous avons un degré suffisant de couverture du code CSS avec des tests avec un nombre relativement faible d'histoires et des coûts minimes pour en créer de nouveaux.
La transition vers un nouveau moteur nous a permis d'éliminer la duplication des informations visuelles dans les captures d'écran, ce qui a grandement simplifié la prise en charge des tests existants.
Le degré de couverture du code CSS est mesurable et, de temps en temps, est surveillé. Il y a bien sûr une grande question - comment ne pas oublier la nécessité de ce contrôle et comment ne pas rater quelque chose dans le processus de collecte d'informations sur la couverture. Idéalement, je voudrais mesurer automatiquement le degré de couverture à chaque test, de sorte que lorsque le seuil spécifié est atteint, les tests tombent avec une erreur. Nous y travaillerons, s'il y a des nouvelles, je vous le dirai certainement.