Infa sera utile aux développeurs JS qui souhaitent comprendre en profondeur l'essence de travailler avec Node.js et Event Loop. Vous pouvez contrôler consciemment et de manière plus flexible le flux du programme (serveur Web).
J'ai compilé cet article sur la base de mon récent rapport à mes collègues.
À la fin de l'article, il existe des documents utiles pour une étude indépendante.
Comment est Node.js. Fonctionnalités asynchrones
Regardons ce code: il illustre parfaitement la synchronisation de l'exécution du code dans Node.js. Une demande est faite quelque part sur GitHub, puis un fichier est lu et le résultat est affiché dans la console. Qu'est-ce qui ressort clairement de ce code synchrone?
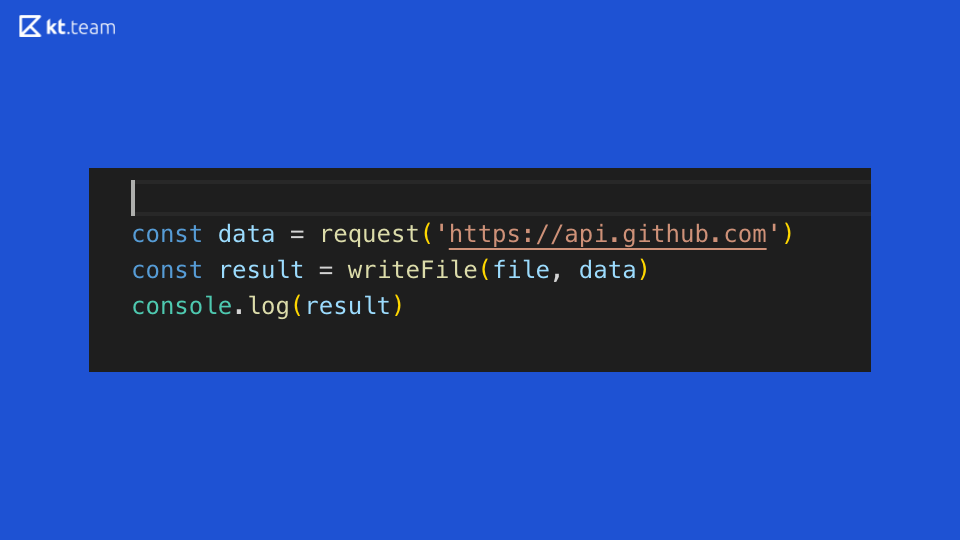
Supposons qu'il s'agit d'un serveur Web abstrait qui effectue des opérations sur un routeur. Si une demande entrante arrive sur ce routeur, nous faisons une demande plus loin, lisons le fichier et l'imprimons sur la console. Par conséquent, le temps consacré à la demande et à la lecture d'un fichier, le serveur sera bloqué, il ne pourra pas traiter d'autres demandes entrantes, ni effectuer d'autres opérations.
Quelles sont les options pour résoudre ce problème?
- Multithreading
- E / S non bloquantes
Pour la première option (multithreading), il existe un bon exemple avec le serveur Web Apache vs Nginx.
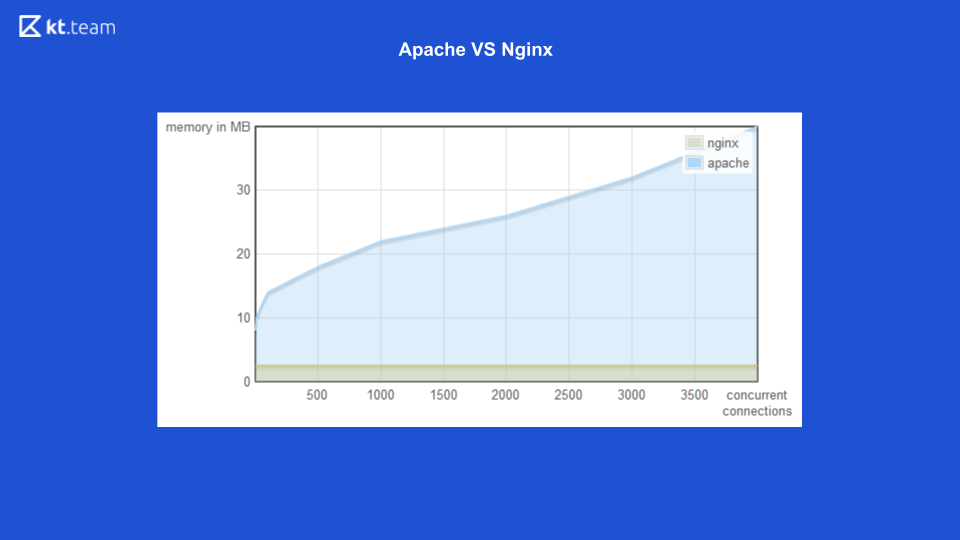
Auparavant, Apache soulevait un flux pour chaque demande entrante: combien de demandes il y avait, le même nombre de threads. A cette époque, Nginx avait l'avantage d'utiliser des E / S non bloquantes. Ici, vous pouvez voir qu'avec une augmentation du nombre de demandes entrantes, la quantité de mémoire consommée par Apache augmente, et sur la diapositive suivante, le nombre de demandes traitées par seconde avec le nombre de connexions pour Nginx est plus élevé.
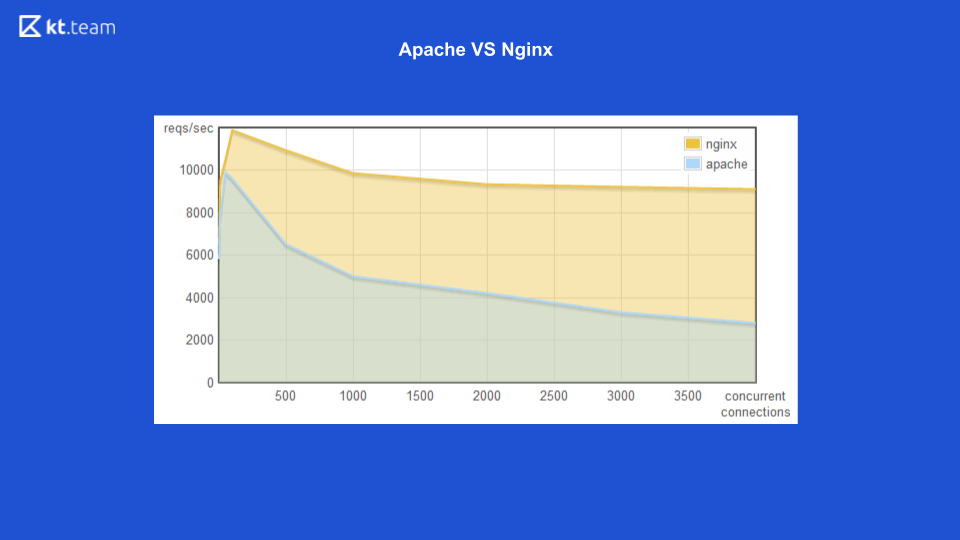
Il est clairement démontré que les entrées / sorties non bloquantes sont plus efficaces.
Les entrées / sorties non bloquantes sont rendues possibles grâce aux systèmes d'exploitation modernes qui fournissent ce mécanisme - un démultiplexeur d'événements.
Un démultiplexeur est un mécanisme qui reçoit une demande d'une application, l'enregistre et l'exécute.
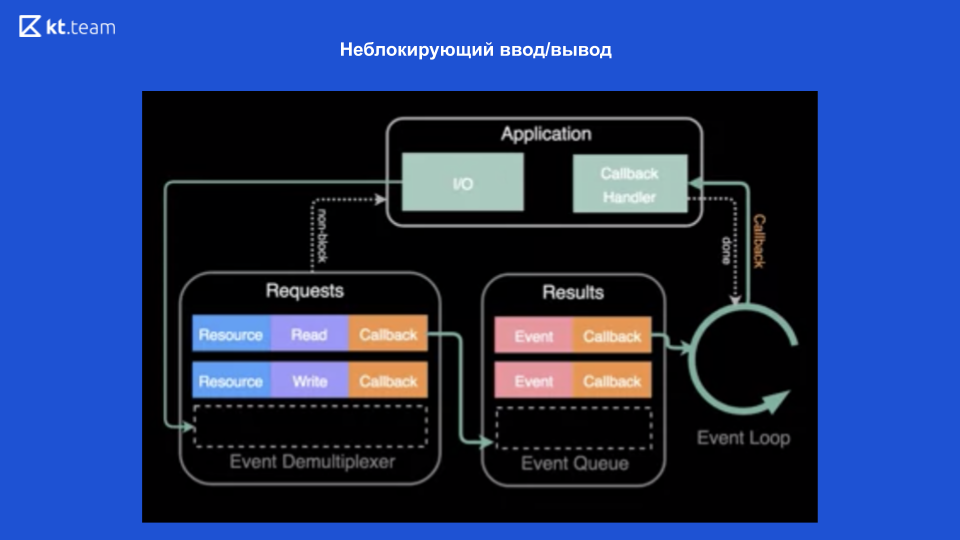
Dans la partie supérieure du diagramme, on voit que nous avons une application et que des opérations y sont effectuées (qu'il s'agisse de lire un fichier). Pour ce faire, une demande est faite au démultiplexeur d'événement, une ressource est envoyée ici (lien vers le fichier), l'opération souhaitée et le rappel. Le démultiplexeur d'événements enregistre cette demande et renvoie le contrôle directement à l'application - il n'est donc pas bloqué. Ensuite, il effectue des opérations sur le fichier, et après cela, lorsque le fichier est lu, le rappel est enregistré dans la file d'attente d'exécution. Ensuite, la boucle d'événements traite progressivement et de façon synchrone chaque rappel de cette file d'attente. Et, en conséquence, renvoie le résultat à l'application. De plus (si nécessaire) tout est refait.
Ainsi, grâce à ces E / S non bloquantes, Node.js peut être asynchrone.
Je précise que dans ce cas, c'est le système d'exploitation qui nous fournit des entrées / sorties non bloquantes. Pour les entrées / sorties non bloquantes (généralement, en principe, pour les opérations d'entrée / sortie), nous incluons les requêtes réseau et travaillons avec les fichiers.
Il s'agit du concept général d'E / S non bloquantes. Lorsque l'occasion s'est présentée, Ryan Dahl, développeur Node.js, s'est inspiré de l'expérience Nginx, qui utilisait des E / S non bloquantes, et a décidé de créer une plate-forme spécifiquement pour les développeurs. La première chose qu'il devait faire était de «se faire des amis» sa plate-forme avec un démultiplexeur d'événements. Le problème était que le démultiplexeur était implémenté différemment dans chaque système d'exploitation, et il devait écrire un wrapper, qui deviendra plus tard libuv. Il s'agit d'une bibliothèque écrite en C. Elle fournit une interface unique pour travailler avec ces démultiplexeurs d'événements.
Fonctionnalités de la bibliothèque Libuv
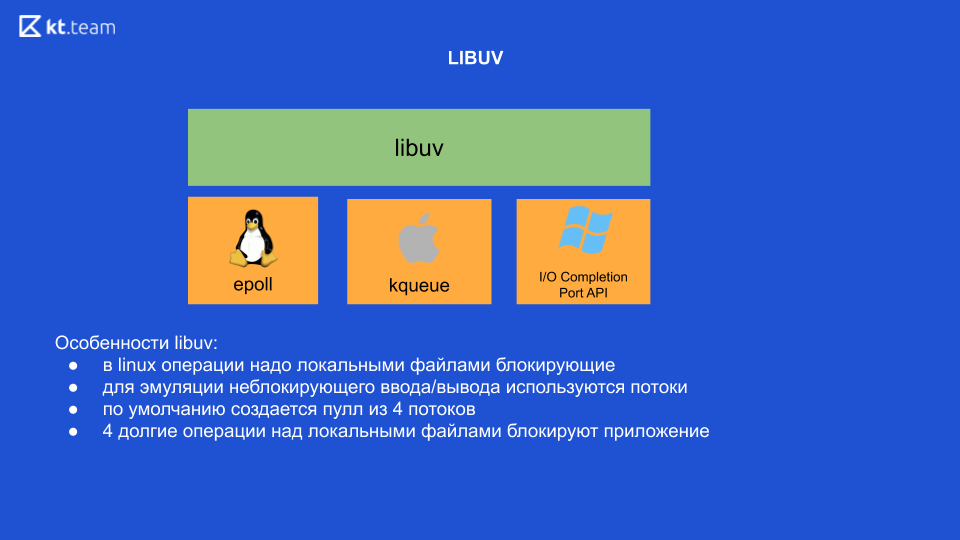
Sous Linux, en principe, pour le moment, toutes les opérations avec des fichiers locaux sont bloquantes. Autrement dit, il semble qu'il y ait des entrées / sorties non bloquantes, mais c'est précisément lorsque vous travaillez avec des fichiers locaux que l'opération est toujours bloquante. C'est pourquoi libuv utilise des threads en interne pour émuler des E / S non bloquantes. 4 threads sortent de la boîte, et ici nous devons faire la conclusion la plus importante: si nous effectuons quelques 4 opérations lourdes sur des fichiers locaux, en conséquence, nous bloquerons toute notre application (c'est sous Linux, les autres OS ne le font pas).
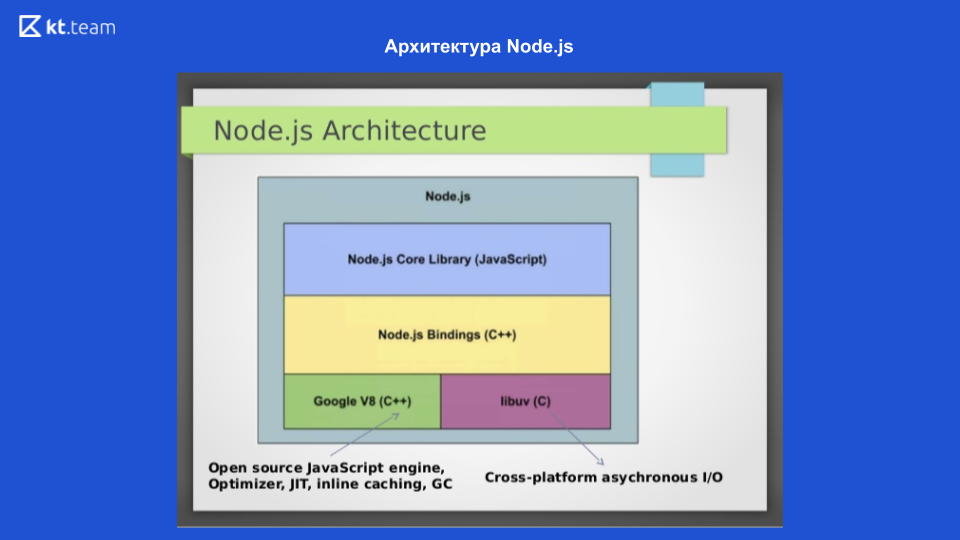
Sur cette diapositive, nous voyons l'architecture de Node.js. Pour interagir avec le système d'exploitation, la bibliothèque libuv écrite en C est utilisée; Pour compiler le code JavaScript en code machine, le moteur Google V8 est utilisé, il existe également une bibliothèque Node.js Core, qui contient des modules pour travailler avec les requêtes réseau, un système de fichiers et un module pour la journalisation. Pour que tout cela interagisse, les liaisons Node.js sont écrites. Ces 4 composants constituent la structure de Node.js. Le mécanisme de boucle d'événement lui-même est dans libuv.
Boucle d'événement
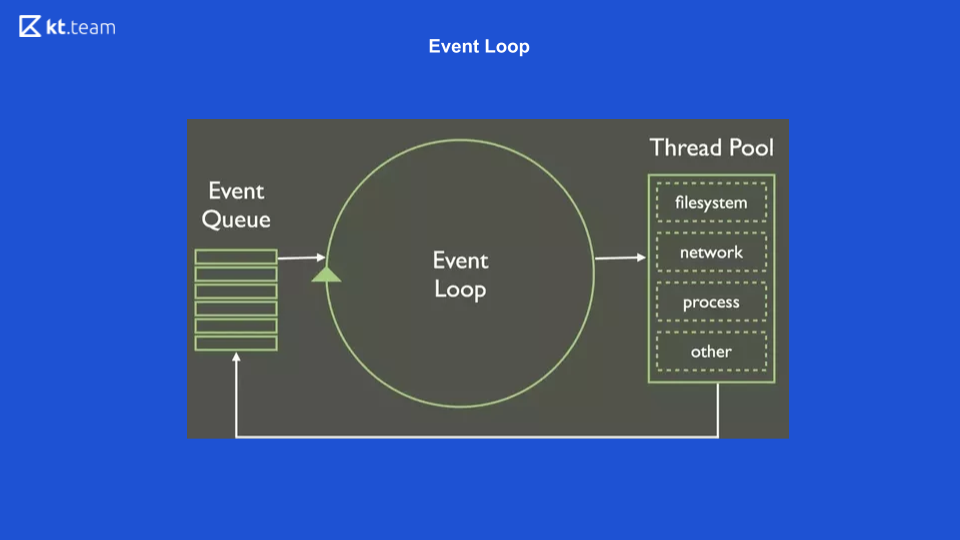
Il s'agit de la représentation la plus simple de ce à quoi ressemble la boucle d'événements. Il y a une certaine file d'attente d'événements, il y a un cycle sans fin d'événements qui effectue de manière synchrone des opérations à partir de la file d'attente, et il les distribue davantage.
Cette diapositive montre à quoi ressemble la boucle d'événements directement dans Node.js.
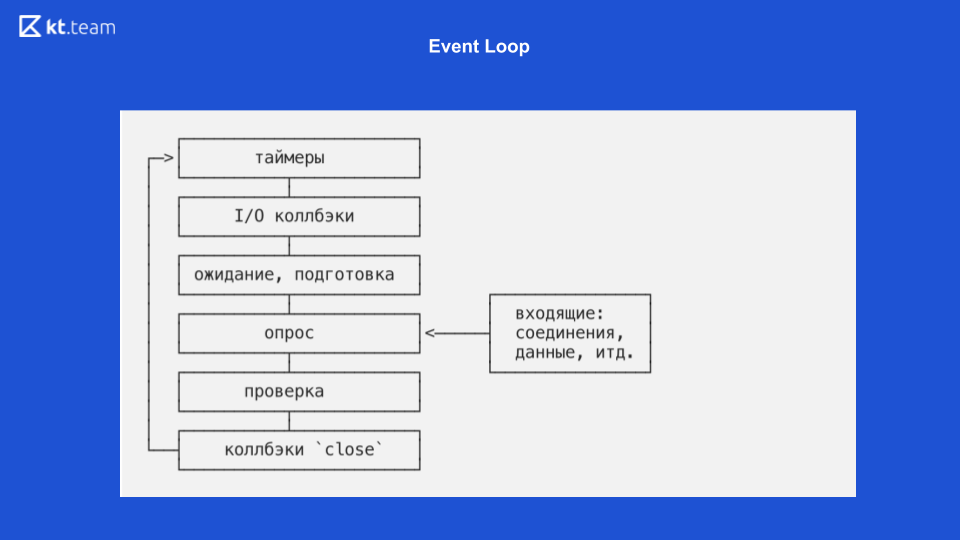
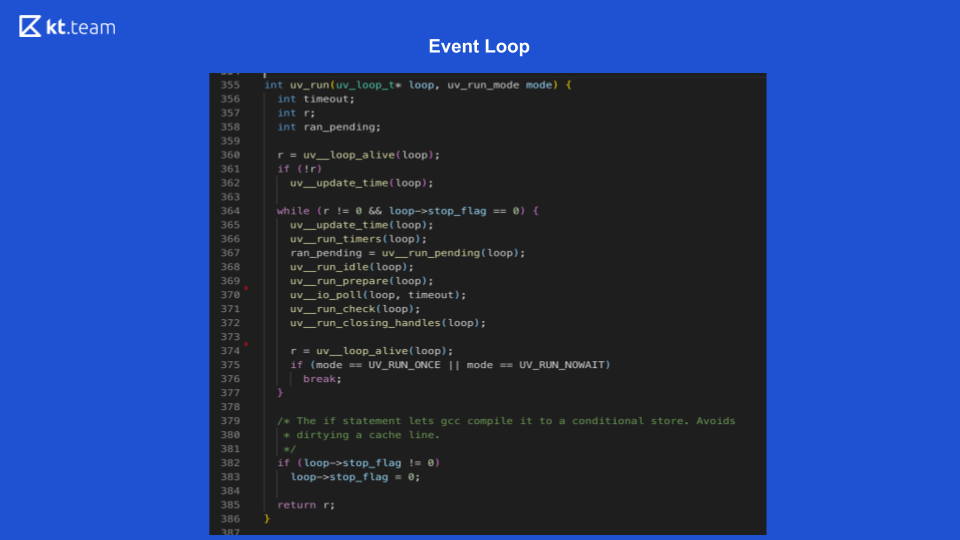
Là, l'implémentation est plus intéressante et plus compliquée. Essentiellement, une boucle d'événement est une boucle d'événement, et elle est infinie tant qu'il y a quelque chose à faire. La boucle d'événements dans Node.js est divisée en plusieurs phases. (Les phases de la diapositive 8 doivent être comparées avec le code source de la diapositive 9.)
Phase 1 - Minuteurs
Cette phase est réalisée directement par Event Loop. (Extrait de code avec uv_update_time) - ici, l'heure à laquelle la boucle d'événements a commencé à fonctionner est simplement mise à jour.
uv_run_timers - dans cette méthode, la prochaine action de temporisation est effectuée. Il y a une certaine pile, plus précisément, un tas de minuteries, c'est essentiellement la même que la file d'attente où se trouvent les minuteries. Le temporisateur avec le temps le plus court est pris, par rapport à l'heure actuelle de la boucle d'événement, et s'il est temps d'exécuter ce temporisateur, son rappel est exécuté. Il convient de noter ici que Node.js a une implémentation de setTimeout et qu'il y a setInterval. Pour libuv, c'est essentiellement la même chose, seul setInterval a toujours un drapeau de répétition.
Par conséquent, si ce temporisateur a un indicateur de répétition, il est à nouveau placé dans la file d'attente d'événements puis traité de la même manière.
Phase 2 - rappels d'E / S
Ici, nous devons revenir au diagramme sur les entrées / sorties non bloquantes.
Lorsque le démultiplexeur d'événements lit un fichier et met en file d'attente le rappel, il correspond simplement à l'étape de rappel d'E / S. Ici, les rappels sont effectués pour les entrées / sorties non bloquantes, c'est-à-dire que ce sont exactement les fonctions qui sont utilisées après une demande à une base de données ou à une autre ressource ou pour lire / écrire un fichier. Ils sont effectués précisément à cette phase.
Dans la diapositive 9, l'exécution de la fonction de rappel d'E / S démarre la ligne 367: ran_pending = uv_run_pending (boucle).
3 phases - attente, préparation
Ce sont des opérations internes pour les rappels, en fait, nous ne pouvons pas influencer la phase, seulement indirectement. Il y a un process.nextTick, son rappel peut être exécuté par inadvertance dans la phase d'attente de préparation. process.nextTick est exécuté dans la phase actuelle, c'est-à-dire qu'en fait process.nextTick peut fonctionner dans n'importe quelle phase. Il n'y a pas d'outil prêt à l'emploi pour exécuter le code dans la phase «attente, préparation» dans Node.js.
Sur la diapositive 9, les lignes 368, 369 correspondent à cette phase:
uv_run_idle (boucle) - attendre;
uv_run_prepare (loop) - préparation.
4 phases - enquête
C'est là que tout notre code que nous écrivons en JS est exécuté. Initialement, toutes les demandes que nous faisons arrivent ici, et c'est là que Node.js peut être bloqué. Si une opération de calcul lourde arrive ici, alors à ce stade, notre application peut simplement geler et attendre que cette opération soit terminée.
Sur la diapositive 9, la fonction d'interrogation est sur la ligne 370: uv_io_poll (boucle, timeout).
5 phases - contrôle
Il y a un temporisateur setImmediate dans Node.js, ses rappels sont exécutés dans cette phase.
Dans le code source, il s'agit de la ligne 371: uv_run_check (loop).
6 phases (dernière) - fermeture des événements de rappel
Par exemple, un socket Web doit fermer la connexion, dans cette phase, un rappel de cet événement sera appelé.
Dans le code source, il s'agit de la ligne 372: uv_run_closing_handless (boucle).
Et à la fin, Event Loop Node.js est comme suit
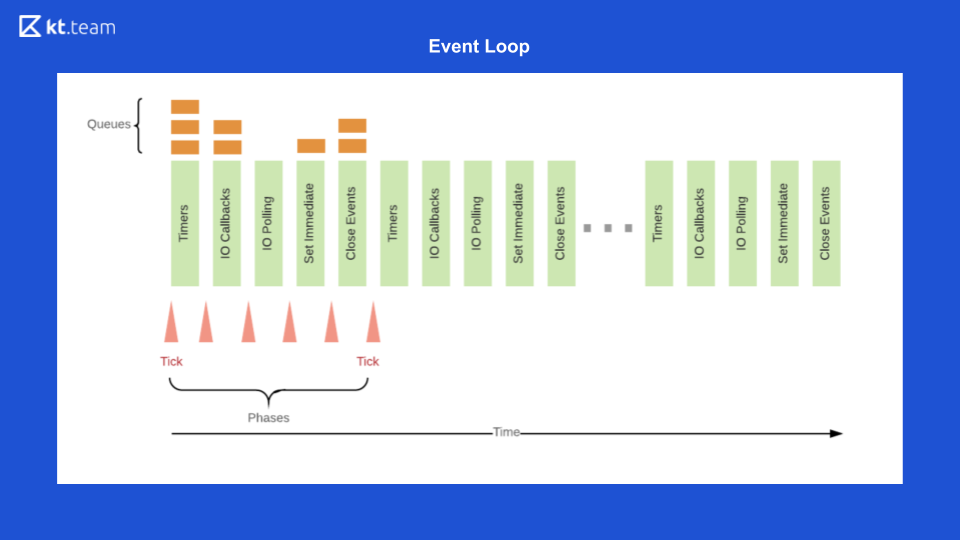
Tout d'abord, dans la file d'attente du minuteur, le minuteur est exécuté, dont la période s'est approchée.
Ensuite, les rappels d'E / S sont exécutés.
Ensuite, le code est la base, puis setImmediate et les événements de fermeture.
Après cela, tout se répète en cercle. Pour illustrer cela, j'ouvre le code. Comment sera-t-il exécuté?
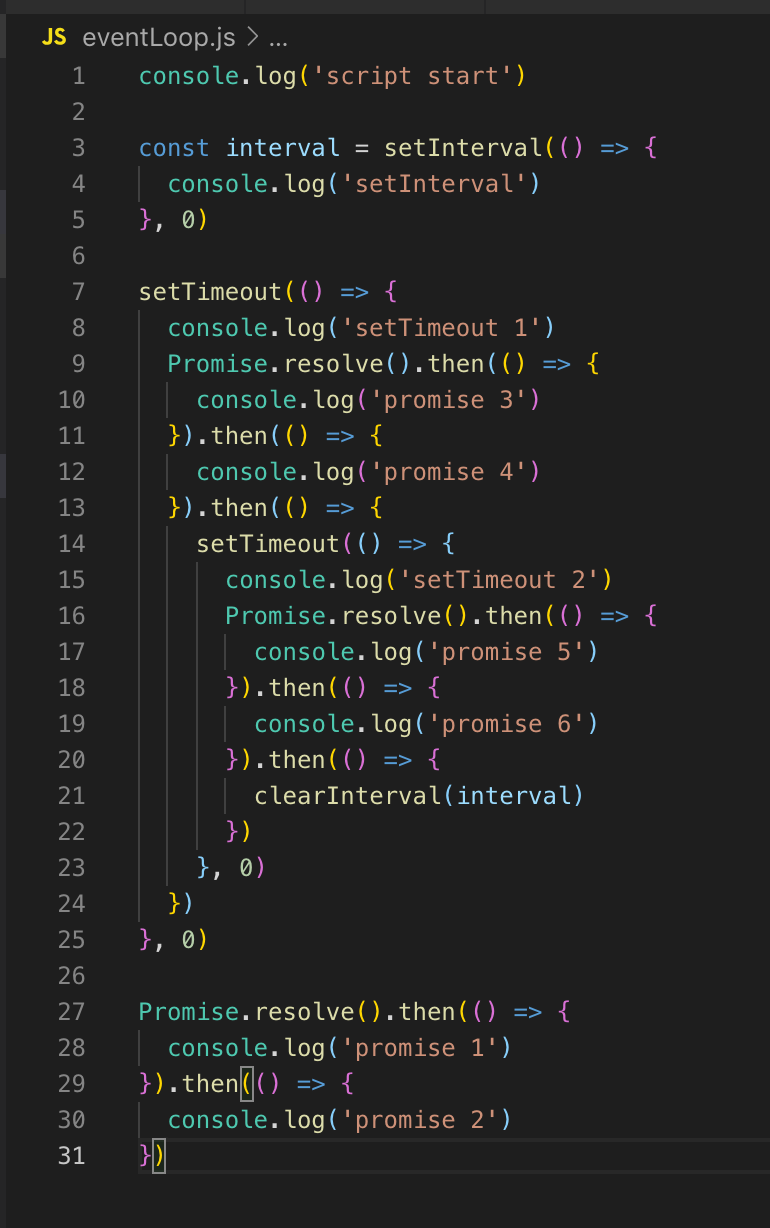
Nous n'avons pas de minuteurs en ligne, donc la boucle d'événement continue. Il n'y a pas non plus de rappel d'E / S, nous passons donc immédiatement à la phase d'interrogation. Tout le code qui est ici est initialement exécuté dans la phase d'interrogation. Par conséquent, nous imprimons d'abord script_start, setInterval est placé dans la file d'attente du temporisateur (non exécuté, juste placé). setTimeout est également placé dans la file d'attente du minuteur, puis les promesses sont exécutées: première promesse 1 puis promesse 2.
Dans le prochain tick (boucle d'événement), nous revenons à l'étape de la minuterie, ici dans la file d'attente il y a déjà 2 temporisateurs: setInterval et setTimeout. Ils sont tous deux retardés de 0, respectivement, ils sont prêts à s'exécuter.
SetInterval est exécuté (sortie vers la console), puis setTimeout 1. Il n'y a pas de rappels d'E / S non bloquants, puis il y aura une phase d'interrogation, la promesse 3 et la promesse 4 sont affichées dans la console.
Ensuite, le minuteur setTimeout est enregistré. Ceci termine la tique, passez à la tique suivante. Il y a de nouveau des temporisateurs, la sortie vers la console est setInterval et setTimeout 2, puis promesse 5 et promesse 6 sont affichés.
Nous avons examiné Event Loop et pouvons maintenant parler plus en détail du multithreading.
Filetage - module worker_threads
Le threading est apparu dans Node.js grâce au module worker_threads de la version 10.5. Et dans la 10e version, il a été lancé exclusivement avec la clé - experimental-worker, et à partir de la 11e version, il était possible de démarrer sans.
Node.js possède également un module de cluster, mais il n'élève pas de threads - il déclenche plusieurs autres processus. L'évolutivité des applications est son objectif principal.
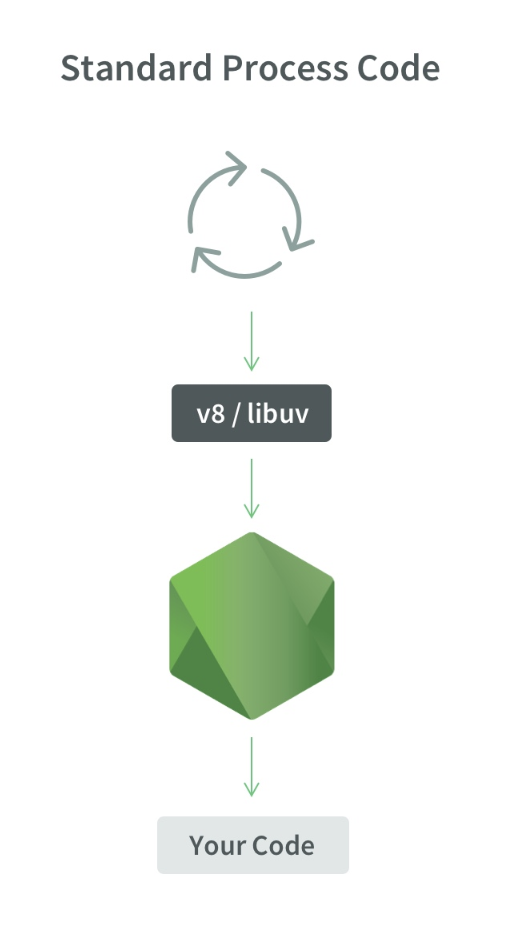
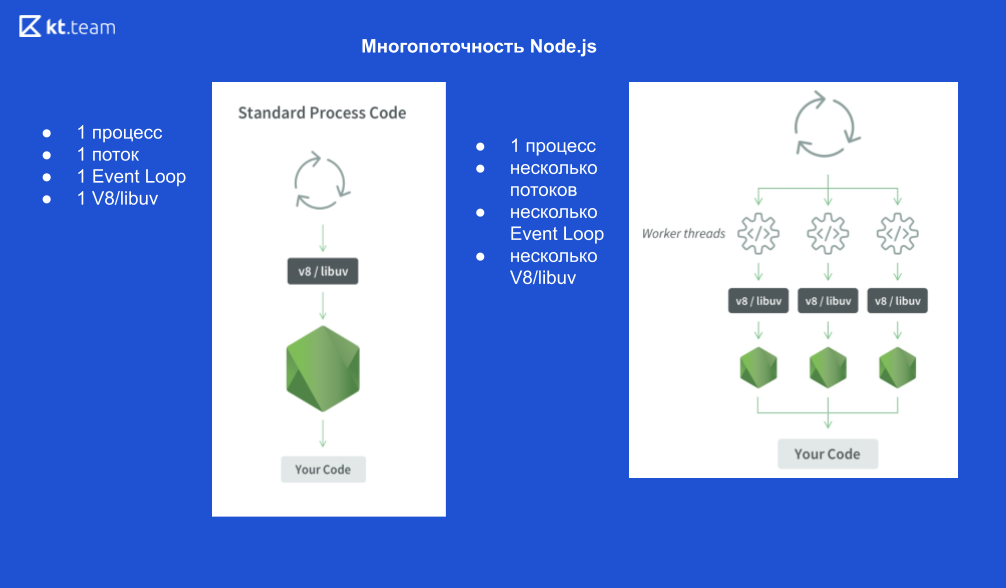
À quoi ressemble 1 processus:
1 processus Node.js, 1 thread, 1 boucle d'événements, 1 moteur V8 et libuv.
Si nous démarrons X threads, cela ressemble à ceci:
1 Processus Node.js, X threads, X Event Loops, X V8 engine et X libuv.
Schématiquement, il se présente comme suit
Prenons un exemple.
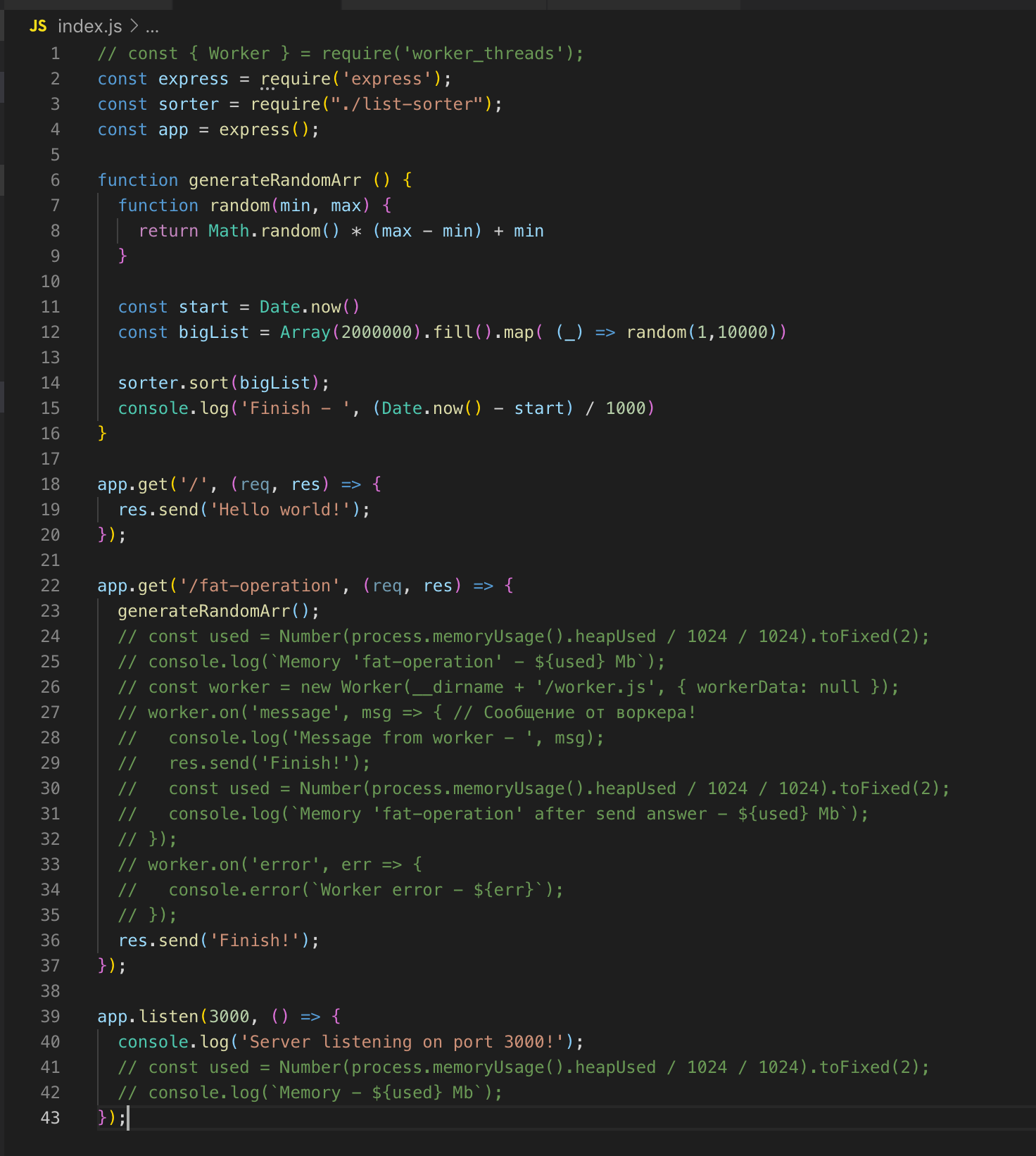
Le serveur Web le plus simple d'Express. Il existe 2 routes'a - / et / fat-operation.
Il existe également une fonction generateRandomArr (). Elle remplit le tableau avec deux millions d'enregistrements et le trie. Commençons le serveur.
Nous faisons une demande pour / fat-operation. Et au moment où l'opération de tri du tableau est effectuée, nous envoyons une autre demande à route /, mais pour obtenir la réponse, nous devons attendre que le tableau soit trié. Il s'agit d'une implémentation classique à un seul thread. Nous connectons maintenant le module worker_threads.
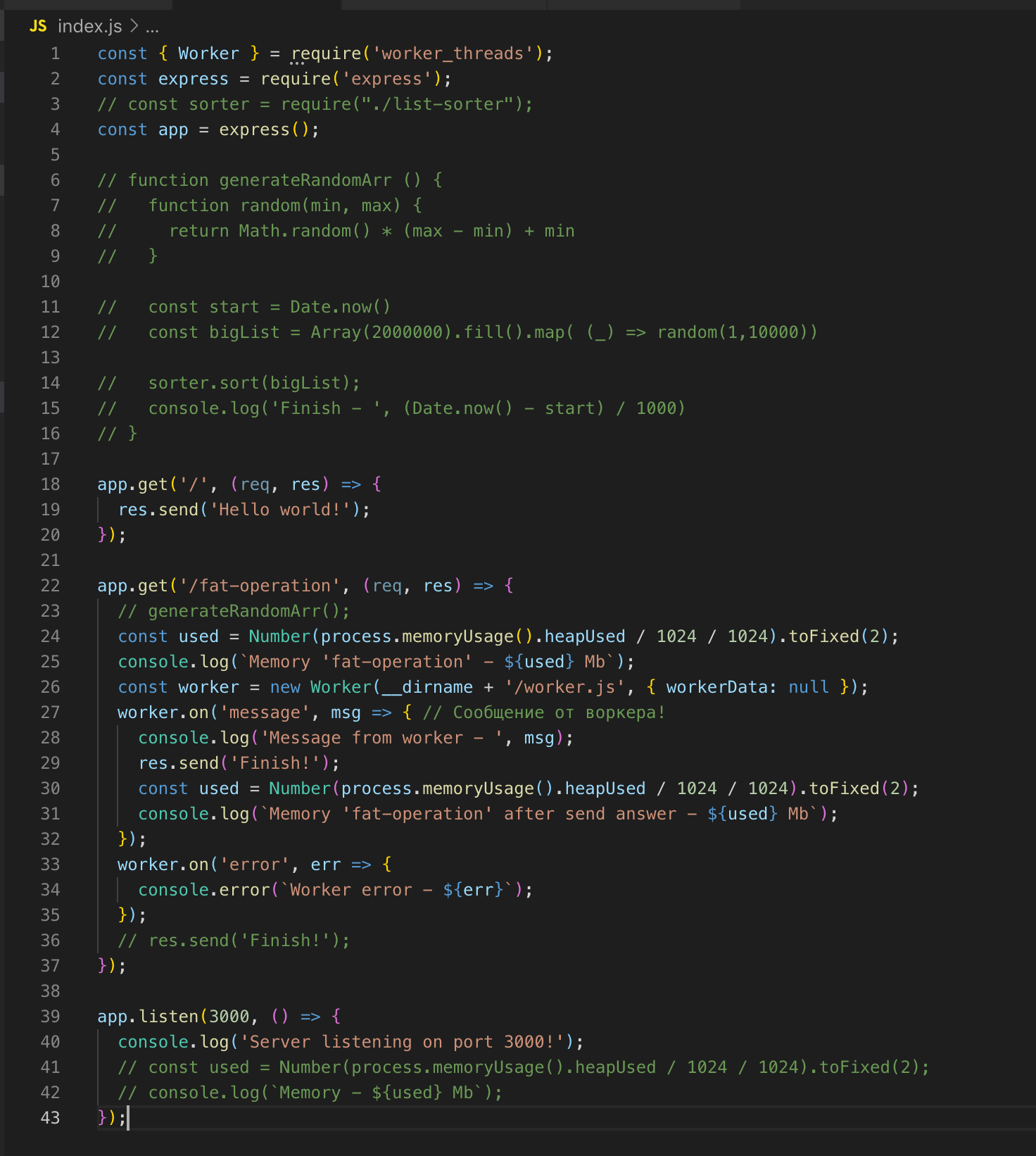
Nous faisons une demande à / fat-operation puis - à /, dont nous obtenons immédiatement la réponse - Bonjour tout le monde!
Pour l'opération de tri du tableau, nous avons soulevé un thread séparé qui a sa propre instance de boucle d'événement, et cela n'affecte pas l'exécution du code dans le thread principal.
Un thread sera "détruit" s'il n'a aucune opération à effectuer.
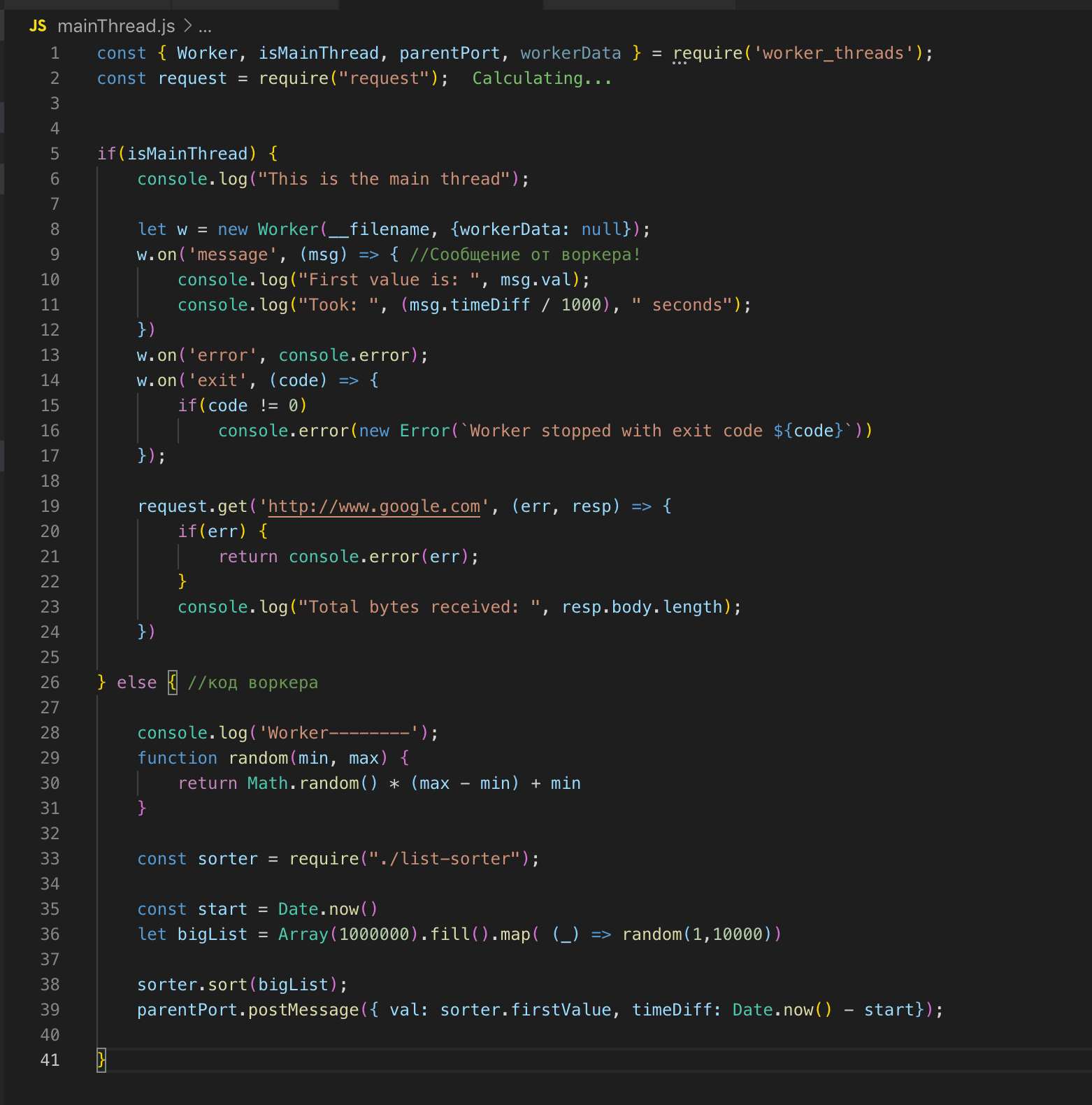
Nous regardons le code source. Nous enregistrons le travailleur à la ligne 26 et, si nécessaire, nous lui transmettons les données. Dans ce cas, je ne transmets rien. Et puis nous souscrivons aux événements: une erreur et un message. Dans l'ouvrier, la fonction est appelée, un tableau de deux millions d'enregistrements est trié. Dès qu'il est trié, nous envoyons le résultat au flux principal ok via post_message.
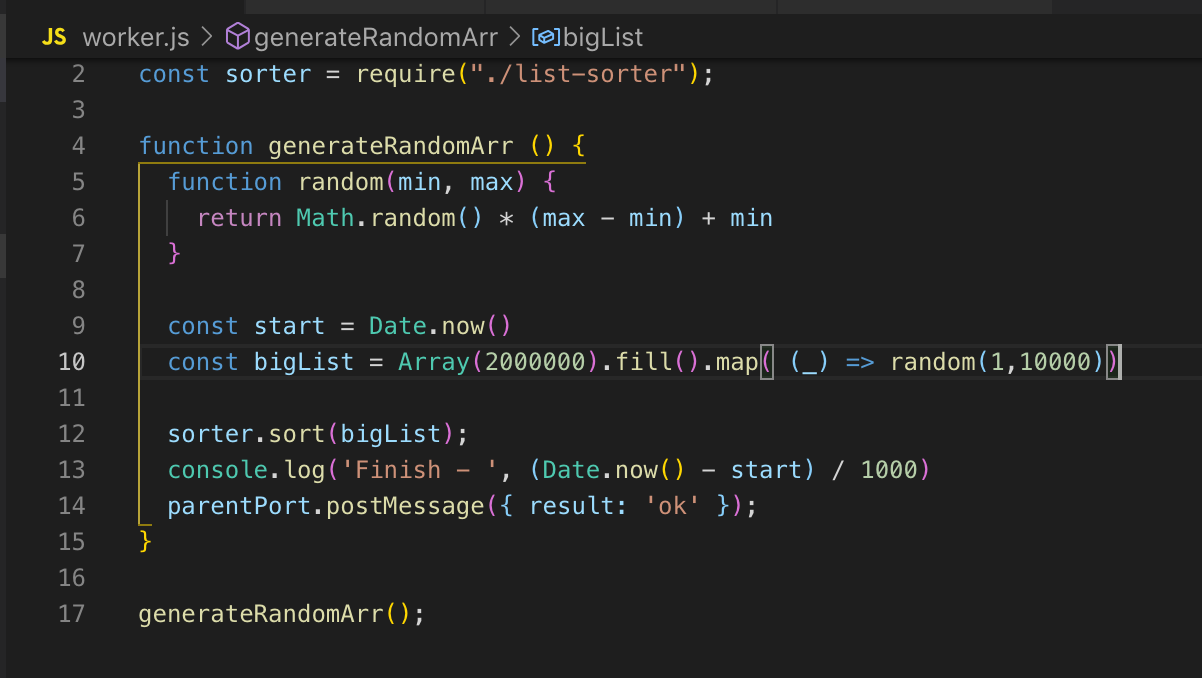
Dans le fil principal, nous interceptons ce message et envoyons le résultat pour terminer. L'ouvrier et le thread principal ont une mémoire commune, nous avons donc accès aux variables globales de l'ensemble du processus. Lorsque nous transférons des données du flux principal vers le travailleur, le travailleur n'en obtient qu'une copie.
Nous pouvons décrire le flux principal et le flux de travail dans un seul fichier. Le module worker_threads fournit une API grâce à laquelle nous pouvons déterminer dans quel thread le code s'exécute actuellement.
Je partage des liens vers des ressources utiles et un lien vers la présentation de Ryan Dahl quand il a présenté la boucle d'événement (intéressant à voir).
Boucle d'événement
- Traduction d'un article de la documentation Node.js
- https://blog.risingstack.com/node-js-at-scale-understanding-node-js-event-loop/
- https://habr.com/en/post/336498/
Worker_threads
- https://nodejs.org/api/worker_threads.html#worker_threads_worker_workerdata - API
- https://habr.com/ru/company/ruvds/blog/415659/
- https://nodesource.com/blog/worker-threads-nodejs/
- Diapositives originales de la présentation de Ryan Dahl (via VPN)