Première partie, complétée.
Cotans, salut.
Je suis Sasha et je me livre aux neurones.
À la demande des travailleurs, j'ai finalement rassemblé mes pensées et décidé de couper une série d'instructions courtes et presque pas à pas.
Des instructions sur la façon de former et de déployer votre réseau de neurones à partir de zéro, tout en se faisant des amis avec le bot de télégramme.
Instructions pour les nuls comme moi.
Aujourd'hui, nous allons choisir l'architecture de notre réseau de neurones, la tester et collecter notre premier ensemble de données d'entraînement.
Choix d'architecture
Après le lancement relativement réussi du robot
selfie2anime (en utilisant le modèle
UGATIT prêt à l'emploi), je voulais faire de même, mais le mien. Par exemple, un modèle qui transforme vos photos en bandes dessinées.
Voici quelques exemples de mon
photo2comicsbot , et nous ferons quelque chose de similaire.



Comme le modèle
UGATIT était trop lourd pour ma carte vidéo, j'ai attiré l'attention sur une analogie plus ancienne mais moins vorace -
CycleGANDans cette implémentation, il existe plusieurs architectures de modèle et un affichage visuel pratique du processus d'apprentissage dans le navigateur.
CycleGAN, comme les
architectures pour le transfert de styles sur une seule image, ne nécessite pas d'images jumelées pour la formation. C'est important, car sinon, il faudrait redessiner toutes les photos nous-mêmes en bandes dessinées pour créer un ensemble d'entraînement.
La tâche que nous allons définir pour notre algorithme se compose de deux parties.
À la sortie, nous devrions obtenir une image qui:
a) semblable à une bande dessinée
b) similaire à l'image originale
Le point «a» peut être mis en œuvre en utilisant le GAN habituel, où le critique formé sera responsable de «ressembler à des bandes dessinées».
Plus sur GAN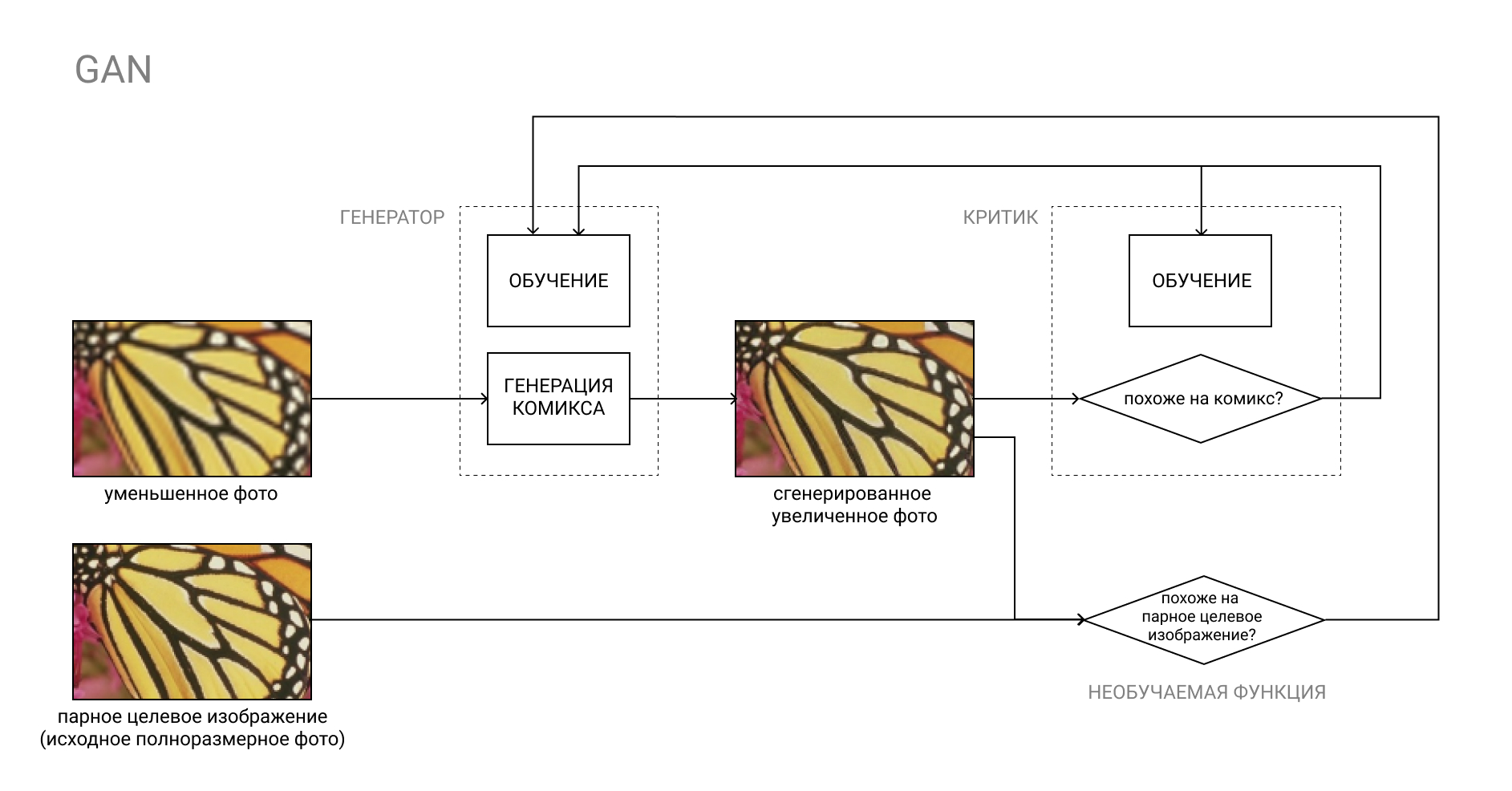
Le GAN, ou Generative Adversarial Network, est une paire de deux réseaux de neurones: Generator et Critic.
Le générateur convertit l'entrée, par exemple, d'une photo en bande dessinée, et le critique compare le résultat «faux» résultant avec une vraie bande dessinée. Le travail du générateur est de tromper le critique, et vice versa.
Dans le processus d'apprentissage, le générateur apprend à créer des bandes dessinées qui sont de plus en plus similaires aux vraies, et le critique apprend à mieux les distinguer.
La deuxième partie est un peu plus compliquée. Si nous avions des images jumelées, où il y aurait des photographies dans l'ensemble «A» et dans l'ensemble «B», elles étaient, mais redessinées en bandes dessinées (c'est-à-dire ce que nous voulons obtenir du modèle), nous pourrions juste pour comparer le résultat produit par le générateur avec l'image appariée de l'ensemble «B» de notre ensemble d'entraînement.
Dans notre cas, les ensembles «A» et «B» ne sont en aucun cas liés les uns aux autres. Dans l'ensemble «A» - photos aléatoires, dans l'ensemble «B» - bandes dessinées aléatoires.
Il est inutile de comparer une fausse bande dessinée avec une bande dessinée aléatoire de l'ensemble «B», car cela dupliquera au moins la fonction du critique, sans parler du résultat imprévisible.
C'est là que l'architecture CycleGAN vient à la rescousse.
En bref, il s'agit d'une paire GAN, dont la première convertit l'image de la catégorie "A" (par exemple, une photo) en catégorie "B" (par exemple, une bande dessinée), et la seconde en arrière, de la catégorie "B" à la catégorie "A".
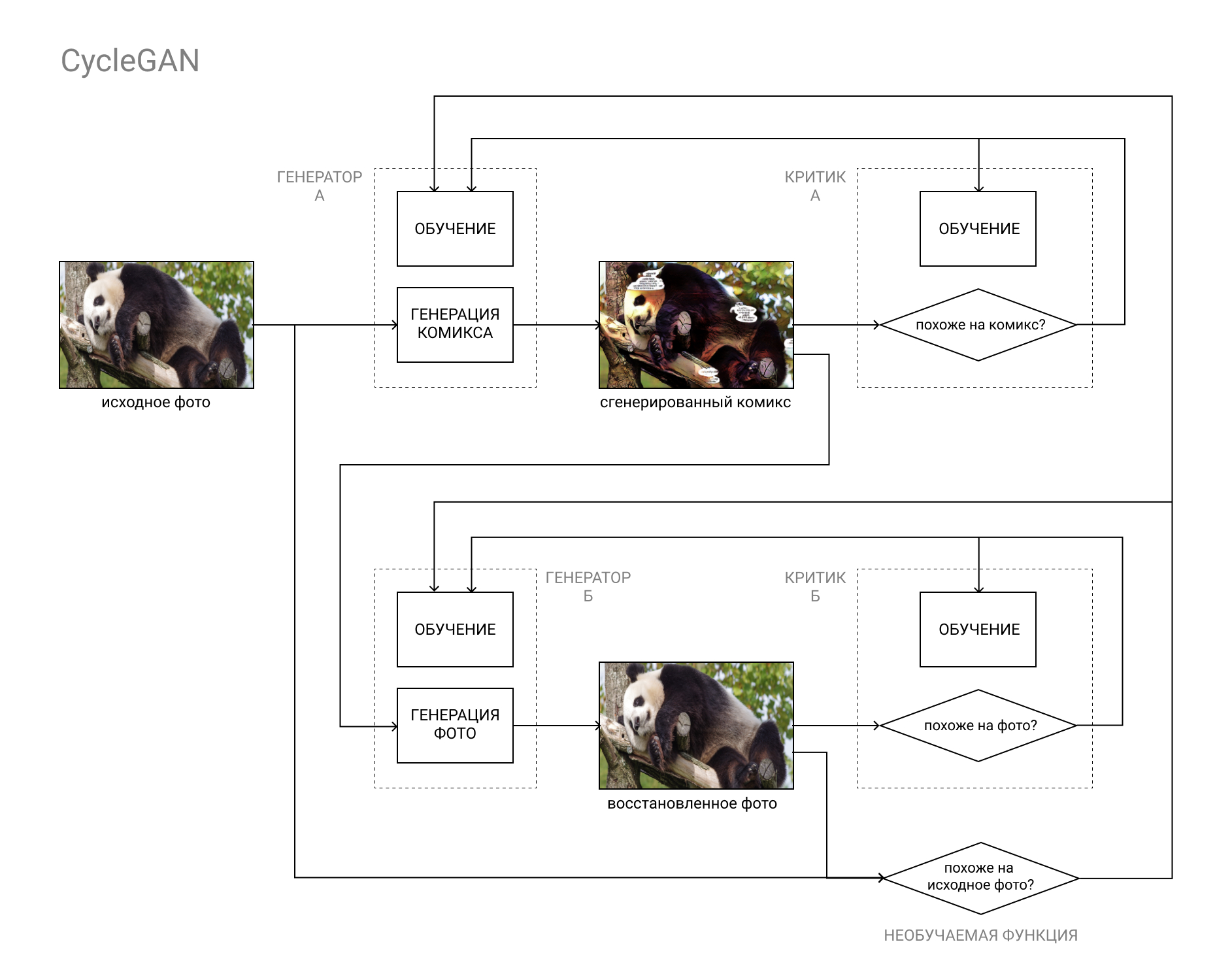
Les modèles sont formés à la fois sur la base de la comparaison de la photo originale avec celle restaurée (à la suite du cycle "A" - "B" - "A", "photo-bande dessinée-photo), et des données des critiques, comme dans un GAN ordinaire.
Cela permet de remplir les deux parties de notre tâche: générer une bande dessinée indiscernable des autres bandes dessinées, et en même temps similaire à la photo originale.
Installation et vérification du modèle
Pour mettre en œuvre notre plan astucieux, nous avons besoin de:
- Carte graphique compatible CUDA avec 8 Go de RAM
- Linux OS
- Miniconda / Anaconda avec Python 3.5+
Les cartes vidéo avec moins de 8 Go de RAM peuvent également fonctionner si vous évoquez les paramètres. Cela fonctionnera également sur Windows, mais plus lentement, j'ai eu une différence d'au moins 1,5-2 fois.
Si vous n'avez pas de GPU avec prise en charge CUDA, ou si vous êtes trop paresseux pour tout configurer, vous pouvez toujours utiliser Google Colab. S'il y a un nombre suffisant de personnes qui le souhaitent, je vais remplir le didacticiel et savoir comment monter tout ce qui suit dans un cloud Google.Miniconda peut être prise iciInstructions d'installationAprès avoir installé Anaconda / Miniconda (ci-après dénommé conda), créez un nouvel environnement pour nos expériences et activez-le:
(Les utilisateurs de Windows doivent d'abord démarrer Anaconda Prompt à partir du menu Démarrer)conda create --name cyclegan conda activate cyclegan
Désormais, tous les packages seront installés dans l'environnement actif sans affecter le reste de l'environnement. Cela est pratique si vous avez besoin de certaines combinaisons de versions de divers packages, par exemple, si vous utilisez l'ancien code de quelqu'un d'autre et que vous devez installer des packages obsolètes sans gâcher votre vie et votre environnement de travail principal.
Ensuite, suivez simplement les instructions README.MD de la distribution:
Enregistrez la distribution CycleGAN:
(ou téléchargez simplement l'archive depuis GitHub) git clone https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix cd pytorch-CycleGAN-and-pix2pix
Installez les packages nécessaires:
conda install numpy pyyaml mkl mkl-include setuptools cmake cffi typing conda install pytorch torchvision -c pytorch conda install visdom dominate -c conda-forge
Téléchargez l'ensemble de données fini et le modèle correspondant:
bash ./datasets/download_cyclegan_dataset.sh horse2zebra bash ./scripts/download_cyclegan_model.sh horse2zebra
Faites attention aux photos qui se trouvent dans le jeu de données téléchargé.
Si vous ouvrez les fichiers de script du paragraphe précédent, vous pouvez voir qu'il existe d'autres jeux de données et modèles prêts à l'emploi pour eux.
Enfin, testez le modèle sur l'ensemble de données téléchargé:
python test.py --dataroot datasets/horse2zebra/testA --name horse2zebra_pretrained --model test --no_dropout
Les résultats seront enregistrés dans le dossier / results / horse2zebra_pretrained /
Création d'un ensemble d'entraînement
Une étape tout aussi importante après avoir choisi l'architecture du futur modèle (et recherché une implémentation terminée sur github) est de compiler un ensemble de données, ou un ensemble de données, sur lequel nous formerons et testerons notre modèle.
Presque tout dépend des données que nous utilisons. Par exemple, UGATIT pour le bot selfie2anime a été formé sur les selfies féminines et les visages féminins de l'anime. Par conséquent, avec des photos masculines, elle se comporte au moins drôle, remplaçant les hommes barbus brutaux par des petites filles avec un col haut. Sur la photo, votre humble serviteur après avoir appris qu'il regardait un anime.

Comme vous l'avez déjà compris, il vaut la peine de sélectionner les photos / bandes dessinées que vous souhaitez utiliser en entrée et en sortie. Envisagez-vous de traiter des selfies - ajoutez des selfies et des gros plans de visages de bandes dessinées, des photos de bâtiments - ajoutez des photos de bâtiments et des pages de bandes dessinées avec des bâtiments.
Comme exemples de photos, j'ai utilisé
DIV2K et
Urban100 , aromatisés avec des photos d'étoiles Google pour améliorer la diversité.
J'ai pris des bandes dessinées de l'univers Marvel, la page entière, jetant des publicités et des annonces où l'image ne ressemble pas à une bande dessinée. Je ne peux pas joindre le lien pour des raisons évidentes, mais à la demande de Marvel Comics, vous pouvez facilement trouver des options numérisées sur vos sites préférés avec des bandes dessinées, si vous savez ce que je veux dire.
Il est important de faire attention au dessin, il diffère selon les séries et le jeu de couleurs.

J'ai eu beaucoup de deadpool et spiderman, donc la peau devient très rouge.
Une liste incomplète d'autres jeux de données publics peut être trouvée
ici .
La structure des dossiers dans notre ensemble de données doit être la suivante:
selfie2comics
├── trainA
├── trainB
├── testA
└── testB
trainA - nos photos (environ 1000pcs)
testA - quelques photos pour les tests de modèles (30 pièces suffiront)
trainB - nos bandes dessinées (environ 1000 pcs.)
testB - bandes dessinées pour les tests (30pcs.)
Il est conseillé de placer le jeu de données sur un SSD, si possible.
C'est tout pour aujourd'hui, dans le prochain numéro, nous commencerons à former le modèle et à obtenir les premiers résultats!
Assurez-vous d'écrire si quelque chose ne va pas avec vous, cela aidera à améliorer le leadership et à soulager la souffrance des lecteurs suivants.
Si vous avez déjà essayé de former le modèle, n'hésitez pas à partager les résultats dans les commentaires. A très bientôt!
⇨ Partie suivante