Dans presque tous les jeux informatiques modernes, la présence d'un moteur physique est une condition préalable. Drapeaux et lapins flottant au vent, bombardés de balles - tout cela nécessite une bonne exécution. Et, bien sûr, même si tous les héros ne portent pas d'imperméables ... mais ceux qui portent ont vraiment besoin d'une simulation adéquate de tissu flottant.

Néanmoins, la modélisation physique complète de telles interactions devient souvent impossible, car elle est beaucoup plus lente que nécessaire pour les jeux en temps réel. Cet article propose une nouvelle méthode de modélisation qui peut accélérer les simulations physiques, les rendre 300 à 5000 fois plus rapides. Son but est d'essayer d'enseigner à un réseau neuronal de simuler des forces physiques.
Les progrès dans le développement de moteurs physiques sont déterminés à la fois par la puissance de calcul croissante des équipements techniques et par le développement de méthodes de modélisation rapides et stables. Ces méthodes incluent, par exemple, la modélisation en découpant l'espace en sous-espaces et les approches basées sur les données - c'est-à-dire basées sur les données. Les premiers ne fonctionnent que dans un sous-espace réduit ou comprimé, où seules quelques formes de déformations sont prises en compte. Pour les grands projets, cela peut entraîner une augmentation significative des exigences techniques. Les approches basées sur les données utilisent la mémoire du système et les données précalculées qui y sont stockées, ce qui réduit ces exigences.
Nous examinons ici une approche qui combine les deux méthodes: de cette manière, elle vise à capitaliser sur les forces des deux. Une telle méthode peut être interprétée de deux manières: soit comme une méthode de modélisation sous-espace paramétrée par un réseau de neurones, soit comme une méthode DD basée sur la modélisation sous-spatiale pour construire un support simulé compressé.
Son essence est la suivante: nous collectons d'abord des données de simulation de haute précision à l'aide de
Maya nCloth , puis nous calculons le sous-espace linéaire en utilisant
la méthode des composants principaux (PCA) . Dans l'étape suivante, nous utilisons l'apprentissage automatique basé sur le modèle de réseau de neurones classique et notre nouvelle méthodologie, après quoi nous introduisons le modèle entraîné dans un algorithme interactif avec plusieurs optimisations, comme un algorithme de décompression efficace par un GPU et une méthode pour approximer les normales des sommets.
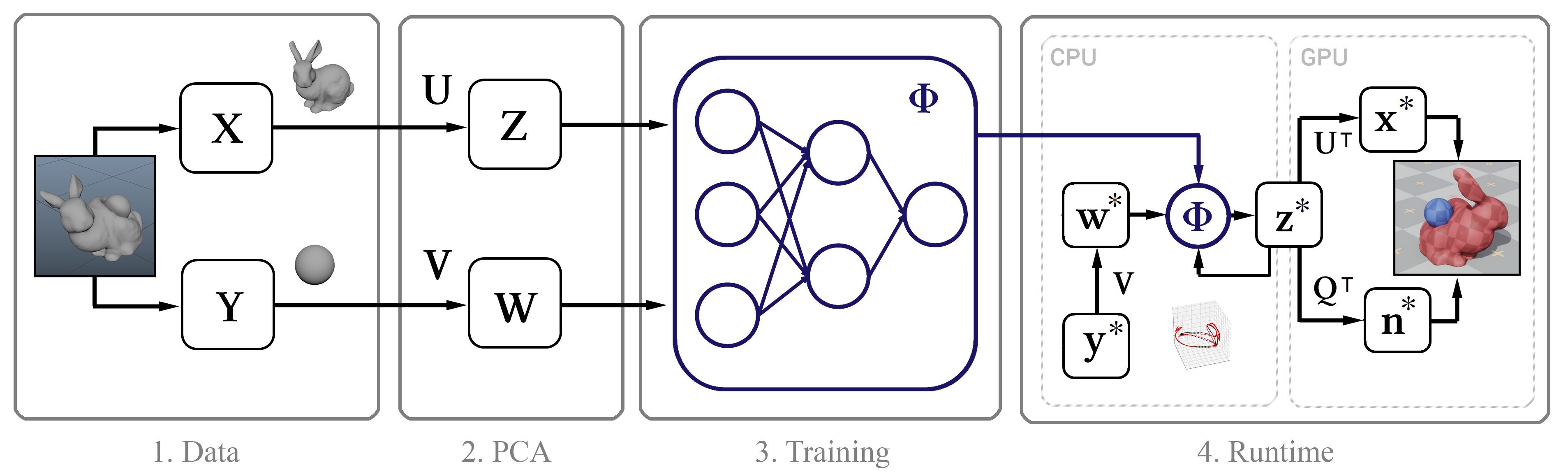 Figure 1. Le schéma structurel de la méthode
Figure 1. Le schéma structurel de la méthodeDonnées d'entraînement
De manière générale, la seule entrée pour cette méthode est les horodatages bruts des positions image par image des sommets de l'objet. Ensuite, nous décrivons le processus de collecte de ces données.
Nous effectuons la simulation dans Maya nCloth, capturant des données à une vitesse de 60 images par seconde, avec 5 ou 20 sous-étapes et 10 ou 25 itérations limites, selon la stabilité de la simulation. Pour les tissus, prenez un modèle de T-shirt avec une légère augmentation du poids du matériau et de sa résistance à l'étirement, et pour les objets déformables, du caoutchouc dur à frottement réduit. Nous effectuons des collisions externes en heurtant des triangles de géométrie externe, des auto-collisions - des sommets avec des sommets pour le tissu et des triangles avec des triangles pour le caoutchouc. Dans tous les cas, nous utilisons une épaisseur de collision assez importante - de l'ordre de 5 cm - pour assurer la stabilité du modèle et éviter les pincements et déchirures du tissu.
Tableau 1. Paramètres des objets modélisés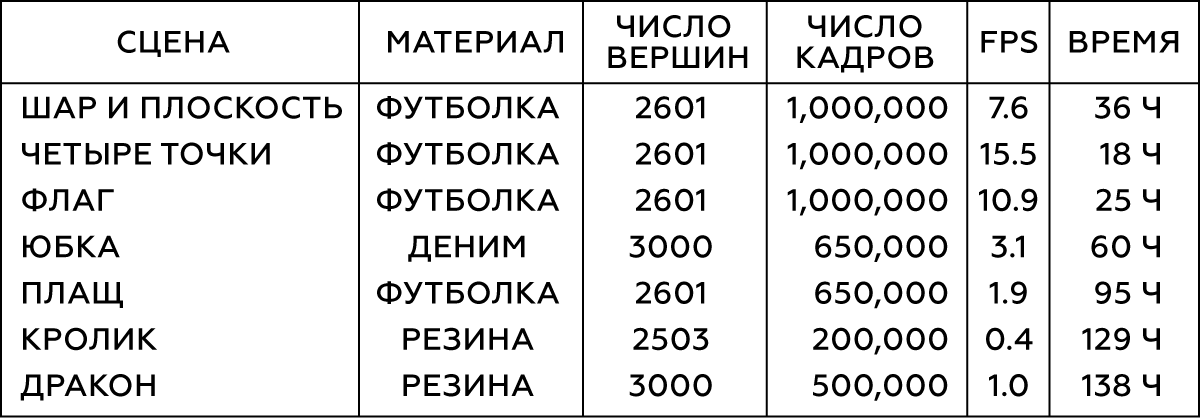
Pour différents types d'interaction d'objets simples (par exemple, des sphères), nous générerons leur mouvement de manière aléatoire en recadrant des coordonnées aléatoires à des moments aléatoires. Pour simuler l'interaction des tissus avec un personnage, nous utilisons une base de données de capture de mouvement de 6,5 × 10
5 images, qui sont une grande animation. Une fois la simulation terminée, nous vérifions le résultat et excluons les trames présentant un comportement instable ou médiocre. Pour la scène avec la jupe, on retire les mains du personnage, car elles se croisent souvent avec la géométrie du maillage des jambes et sont désormais insignifiantes.
 Figure 2. Les deux premières scènes du tableau
Figure 2. Les deux premières scènes du tableauHabituellement, nous avons besoin de 10
5 -10
6 images de données d'entraînement. D'après notre expérience, dans la plupart des cas, 10
5 images suffisent pour les tests, tandis que les meilleurs résultats sont obtenus avec 10
6 images.
La formation
Ensuite, nous parlerons du processus d'apprentissage automatique: du paramétrage dans notre réseau de neurones, de l'architecture du réseau et directement de la technique elle-même.
Paramétrisation
Afin d'obtenir un ensemble de données d'apprentissage, nous collectons les coordonnées des sommets de chaque image
t dans un vecteur
x t , puis combinons ces vecteurs image par image dans une grande matrice X. Cette matrice décrit les états de l'objet modélisé. De plus, il faut avoir une idée de l'état des objets externes dans chaque trame. Pour les objets simples (tels que les balles), vous pouvez utiliser leurs coordonnées tridimensionnelles, tandis que l'état des modèles complexes (personnage) est décrit par la position de chaque articulation par rapport au point de référence: dans le cas d'une jupe, un tel support sera l'articulation de la hanche, dans le cas d'une cape - le cou. Pour les objets avec un système de référence en mouvement, la position de la Terre par rapport à elle doit être prise en compte: alors notre système connaîtra la direction de la gravité, ainsi que sa vitesse linéaire, son accélération, sa vitesse de rotation et son accélération de rotation. Pour le drapeau, nous prendrons en compte la vitesse et la direction du vent. En conséquence, pour chaque objet, nous obtenons un grand vecteur qui décrit l'état de l'objet externe, et tous ces vecteurs sont également combinés dans la matrice Y.
Maintenant, nous appliquons l'ACP à la matrice X et Y, et utilisons les matrices de transformation résultantes Z et W pour construire l'image du sous-espace. Si la procédure PCA nécessite trop de mémoire, échantillonnez d'abord nos données.
La compression PCA entraîne inévitablement une perte de détails, en particulier pour les objets présentant de nombreuses conditions potentielles, tels que des plis fins de tissu. Cependant, si le sous-espace se compose de 256 vecteurs de base, cela aide généralement à préserver la plupart des détails. Vous trouverez ci-dessous des animations de la physique standard de la cape et des modèles avec 256, 128 et 64 vecteurs de base, respectivement.
 Figure 3. Comparaison du modèle de contrôle (standard) avec les modèles obtenus par notre méthode dans des espaces avec des bases de dimensions différentes
Figure 3. Comparaison du modèle de contrôle (standard) avec les modèles obtenus par notre méthode dans des espaces avec des bases de dimensions différentesSource et modèle étendu
Il était nécessaire de développer un modèle qui pourrait prédire l'état des vecteurs du modèle dans les futures trames. Et comme les objets modélisés sont généralement caractérisés par une inertie ayant tendance à un certain état de repos moyen (après la procédure PCA, l'objet prend un tel état à des valeurs nulles), un bon modèle initial serait l'expression représentée par la ligne 9 de l'algorithme de la figure 4. Ici, α et β sont les paramètres du modèle, ⊙ est un produit éclaté. Les valeurs de ces paramètres seront obtenues à partir des données sources en résolvant individuellement l'
équation des moindres carrés linéaires pour α et β:
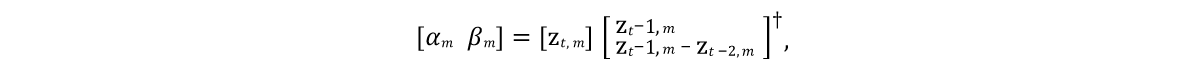
Voici † la
transformation pseudoinverse de la matrice .
Étant donné qu'une telle prédiction n'est qu'une approximation très approximative et ne prend pas en compte l'influence des objets externes w, elle ne sera évidemment pas en mesure de modéliser avec précision les données d'apprentissage. Par conséquent, nous formons le réseau neuronal Φ d'approximation des effets résiduels du modèle conformément à la 11e ligne de l'algorithme. Ici, nous paramétrons un
réseau de neurones à distribution directe standard avec 10 couches, pour chaque couche (sauf la sortie) en utilisant la fonction d'activation
ReLU . En excluant les couches d'entrée et de sortie, nous avons défini le nombre d'unités cachées sur chaque couche restante égal à une fois et demie la taille des données PCA, ce qui a conduit à un bon compromis entre l'espace occupé sur le disque dur et les performances.
 Figure 4. Algorithme d'apprentissage du réseau neuronal
Figure 4. Algorithme d'apprentissage du réseau neuronalFormation au réseau de neurones
Une façon standard de former un réseau de neurones serait d'itérer sur l'ensemble des données et d'entraîner le réseau à faire des prédictions pour chaque trame. Bien sûr, une telle approche entraînera une faible erreur d'apprentissage, mais le retour dans une telle prédiction entraînera un comportement instable de son résultat. Par conséquent, pour assurer une prédiction stable à long terme, notre algorithme utilise la
méthode de rétro-propagation des erreurs tout au long de la procédure d'intégration.
En général, cela fonctionne comme ceci: à partir d'une petite fenêtre de données d'apprentissage
z et
w, nous prenons les deux premières images
z 0 et
z 1 et leur ajoutons un peu de bruit
r 0 ,
r 1 , afin de perturber légèrement le parcours d'apprentissage. Ensuite, pour prédire les trames suivantes, nous exécutons l'algorithme plusieurs fois, en revenant aux résultats précédents des prédictions à chaque nouveau pas de temps. Dès que nous obtenons une prédiction de la trajectoire entière, nous calculons l'erreur de coordonnées moyenne, puis la transmettons à l'optimiseur AmsGrad en utilisant les dérivées automatiques calculées à l'aide de TensorFlow.
Nous allons répéter cet algorithme sur des mini-échantillons de 16 images, en utilisant des fenêtres superposées de 32 images, pendant 100 époques ou jusqu'à ce que la formation converge. Nous utilisons le taux d'apprentissage de 0,0001, le coefficient d'atténuation du taux d'apprentissage de 0,999 et l'écart-type du bruit calculé à partir des trois premières composantes de l'espace PCA. Cette formation dure de 10 à 48 heures, selon la complexité de l'installation et la taille des données PCA.
 Figure 5. Comparaison visuelle de la jupe de référence et de celle que notre réseau de neurones a appris à construire
Figure 5. Comparaison visuelle de la jupe de référence et de celle que notre réseau de neurones a appris à construireImplémentation du système
Nous décrirons en détail la mise en œuvre de notre méthode dans un environnement interactif, y compris l'évaluation d'un réseau de neurones, le calcul des normales aux surfaces des objets pour le rendu, et comment nous traitons les intersections visibles.
Application de rendu
Nous rendons les modèles résultants dans une simple application 3D interactive écrite en C ++ et DirectX: nous implémentons à nouveau les pré-processus et les opérations du réseau neuronal en code C ++ monothread et chargeons les poids de réseau binaires obtenus lors de notre formation. Ensuite, nous appliquons quelques optimisations simples pour l'estimation de réseau, en particulier, la réutilisation de tampons de mémoire et de données matricielles éparses, ce qui devient possible grâce à la présence de zéro unités cachées obtenues grâce à la fonction d'activation ReLU.
Décompression GPU
Envoyez des données d'état z compressées au GPU et décompressez-les pour un rendu supplémentaire. À cette fin, nous utilisons un shader de calcul simple, qui calcule pour chaque sommet de l'objet le produit ponctuel du vecteur z et les trois premières lignes de la matrice U
T correspondant aux coordonnées de ce sommet, après quoi nous ajoutons la valeur moyenne
x µ . Cette approche présente deux avantages par rapport à la
méthode de décompression
naïve . Premièrement, le parallélisme du GPU accélère considérablement le calcul du vecteur d'état du modèle, ce qui peut prendre jusqu'à 1 ms. Deuxièmement, il réduit le temps de transfert de données entre le central et le GPU d'un ordre de grandeur, ce qui est particulièrement important pour les plates-formes sur lesquelles le transfert de l'état entier de l'objet entier est trop lent.
Vertex Normal Prediction
Pendant le rendu, il ne suffit pas d'avoir accès uniquement aux coordonnées des sommets - des informations sur les déformations de leurs normales sont également nécessaires. Habituellement, dans un moteur physique, omettez ce calcul ou effectuez un recalcul naïf image par image des normales avec leur redistribution ultérieure aux sommets voisins. Cela peut s'avérer inefficace, car la mise en œuvre de base du processeur central, en plus des coûts de décompression et de transfert de données, nécessite encore 150 μs pour une telle procédure. Et bien que ce calcul puisse être effectué sur le GPU, il s'avère plus difficile à mettre en œuvre en raison de la nécessité d'opérations parallèles.
Au lieu de cela, nous effectuons une régression linéaire de l'état du sous-espace vers des vecteurs normaux à l'état complet sur le shader GPU. Connaissant les valeurs des normales des sommets dans chaque trame, nous calculons la matrice Q, qui représente le mieux la représentation du sous-espace sur les normales des sommets.
Étant donné que la prédiction des normales dans notre méthode n'a jamais été présentée auparavant, il n'y a aucune garantie que cette approche sera exacte, mais en pratique, elle s'est avérée très bonne, comme le montre la figure ci-dessous.
 Figure 6. Comparaison des modèles calculés par notre méthode et de la référence (vérité terrain), ainsi que la différence entre eux
Figure 6. Comparaison des modèles calculés par notre méthode et de la référence (vérité terrain), ainsi que la différence entre euxCombat d'intersection
Notre réseau de neurones apprend à effectuer efficacement des collisions, cependant, en raison d'inexactitudes dans les prédictions et d'erreurs causées par la compression du sous-espace, des intersections peuvent se produire entre des objets externes et des objets simulés. De plus, comme nous reportons le calcul de l'état complet de la scène jusqu'au tout début du rendu, il n'y a aucun moyen de résoudre efficacement ces problèmes à l'avance. Par conséquent, pour maintenir des performances élevées, l'élimination de ces intersections est nécessaire lors du rendu.
Nous avons trouvé une solution simple et efficace à cela, consistant dans le fait que des sommets se croisant sont projetés sur la surface des primitives dont nous constituons le personnage. Cette projection est facile à faire sur le GPU en utilisant le même shader de calcul qui décompresse le tissu et calcule l'ombrage normal.
Donc, tout d'abord, nous allons composer le personnage à partir des objets proxy connectés aux sommets avec différents rayons initiaux et finaux, après quoi nous transférerons des informations sur les coordonnées et les rayons de ces objets au shader de calcul. Encore une fois, vérifiez les coordonnées de chaque sommet pour l'intersection avec l'objet proxy correspondant et, si c'est le cas, projetez ce sommet sur la surface de l'objet proxy. On ne corrige donc que la position du sommet, sans toucher à la normale elle-même, afin de ne pas endommager l'ombrage.
Cette approche supprimera les petites intersections visibles d'objets, à condition que les erreurs de déplacement du sommet ne soient pas si importantes que la projection se trouve du côté opposé de l'objet proxy correspondant.
 Figure 7. Modèle de caractères composé d'objets proxy et résultats de l'élimination des intersections visibles à l'aide de notre méthode: avant et après
Figure 7. Modèle de caractères composé d'objets proxy et résultats de l'élimination des intersections visibles à l'aide de notre méthode: avant et aprèsAnalyse des résultats
Ainsi, nos scènes de test incluent:
, .
- 16 , 120 240 .
 8. 16 . Party time!
8. 16 . Party time!, , , , .
, PCA. , , , .
 9. , , –
9. , , –Exécution
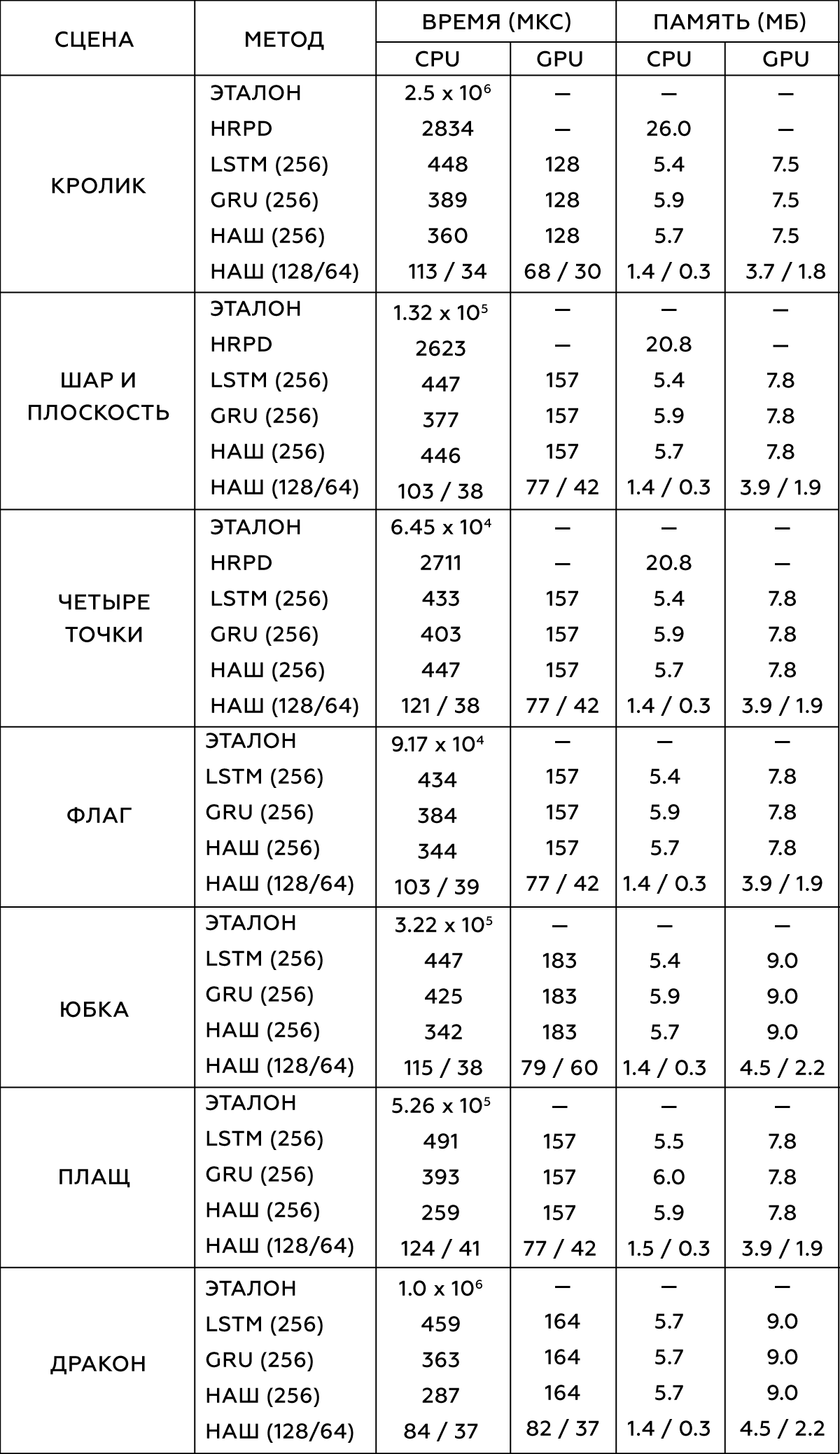
― , . , . 300-5000 , . ,
- (HRPD) ,
(LSTM) (GRU) .
, . Intel Xeon E5-1650 3.5 GHz GeForce GTX 1080 Titan.
2.
, , . , .
data-driven , . , , , , , . , , ― , .
, , , .
, . data-driven , ― , . , , , . , , , .
, . .
, , , . , , ― , . -, , , - . .
, , , , . , , , , ― , , . .
.
 10. vs : choose your fighter
10. vs : choose your fighter