Par type d'activité, il faut faire face à des situations où un développeur écrit une requête et pense que "la
base est intelligente, elle peut tout gérer! "
Dans certains cas (en partie par ignorance des capacités de la base de données, en partie par optimisations prématurées), cette approche conduit à l'apparition de «Frankenstein».
Je vais d'abord donner un exemple d'une telle requête:
Afin d'évaluer objectivement la qualité de la demande, créons un ensemble de données arbitraire:
CREATE TABLE tbl AS SELECT (random() * 1000)::integer key_a , (random() * 1000)::integer key_b , (random() * 10000)::integer fld1 , (random() * 10000)::integer fld2 FROM generate_series(1, 10000); CREATE INDEX ON tbl(key_a, key_b);
Il s'avère que la
lecture des données elles- mêmes a
pris moins d'un quart du temps d' exécution
total des requêtes:
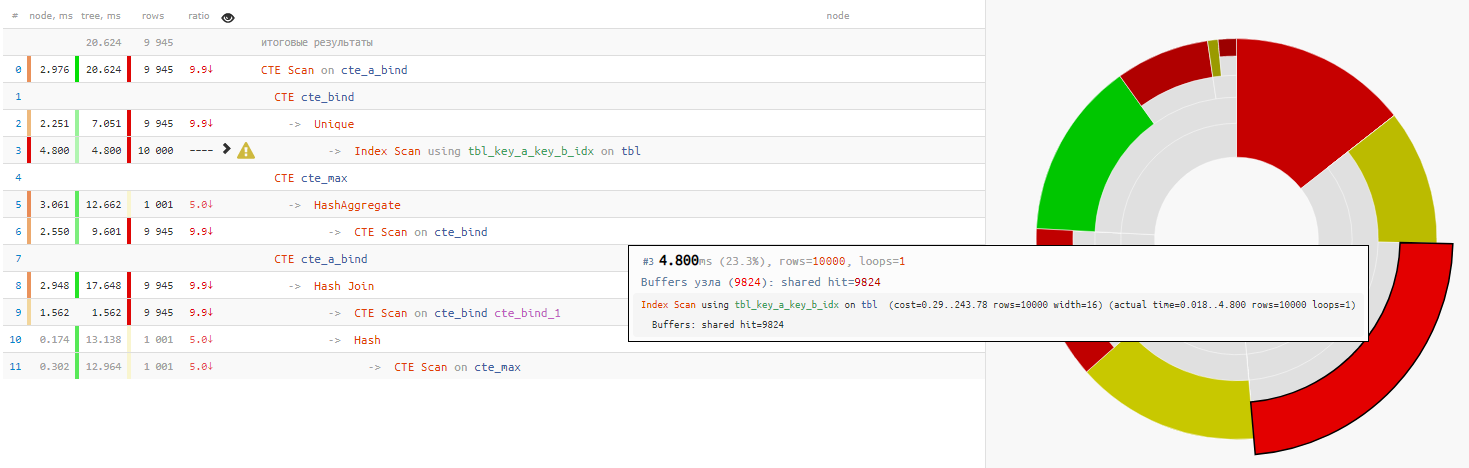 [regardez expliquez.tensor.ru]
[regardez expliquez.tensor.ru]Démonter par os
Nous examinerons attentivement la demande et nous serons perplexes:
- Pourquoi est AVEC récursif ici, s'il n'y a pas de CTE récursif?
- Pourquoi grouper les valeurs min / max dans un CTE séparé si elles sont quand même encore attachées à l'échantillon d'origine?
+ 25% du temps - Pourquoi à la fin utiliser des relectures du CTE précédent via le 'SELECT * FROM' inconditionnel?
+ 14% du temps
Dans ce cas, nous avons été très chanceux que Hash Join ait été choisi pour la connexion, et non Nested Loop, car alors nous n'obtiendrions pas un seul passage CTE Scan, mais 10K!
un peu sur CTE ScanIci, nous devons rappeler que CTE Scan est un analogue de Seq Scan - c'est-à-dire, pas d'indexation, mais seulement une recherche exhaustive, qui nécessiterait 10K x 0,3ms = 3000ms pour les cycles cte_max ou 1K x 1,5ms = 1500ms pour les cycles cte_bind !
En fait, que vouliez-vous obtenir en conséquence?
Ouais, c'est généralement ce genre de question qu'il visite quelque part à la 5ème minute de l'analyse des requêtes "à trois étages".Nous voulions que chaque paire de clés unique supprime
min / max du groupe par key_a .
Nous allons donc utiliser les
fonctions de fenêtre pour cela:
SELECT DISTINCT ON(key_a, key_b) key_a a , key_b b , max(fld1) OVER(w) bind_fld1 , min(fld2) OVER(w) bind_fld2 FROM tbl WINDOW w AS (PARTITION BY key_a);
 [regardez expliquez.tensor.ru]
[regardez expliquez.tensor.ru]Étant donné que la lecture des données dans les deux versions prend environ 4 à 5 ms également, tout notre gain de temps de
-32% est une
charge pure
supprimée du processeur de base , si une telle demande est effectuée assez souvent.
En général, vous ne devez pas forcer la base à «arrondir l'usure, le carré».