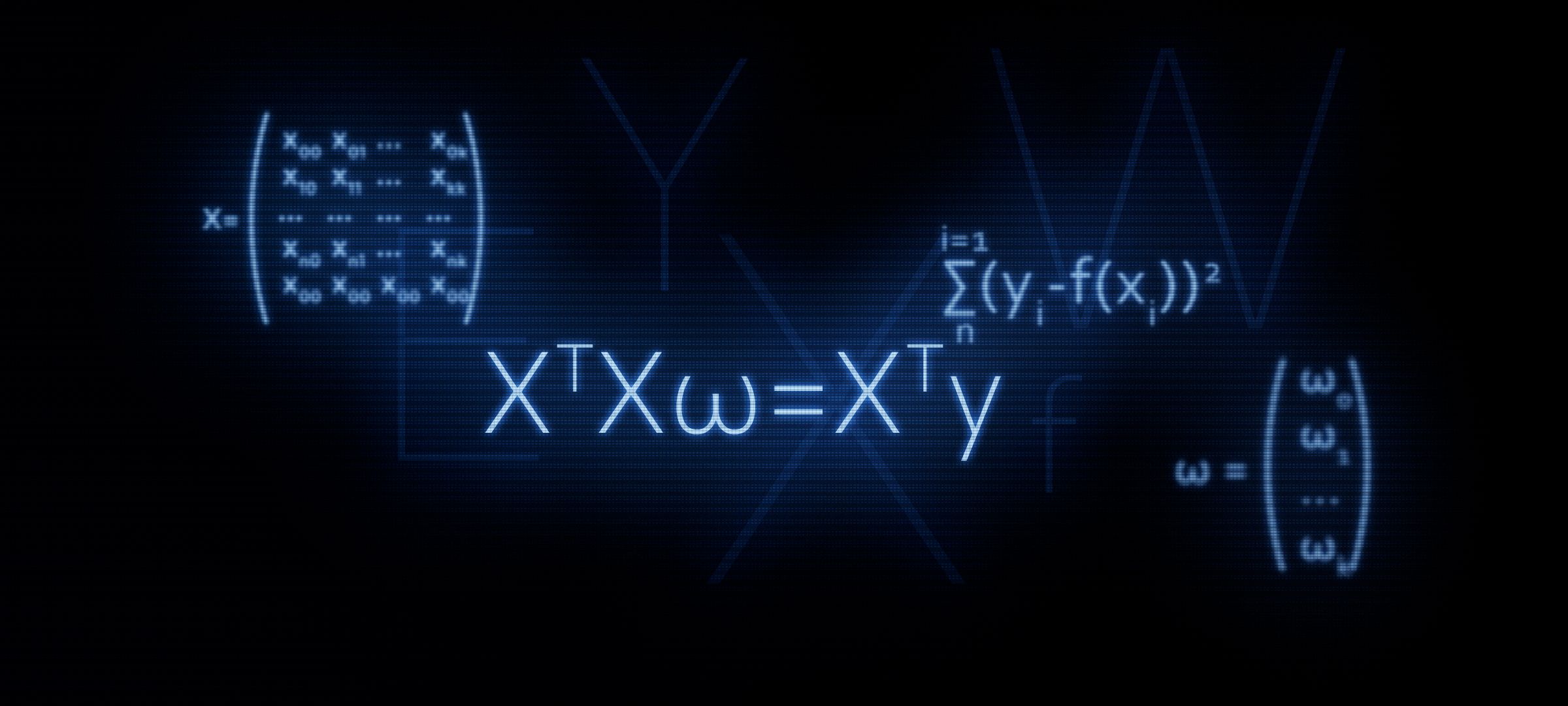
Le but de cet article est de fournir un support aux débutants. Dans l'
article précédent, nous avons examiné sur les doigts trois méthodes pour résoudre l'équation de régression linéaire: solution analytique, descente de gradient, descente de gradient stochastique. Ensuite, pour la solution analytique, nous avons appliqué la formule
XTX vecw=XT vecy . Dans cet article, comme il ressort du titre, nous justifierons l'utilisation de cette formule, ou en d'autres termes, nous la dériverons indépendamment.
Pourquoi il est logique d'accorder une attention accrue à la formule
XTX vecw=XT vecy ?
C'est avec l'équation matricielle que dans la plupart des cas, la connaissance de la régression linéaire commence. Dans le même temps, les calculs détaillés de la façon dont la formule a été dérivée sont rares.
Par exemple, dans les cours de machine learning Yandex, lorsque les étudiants sont initiés à la régularisation, ils suggèrent d'utiliser les fonctions de la bibliothèque
sklearn , alors
qu'aucun mot n'est mentionné sur la représentation matricielle de l'algorithme. C'est à ce moment que certains auditeurs peuvent vouloir comprendre ce problème plus en détail - écrire du code sans utiliser de fonctions prédéfinies. Et pour cela, nous devons d'abord présenter l'équation avec le régularisateur sous forme matricielle. Cet article permettra à ceux qui souhaitent maîtriser de telles compétences. Commençons.
Référence
Cibles
Nous avons un certain nombre de valeurs cibles. Par exemple, l'objectif peut être le prix d'un actif: pétrole, or, blé, dollar, etc. Dans le même temps, par un certain nombre de valeurs de l'indicateur cible, nous entendons le nombre d'observations. De telles observations peuvent être, par exemple, les prix mensuels du pétrole pour l'année, c'est-à-dire que nous aurons 12 valeurs cibles. Nous commençons à introduire la notation. Nous désignons chaque valeur cible comme
yi . Total que nous avons
n observations, ce qui signifie que nous pouvons imaginer nos observations comme
y1,y2,y3...yn .
Régresseurs
Nous supposons qu'il existe des facteurs qui expliquent dans une certaine mesure les valeurs de l'indicateur cible. Par exemple, le taux de change de la paire dollar / rouble est fortement influencé par le prix du pétrole, le taux de la Fed, etc. Ces facteurs sont appelés régresseurs. En même temps, chaque valeur de l'indicateur cible doit correspondre à la valeur du régresseur, c'est-à-dire que si nous avons 12 cibles pour chaque mois en 2018, nous devons également avoir 12 régresseurs pour la même période. Notons les valeurs de chaque régresseur par
xi:x1,x2,x3...xn . Soit dans notre cas il y a
k régresseurs (c.-à-d.
k facteurs qui influencent la valeur de la cible). Nos régresseurs peuvent donc être représentés comme suit: pour le 1er régresseur (par exemple, le prix du pétrole):
x11,x12,x13...x1n , pour le 2e régresseur (par exemple, le taux Fed):
x21,x22,x23...x2n pour
k e "régresseur:
xk1,xk2,xk3...xknDépendance des cibles sur les régresseurs
Supposons une dépendance cible
yi des régresseurs "
i -th "observation peut être exprimée par l'équation de régression linéaire de la forme:
f(w,xi)=w0+w1x1i+...+wkxki
où
xi - "
i e "valeur de régresseur de 1 à
n ,
k - le nombre de régresseurs de 1 à
kw - des coefficients angulaires qui représentent le montant par lequel l'indicateur cible calculé changera en moyenne lorsque le régresseur change.
En d'autres termes, nous sommes pour tout le monde (sauf
w0 ) du régresseur nous déterminons «notre» coefficient
w , puis multipliez les coefficients par les valeurs des régresseurs "
i -th "observation, on obtient ainsi une certaine approximation"
i e "cible.
Par conséquent, nous devons sélectionner ces coefficients
w pour lequel les valeurs de notre fonction d'approximation
f(w,xi) sera situé le plus près possible des valeurs des cibles.
Estimation de la qualité de la fonction d'approximation
Nous déterminerons l'estimation de la qualité de la fonction d'approximation par la méthode des moindres carrés. Dans ce cas, la fonction d'évaluation de la qualité prendra la forme suivante:
Err= sum limitsni=1(yi−f(xi))2 rightarrowmin
Nous devons choisir ces valeurs des coefficients $ w $ pour lesquels la valeur
Err sera le plus petit.
Nous traduisons l'équation sous forme de matrice
Vue vectorielle
Tout d'abord, pour vous faciliter la vie, vous devez faire attention à l'équation de régression linéaire et noter que le premier coefficient
w0 pas multiplié par aucun régresseur. De plus, lorsque nous traduisons les données sous forme de matrice, la circonstance ci-dessus compliquera sérieusement les calculs. À cet égard, il est proposé d'introduire un autre régresseur pour le premier coefficient
w0 et égal à un. Ou plutôt, chacun "
i la "valeur" de ce régresseur à égaler à l'unité - parce que multiplié par l'unité, rien ne changera en termes de résultat des calculs, et du point de vue des règles pour le produit des matrices, notre tourment sera considérablement réduit.
Maintenant, pendant un certain temps, pour simplifier le matériel, supposons que nous n'en avons qu'un "
i e "observation. Ensuite, imaginez les valeurs des régresseurs"
i e observation comme vecteur
vecxi . Vecteur
vecxi a une dimension
(k fois1) c'est
k lignes et 1 colonne:
vecxi= beginpmatrixx0ix1i...xki endpmatrix qquad
Les coefficients souhaités peuvent être représentés comme un vecteur
vecw avoir une dimension
(k fois1) :
vecw= beginpmatrixw0w1...wk endpmatrix qquad
L'équation de régression linéaire pour "
i -ème "observation prendra la forme:
f(w,xi)= vecxiT vecw
La fonction d'évaluation de la qualité du modèle linéaire prendra la forme:
Err= sum limitsni=1(yi− vecxiT vecw)2 rightarrowmin
Notez que conformément aux règles de multiplication matricielle, nous devions transposer le vecteur
vecxi .
Représentation matricielle
À la suite de la multiplication des vecteurs, nous obtenons le nombre:
(1 timesk) centerdot(k times1)=1 times1 comme prévu. Ce nombre est approximatif "
i -th "cible. Mais nous devons approximer non pas une valeur de la cible, mais toutes. Pour ce faire, nous écrivons tout"
i régresseurs matriciels
X . La matrice résultante a la dimension
(n foisk) :
$$ afficher $$ X = \ begin {pmatrix} x_ {00} & x_ {01} & ... & x_ {0k} \\ x_ {10} & x_ {11} & ... & x_ {1k} \\ ... & ... & ... & ... \\ x_ {n0} & x_ {n1} & ... & x_ {nk} \ end {pmatrix} \ qquad $$ display $$
Maintenant, l'équation de régression linéaire prendra la forme:
f(w,X)=X vecw
Indiquent les valeurs des indicateurs cibles (tous
yi ) par vecteur
vecy dimension
(n fois1) :
vecy= beginpmatrixy0y1...yn endpmatrix qquad
Maintenant, nous pouvons écrire dans le format matriciel l'équation pour évaluer la qualité d'un modèle linéaire:
Err=(X vecw− vecy)2 rightarrowmin
En fait, à partir de cette formule, nous obtenons en outre la formule connue de nous
XTXw=XTyComment cela se fait-il? Les crochets sont ouverts, la différenciation est effectuée, les expressions résultantes sont transformées, etc., et c'est ce que nous allons faire maintenant.
Transformations matricielles
Développez les crochets
(X vecw− vecy)2=(X vecw− vecy)T(X vecw− vecy)=(X vecw)TX vecw− vecyTX vecw−(X vecw)T vecy+ vecyT vecyPréparer une équation pour la différenciation
Pour ce faire, nous effectuons quelques transformations. Dans les calculs ultérieurs, il nous sera plus commode que le vecteur
vecwT sera présenté au début de chaque travail dans l'équation.
Conversion 1
vecyTX vecw=(X vecw)T vecy= vecwTXT vecyComment est-ce arrivé? Pour répondre à cette question, il suffit de regarder les tailles des matrices multipliées et de voir qu'en sortie on obtient un nombre ou autre
const .
Nous écrivons les dimensions des expressions matricielles.
vecyTX vecw:(1 timesn) centerdot(n timesk) centerdot(k times1)=(1 times1)=const(X vecw)T vecy:((n timesk) centerdot(k times1))T centerdot(n times1)=(1 timesn) centerdot(n times1)=(1 times1)=const vecwTXT vecy:(1 timesk) centerdot(k timesn) centerdot(n times1)=(1 times1)=constConversion 2
(X vecw)TX vecw= vecwTXTX vecwNous écrivons de manière similaire à la transformation 1
(X vecw)TX vecw:((n timesk) centerdot(k times1))T centerdot(n timesk) centerdot(k times1)=(1 fois1)=const vecwTXTX vecw:(1 timesk) centerdot(k timesn) centerdot(n timesk) centerdot(k times1)=(1 fois1)=constEn sortie, nous obtenons une équation que nous devons différencier:
Err= vecwTXTX vecw−2 vecwTXT vecy+ vecyT vecyNous différencions la fonction d'évaluation de la qualité du modèle
Différencier par vecteur
vecw :
fracd( vecwTXTX vecw−2 vecwTXT vecy+ vecyT vecy)d vecw
( vecwTXTX vecw)′−(2 vecwTXT vecy)′+( vecyT vecy)′=02XTX vecw−2XT vecy+0=0XTX vecw=XT vecyQuestions pourquoi
( vecyT vecy)′=0 ne devrait pas être, mais les opérations pour déterminer les dérivées dans les deux autres expressions, nous analyserons plus en détail.
Différenciation 1
Nous révélons la différenciation:
fracd( vecwTXTX vecw)d vecw=2XTX vecwAfin de déterminer la dérivée d'une matrice ou d'un vecteur, vous devez voir ce qu'ils ont à l'intérieur. Nous regardons:
$ inline $ \ vec {w} ^ T = \ begin {pmatrix} w_0 & w_1 & ... & w_k \ end {pmatrix} \ qquad $ inline $
vecw= beginpmatrixw0w1...wk endpmatrix qquad$ en ligne $ X ^ T = \ begin {pmatrix} x_ {00} & x_ {10} & ... & x_ {n0} \\ x_ {01} & x_ {11} & ... & x_ {n1} \\ ... & ... & ... & ... \\ x_ {0k} & x_ {1k} & ... & x_ {nk} \ end {pmatrix} \ qquad $ inline $
$ inline $ X = \ begin {pmatrix} x_ {00} & x_ {01} & ... & x_ {0k} \\ x_ {10} & x_ {11} & ... & x_ {1k} \\ ... & ... & ... & ... \\ x_ {n0} & x_ {n1} & ... & x_ {nk} \ end {pmatrix} \ qquad $ inline $
Indique le produit des matrices
XTX à travers la matrice
A . Matrix
A carré et de plus, il est symétrique. Ces propriétés nous seront utiles plus loin, souvenez-vous-en. Matrix
A a une dimension
(k foisk) :
$ inline $ A = \ begin {pmatrix} a_ {00} & a_ {01} & ... & a_ {0k} \\ a_ {10} & a_ {11} & ... & a_ {1k} \\ ... & ... & ... & ... \\ a_ {k0} & a_ {k1} & ... & a_ {kk} \ end {pmatrix} \ qquad $ inline $
Maintenant, notre tâche est de multiplier correctement les vecteurs par la matrice et de ne pas obtenir «deux fois deux cinq», nous allons donc nous concentrer et être extrêmement prudents.
$ inline $ \ vec {w} ^ TA \ vec {w} = \ begin {pmatrix} w_0 & w_1 & ... & w_k \ end {pmatrix} \ qquad \ times \ begin {pmatrix} a_ {00} & a_ {01} & ... & a_ {0k} \\ a_ {10} & a_ {11} & ... & a_ {1k} \\ ... & ... & ... & ... \ \ a_ {k0} & a_ {k1} & ... & a_ {kk} \ end {pmatrix} \ qquad \ times \ begin {pmatrix} w_0 \\ w_1 \\ ... \\ w_k \ end {pmatrix} \ qquad = $ inline $
$ inline $ = \ begin {pmatrix} w_0a_ {00} + w_1a_ {10} + ... + w_ka_ {k0} & ... & w_0a_ {0k} + w_1a_ {1k} + ... + w_ka_ {kk} \ end {pmatrix} \ times \ begin {pmatrix} w_0 \\ w_1 \\ ... \\ w_k \ end {pmatrix} \ qquad = $ inline $
= beginpmatrix(w0a00+w1a10+...+wkak0)w0 mkern10mu+ mkern10mu... mkern10mu+ mkern10mu(w0a0k+w1a1k+...+wkakk)wk endpmatrix==w20a00+w1a10w0+wkak0w0 mkern10mu+ mkern10mu... mkern10mu+ mkern10muw0a0kwk+w1a1kwk+...+w2kakkCependant, nous avons eu une expression complexe! En fait, nous avons obtenu un nombre - un scalaire. Et maintenant, déjà vraiment, nous passons à la différenciation. Il faut trouver la dérivée de l'expression obtenue pour chaque coefficient
w0w1...wk et obtenir le vecteur de dimension à la sortie
(k fois1) . Au cas où, je décrirai les procédures des actions:
1) différencier par
wo nous obtenons:
2w0a00+w1a10+w2a20+...+wkak0+a01w1+a02w2+...+a0kwk2) différencier par
w1 nous obtenons:
w0a01+2w1a11+w2a21+...+wkak1+a10w0+a12w2+...+a1kwk3) différencier par
wk nous obtenons:
w0a0k+w1a1k+w2a2k+...+w(k−1)a(k−1)k+ak0w0+ak1w1+ak2w2+...+2wkakkEn sortie, le vecteur de taille promis
(k fois1) :
beginpmatrix2w0a00+w1a10+w2a20+...+wkak0+a01w1+a02w2+...+a0kwkw0a01+2w1a11+w2a21+...+wkak1+a10w0+a12w2+...+a1kwk.........w0a0k+w1a1k+w2a2k+...+w(k−1)a(k−1)k+ak0w0+ak1w1+ak2w2+...+2wkakk endpmatrix
Si vous regardez de plus près le vecteur, vous remarquerez que les éléments gauche et droit correspondants du vecteur peuvent être regroupés de telle sorte que, par conséquent, le vecteur peut être distingué du vecteur présenté
vecw la taille
(k fois1) . Par exemple
w1a10 (élément gauche de la ligne supérieure du vecteur)
+a01w1 (l'élément droit de la ligne supérieure du vecteur) peut être représenté comme
w1(a10+a01) et
w2a20+a02w2 - comment
w2(a20+a02) etc. sur chaque ligne. Groupe:
beginpmatrix2w0a00+w1(a10+a01)+w2(a20+a02)+...+wk(ak0+a0k)w0(a01+a10)+2w1a11+w2(a21+a12)+...+wk(ak1+a1k).........w0(a0k+ak0)+w1(a1k+ak1)+w2(a2k+ak2)+...+2wkakk endpmatrix
Sortez le vecteur
vecw et en sortie on obtient:
$$ afficher $$ \ begin {pmatrix} 2a_ {00} & a_ {10} + a_ {01} & a_ {20} + a_ {02} & ... & a_ {k0} + a_ {0k} \\ a_ {01} + a_ {10} & 2a_ {11} & a_ {21} + a_ {12} & ... & a_ {k1} + a_ {1k} \\ ... & ... & .. . & ... & ... \\ ... & ... & ... & ... & ... \\ ... & ... & ... & ... & .. . \\ a_ {0k} + a_ {k0} & a_ {1k} + a_ {k1} & a_ {2k} + a_ {k2} & ... & 2a_ {kk} \ end {pmatrix} \ times \ begin {pmatrix} w_0 \\ w_1 \\ ... \\ ... \\ ... \\ w_k \ end {pmatrix} \ qquad $$ display $$
Voyons maintenant la matrice résultante. Une matrice est la somme de deux matrices
A+AT :
$$ afficher $$ \ begin {pmatrix} a_ {00} & a_ {01} & a_ {02} & ... & a_ {0k} \\ a_ {10} & a_ {11} & a_ {12} & ... & a_ {1k} \\ ... & ... & ... & ... & ... \\ a_ {k0} & a_ {k1} & a_ {k2} & ... & a_ {kk} \ end {pmatrix} + \ begin {pmatrix} a_ {00} & a_ {10} & a_ {20} & ... & a_ {k0} \\ a_ {01} & a_ {11} & a_ {21} & ... & a_ {k1} \\ ... & ... & ... & ... & ... \\ a_ {0k} & a_ {1k} & a_ {2k} & ... & a_ {kk} \ end {pmatrix} \ qquad $$ display $$
Rappelons qu'un peu plus tôt, nous avons noté une propriété importante de la matrice
A - il est symétrique. Sur la base de cette propriété, nous pouvons affirmer avec confiance que l'expression
A+AT est égal
2A . Ceci est facile à vérifier en révélant le produit matrice par élément
XTX . Nous ne le ferons pas ici, ceux qui le souhaitent peuvent effectuer eux-mêmes un contrôle.
Revenons à notre expression. Après nos transformations, il s'est avéré que nous voulions le voir:
(A+AT) times beginpmatrixw0w1...wk endpmatrix qquad=2A vecw=2XTX vecw
Nous avons donc fait face à la première différenciation. Nous passons à la deuxième expression.
Différenciation 2
fracd(2 vecwTXT vecy)d vecw=2XT vecyAllons le long des sentiers battus. Il sera beaucoup plus court que le précédent, alors n'allez pas loin de l'écran.
Nous révélons les vecteurs et la matrice par élément:
$ inline $ \ vec {w} ^ T = \ begin {pmatrix} w_0 & w_1 & ... & w_k \ end {pmatrix} \ qquad $ inline $
$ en ligne $ X ^ T = \ begin {pmatrix} x_ {00} & x_ {10} & ... & x_ {n0} \\ x_ {01} & x_ {11} & ... & x_ {n1} \\ ... & ... & ... & ... \\ x_ {0k} & x_ {1k} & ... & x_ {nk} \ end {pmatrix} \ qquad $ inline $
vecy= beginpmatrixy0y1...yn endpmatrix qquadPendant un certain temps, nous supprimons le diable des calculs - il ne joue pas un grand rôle, puis nous le remettrons à sa place. Multipliez les vecteurs par la matrice. Tout d'abord, nous multiplions la matrice
XT sur le vecteur
vecy , ici nous n'avons aucune restriction. Obtenez le vecteur de taille
(k fois1) :
beginpmatrixx00y0+x10y1+...+xn0ynx01y0+x11y1+...+xn1yn...x0ky0+x1ky1+...+xnkyn endpmatrix qquad
Effectuez l'action suivante - multipliez le vecteur
vecw au vecteur résultant. En sortie, un nombre nous attendra:
beginpmatrixw0(x00y0+x10y1+...+xn0yn)+w1(x01y0+x11y1+...+xn1yn) mkern10mu+ mkern10mu... mkern10mu+ mkern10muwk(x0ky0+x1ky1+...+xnkyn) endpmatrix qquad
Nous le différencions ensuite. En sortie on obtient un vecteur de dimension
(k fois1) :
beginpmatrixx00y0+x10y1+...+xn0ynx01y0+x11y1+...+xn1yn...x0ky0+x1ky1+...+xnkyn endpmatrix qquad
Ressemble-t-il à quelque chose? D'accord! C'est le produit de la matrice.
XT sur le vecteur
vecy .
Ainsi, la deuxième différenciation s'est terminée avec succès.
Au lieu d'une conclusion
Nous savons maintenant comment l’égalité est née.
XTX vecw=XT vecy .
Enfin, nous décrivons un moyen rapide de transformer les principales formules.
Estimez la qualité du modèle selon la méthode des moindres carrés: sum limitsni=1(yi−f(xi))2 mkern20mu= mkern20mu sum limitsni=1(yi− vecxiT vecw)2==(X vecw− vecy)2 mkern20mu= mkern20mu(X vecw− vecy)T(X vecw− vecy) mkern20mu= mkern20mu vecwTXTX vecw−2 vecwTXT vecy+ vecyT vecyOn différencie l'expression résultante: fracd( vecwTXTX vecw−2 vecwTXT vecy+ vecyT vecy)d vecw=2XTX vecw−2XT vecy=0XTX vecw=XT vecy leftarrow Travaux antérieurs de l'auteur - «Nous résolvons l'équation de la régression linéaire simple» rightarrow Le prochain travail de l'auteur - "Chewing Logistic Regression"Littérature
Sources Internet:1)
habr.com/en/post/2785132)
habr.com/ru/company/ods/blog/3220763)
habr.com/en/post/3070044)
nabatchikov.com/blog/view/matrix_derManuels, collections de tâches:1) Notes de cours sur les mathématiques supérieures: cours complet / D.T. Écrit - 4e éd. - M .: Iris Press, 2006
2) Analyse de régression appliquée / N. Draper, G. Smith - 2e éd. - M .: Finance and Statistics, 1986 (traduit de l'anglais)
3) Tâches pour résoudre les équations matricielles:
function-x.ru/matrix_equations.html
mathprofi.ru/deistviya_s_matricami.html