
Ne soyez pas surpris, mais la deuxième rubrique de cet article a généré un réseau de neurones, ou plutôt l'algorithme de sammarisation. Et qu'est-ce que la sammarisation?
C'est l'un des
défis clés et classiques
du traitement automatique du langage naturel (NLP) . Il consiste à créer un algorithme qui prend du texte en entrée et en édite une version abrégée. De plus, la structure correcte (correspondant aux normes de la langue) y est préservée et l'idée principale du texte est correctement transmise.
De tels algorithmes sont largement utilisés dans l'industrie. Par exemple, ils sont utiles pour les moteurs de recherche: en utilisant la réduction de texte, vous pouvez facilement comprendre si l'idée principale d'un site ou d'un document est en corrélation avec une requête de recherche. Ils sont utilisés pour rechercher des informations pertinentes dans un large flux de données multimédias et pour filtrer les informations inutiles. La réduction de texte aide à la recherche financière, à l'analyse des contrats juridiques, à l'annotation des articles scientifiques et bien plus encore. Soit dit en passant, l'algorithme de sammarisation a généré toutes les sous-rubriques pour ce message.
À ma grande surprise, sur Habré il y avait très peu d'articles sur la sammarisation, j'ai donc décidé de partager mes recherches et résultats dans ce sens. Cette année, j'ai participé à l'hippodrome lors de la conférence
Dialogue et expérimenté avec des générateurs de titres pour des informations et des poèmes utilisant des réseaux de neurones. Dans cet article, je vais d'abord brièvement passer en revue la partie théorique de la sammarisation, puis je donnerai des exemples avec la génération de titres, je vous dirai quelles difficultés les modèles ont lors de la réduction du texte et comment ces modèles peuvent être améliorés pour obtenir de meilleurs titres.
Vous trouverez ci-dessous un exemple de news et son titre de référence d'origine. Les modèles dont je vais parler s'entraîneront à générer des en-têtes avec cet exemple:

Secrets pour couper l'architecture de texte seq2seq
Il existe deux types de méthodes de réduction de texte:
- Extractive . Elle consiste à trouver les parties les plus informatives du texte et à en construire l'annotation correcte pour la langue donnée. Ce groupe de méthodes utilise uniquement les mots qui se trouvent dans le texte source.
- Résumé Il consiste à extraire des liens sémantiques du texte, tout en tenant compte des dépendances linguistiques. Avec la sammarisation abstraite, les mots d'annotation ne sont pas sélectionnés dans le texte abrégé, mais dans le dictionnaire (la liste des mots pour une langue donnée) - reformulant ainsi l'idée principale.
La seconde approche implique que l'algorithme doit prendre en compte les dépendances du langage, reformuler et généraliser. Il souhaite également avoir une certaine connaissance du monde réel afin d'éviter les erreurs factuelles. Pendant longtemps, cela a été considéré comme une tâche difficile, et les chercheurs n'ont pas pu obtenir une solution de haute qualité - un texte grammaticalement correct tout en préservant l'idée principale. C'est pourquoi dans le passé, la plupart des algorithmes étaient basés sur une approche d'extraction, car la sélection de morceaux entiers de texte et leur transfert vers le résultat vous permet de maintenir le même niveau d'alphabétisation que la source.
Mais c'était avant le boom des réseaux de neurones et sa pénétration imminente dans la PNL. En 2014, l'architecture
seq2seq a été
introduite avec un mécanisme d'attention qui peut lire certaines séquences de texte et en générer d'autres (ce qui dépend de ce que le modèle a appris à produire) (
article de Sutskever et al.). En 2016, une telle architecture a été appliquée directement à la solution du problème de la sammarisation, réalisant ainsi une approche abstraite et obtenant un résultat comparable à ce qu'une personne compétente pourrait écrire (
article de Nallapati et al., 2016;
article de Rush et al., 2015; ) Comment fonctionne cette architecture?
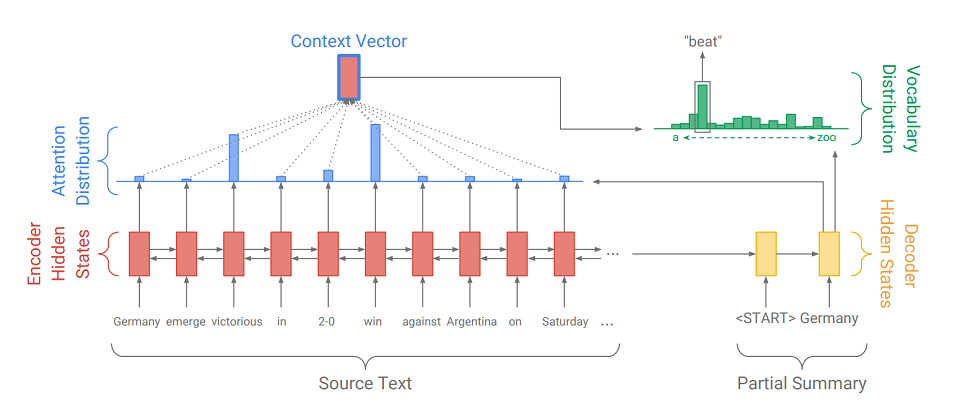
Seq2Seq se compose de deux parties:
- Encodeur (Encoder) - un RNN bidirectionnel, qui est utilisé pour lire la séquence d'entrée, c'est-à-dire qui traite séquentiellement les éléments d'entrée simultanément de gauche à droite et de droite à gauche pour mieux prendre en compte le contexte.
- décodeur (décodeur) - RNN unidirectionnel, qui produit séquentiellement et par élément une séquence de sortie.
Premièrement, la séquence d'entrée est traduite en une séquence d'intégration (en bref, l'intégration est une représentation concise d'un mot en tant que vecteur). Les plongements passent ensuite par le réseau récursif de l'encodeur. Ainsi, pour chaque mot, nous obtenons les états cachés de l'encodeur (
indiqués par des rectangles rouges dans le diagramme ), et ils contiennent des informations sur le jeton lui-même et son contexte, ce qui nous permet de prendre en compte les connexions linguistiques entre les mots.
Après avoir traité l'entrée, l'encodeur transfère son dernier état caché (qui contient des informations compressées sur le texte entier) au décodeur, qui reçoit un jeton spécial

et crée le premier mot de la séquence de sortie (
dans l'image, c'est «Allemagne» ). Ensuite, il prend cycliquement sa sortie précédente, la transmet à lui-même et affiche à nouveau l'élément de sortie suivant (
donc après «Allemagne» vient «beat», et après «beat» vient le mot suivant, etc. ). Ceci est répété jusqu'à ce qu'un jeton spécial soit émis
. Cela signifie la fin de la génération.
Pour afficher l'élément suivant, le décodeur, tout comme l'encodeur, convertit le jeton d'entrée en intégration, fait un pas dans le réseau récursif et reçoit le prochain état caché du décodeur (
rectangles jaunes dans le diagramme ). Ensuite, en utilisant une couche entièrement connectée, une distribution de probabilité est obtenue pour tous les mots à partir d'un dictionnaire de modèles précompilé. Les mots les plus probables seront déduits par le modèle.
L'ajout d'
un mécanisme d'attention aide le décodeur à mieux utiliser les informations d'entrée. Le mécanisme à chaque étape de la génération détermine la
distribution dite d'
attention (les
rectangles bleus sur la figure sont l'ensemble des poids correspondant aux éléments de la séquence d'origine, la somme des poids est 1, tous les poids> = 0 ), et à partir de cela, il reçoit la somme pondérée de tous les états cachés de l'encodeur, formant ainsi vecteur de contexte (
le diagramme montre un rectangle rouge avec un trait bleu ). Ce vecteur concatène avec l'incorporation du mot d'entrée du décodeur au stade du calcul de l'état latent et avec l'état latent lui-même au stade de la détermination du mot suivant. Ainsi, à chaque étape de la sortie, le modèle peut déterminer quels états du codeur sont les plus importants pour lui pour le moment. En d'autres termes, il décide du contexte dans lequel les mots d'entrée doivent être le plus pris en compte (par exemple, dans l'image, affichant le mot "beat", le mécanisme d'attention accorde un poids important aux jetons "victorieux" et "win", et les autres sont proches de zéro).
Étant donné que la génération d'en-têtes est également l'une des tâches de la sammarisation, uniquement avec le minimum de sortie possible (1-12 mots), j'ai décidé d'appliquer également
seq2seq avec le mécanisme d'attention pour notre cas. Nous formons un tel système sur des textes avec des titres, par exemple, sur l'actualité. De plus, il est conseillé au stade de la formation de soumettre au décodeur non pas sa propre sortie, mais les mots du vrai titre (forçage de l'enseignant), facilitant ainsi la vie de lui-même et du modèle. En tant que fonction d'erreur, nous utilisons la fonction de perte d'entropie croisée standard, montrant à quel point les distributions de probabilité du mot de sortie et du mot de l'en-tête réel sont proches:
Lorsque vous utilisez le modèle entraîné, nous utilisons la recherche de rayons pour trouver une séquence de mots plus probable que l'utilisation de l'algorithme gourmand. Pour ce faire, à chaque étape de la génération, nous ne dérivons pas le mot le plus probable, mais en même temps regardons la largeur de faisceau des séquences de mots les plus probables. Quand ils se terminent (chacun se termine le
), nous dérivons la séquence la plus probable.
Evolution du modèle
L'un des problèmes du modèle sur seq2seq est l'impossibilité de citer des mots qui ne sont pas dans le dictionnaire. Par exemple, le modèle n'a aucune chance de déduire "obamacare" de l'article ci-dessus. Il en va de même pour:
- noms et prénoms rares
- nouveaux termes
- des mots dans d'autres langues,
- différentes paires de mots reliés par un trait d'union (en tant que "sénateur républicain")
- et d'autres modèles.
Bien sûr, vous pouvez étendre le dictionnaire, mais cela augmente considérablement le nombre de paramètres entraînés. De plus, il est nécessaire de fournir un grand nombre de documents dans lesquels se trouvent ces mots rares, afin que le générateur apprenne à les utiliser de manière qualitative.
Une autre solution plus élégante à ce problème a été présentée dans un article de 2017 - «
Get to the Point: Summarization with Pointer-Generator Networks » (Abigail See et al.). Elle ajoute un nouveau mécanisme à notre modèle -
un mécanisme de pointeur, qui peut sélectionner des mots dans le texte source et les insérer directement dans la séquence générée. Si le texte contient OOV (
hors vocabulaire - un mot qui n'est pas dans le dictionnaire ), alors le modèle, s'il le juge nécessaire, peut isoler OOV et l'insérer à la sortie. Un tel système est appelé
« pointeur-générateur» (pointeur-générateur ou pg) et est une synthèse de deux approches de la sammarisation. Elle-même peut décider à quelle étape elle doit être abstraite et à quelle étape - extraire. Comment elle le fait, nous allons le découvrir maintenant.
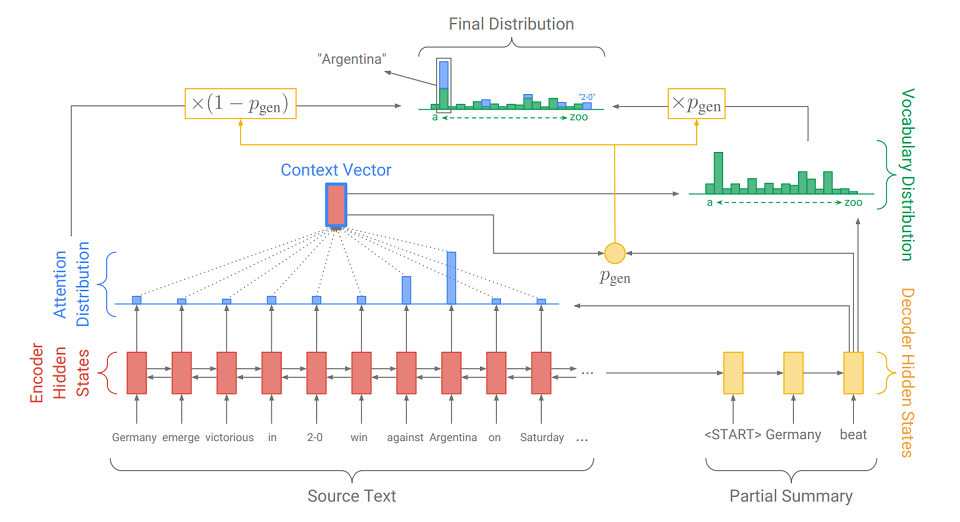
La principale différence par rapport au modèle seq2seq habituel est l'action supplémentaire sur laquelle p
gen est calculé - la probabilité de génération. Cela se fait à l'aide de l'état caché du décodeur et du vecteur de contexte. La signification de l'action supplémentaire est simple. Plus p
gen est proche de 1, plus il est probable que le modèle émette un mot de son dictionnaire en utilisant la génération abstraite. Plus p
gen est proche de 0, plus il est probable que le générateur extrait le mot du texte, guidé par la répartition de l'attention obtenue précédemment. La distribution de probabilité finale des résultats du mot est la somme de la distribution de probabilité générée des mots (dans laquelle il n'y a pas d'OOV) multipliée par p
gen et de la distribution de l'attention (dans laquelle OOV est, par exemple, «2-0» dans l'image) multipliée par (1 - p
gen ).

En plus du mécanisme de pointage, l'article présente
un mécanisme de couverture , qui permet d'éviter de répéter des mots. Je l'ai également expérimenté, mais je n'ai pas remarqué d'amélioration significative de la qualité des en-têtes - ce n'est pas vraiment nécessaire. Très probablement, cela est dû aux spécificités de la tâche: comme il est nécessaire de sortir un petit nombre de mots, le générateur n'a tout simplement pas le temps de se répéter. Mais pour d'autres tâches de sammarisation, par exemple, l'annotation, cela peut être utile. Si vous êtes intéressé, vous pouvez en lire plus dans l'
article original.

Grande variété de mots russes
Une autre façon d'améliorer la qualité des en-têtes de sortie consiste à prétraiter correctement la séquence d'entrée. En plus de l'élimination évidente des caractères majuscules, j'ai également essayé de convertir les mots du texte source en paires de styles et d'inflexions (c'est-à-dire les fondations et les terminaisons). Pour le fractionnement, utilisez le Porter Stemmer.
Nous marquons toutes les inflexions avec le symbole «+» au début pour les distinguer des autres jetons. Nous considérons chaque sujet et inflexion comme un mot distinct et apprenons d'eux de la même manière que dans les mots. Autrement dit, nous obtenons d'eux des plongements et en dérivons une séquence (également décomposée en fondements et terminaisons) qui peut être facilement transformée en mots.
Une telle conversion est très utile lorsque vous travaillez avec des langues morphologiquement riches comme le russe. Au lieu de compiler d'énormes dictionnaires avec une grande variété de formes de mots russes, vous pouvez vous limiter à un grand nombre de tiges de ces mots (elles sont plusieurs fois plus petites que le nombre de formes de mots) et à un très petit ensemble de terminaisons (j'ai eu beaucoup de 450 inflexions). Ainsi, nous permettons au modèle de travailler plus facilement avec cette «richesse» et en même temps nous n'augmentons pas la complexité de l'architecture et le nombre de paramètres.

J'ai également essayé d'utiliser la transformation lemme + gramme. Autrement dit, à partir de chaque mot avant le traitement, vous pouvez obtenir sa forme initiale et sa signification grammaticale en utilisant le package pymorphy (par exemple, "was"
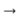
"Être" et "VERBE | impf | passé | chanter | femn"). Ainsi, j'ai obtenu une paire de séquences parallèles (dans l'une - les formes initiales, dans l'autre - les valeurs grammaticales). Pour chaque type de séquence, j'ai compilé mes plongements, que j'ai ensuite concaténés et soumis au pipeline décrit précédemment. Dans ce document, le décodeur n'a pas appris à donner un mot, mais un lemme et des grammes. Mais un tel système n'a pas apporté d'améliorations visibles par rapport à pg sur le sujet. C'était peut-être une architecture trop simple pour travailler avec des valeurs grammaticales, et cela valait la peine de créer un classificateur distinct pour chaque catégorie grammaticale dans la sortie. Mais je n'ai pas expérimenté de modèles tels ou plus complexes.
J'ai expérimenté un autre ajout à l'architecture originale du générateur de pointeur, qui, cependant, ne s'applique pas au prétraitement. Il s'agit d'une augmentation du nombre de couches (jusqu'à 3) des réseaux récursifs du codeur et du décodeur. L'augmentation de la profondeur du réseau récurrent peut améliorer la qualité de la sortie, car l'état caché des dernières couches peut contenir des informations sur une sous-séquence d'entrée beaucoup plus longue que l'état caché d'un RNN monocouche. Cela permet de prendre en compte les connexions sémantiques étendues complexes entre les éléments de la séquence d'entrée. Certes, cela coûte une augmentation significative du nombre de paramètres du modèle et complique l'apprentissage.

Expériences de générateur d'en-tête
Toutes mes expériences sur les générateurs de titres peuvent être divisées en deux types: les expériences avec des articles de presse et des versets. Je vais vous en parler dans l'ordre.
Expériences
Lorsque je travaillais avec des actualités, j'utilisais des modèles tels que seq2seq, pg, pg avec des tiges et des inflexions - monocouche et trois couches. J'ai également considéré les modèles qui fonctionnent avec des grammes, mais tout ce que je voulais en dire, je l'ai déjà décrit ci-dessus. Je dois dire tout de suite que tous les pg décrits dans cette section utilisaient le mécanisme de revêtement, bien que son influence sur le résultat soit douteuse (car sans elle ce n'était pas bien pire).
Je me suis entraîné sur l'ensemble de données RIA Novosti, qui a été fourni par l'agence de presse Rossiya Segodnya pour mener une piste de génération de titres lors de la conférence Dialog. L'ensemble de données contient 1 003 869 articles de presse publiés de janvier 2010 à décembre 2014.
Tous les modèles étudiés ont utilisé les mêmes plongements (128), vocabulaire (100k) et états latents (256) et formés pour le même nombre d'époques. Par conséquent, seuls des changements qualitatifs dans l'architecture ou dans le prétraitement pourraient affecter le résultat.
Les modèles adaptés pour travailler avec du texte prétraité donnent de meilleurs résultats que les modèles qui fonctionnent avec des mots. Un pg à trois couches qui utilise des informations sur les sujets et les inflexions fonctionne mieux. Lorsque vous utilisez un pg, l'amélioration attendue de la qualité des en-têtes par rapport à seq2seq apparaît également, ce qui indique l'utilisation préférée du pointeur lors de la génération des en-têtes. Voici un exemple de fonctionnement de tous les modèles:
En regardant les en-têtes générés, nous pouvons distinguer les problèmes suivants des modèles à l'étude:
- Les modèles utilisent souvent des formes de mots irrégulières. Les modèles à tiges (comme dans l'exemple ci-dessus) sont plus soulagés de cet inconvénient;
- Tous les modèles, à l'exception de ceux qui fonctionnent avec des thèmes, peuvent produire des en-têtes qui semblent incomplets ou des conceptions étranges qui ne sont pas dans le langage (comme dans l'exemple ci-dessus);
- Tous les modèles étudiés confondent souvent les personnes décrites, substituent des dates incorrectes ou utilisent des mots pas tout à fait appropriés.


Expériences avec des versets
Étant donné que la pg à trois couches avec les thèmes présente le moins d'inexactitudes dans les en-têtes générés, c'est le modèle que j'ai choisi pour les expériences avec les versets. Je lui ai enseigné le cas, composé de 6 millions de poèmes russes du site "stihi.ru". Ils comprennent l'amour (environ la moitié des versets sont consacrés à ce sujet), civique (environ un quart), la poésie urbaine et paysagère. Période d'écriture: janvier 2014 - mai 2019. Je vais donner des exemples de rubriques générées pour les vers:
Le modèle s'est avéré être principalement extrait: presque tous les en-têtes sont une seule ligne, souvent extraite de la première ou de la dernière strophe. Dans des cas exceptionnels, le modèle peut générer des mots qui ne sont pas dans le poème. Cela est dû au fait qu'un très grand nombre de textes dans le cas ont vraiment une des lignes comme nom.
En conclusion, je dirai que le générateur d'index, qui fonctionne sur les tiges et utilise un décodeur et un encodeur monocouche, a pris la deuxième place sur la
piste de la
compétition pour générer des titres pour des articles d'actualité à la conférence scientifique Dialogue sur la linguistique informatique. L'organisateur principal de cette conférence est ABBYY, la société est engagée dans la recherche dans presque tous les domaines modernes du traitement automatique du langage naturel.
Enfin, je vous propose un peu interactif: envoyez des nouvelles dans les commentaires, et voyez quels en-têtes le réseau neuronal va générer pour eux.
Matvey, développeur chez NLP Group chez ABBYY