Peur des tampons d'opérations apportant ...
En utilisant une petite requête comme exemple, considérez quelques approches universelles pour optimiser les requêtes sur PostgreSQL. Les utiliser ou non est à vous de choisir, mais vous devez les connaître.
Dans certaines versions futures de PG, la situation pourrait changer avec la «sagesse» du planificateur, mais pour 9.4 / 9.6, cela ressemble à peu près, comme les exemples ici.
Je vais prendre une demande bien réelle:
SELECT TRUE FROM "" d INNER JOIN "" doc_ex USING("@") INNER JOIN "" t_doc ON t_doc."@" = d."" WHERE (d."3" = 19091 or d."" = 19091) AND d."$" IS NULL AND d."" IS NOT TRUE AND doc_ex.""[1] IS TRUE AND t_doc."" = '' LIMIT 1;
sur les noms des tables et des champsLes noms «russes» des champs et des tables peuvent être traités différemment, mais c'est une question de goût. Comme
nous n'avons pas de développeurs étrangers
dans «Tensor» , et PostgreSQL nous permet de donner des noms même avec des hiéroglyphes, s'ils sont
placés entre guillemets , nous préférons nommer les objets sans ambiguïté, clairement, afin qu'il n'y ait pas de malentendus.
Regardons le plan résultant:
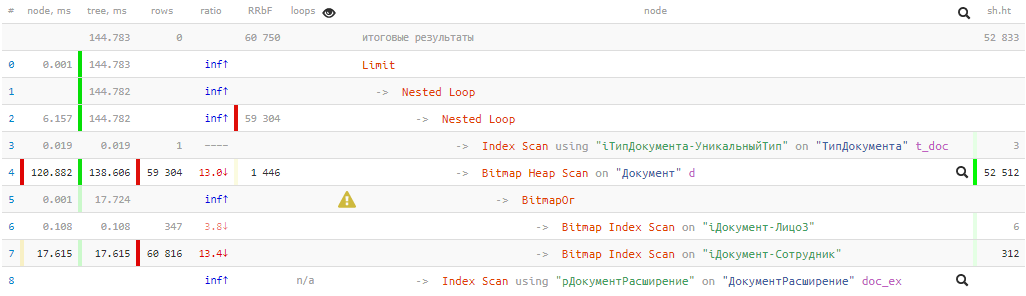 [regardez expliquez.tensor.ru]144 ms et près de 53 Ko de tampons
[regardez expliquez.tensor.ru]144 ms et près de 53 Ko de tampons , soit plus de 400 Mo de données! Et nous sommes chanceux si tous sont dans le cache au moment de notre demande, sinon cela sera plusieurs fois plus long lorsqu'il sera soustrait du disque.
L'algorithme est le plus important!
Afin d'optimiser en quelque sorte toute demande, vous devez d'abord comprendre ce qu'elle doit faire.
Pour l'instant, nous laissons le développement de la structure de la base de données en dehors du champ d'application de cet article et convenons que nous pouvons
réécrire relativement «bon marché»
la requête et / ou introduire dans la base de données tous les
index dont nous avons besoin.
La demande est donc:
- vérifie l'existence d'au moins un document
- dans l'état dont nous avons besoin et d'un certain type
- lorsque l'auteur ou l'exécuteur testamentaire est l'employé dont nous avons besoin
REJOINDRE + LIMIT 1
Très souvent, il est plus facile pour un développeur d'écrire une requête où, dans un premier temps, un grand nombre de tables sont jointes, puis à partir de cet ensemble, il n'y a qu'un seul enregistrement. Mais plus facile pour le développeur - ne signifie pas plus efficace pour la base de données.
Dans notre cas, il n'y avait que 3 tableaux - et quel effet ...
Tout d'abord, débarrassons-nous de la connexion à la table «TypeDocument», et en même temps, disons à la base de données que notre
enregistrement de type est unique (nous le savons, mais le planificateur n'a aucune idée):
WITH T AS ( SELECT "@" FROM "" WHERE "" = '' LIMIT 1 ) ... WHERE d."" = (TABLE T) ...
Oui, si la table / CTE se compose d'un seul champ d'un seul enregistrement, alors dans PG, vous pouvez écrire même ainsi, au lieu de
d."" = (SELECT "@" FROM T LIMIT 1)
Informatique paresseuse dans les requêtes PostgreSQL
BitmapOr vs UNION
Dans certains cas, Bitmap Heap Scan nous coûtera beaucoup d'argent - par exemple, dans notre situation, lorsqu'un nombre suffisant d'enregistrements correspond à la condition requise. Nous l'avons obtenu en raison de la
condition OR, qui s'est transformée en une opération
BitmapOr dans le plan.
Revenons à la tâche d'origine - vous devez trouver un enregistrement qui correspond à l'
une des conditions - c'est-à-dire qu'il n'est pas nécessaire de rechercher tous les enregistrements 59K pour les deux conditions. Il existe un moyen de résoudre une condition et de
passer à la seconde uniquement lorsque rien n'a été trouvé sur la première . Cette conception nous aidera à:
( SELECT ... LIMIT 1 ) UNION ALL ( SELECT ... LIMIT 1 ) LIMIT 1
«External» LIMIT 1 garantit que la recherche se termine lorsque le premier enregistrement est trouvé. Et s'il est déjà dans le premier bloc, le second ne sera pas
exécuté (
jamais exécuté dans le plan).
«Se cacher sous CASE» des conditions difficiles
Il y a un moment extrêmement gênant dans la demande initiale - vérifier l'état à l'aide du tableau lié "Extension de document". Quelle que soit la vérité des conditions restantes dans l'expression (par exemple,
d. «Supprimé» N'EST PAS VRAI ), cette connexion est toujours effectuée et «vaut les ressources». Plus ou moins d'entre eux seront dépensés - dépend de la taille de ce tableau.
Mais vous pouvez modifier la demande afin que la recherche de l'enregistrement associé ne se produise que lorsque cela est vraiment nécessaire:
SELECT ... FROM "" d WHERE ... AND CASE WHEN "$" IS NULL AND "" IS NOT TRUE THEN ( SELECT ""[1] IS TRUE FROM "" WHERE "@" = d."@" ) END
Comme nous
n'avons besoin d'aucun des champs pour le résultat de la table liée, nous sommes en mesure de transformer le JOIN en condition pour une sous-requête.
Nous laissons les champs indexés «en dehors des crochets» de CASE, nous ajoutons des conditions simples de l'enregistrement au bloc WHEN - et maintenant la requête «lourde» n'est exécutée que lors du passage à THEN.
Mon nom de famille est «Total»
Nous collectons la requête résultante avec toutes les mécaniques décrites ci-dessus:
WITH T AS ( SELECT "@" FROM "" WHERE "" = '' ) ( SELECT TRUE FROM "" d WHERE ("3", "") = (19091, (TABLE T)) AND CASE WHEN "$" IS NULL AND "" IS NOT TRUE THEN ( SELECT ""[1] IS TRUE FROM "" WHERE "@" = d."@" ) END LIMIT 1 ) UNION ALL ( SELECT TRUE FROM "" d WHERE ("", "") = ((TABLE T), 19091) AND CASE WHEN "$" IS NULL AND "" IS NOT TRUE THEN ( SELECT ""[1] IS TRUE FROM "" WHERE "@" = d."@" ) END LIMIT 1 ) LIMIT 1;
Personnaliser les indices [Under]
L'œil averti a remarqué que les conditions indexées dans les sous-unités UNION sont légèrement différentes - c'est parce que nous avons déjà les index appropriés sur la table. Et s'ils n'étaient pas là, alors cela vaudrait la peine de créer:
Document (Personne3, Type de document) et
Document (Type de document, Employé) .
sur l'ordre des champs dans les conditions de l'empriseDu point de vue du planificateur, vous pouvez bien sûr écrire à la fois (A, B) = (constA, constB) et (B, A) = (constB, constA) . Mais lors de l'écriture dans l'ordre des champs de l'index , une telle demande est simplement plus pratique à déboguer plus tard.
Quel est le plan?
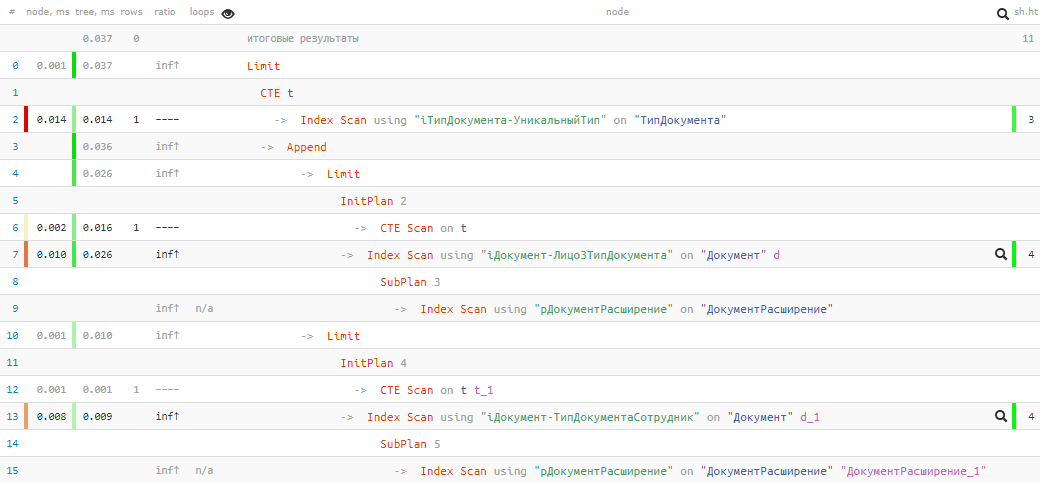 [regardez expliquez.tensor.ru]
[regardez expliquez.tensor.ru]Malheureusement, nous n'avons pas eu de chance, et rien n'a été trouvé dans le premier bloc UNION, donc le second a quand même été exécuté. Mais même ainsi - seulement
0,037 ms et 11 tampons !
Nous avons accéléré la demande et réduit le "pompage" des données en mémoire de
plusieurs milliers de fois , en utilisant des méthodes assez simples - un bon résultat avec un petit copier-coller. :)