Bonjour, Habr! Je m'appelle Roman et je veux parler aujourd'hui de la façon dont nous, à Innopolis University, avons développé un banc d'essai et un service pour le système Acronis Active Restore, qui devrait bientôt faire partie de la gamme de produits de l'entreprise. Tous ceux qui s'intéressent à la façon dont l'université établit des relations avec des partenaires industriels, je vous invite à procéder sous cat.

Le développement d'Active Restore a commencé au sein d'Acronis, mais nous, en tant qu'étudiants de l'Université Innopolis, avons participé à ce processus dans le cadre d'un projet de formation industrielle. Mon conservateur (et maintenant collègue) Daulet Tumbaev a déjà écrit sur l'idée, ainsi que sur l'architecture,
dans son article . Aujourd'hui, je vais parler de la façon dont nous avons préparé le service d'Innopolis.
Tout a commencé en été, lorsque nous avons été informés qu'au cours du premier semestre, les sociétés informatiques viendraient nous voir et nous proposeraient leurs idées pour des travaux pratiques. Et donc, en décembre 2018, 15 projets différents nous ont été présentés et, à la fin du mois, nous avons défini des priorités, déterminé qui aimait le mieux.
Tous les étudiants de premier cycle ont rempli un formulaire où il était nécessaire de choisir quatre projets auxquels nous voulions participer. Il fallait motiver pourquoi moi, et pourquoi précisément ces projets. Par exemple, j'ai souligné que j'avais déjà de l'expérience en programmation système et développement en C / C ++. Mais surtout, le projet m'a permis de développer mes compétences et de continuer à grandir.
Deux semaines plus tard, nous avons été affectés et dès le début du deuxième semestre, le travail sur les projets a commencé. L'équipe a été formée, lors de la première réunion, nous avons évalué les forces et les faiblesses de chacun et attribué des rôles.
- Roman Rybkin est un développeur Python / C ++.
- Eugene Ishutin - Développeur Python / C ++, responsable de l'interaction avec l'entreprise.
- Anastasia Rodionova est un développeur Python / C ++ responsable de la rédaction de la documentation.
- Brandon Acosta - mise en place de l'environnement, préparation du stand pour les expériences et les tests.
Les deux premières semaines, nous avons dû entamer le processus. Nous avons établi des contacts avec le client, formalisé les exigences du projet, lancé un processus itératif et mis en place l'environnement de travail.
Soit dit en passant, notre travail avec le client a vraiment commencé à bouillir lorsque nous avons commencé les cours au choix. Le fait est qu'Acronis mène à l'Université Innopolis (et pas seulement) des sujets de choix. Et Alexey Kostyushko, l'un des principaux développeurs de l'équipe Kernel, enseigne deux cours de façon continue: l'ingénierie inverse et l'architecture et les pilotes du noyau Windows. Pour autant que je sache, un cours sur la programmation système et l'informatique multi-thread est également prévu à l'avenir. Mais l'essentiel est que tous ces cours soient conçus de manière à aider les étudiants à faire face aux projets industriels. Ils pompent sérieusement dans la compréhension du sujet et simplifient ainsi le travail sur le projet.
Pour cette raison, nous avons commencé plus vigoureusement que les autres équipes, et l'interaction avec Acronis lui-même est devenue plus dense. Alexey Kostyushko a agi pour nous dans le rôle de Product Owner, de lui nous avons reçu les connaissances nécessaires dans le domaine. Grâce à ses choix, nos compétences et nos compétences ont été très fortement pompées, nous sommes devenus vraiment prêts à accomplir la tâche qui nous attendait.
De la pensée au projet
Le premier mois pour toutes les équipes a été aussi difficile que possible. Tout le monde était perdu, ne savait pas par où commencer - peut-être avec des documents ou, inversement, plonger dans le code. Au début, des commentaires contradictoires sont venus des conservateurs et des mentors des représentants de l'université et de l'entreprise.
Lorsque tout s'est mis en place (du moins dans ma tête), il est devenu clair que les mentors de l'université nous ont aidés à construire des relations internes au sein de l'équipe et à préparer les documents. Mais le véritable point de rupture a été l'arrivée de Daulet en mars. Nous nous sommes juste assis et avons travaillé sur le projet tout le week-end. Ensuite, nous avons repensé l'essence du projet, redémarré, redistribué les priorités des tâches et pris rapidement l'avion. Nous avons compris ce qu'il fallait faire pour démarrer l'expérience (à ce sujet un peu plus tard) et développer le service. A partir de ce moment, l'idée générale s'est transformée en un plan clair. Le véritable développement du code a commencé et en 2 semaines, nous avons développé la première version du banc de test, y compris les machines virtuelles, les services nécessaires et le code pour automatiser l'expérience et collecter les données.
Il est à noter qu'en parallèle au projet industriel, des formations ont permis de construire une architecture compétente pour nos projets et d'organiser le Management Qualité. Au début, ces tâches prenaient 70 à 90% du temps par semaine, mais il s'est avéré qu'il fallait du temps pour éviter les problèmes dans le processus de développement. L'objectif de l'université était d'apprendre à construire le processus de développement avec compétence et les entreprises, en tant que clients, étaient plus intéressées par le résultat. Bien sûr, cela a créé beaucoup de confusion, mais cela a aidé à combiner les compétences théoriques et pratiques. Une complexité et une charge suffisantes ont assuré la présence de la motivation, ce qui a abouti au succès du projet.
Au départ, deux personnes de notre équipe étaient engagées dans le développement pur, une personne a repris les documents, et une autre a plongé dans la mise en place de l'environnement. Cependant, plus tard, trois autres célibataires nous ont rejoints, avec lesquels nous sommes devenus une seule équipe. L'université a décidé de lancer un projet industriel test pour les étudiants de troisième année d'études. L'expansion de l'équipe de 4 à 7 personnes a considérablement accéléré le processus, car nos bacheliers pouvaient facilement effectuer des tâches liées au développement. Ekaterina Levchenko a aidé à écrire du code python et des scripts batch pour le banc de test. Ansat Abirov et Ruslan Kim ont agi en tant que développeurs, ils se sont engagés dans la sélection et l'optimisation des algorithmes.
Nous avons travaillé dans ce format jusqu'à fin mai, date du lancement de l'expérience. À ce moment, le projet industriel pour les célibataires s'est terminé. Deux d'entre eux ont commencé un stage Acronis et ont continué à travailler avec nous. Par conséquent, après mai, nous avons déjà travaillé en équipe de 6 personnes.
Avant nous était le troisième semestre, qui à Innopolis est exempt d'activités académiques. Nous n'avions que 2 choix et le reste du temps était consacré à un projet industriel. C'est au troisième semestre que les travaux sur le service se sont intensifiés. Le processus de développement est complètement tombé sur les rails, les démos et les rapports sont devenus réguliers. Dans ce format, nous avons travaillé pendant 1,5 mois, et fin juillet, nous avons presque terminé la partie développement du travail.
Détails techniques
Tout d'abord, les exigences pour un service ont été formulées, qui devraient interagir de manière adéquate avec le pilote du minifiltre du système de fichiers (qui est ce que vous pouvez lire
ici ) et son architecture a été pensée. Avec un œil sur la simplicité de la prise en charge de code supplémentaire, nous avons immédiatement fourni une approche modulaire. Notre service comprend plusieurs gestionnaires, agents et gestionnaires, et avant même le début du codage, la possibilité de travailler en mode parallèle était prévue.
Cependant, après avoir discuté d'architecture lors d'une réunion avec des gars d'Acronis, il a été décidé de mener une expérience d'abord, puis de prendre le service lui-même. En conséquence, le développement n'a pris que 2,5 mois. Le reste du temps, nous avons mené une expérience pour trouver la liste minimale suffisante de fichiers sur lesquels Windows pourrait être exécuté. Dans un système réel, cet ensemble de fichiers est généré à l'aide du pilote, cependant, nous avons décidé de trouver cet ensemble heuristiquement, en utilisant la méthode de la demi-division, pour vérifier le fonctionnement du pilote.
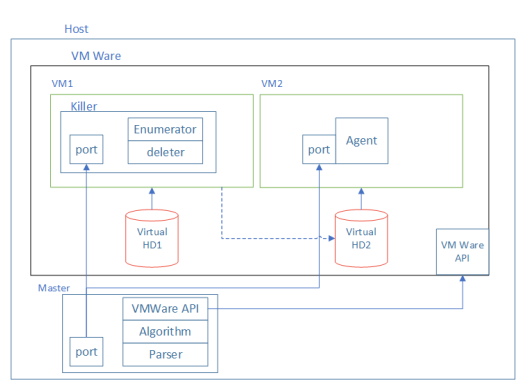 Le banc d'expérimentation.
Le banc d'expérimentation.
Pour ce faire, nous avons monté un stand en Python à partir de deux machines virtuelles. L'un d'eux a travaillé sur Linux et le second a chargé Windows. Deux disques ont été configurés pour eux: Virtual HD1 et Virtual HD2. Les deux disques étaient connectés à VM1 sur lequel Linux était installé. Sur cette machine virtuelle sur HD1, l'application Killer a été installée, ce qui a «endommagé» HD2. Les dommages se réfèrent à la suppression de certains fichiers du disque. HD2 était un disque de démarrage pour VM2 qui fonctionnait sous Windows. Après les «dommages» sur le disque, nous avons essayé de démarrer VM2. S'il était possible de le faire, les fichiers supprimés du disque étaient considérés comme inutiles à exécuter.
Afin d'automatiser ce processus, nous avons essayé de supprimer des fichiers non pas au hasard, mais dans le cadre d'une approche prédéfinie. L'algorithme comprenait 3 étapes:
- Divisez la liste des fichiers en deux.
- Supprimez l'un des demi-fichiers.
- Essayez de démarrer le système. Si le système a démarré, ajoutez les fichiers supprimés à la liste des fichiers inutiles. Sinon, nous revenons à l'étape 1.
Tout d'abord, nous avons décidé de simuler l'algorithme. Supposons qu'il y ait 1 000 000 de fichiers dans le système de fichiers. Dans ce cas, la recherche la plus efficace de fichiers critiques s'est produite dans les cas où les fichiers critiques représentaient environ 15% du total.
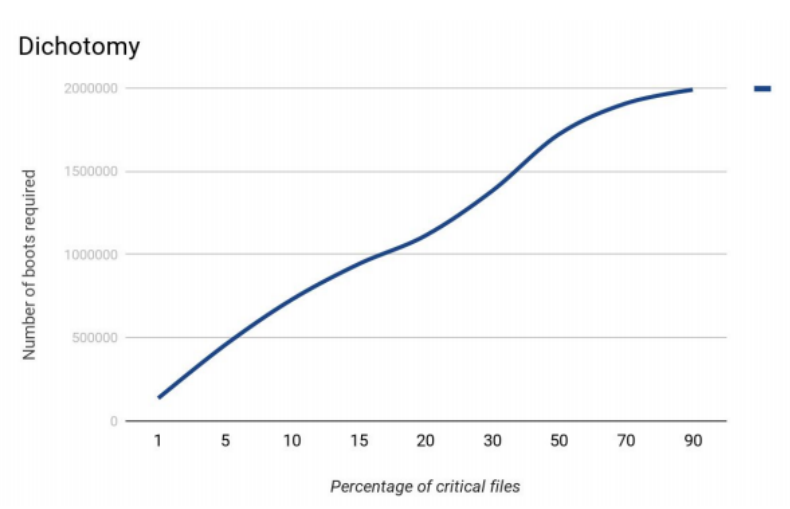 Méthode de demi-division.
Méthode de demi-division.Au début, il y avait beaucoup de problèmes avec l'expérience. Pendant 2-3 semaines, un banc d'essai était prêt. Et encore 1-1,5 mois, j'ai dû attraper des bugs, ajouter le code et appliquer diverses astuces pour faire fonctionner le stand.
La chose la plus difficile a été de détecter un bogue associé à la mise en cache des opérations sur disque. L'expérience a fonctionné pendant 2 jours et a produit des résultats très optimistes qui ont été plusieurs fois plus rapides que les simulations. Cependant, le test du fichier critique a échoué, le système n'a pas démarré. Il s'est avéré que lors de l'arrêt forcé de la machine virtuelle, les opérations de suppression mises en cache par le système de fichiers n'ont pas été effectuées et, par conséquent, le disque n'a pas été complètement effacé. En conséquence, l'algorithme a reçu des résultats incorrects, et pendant quelques jours, nous avons mis toutes nos convolutions à rude épreuve pour tout comprendre.
À un certain moment, nous avons remarqué que pendant le fonctionnement continu, l'algorithme était enterré dans l'un des segments du système de fichiers et a commencé à essayer de supprimer les mêmes fichiers (dans l'espoir d'un nouveau résultat). Cela s'est produit à des moments où l'algorithme reposait dans les régions où la plupart étaient nécessaires, tout en choisissant le mauvais intervalle pour la suppression. À ce stade, nous avons décidé d'ajouter une liste de fichiers de remaniement. Autrement dit, après quelques itérations, la liste des fichiers a été mélangée. Cela a aidé à éliminer l'algorithme de ces bâtons.
Lorsque tout était prêt, nous avons lancé ces deux machines virtuelles pendant 3 jours. Au total, environ 600 itérations se sont écoulées, parmi lesquelles plus de 20 lancements réussis. Il est devenu clair que cette expérience peut être exécutée pendant une longue période, ainsi que sur des machines plus puissantes, pour trouver la taille de fichier optimale pour exécuter Windows. De plus, l'algorithme peut être distribué sur plusieurs machines pour accélérer davantage ce processus
Dans notre cas, en plus de Windows, il n'y avait que Python et notre service sur le disque. En trois jours, nous avons réussi à réduire le nombre de fichiers de 70 000 à 50 000. La liste des fichiers n'a été réduite que de 28%, mais il est devenu clair que cette approche fonctionne et elle vous permet de déterminer l'ensemble minimal de fichiers requis pour charger le système d'exploitation.
Structure de service
Abordons une petite structure de service. Le module de service principal est un gestionnaire de files d'attente. Comme nous obtenons une liste de fichiers du pilote, nous devons restaurer les fichiers de cette liste. Pour ce faire, nous avons créé un virage avec des priorités.
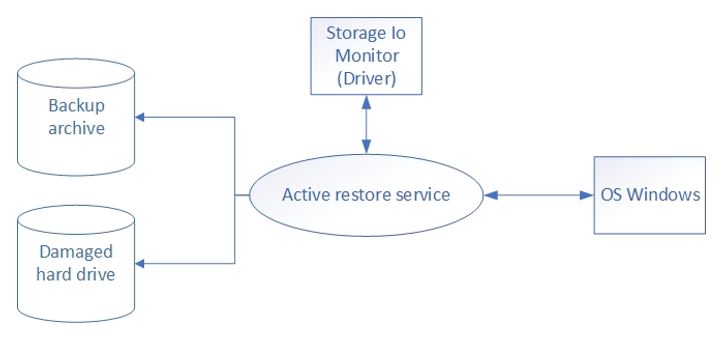
Nous avons une liste de fichiers qui sont restaurés à leur tour. Et si de nouvelles demandes d'accès apparaissent, les fichiers nécessaires de toute urgence sont restaurés en priorité. Pour cette raison, au début de la file d'attente, il y aura les fichiers dont l'utilisateur a vraiment besoin maintenant, et à la fin de la ligne - ces fichiers qui pourraient être nécessaires à l'avenir. Mais avec le travail actif de l'utilisateur, une «file d'attente d'objets extraordinaires» peut être formée, ainsi qu'une liste de fichiers en cours de restauration. En outre, l'opération de recherche aurait dû être appliquée à toutes ces files d'attente à la fois. Hélas, nous n'avons pas trouvé une telle implémentation de la file d'attente qui pourrait définir plusieurs priorités de fichiers, tout en prenant en charge la recherche, ainsi que des priorités changeantes à la volée. Nous ne voulions pas nous adapter aux structures de données existantes, et nous avons donc dû écrire les nôtres et mettre en place la capacité de travailler avec.
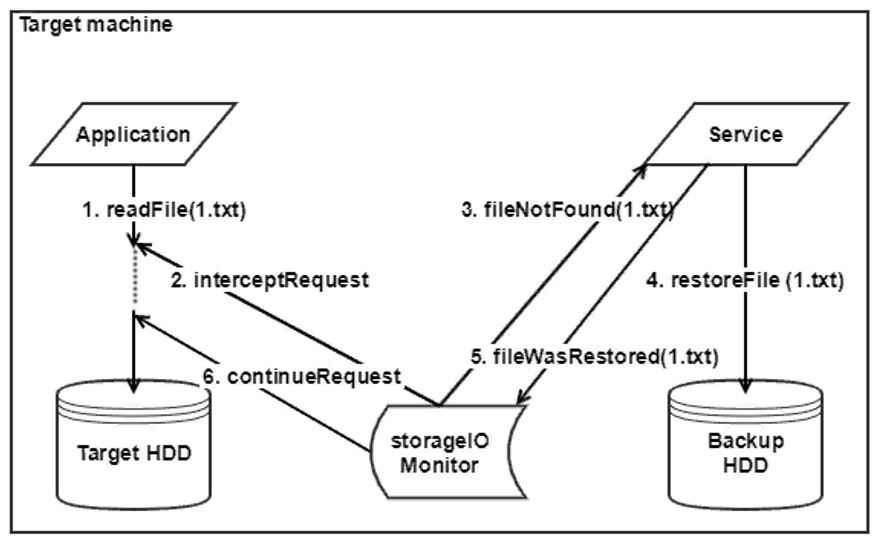
Notre service devra d'abord communiquer avec le pilote sur lequel Daulet a travaillé, puis avec les composants responsables de la restauration des fichiers ... Par conséquent, pour les débutants, nous avons décidé de créer notre propre petit émulateur du système de récupération, qui pourrait émettre des fichiers à partir d'un disque externe afin qu'ils puissent être restaurer et tester le service.
Au total, deux modes de fonctionnement ont été fournis - le mode normal et le mode de récupération. En mode normal, le pilote nous envoie une liste des fichiers concernés par le démarrage du système d'exploitation. Ensuite, pendant que le système est en cours d'exécution, le pilote surveille toutes les opérations sur les fichiers et envoie des notifications à notre service, qui modifie à son tour la liste des fichiers. En mode de récupération, le pilote informe le service que la récupération du système est nécessaire. Le service met en file d'attente les fichiers, exécute les agents logiciels qui demandent des fichiers à la sauvegarde et commence le processus de récupération.
Diplôme, invitation à l'emploi et nouveaux projets
Lorsque le service était prêt et testé, nous avions la dernière activité sur le projet. Il était nécessaire de mettre à jour et de structurer tous les artefacts que nous avons accumulés, ainsi que de présenter nos résultats au client et à l'université. Pour l'entreprise, c'était une autre étape vers la mise en œuvre du projet, pour l'université avec notre thèse de fin d'études.
Suite à la présentation, une proposition a été faite aux étudiants. Et après quelques semaines, je vais travailler chez Acronis. Les résultats du projet ont conduit les développeurs à penser qu'il est possible de rendre le service plus efficace en le réduisant au niveau de l'application Windows native. Mais plus à ce sujet dans le prochain article.