
Salutations habr.
Si quelqu'un exécute un système Web graphite et rencontre un problème de performances de stockage silencieux (IO, consommation d'espace disque), la chance que ClickHouse soit casté en remplacement devrait viser un. Cette déclaration implique qu'une implémentation tierce, telle que carbonwriter ou go-carbon, est déjà utilisée comme métrique de réception du démon.
ClickHouse résout bien les problèmes décrits. Par exemple, après avoir transféré des données 2TiB à partir d'un murmure, elles tiennent dans 300GiB. Je ne m'attarderai pas sur la comparaison en détail, il y a suffisamment d'articles sur ce sujet. De plus, jusqu'à récemment, tout était parfait avec notre stockage ClickHouse.
Problèmes de consommation
À première vue, tout devrait bien fonctionner. Suite à la documentation , nous créons une configuration pour le schéma de stockage des métriques (ci-après retention ), puis créons une table selon la recommandation du backend sélectionné pour graphite-web: carbon-clickhouse + graphite-clickhouse ou graphouse , selon la pile utilisée. Et ... la bombe à retardement se déclenche.
Afin de comprendre lequel, vous devez savoir comment les insertions et le chemin de vie des données dans les tableaux de la famille de moteurs * MergeTree ClickHouse (diagrammes tirés de la présentation d' Alexei Zatelepin):
- Un

- Chacun de ces blocs avant d'écrire sur le disque est trié selon la clé
ORDER BY spécifiée lors de la création de la table. - Après le tri, une donnée est écrite sur le disque.
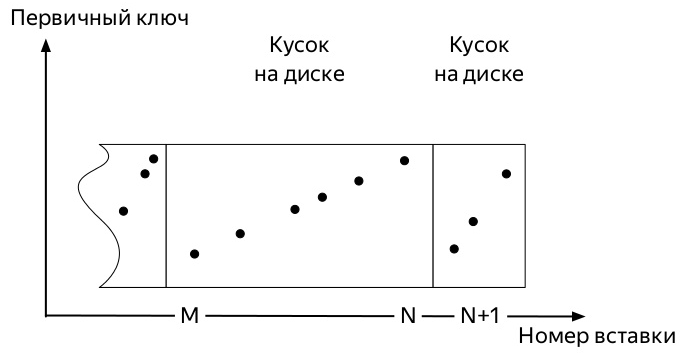
- Le serveur surveille en arrière-plan qu'il n'y en a pas beaucoup et démarre les
merge , ci-après fusion).
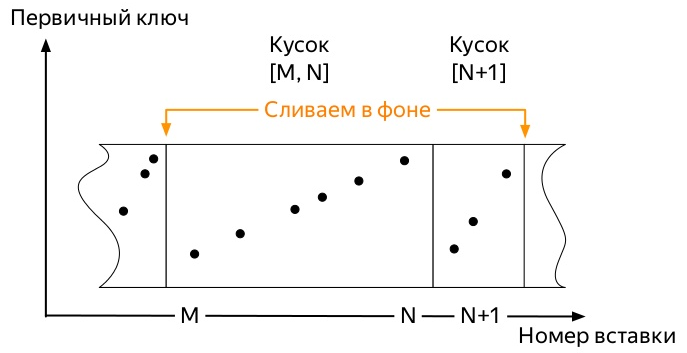

- Le serveur arrête de démarrer la fusion de lui-même dès que les données n'entrent plus activement
partition , mais vous pouvez démarrer le processus manuellement avec la commande OPTIMIZE . - S'il ne reste qu'une seule pièce dans la partition, vous ne pouvez pas démarrer la fusion avec la commande habituelle, vous devez utiliser
OPTIMIZE ... FINAL
Ainsi, les premières mesures arrivent. Et ils occupent un certain espace. Les événements ultérieurs peuvent varier légèrement en fonction de nombreux facteurs:
- La clé de partitionnement peut être très petite (jour) ou très grande (plusieurs mois).
- La configuration de rétention peut prendre en charge plusieurs seuils d'agrégation de données significatifs au sein de la partition active (où va l'enregistrement des métriques), ou non.
- S'il y a beaucoup de données, les premières pièces, qui en raison des fusions d'arrière-plan peuvent déjà être énormes (lors du choix d'une clé de partition sous-optimale), ne pourront pas se tripoter avec de petites pièces fraîches.
Et tout finit toujours pareil. La place occupée par les métriques dans ClickHouse ne se développe que si:
- n'appliquez pas
OPTIMIZE ... FINAL manuellement ou - n'insérez pas de données dans toutes les partitions de façon continue afin de démarrer une fusion en arrière-plan tôt ou tard
La deuxième méthode semble la plus simple à mettre en œuvre et, par conséquent, il a tort et a été testé en premier.
J'ai écrit un script python assez simple qui a envoyé des métriques factices pour chaque jour au cours des 4 dernières années et a été exécuté toutes les heures par la couronne.
Étant donné que tout le travail de ClickHouse DBMS est basé sur le fait que ce système fera tout le travail d'arrière-plan tôt ou tard, mais on ne sait pas quand, je ne pouvais pas attendre que les énormes pièces anciennes daignent commencer à fusionner avec de nouvelles petites. Il est devenu clair que nous devions chercher un moyen d'automatiser les optimisations forcées.

Jetez un œil à la structure de la table system.parts . Il s'agit d'informations complètes sur chaque élément de toutes les tables du serveur ClickHouse. Il contient, entre autres, les colonnes suivantes:
- Nom de la
database ( database ); - nom de table (
table ); - Nom et ID de la
partition ( partition & partition_id ); - quand la pièce a été créée (
modification_time ); - date minimum et maximum dans un morceau (le partitionnement se fait par jour) (
min_date & max_date );
Il existe également une table system.graphite_retentions , avec les champs intéressants suivants:
- Nom de la base de données (
Tables.database ); - nom de la table (
Tables.table ); - l'âge de la mesure lorsque la prochaine agrégation (
age ) doit être appliquée;
Donc:
- Nous avons un tableau de pièces et un tableau de règles d'agrégation.
- Combinez leur intersection et obtenez toutes les tables * GraphiteMergeTree.
- Nous recherchons toutes les partitions dans lesquelles:
- plus d'une pièce
- ou le moment est venu d'appliquer la règle d'agrégation suivante, et
modification_time plus ancien que ce moment.
Implémentation
Cette demande SELECT concat(p.database, '.', p.table) AS table, p.partition_id AS partition_id, p.partition AS partition,
renvoie chacune des partitions des tables * GraphiteMergeTree dont la fusion devrait libérer de l'espace disque. Il ne reste que la petite chose: parcourez-les tous avec la requête OPTIMIZE ... FINAL . L'implémentation finale a également pris en compte le moment où il n'est pas nécessaire de toucher les partitions avec un enregistrement actif.
C'est exactement ce que fait le projet graphite-ch-optimizer . D'anciens collègues de Yandex.Market l'ont testé dans la prod, le résultat du travail peut être vu ci-dessous.

Si vous exécutez le programme sur le serveur avec ClickHouse, il commencera simplement à fonctionner en mode démon. Une fois par heure, une requête sera exécutée, vérifiant s'il existe de nouvelles partitions de plus de trois jours pouvant être optimisées.
Dans un avenir proche - pour fournir au moins les packages deb, et si possible - également rpm.
UPD: les packages sont disponibles sur les versions de github , et des images de travail peuvent être trouvées sur docker-hub dans le référentiel innogames / graphite-ch-optimizer.
Au lieu d'une conclusion
Au cours des 9 derniers mois et plus, j'ai passé beaucoup de temps au sein de ma société InnoGames à la jonction de ClickHouse et de graphite-web. Ce fut une bonne expérience, qui a permis de passer rapidement de chuchotement à ClickHouse en tant que référentiel de métriques. J'espère que cet article est quelque chose comme le début d'un cycle sur les améliorations que nous avons apportées à différentes parties de cette pile, et ce qui sera fait à l'avenir.
Plusieurs litres de bière et des journées d'administration ont été consacrés au développement de demandes avec v0devil , pour lequel je tiens à lui exprimer ma gratitude. Et aussi pour avoir revu cet article.
Page du projet sur github