PostgreSQL utilise des statistiques accumulées sur la distribution des valeurs de données dans les tables cibles pour sélectionner le plan d'exécution de requête le plus efficace.
Il est mis à jour en exécutant explicitement les commandes
ANALYZE et
VACUUM ANALYZE ou en arrière-plan par le
processus autovacuum / autoanalyze . Mais si les statistiques n'ont pas le temps d'être mises à jour, des problèmes peuvent survenir.
Comment détecter et résoudre un tel problème?
L'option principale lorsqu'une telle situation peut se produire est que l'ensemble de données a radicalement changé dans le tableau. Autrement dit, il a
généré un grand nombre de INSERT / UPDATE / DELETE ou simplement «versé» les données dans une table vide - par exemple,
lors de la restauration à partir d'une sauvegarde .
L'aide de l'
utilitaire de récupération standard
pg_restore dit même explicitement:
Après la récupération, il est judicieux d'exécuter ANALYZE pour chaque table restaurée afin que l'optimiseur reçoive des statistiques à jour.
Par conséquent, si vous faites quelque chose de similaire avec la base de données - ne soyez pas paresseux, exécutez immédiatement
ANALYZE sur les tables les plus "en gras" ou la base de données entière.
Nous déterminons la présence d'un problème
À quoi la situation «tout mauvais» ressemble-t-elle exactement? Habituellement, quelque chose comme ça:
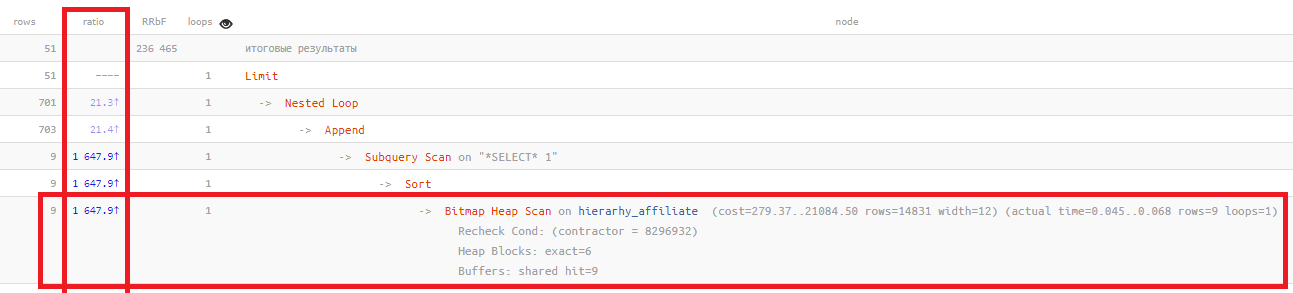
La colonne du
ratio montre simplement la relation "parfois" entre le nombre d'enregistrements prévus sur la base de statistiques et le nombre effectivement lu:
Bitmap Heap Scan on ... (... rows=14831 ...) (actual ... rows=9 ...)
Plus cette valeur est élevée, plus les statistiques reflètent la situation réelle de votre tableau. Normalement, il ne
dépasse généralement
pas des centaines , dans cet exemple,
mille et demi fois .
Cela conduit au choix d'un plan inefficace et, par conséquent, à la
charge la
plus folle sur la base . Pour le retirer rapidement, il vous suffit d'écouter les recommandations du manuel et de parcourir
ANALYSER sur les tableaux principaux.
Voici la charge CPU sur le serveur de base de données avant et après cette opération pour l'exemple ci-dessus:
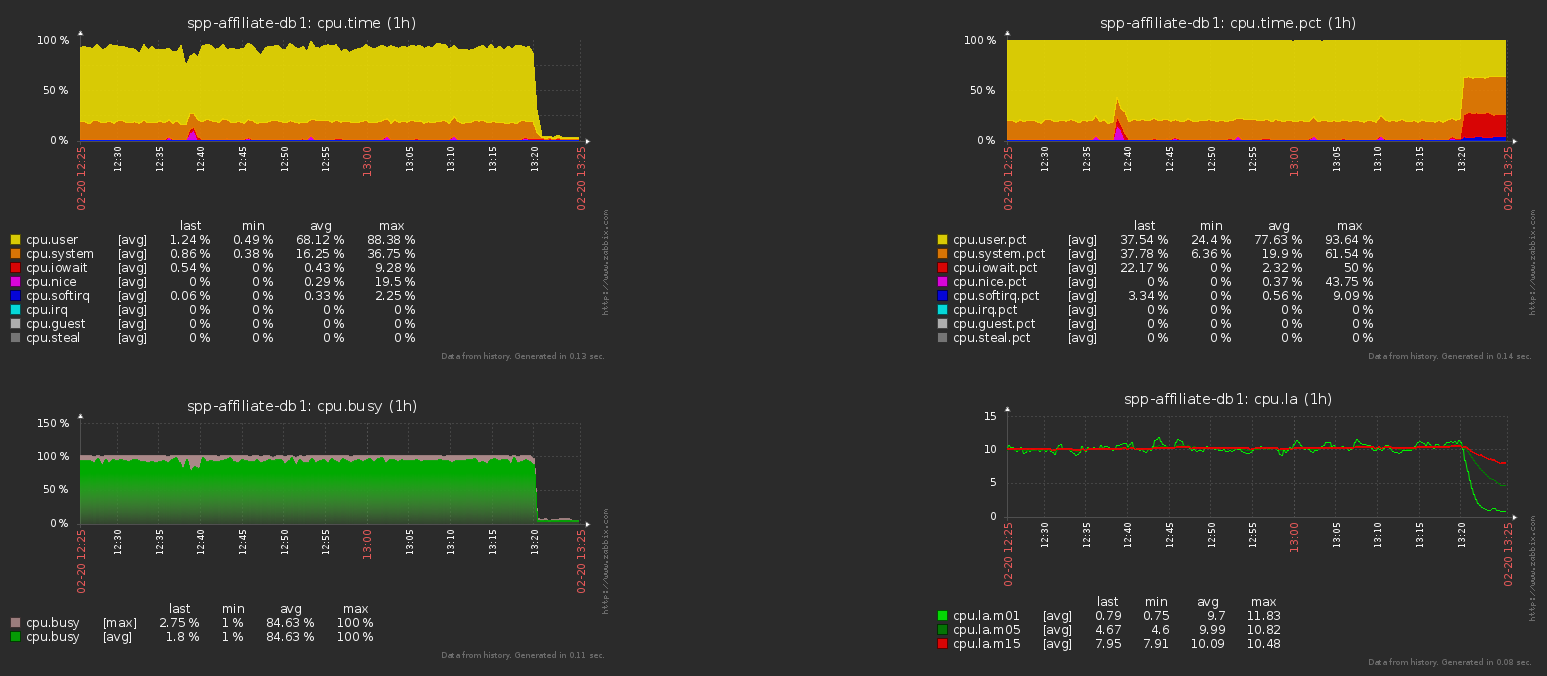
Tableau fréquemment mis à jour
Mais que se passe-t-il si la table change vraiment un grand nombre d'enregistrements? Par exemple, il s'agit d'une sorte de tampon ou de file d'attente de traitement où de nouveaux enregistrements sont constamment ajoutés et les anciens sont supprimés.
Dans ce cas, les
paramètres de configuration suivants nous aideront:
autovacuum_naptime (entier)
Définit le délai minimum entre deux exécutions de nettoyage automatique pour une seule base de données. Le démon d'autonettoyage analyse la base de données à l'intervalle de temps spécifié et émet les commandes VACUUM et ANALYZE lorsque cela est requis pour les tables de cette base de données. Si cette valeur est spécifiée sans unités, elle est considérée comme définie en secondes. Par défaut, le retard est d'une minute (1min). Ce paramètre ne peut être défini que dans postgresql.conf ou sur la ligne de commande au démarrage du serveur.
autovacuum_analyze_threshold (entier)
Définit le nombre minimum de tuples ajoutés, modifiés ou supprimés auxquels ANALYZE sera exécuté pour une seule table. La valeur par défaut est 50 tuples. Ce paramètre ne peut être défini que dans postgresql.conf ou sur la ligne de commande au démarrage du serveur. Cependant, cette valeur peut être remplacée pour les tables sélectionnées en modifiant leurs paramètres de stockage.
autovacuum_analyze_scale_factor (virgule flottante)
Spécifie le pourcentage de la taille de la table qui sera ajouté à autovacuum_analyze_threshold lorsque le seuil de commande ANALYZE est sélectionné. La valeur par défaut est 0,1 (10% de la taille du tableau). Vous ne pouvez définir ce paramètre que dans postgresql.conf ou sur la ligne de commande au démarrage du serveur. Cependant, cette valeur peut être remplacée pour les tables sélectionnées en modifiant leurs paramètres de stockage.
SWSS
Parfois, lors de la configuration d'un serveur,
autovacuum_naptime est «
écrasé » à «une fois par jour» (1d) afin
que les autoVACUUMs parcourent la base de données moins souvent et consomment moins de ressources.
Parfois, bien que très rarement, cela est même justifié - par exemple, si vous avez des
milliers de tables / sections dans une base de données (même si elles sont disposées selon des modèles différents).
Étant donné que la définition même des tables spécifiques de la liste entière doit être traitée, lors de l'initialisation du processus de vide automatique, cela
peut prendre une part considérable de ressources et ralentir le serveur .
Juste dans ce cas, vous aurez des problèmes avec une table fréquemment modifiée.
Ici - soit définir un intervalle de lancement plus adéquat, soit poursuivre ANALYSER selon un tel tableau en mode «manuel» pour certaines raisons appliquées (par exemple, un minuteur externe ou après la fin de la prochaine étape du traitement de la file d'attente).
Camarade, tenez les statistiques à jour!