Salut Habr!
Le crédit immobilier est un système vaste et très dynamique, qui est parfois difficile à suivre. Pour aider les employés à se tenir au courant de toutes les nouvelles et changements et à suivre le rythme partout, nous introduisons activement des algorithmes d'apprentissage automatique. Dans notre banque, les chat bots assument déjà une partie du travail des opérateurs, les avis clients sont analysés non seulement par des experts, mais aussi par des algorithmes intelligents de traitement du langage naturel.
Aujourd'hui, je vais vous dire comment nous avons aidé les spécialistes de l'exploitation des services bancaires à se débarrasser de la nécessité de consulter en permanence les tableaux de bord des systèmes de surveillance, à savoir, ils ont appelé à l'apprentissage automatique pour aider. Voilà ce que nous avons.

Comment fonctionne la surveillance manuelle?
Un lieu de travail typique d'un spécialiste de l'exploitation ressemble à l'image ci-dessus, et il passe la plupart de son temps à regarder les tableaux de bord. Toute activité suspecte dans le système, par exemple, lorsque le réseau est tombé en panne ou qu'une NullPointerException a plu, attirera immédiatement l'attention - une enquête commencera immédiatement.
L'homme n'est pas une machine. Il peut être distrait, aller dîner, répondre au téléphone. Et lorsque le nombre de graphiques dépasse la centaine, il devient difficile de les lier tous ensemble et d'aller au fond de l'essence.
Un autre problème est qu'il existe une famille d'erreurs qui se produisent constamment, mais n'affectent pas sérieusement le comportement du système. Par exemple, un microservice tiers est tombé et les tableaux de bord ont tremblé, mais en fait le système est hors de danger. À première vue, on ne sait pas toujours à quel point un comportement anormal est critique et ce qui se cache derrière. Pour établir les raisons en détail, vous devez vous rendre sur le serveur et approfondir les journaux. Une telle opération doit être effectuée des dizaines de fois par jour. Confions-la au moins partiellement à la voiture.
L'apprentissage automatique en tant qu'assistant intelligent
Il existe trois principales sources de données: Zabbix, ElasticSearch et un système de surveillance des métriques commerciales internes. Nous utilisons Zabbix pour surveiller le matériel, le réseau et la disponibilité de divers points d'entrée dans les systèmes. À l'aide d'ElasticSearch, analysez et extrayez le journal des messages. Diverses erreurs, exécutions et requêtes sont utilisées comme métriques. Les analystes commerciaux surveillent cependant les performances des utilisateurs: le nombre de transferts, de ventes et d'autres activités commerciales. Les données sont collectées à une fréquence d'une fois par minute et ajoutées à la base de données. Eh bien, les données sont collectées, il est temps d'écrire un tas de si pour mettre l'apprentissage automatique au combat.
Nous formulons le problème comme suit: en ayant les métriques du système en entrée, nous classerons l'état final du système: régulier ou anormal. Dans ce contexte, le problème s'inscrit parfaitement dans le paradigme de l'apprentissage avec un enseignant. Cela signifie que l'ensemble de nos données de formation doivent être étiquetées. En d'autres termes, chaque minute de fonctionnement du système doit avoir une étiquette de 0 (comportement normal) ou -1 (comportement anormal).
Dans la vie, il s'avère que tout n'est pas aussi rose que nous le souhaiterions. En règle générale, tous les incidents ne sont pas enregistrés dans JIRA, beaucoup reste dans le courrier et ne va pas au-delà, et parfois les délais de l'anomalie sont flous ou inexacts. Il s'avère que la construction d'un ensemble de données de haute qualité dans le domaine des données historiques n'est pas une tâche triviale.
Alors que les nouvelles données commencent à peine à être présentées, essayons de tirer le meilleur parti de ce que nous avons déjà. Pour les cas où les données n'ont pas de balisage, des algorithmes d'apprentissage sans professeur sont utilisés. Nous partirons du fait que la plupart du temps le système fonctionne correctement, mais que des événements imprévus se produisent parfois: des bugs (où sans eux), la base est tombée, ou, par exemple, la pelle Petr a heurté le câble du centre de données. Par conséquent, nous réduisons notre tâche à la recherche d'anomalies, à savoir la recherche d'un nouveau comportement système (Détection de nouveauté).
Pour ce faire, utilisez l'algorithme de forêt isolée. Il est déjà implémenté dans la bibliothèque sklearn. Nous utiliserons les métriques des systèmes de surveillance comme fonctionnalités.
clf = IsolationForest(behaviour='new', max_samples=100, random_state=rng, contamination='auto')
Nous formerons la forêt isolée sur des données historiques et nous utiliserons les nouvelles données que nous avons déjà réussi à marquer pour évaluer la qualité. Il reste donc à choisir les hyperparamètres du modèle et la taille du jeu de données pour la formation.
Maintenant, les données d'état, qui sont collectées toutes les minutes, sont entrées dans le modèle formé et obtiennent le label 0 ou -1.
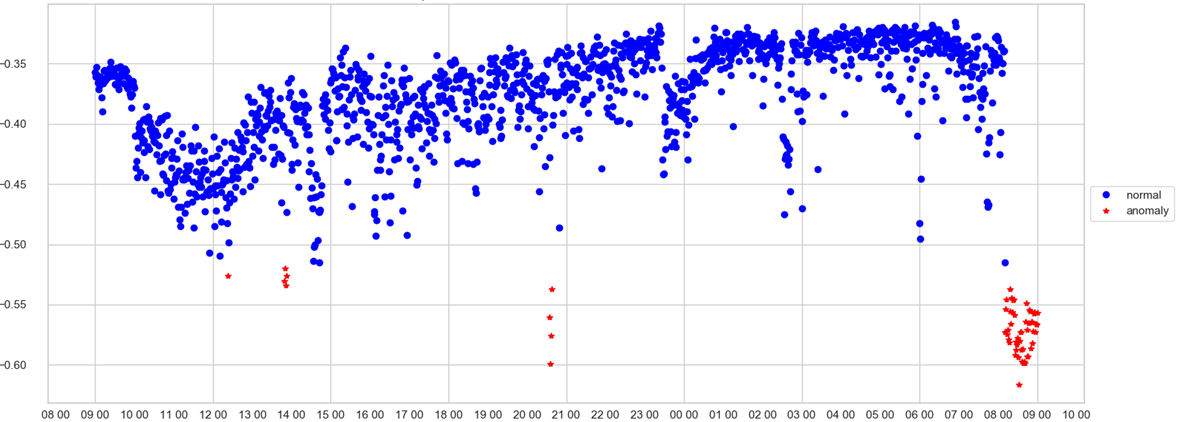
Un opérateur ne peut suivre qu'un seul horaire. Sur l'axe X - temps, sur le score d'anomalie Y, c'est-à-dire avec quelle force le modèle considérait l'état du système à cette minute anormal. Si la valeur de vitesse a traversé la poubelle (que le modèle sélectionne lui-même), le point est teinté en rouge et une anomalie est enregistrée.
Nous apprenons maintenant que le système fonctionne dans un mode inhabituel ou qu'une situation d'urgence s'est produite en temps quasi réel. C'est très bien, mais qu'en est-il de l'opérateur au moment de recevoir le signal de l'anomalie? Quel tableau de bord regarder? Essayons d'ouvrir la «boîte noire» de notre modèle et de comprendre comment il prend des décisions.
Interprétation d'un modèle à l'aide de LIME
Il existe différentes approches pour ouvrir la boîte noire d'un modèle formé et comprendre ce qui est dans l'esprit de la machine. Avec une régression logistique ou un arbre de décision, tout est clair, il n'est pas difficile de comprendre sur la base duquel la décision a été prise. Avec la forêt isolée, les choses sont plus compliquées. Premièrement, il y a un accident à l'intérieur de l'algorithme, et deuxièmement, c'est un algorithme d'apprentissage sans professeur.
Le premier candidat était la bibliothèque LIME, qui utilise l'approche modèle agnostique, qui aide à interpréter tous les modèles, l'essentiel est que la sortie du modèle a une distribution probabiliste entre les classes. D'accord, bien sûr, le résultat n'est pas la probabilité, mais bientôt, mais essayons de les normaliser dans la plage de 0 à 1 et de le traiter comme une probabilité. Ainsi, nous avons pu fournir un format d'entrée compatible avec LIME.
La façon dont LIME a interprété les résultats était décevante. Premièrement, à titre d'interprétation, il y avait plusieurs signes les plus importants à la sortie et, dans la plupart des cas, un seul d'entre eux reflétait vraiment adéquatement l'essence de la décision, le reste ajoutant du bruit. Le deuxième inconvénient était que l'interprétation était instable et produisait souvent différentes listes de signes d'une course à l'autre. Pour obtenir des résultats plus stables, vous avez dû exécuter l'interprétation plusieurs fois et faire la moyenne des résultats. Je ne voulais pas vraiment faire ça.
SHAP - pont de personne à voiture
Après cela, nos yeux sont tombés sur une autre bibliothèque pour l'interprétation des modèles - SHAP. L'idée derrière la bibliothèque est venue de la théorie des jeux. La bibliothèque a également une belle visualisation. Après avoir regardé les exemples, nous avons réalisé avec frustration que SHAP ne pouvait pas interpréter la forêt isolée, et nous voulions vraiment! Mais, d'autre part, SHAP peut disséquer XGBoost en toute confiance. Nous avons pensé, et si on nous apprenait à faire XGBoost la même chose que la forêt isolée peut faire? Pour ce faire, nous avons pris l'ensemble de nos données et l'avons marqué avec la forêt isolée. De plus, en tant que cible, ils ont pris non pas un cours, mais un score, qui a été attribué à la forêt isolée. Nous prédirons par toutes les métriques la vitesse que donnerait la forêt isolée, mais seulement avec XGBoot! Aussitôt dit, aussitôt fait. Nous exécuterons notre jeu de données balisé via XGBoost. Et maintenant, maintenant il sait prédire la vitesse de la même manière que la forêt isolée. Hourra, maintenant nous pouvons utiliser SHAP!
La première étape consiste à créer un objet TreeExplainer, en passant le modèle lui-même comme paramètre. Ensuite, les valeurs de shap sont calculées, ce qui nous permet d'expliquer comment le modèle a pris telle ou telle décision.
explainer = shap.TreeExplainer(model) shap_values = explainer.shap_values(X)
SHAP vous permet d'interpréter à la fois le modèle dans son ensemble et les résultats pour des exemples spécifiques. Par exemple, vous pouvez obtenir une explication pour un exemple spécifique en utilisant la méthode force_plot (), qui reçoit les valeurs d'entrée et les valeurs de l'exemple lui-même.
shap.force_plot(explainer.expected_value,shap_values[0,:], X.iloc[0,:])
Il s'avère que le graphique suivant, qui montre quelles caractéristiques du modèle et dans quelle mesure ont influencé la décision.

Nous aidons les entreprises
Maintenant, sachant quelles mesures ont contribué de manière significative au taux global d'anomalie, il devient possible d'établir à quel niveau le problème est survenu et, surtout, s'il a affecté les utilisateurs finaux du système.

Chaque fois qu'une anomalie est détectée, une liste de métriques ayant le plus grand impact sur la décision est obtenue. Si la liste comprend des métriques qui suivent directement les indicateurs liés à l'entreprise, cela est mentionné dans l'alerte d'une manière spéciale, augmentant ainsi automatiquement la priorité de l'anomalie.
Ce n'est que la première mais importante étape dans le renforcement et l'automatisation du système de surveillance à l'aide de l'apprentissage automatique, ce qui peut augmenter considérablement la vitesse d'identification des causes et de l'influence du comportement anormal du système.
Références:scikit-learn.org/stable/modules/generated/sklearn.ensemble.IsolationForest.htmlgithub.com/marcotcr/limegithub.com/slundberg/shap